
AI 训练通常需要重复读取海量数据,这会产生巨大的网络开销,影响训练效率。在灵骏智算场景下,PAI提供了本地缓存加速功能,通过将数据缓存至本地计算节点,减少网络开销,提高训练吞吐,大幅提升数据读取性能,为您的 AI 训练任务提速。
技术优势
高速缓存:利用计算节点的内存与本地盘构建单机和分布式读缓存,加速数据集与 Checkpoint 访问,显著减少数据访问延迟。
水平扩展:缓存吞吐能力随计算节点规模线性扩展,支持数百至数千个节点规模。
P2P 模型分发:通过 P2P支持大规模模型的高并发加载与分发,利用 GPU 节点间的高速网络实现热点数据的并行读取加速。
Serverless 简单易用:一键开启和关闭,无需修改代码,对程序无侵入,无需关注运维。
限制与说明
存储支持:支持 OSS 、智算 CPFS。
适用资源:目前仅支持灵骏智算资源,注意开启后会占用算力节点一定资源(CPU:4核,Mem:14GB)。
容量与策略:最大缓存容量和灵骏智算规格相关,淘汰策略采用 LRU(最近最少使用)。
加速目标:核心目标是提升数据读取性能,不支持写。
数据高可用性:不保证数据高可用。本地缓存数据可能存在丢失情况,重要训练数据请及时备份。
