
本文以Qwen3模型为例,基于PAI-ChatLearn训练框架,介绍如何在PAI中使用灵骏智算资源进行LLM高效分布式强化学习训练并部署训练后模型。
一、准备工作
1.1 开发环境准备
在开始执行操作前,请确认您已经完成以下工作:
购买灵骏智算资源并创建资源配额。本文示例必须使用灵骏资源。完成示例需2台机器,节点规格为
ml.gx8xf.8xlarge-gu108。关于灵骏智算资源的节点规格详情,请参见AI计算资源计费说明。创建数据集,用于存储训练所需的文件和结果文件。
存储类型:选择文件存储类的,本文使用文件存储(通用型NAS)。如没有NAS文件系统请参见创建文件系统。
说明如果您的训练任务对数据读取有很高的读写速度与性能要求,建议您使用文件存储(智算CPFS)。
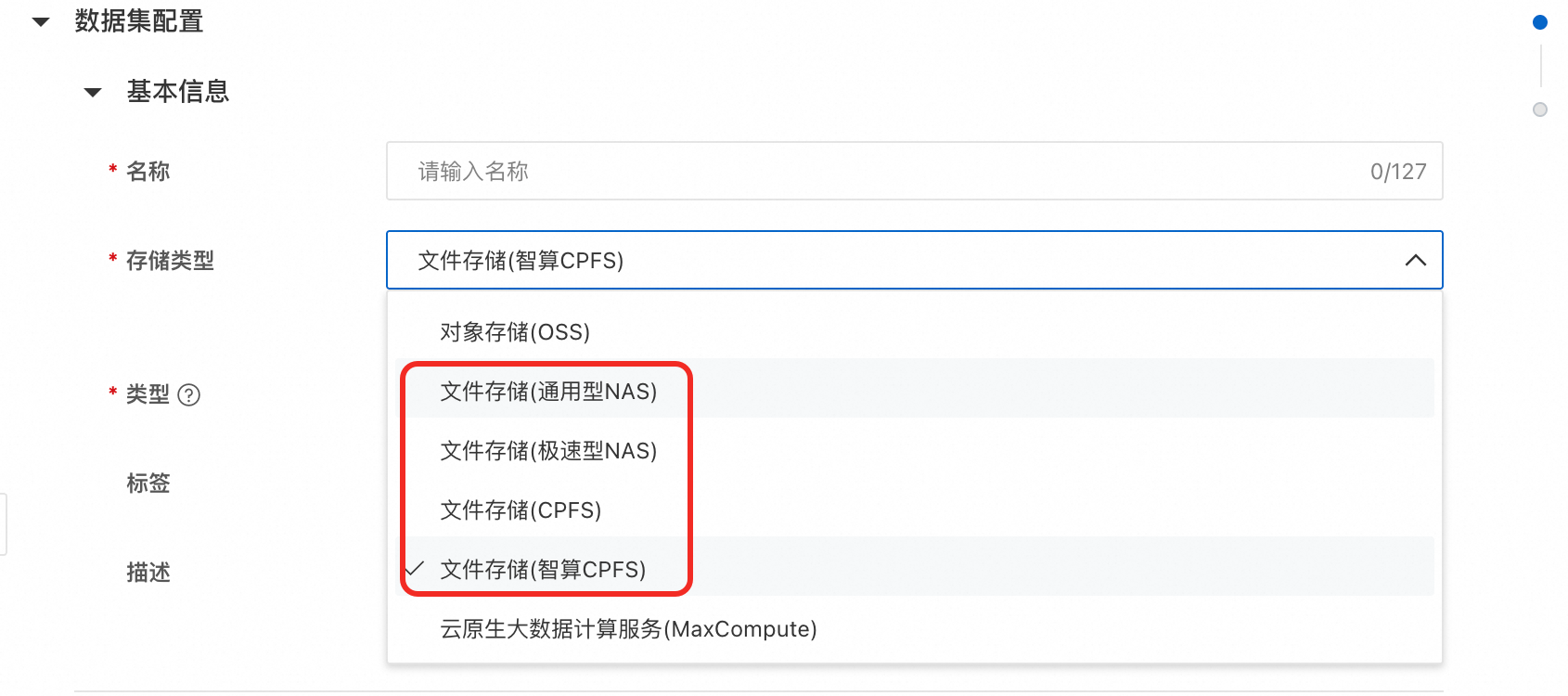
默认挂载路径:使用默认值/mnt/data/。
创建DSW实例,其中关键参数配置如下。
资源配额:选择已创建的灵骏智算资源的资源配额。
资源规格:配置以下资源规格。
GPU(卡数):至少为8。
CPU(核数):90。
内存(GiB):1024。
共享内存(GiB):1024。
镜像:选择镜像地址,配置镜像为
dsw-registry-vpc.cn-wulanchabu.cr.aliyuncs.com/pai-training-algorithm/chatlearn:torch2.5.1-vllm0.6.6-ubuntu22.04-cuda12.6-py310。需要根据当前region信息来更改镜像地址,比如,启动在上海的DSW实例,镜像中region信息更改为cn-shanghai。数据集挂载:单击自定义数据集,选择已创建的数据集,并使用默认挂载路径。
如果使用RAM用户完成以下相关操作,需要为RAM用户授予DSW、DLC或EAS的操作权限。具体操作,请参见云产品依赖与授权:DSW、云产品依赖与授权:DLC或云产品依赖与授权:EAS。
1.2 下载代码库
进入PAI-DSW开发环境。
登录PAI控制台,在页面左上方选择地域,推荐华北6(乌兰察布)。
在左侧导航栏单击工作空间列表,在工作空间列表页面中单击待操作的工作空间名称,进入对应工作空间内。
在左侧导航栏,选择模型开发与训练 > 交互式建模(DSW),单击目标实例操作列下的打开。
在顶部菜单栏单击Terminal,在该页签中单击创建terminal。
下载ChatLearn代码库。
git clone https://github.com/alibaba/ChatLearn.git && cd ChatLearn && git checkout 4ad5912306df5d4a814dc2dd5567fcb26f5d473b
1.3 准备Qwen3模型
从modelscope下载Qwen3模型权重。
modelscope download --model Qwen/Qwen3-8B --local_dir Qwen3-8B1.4 准备训练数据集
