
混淆矩阵(Confusion Matrix)适用于监督学习,与无监督学习中的匹配矩阵对应。在精度评价中,混淆矩阵主要用于比较分类结果和实际测量值,可以将分类结果的精度显示在一个矩阵中。本文为您介绍混淆矩阵组件的配置方法。
使用限制
支持的计算引擎为MaxCompute。
组件配置
您可以使用以下任意一种方式,配置混淆矩阵组件参数。
方式一:可视化方式
在Designer工作流页面配置组件参数。
|
参数 |
描述 |
|
原数据的标签列列名 |
支持数值类型。 |
|
预测结果的标签列列名 |
如果未配置阈值,则该参数必选。 |
|
阈值 |
大于该参数值的样本为正样本。 |
|
预测结果的详细列列名 |
与预测结果的标签列列名不能共存。如果已配置阈值,则该参数必选。 |
|
正样本的标签值 |
如果已配置阈值,则该参数必选。 |
方式二:PAI命令方式
使用PAI命令方式,配置该组件参数。您可以使用SQL脚本组件进行PAI命令调用,详情请参见SQL脚本。
-
未指定阈值
pai -name confusionmatrix -project algo_public -DinputTableName=wpbc_pred -DoutputTableName=wpbc_confu -DlabelColName=label -DpredictionColName=prediction_result; -
指定阈值
pai -name confusionmatrix -project algo_public -DinputTableName=wpbc_pred -DoutputTableName=wpbc_confu -DlabelColName=label -DpredictionDetailColName=prediction_detail -Dthreshold=0.8 -DgoodValue=N;
|
参数 |
是否必选 |
描述 |
默认值 |
|
inputTableName |
是 |
输入表的名称,即预测输出表。 |
无 |
|
inputTablePartition |
否 |
输入表的分区。 |
全表 |
|
outputTableName |
是 |
输出表的名称,用于存储混淆矩阵。 |
无 |
|
labelColName |
是 |
原始标签列的名称。 |
无 |
|
predictionColName |
否 |
预测结果列的名称。如果未配置threshold,则该参数必选。 |
无 |
|
predictionDetailColName |
否 |
预测结果详细列的名称。如果已配置threshold,则该参数必选。 |
无 |
|
threshold |
否 |
划分正样本的阈值。 |
0.5 |
|
goodValue |
否 |
二分类时,指定训练系数对应的标签值。如果已配置threshold,则该参数必选。 |
无 |
|
coreNum |
否 |
计算的核心数量。 |
系统自动分配 |
|
memSizePerCore |
否 |
每个核心的内存,单位为MB。 |
系统自动分配 |
|
lifecycle |
否 |
输出表的生命周期。 |
无 |
示例
-
用MaxCompute客户端创建表test_data,其中列字段和数据类型为
id bigint、label string、prediction_result string。关于MaxCompute客户端的安装及配置请参见使用本地客户端(odpscmd)连接,如何创建表,请参见创建表。 -
将如下测试数据导入到表test_data中。如何导入数据,请参见导入数据。
id
label
prediction_result
0
A
A
1
A
B
2
A
A
3
A
A
4
B
B
5
B
B
6
B
A
7
B
B
8
B
A
9
A
A
-
构建如下工作流,并运行组件,详情请参见算法建模。
-
在Designer左侧组件列表中,分别搜索读数据表组件和混淆矩阵组件,并拖入右侧画布中。
-
参照以上步骤,通过连线的方式,将各个节点组织构建成为一个有上下游关系的工作流。
-
配置组件参数。
-
在画布中单击读数据表-1组件,在右侧表选择页签,配置表名为test_data。
-
在画布中单击混淆矩阵-1组件,在右侧配置如下表中的参数,其余参数使用默认值。
参数
描述
原数据的标签列列名
选择label列。
预测结果的标签列列名
输入prediction_result。
-
-
参数配置完成后,单击运行按钮
 ,运行工作流。
,运行工作流。
-
-
工作流运行成功后,右键单击混淆矩阵-1组件,在快捷菜单,选择可视化分析,查看混淆矩阵组件的输出结果。
-
单击混淆矩阵页签,查看输出的混淆矩阵。
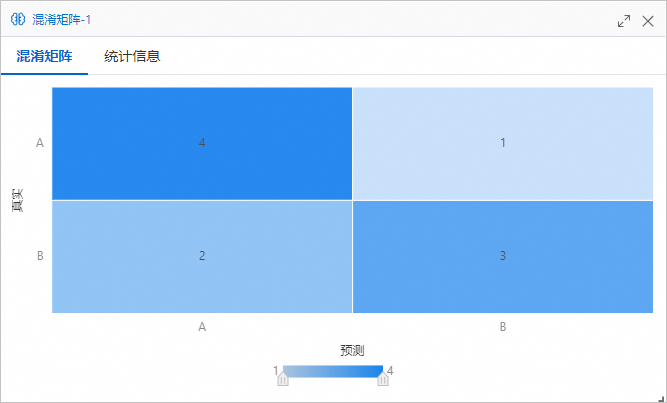
-
单击统计信息页签,查看模型统计信息。
统计信息包括 TruePositive、FalsePositive、Accuracy、Precision、Recall 和 F1 Score。例如,Model A 的指标值分别为 4、2、0.7、0.6667、0.8、0.7273;Model B 的指标值分别为 3、1、0.7、0.75、0.6、0.6667。
-
相关文档
-
关于Designer组件更详细的内容介绍,请参见Designer概述。
-
Designer预置了多种算法组件,你可以根据不同的使用场景选择合适的组件进行数据处理,详情请参见组件参考:所有组件汇总。