工作机制:在多轮训练时,第一轮需要从存储实例(例如: OSS、 智算CPFS)读取数据,性能与直读存储实例一致。但在后续多轮训练中,将从本地缓存中读取数据,可以提升读取速度。
使用方法
开启资源配额(Quota)本地缓存。在左侧导航栏单击资源配额(Quota)> 灵骏智算资源,找到并单击目标Quota名称进入管理页面。开启本地缓存,并设置需要缓存的存储路径。
如果是多级嵌套的资源配额,需保证第一级资源配额(Quota)已开启本地缓存。
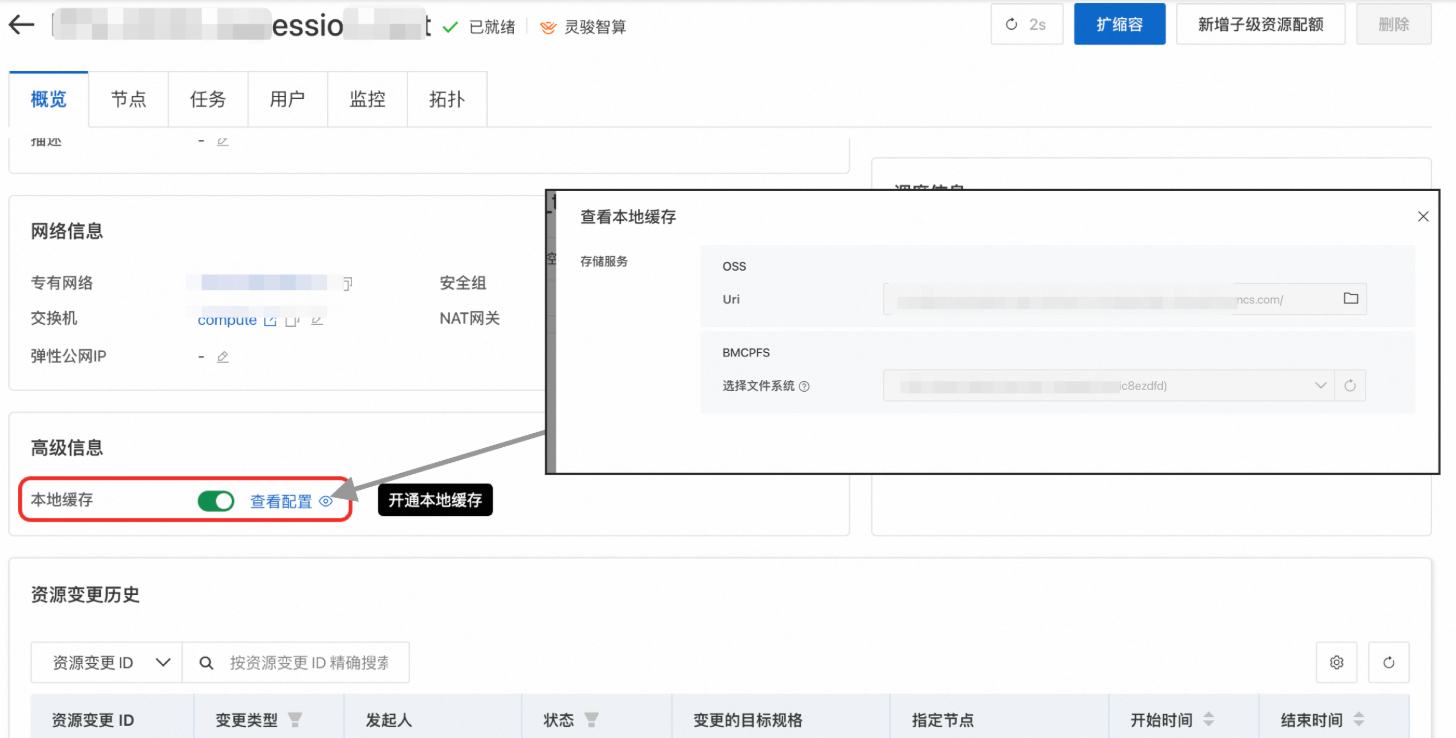
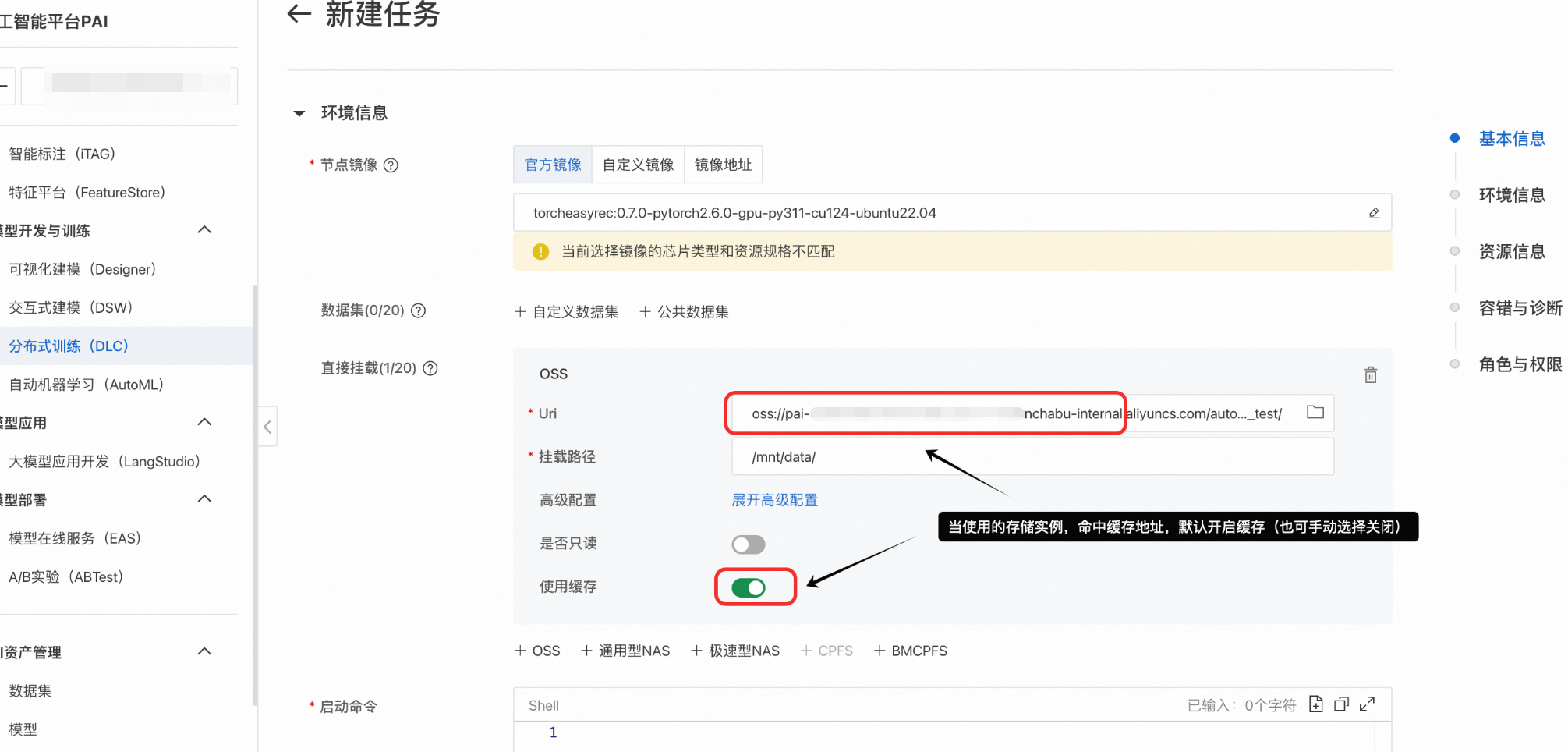