本案例以MATH-lighteval数据集为例,介绍ChatLearn强化学习流程。
该数据集是一个数学推理任务数据集,使用固定规则来验证reward打分。
如果需要在自定义任务上进行强化学习训练,可参考chatlearn代码库中
examples/fsdp/models/rule_reward.py实现自定义reward打分函数。
# 下载数据集
mkdir -p dataset
modelscope download --dataset AI-ModelScope/MATH-lighteval --local_dir dataset/MATH-lighteval
# 数据集预处理
python examples/fsdp/data/data_preprocess/math_lighteval.py --input_dir dataset/MATH-lighteval --local_dir dataset/MATH-lighteval二、强化学习训练
建议您先在DSW环境中开发调试完成后,再在DLC环境中提交多机多卡分布式训练任务。
本示例使用FSDP作为训练引擎,若需要使用megatron加速训练可参考tutorial_grpo_mcore。
2.1 DSW单机训练
直接在DSW环境中继续执行如下命令开始训练。训练后的模型将存储到挂载的数据集中,用于后续部署。
bash examples/fsdp/scripts/train_grpo_qwen3.sh使用train_grpo_qwen3.sh默认参数,预计训练耗时2~3小时。
2.2 DLC多机训练
在单机开发调试完成后,您可以在DLC环境中配置多机多卡的分布式任务,加快模型的训练速度。具体操作步骤如下:
进入新建任务页面。
登录PAI控制台,在页面上方选择目标地域,并在右侧选择目标工作空间,然后单击进入DLC。
在分布式训练(DLC)页面,单击新建任务。
在新建任务页面,配置以下关键参数,其他参数取默认配置即可。更多详细内容,请参见创建训练任务。
参数
描述
基本信息
任务名称
自定义任务名称。本方案配置为:test_qwen3_dlc。
环境信息
节点镜像
选中镜像地址并在文本框中输入:dsw-registry-vpc.cn-wulanchabu.cr.aliyuncs.com/pai-training-algorithm/chatlearn:torch2.5.1-vllm0.6.6-ubuntu22.04-cuda12.6-py310,需要根据当前region信息来更改镜像地址。
数据集
单击自定义数据集,并配置以下参数:
自定义数据集:选择已创建的NAS类型数据集,
挂载路径:配置为
/mnt/data/。
启动命令
配置以下命令,其中train_grpo_qwen3.sh脚本输入的启动参数与DSW单机预训练模型一致。
cd /mnt/data/ChatLearn && bash examples/fsdp/scripts/train_grpo_qwen3.sh资源信息