使用目标资源配额的灵骏资源创建DLC任务,并开启使用缓存。当挂载的存储地址命中步骤1中填写的缓存地址时,默认加速(用户可选择关闭)。
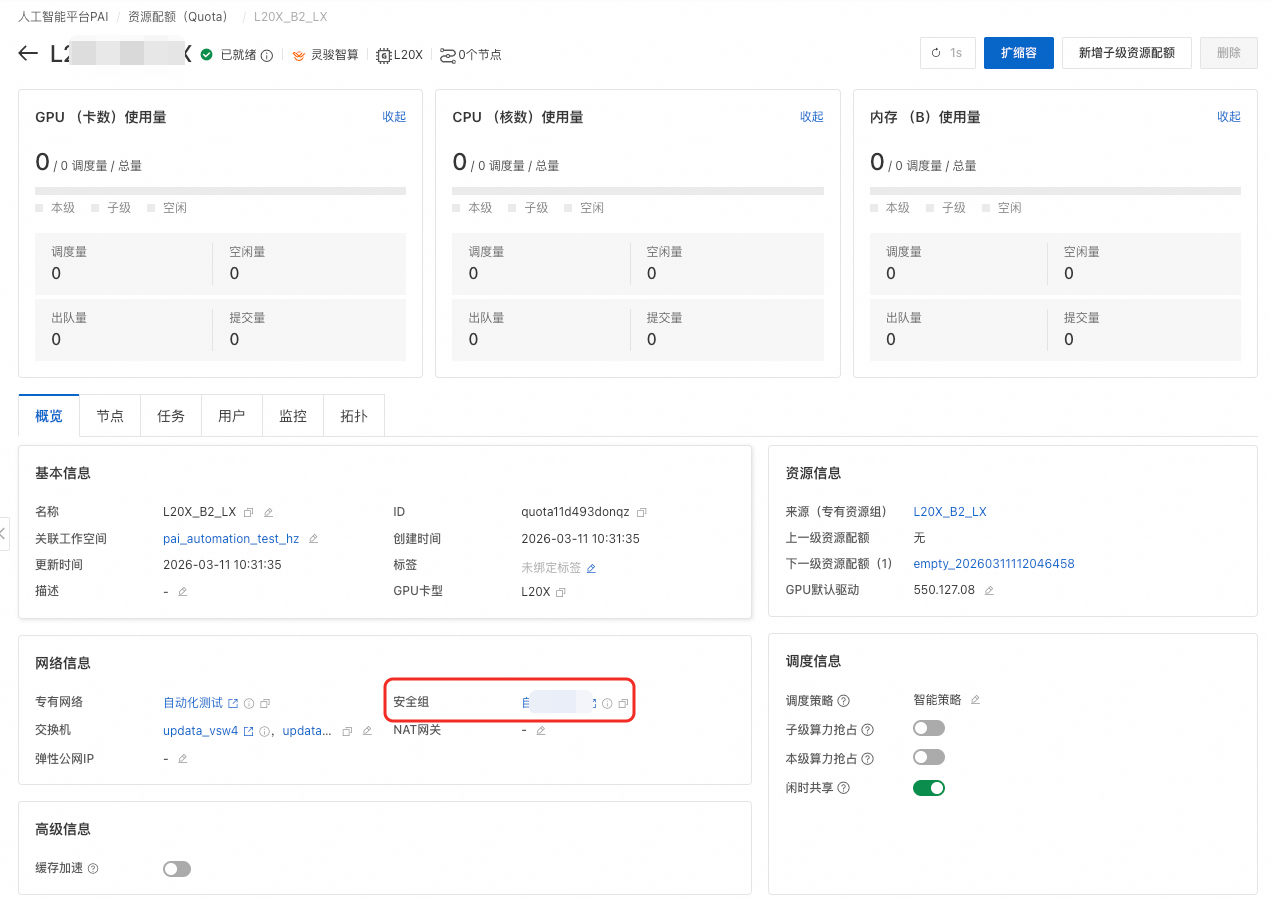
安全组配置入规则
当您使用的安全组类型为企业级安全组时,需额外配置入规则,实现与专有网络VPC的连通。
在资源配额页面网络信息区域查看配置的安全组。
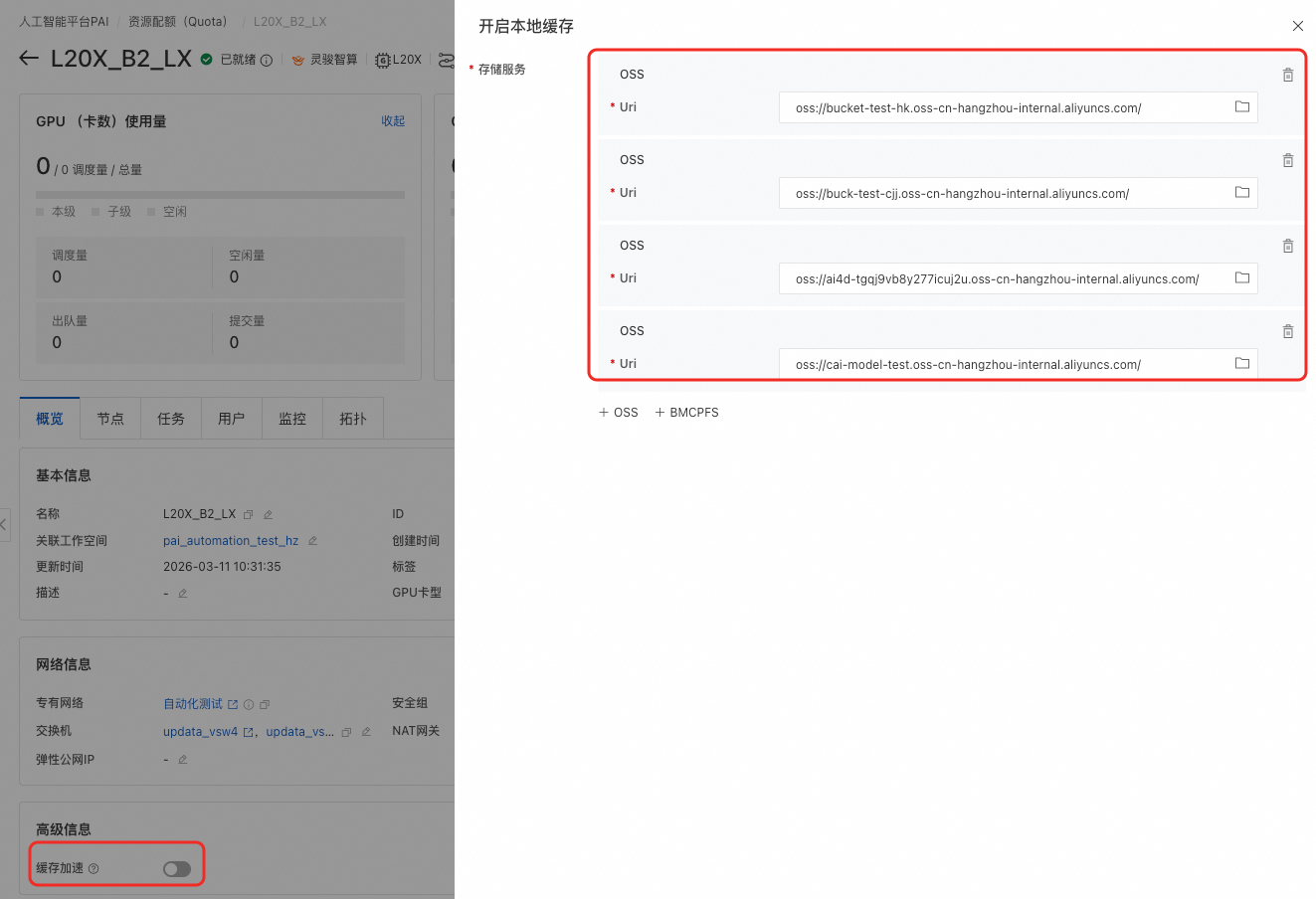
当开通缓存加速功能时,需要根据设置的存储服务数量配置对应的入规则端口,此处以4个为例。
到对应安全组的页面,如果安全组类型为企业级,需要增加一项入方向的规则。
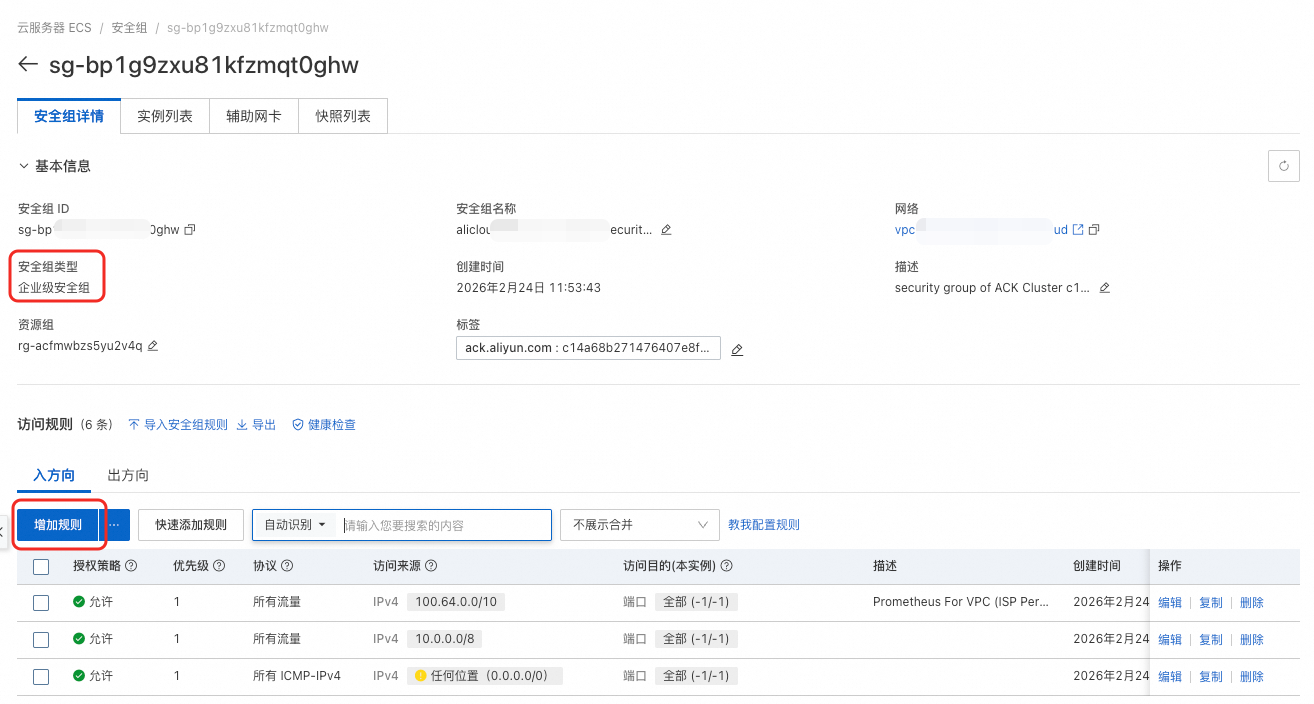
 访问来源配置为的资源配额使用的交换机对应的网段。访问目的需要配置端口,端口数需要与缓存配置的存储服务数相同。如果存储服务数为n,则端口需配置为10080/10080+n-1,其中n<=10。(表示端口范围为
访问来源配置为的资源配额使用的交换机对应的网段。访问目的需要配置端口,端口数需要与缓存配置的存储服务数相同。如果存储服务数为n,则端口需配置为10080/10080+n-1,其中n<=10。(表示端口范围为10080-10080+n-1)。本示例配置了4个,因此为10080/10083。