资源类型
选择灵骏智算。
资源来源
选择资源配额。
资源配额
本方案选择已创建的灵骏智算资源的资源配额。
框架
选择PyTorch。
任务资源
在Worker节点配置页签配置以下参数:
节点数量:2,如果需要多机训练,配置节点数量为需要的机器数即可。
GPU(卡数):8
CPU(核数):90
内存(GiB):1024
共享内存(GiB):1024
单击提交,页面自动跳转到分布式训练(DLC)页面。您可以单击任务名称,在任务详情页面查看任务执行状态。当状态变为已成功时,表明训练任务执行成功。
说明当前DLC任务出现
ray.exceptions.RpcError: Timed out while waiting for GCS to become available.时并显示失败时,实际训练任务已经完成,可以直接使用保存模型部署服务。
2.3 主要参数说明
三、部署及调用模型
完成模型训练后,您可以直接将模型部署为在线服务,并在实际的生产环境中调用。
3.1 部署模型服务
登录PAI控制台,在页面上方选择目标地域,并在右侧选择目标工作空间,然后单击进入EAS。
单击部署服务,然后在自定义模型部署区域,单击自定义部署。
在自定义部署页面配置以下关键参数,其他参数取默认配置即可。
参数
描述
基本信息
服务名称
自定义模型服务名称,同地域内唯一。本方案配置为:test_qwen3。
环境信息
部署方式
本方案选择镜像部署。
镜像配置
选择镜像地址,在本文框中配置镜像地址
eas-registry-vpc.cn-wulanchabu.cr.aliyuncs.com/pai-eas/vllm:v0.8.5.post1,需要根据当前region信息来更改镜像地址。模型配置
选择通用型NAS,并配置以下参数:
选择文件系统:选择创建数据集使用的NAS文件系统。
文件系统挂载点:选择创建数据集使用的挂载点。
文件系统路径:配置为存放在NAS中的Huggingface格式模型的路径。本方案配置为
/ChatLearn/output/qwen3-grpo/save_model/policy_trainer/20/huggingface/。挂载路径:指定挂载后的路径,本方案配置为:
/qwen3_rlhf。
运行命令
配置为
vllm serve /qwen3_rlhf --host 0.0.0.0 --port 8000 --max-model-len 8192。说明如您使用V100部署,运行命令配置为
vllm serve /qwen3_rlhf --host 0.0.0.0 --port 8000 --max-model-len 8192 --dtype=half。端口号
配置为:8000。
资源部署
资源类型
本方案选择公共资源。
实例数
根据模型和选择的资源情况进行配置。以8b模型为例,实例数配置为1。
部署资源
资源规格选择A10或V100,本方案配置为
ecs.gn7i-c32g1.8xlarge。专有网络
专有网络(VPC)