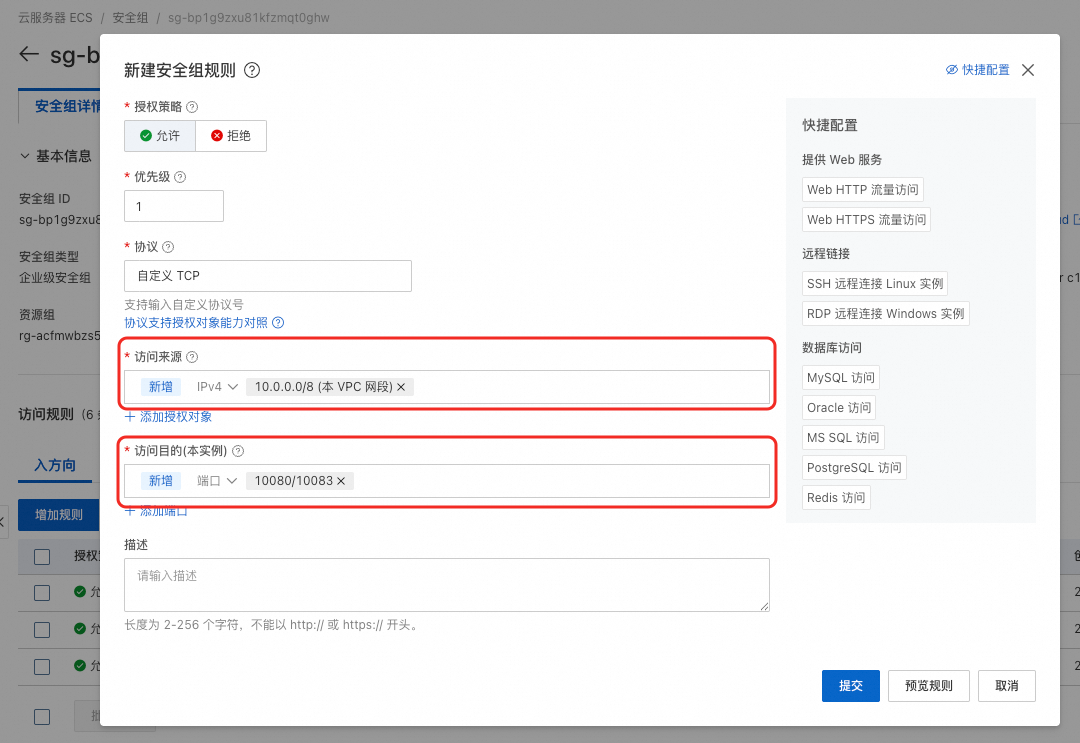 访问来源配置为的资源配额使用的交换机对应的网段。访问目的需要配置端口,端口数需要与缓存配置的存储服务数相同。如果存储服务数为n,则端口需配置为10080/10080+n-1,其中n<=10。(表示端口范围为
访问来源配置为的资源配额使用的交换机对应的网段。访问目的需要配置端口,端口数需要与缓存配置的存储服务数相同。如果存储服务数为n,则端口需配置为10080/10080+n-1,其中n<=10。(表示端口范围为