配置好NAS挂载点后,系统自动匹配与预设的NAS文件系统一致的VPC、交换机,根据需求设置安全组。
交换机
安全组名称
单击部署。服务部署时间约为6分钟,当服务状态变为运行中时,表明服务部署成功。
3.2 调用服务
获取服务访问地址和Token。在推理服务页签,找到目标服务,单击调用信息。
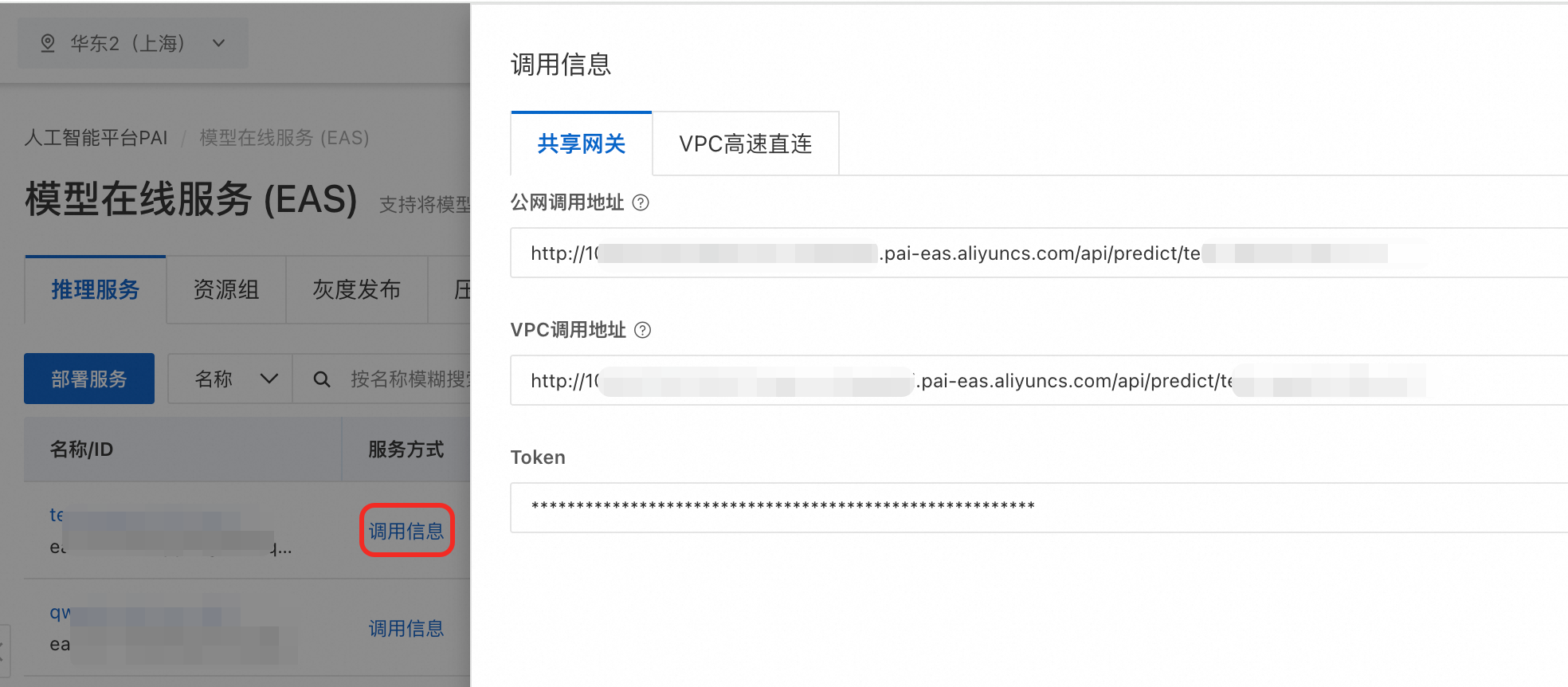
使用如下代码调用服务。其中,<YOUR EAS URL>替换为步骤1中的调用地址;Token建议设置为环境变量。
import os from openai import OpenAI # 建议将Token设置为环境变量 openai_api_key =os.environ.get("Token") # <YOUR EAS URL>替换为服务的访问地址。 openai_api_base = "<YOUR EAS URL>/v1" client = OpenAI( api_key=openai_api_key, base_url=openai_api_base, ) chat_response = client.chat.completions.create( model="/qwen3_rlhf", messages=[ {"role": "system", "content": "You are a helpful assistant."}, {"role": "user", "content": "Find the smallest positive integer solution to $\\tan{19x^{\\circ}}=\\dfrac{\\cos{96^{\\circ}}+\\sin{96^{\\circ}}}{\\cos{96^{\\circ}}-\\sin{96^{\\circ}}}$. Let's think step by step and output the final answer within \\boxed{}."}, ], temperature=0.7, top_p=0.8, presence_penalty=1.5, extra_body={ "top_k": 20, "chat_template_kwargs": {"enable_thinking": False}, } ) print("Chat response:", chat_response)
附录:训练部署所需资源规格参考
不同的模型参数量支持的资源规格列表如下:
模型参数量 | 全参数训练资源(最低) | 推理资源(最低) | |
数量 | 规格 | ||
Qwen3-8B | 1台 |
| 1*V100(32 GB显存) / 1*A10(22 GB显存) |
Qwen3-32B | 2台 | 4*V100(32 GB显存)/ 4*A10(22 GB显存) | |
Qwen3-30B-A3B | 2台 | 4*V100(32 GB显存)/ 4*A10(22 GB显存) | |