DSW可以连接EMR集群,提交并执行Spark作业。这将帮助您充分利用EMR强大的性能高效处理数据,并无缝衔接模型开发,实现大数据与AI的融合。
背景信息
数据预处理在机器学习和大语言模型领域中至关重要,但通常耗时且复杂,涵盖数据清洗、转换及特征构建等关键步骤。因此,DSW与开源大数据平台EMR合作推出了一站式大数据与AI整合方案。
EMR作为阿里云平台上的全托管大数据处理服务,集成了Apache Spark,使得用户能便捷地在云环境搭建、管理和使用Spark集群,并进行大规模数据处理、实时计算、机器学习任务以及图形处理等。
适用范围
只有以下类型的DSW实例支持连接到EMR集群:
使用公共资源组创建的后付费DSW实例。
仅支持以下类型的EMR集群:
DataLake集群
安装了Spark3和Hadoop的自定义集群
每个DSW实例最多可以连接一个EMR集群,连接完成后不支持切换到其它集群。
前提条件
操作步骤
在DSW中打开教程文件
进入DSW开发环境。
登录PAI控制台。
在页面左上方,选择DSW实例所在的地域。
在左侧导航栏单击工作空间列表,在工作空间列表页面中单击默认工作空间名称,进入对应工作空间内。
在左侧导航栏,选择模型开发与训练>交互式建模(DSW)。
单击需要打开的实例操作列下的打开,进入DSW实例开发环境。
在Notebook页签的Launcher页面,单击快速开始区域Tool下的DSW Gallery,打开DSW Gallery页面。
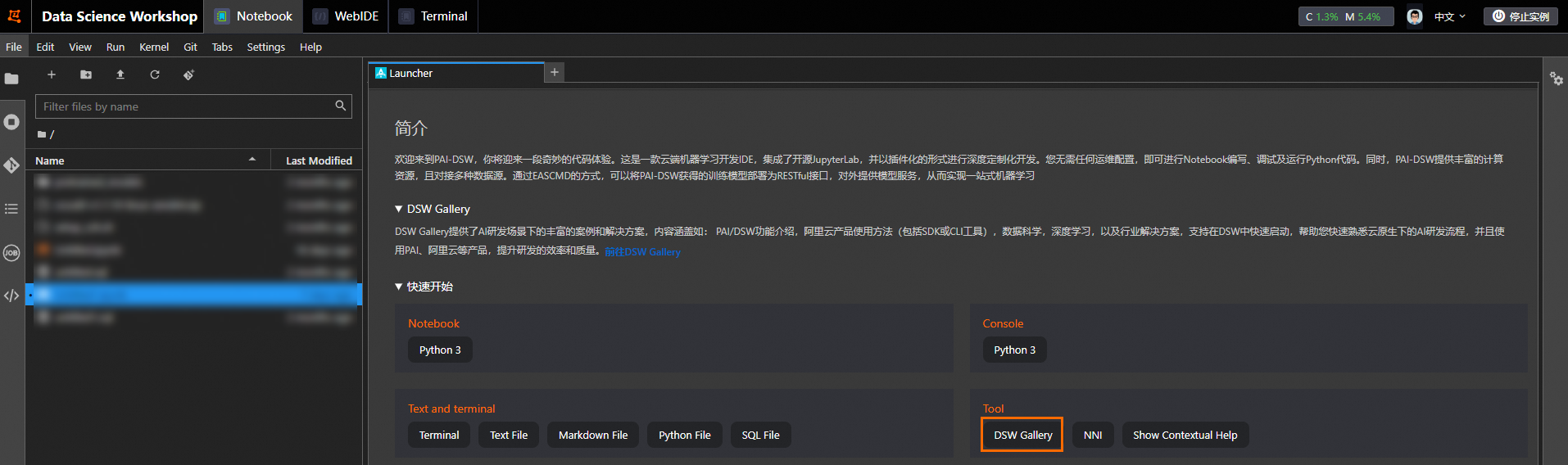
在DSW Gallery页面中,搜索大数据和AI一体化:向EMR集群提交Spark作业,单击在DSW中打开,即可自动将本教程所需的资源和教程文件下载至DSW实例中,并在下载完成后自动打开教程文件。
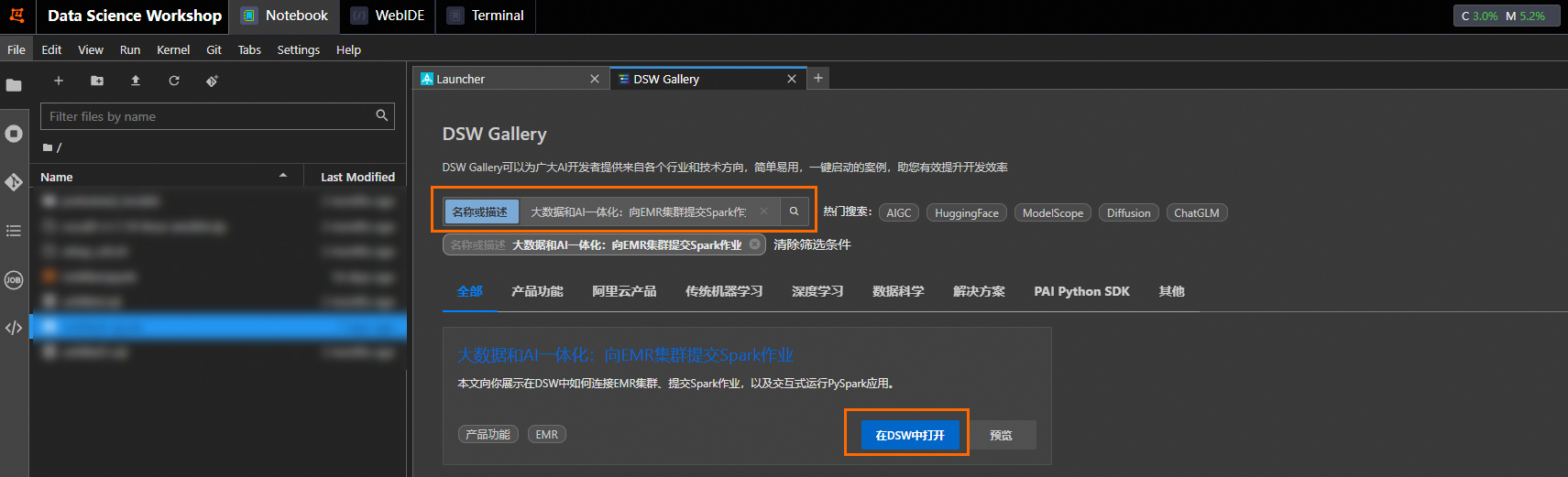
运行教程文件
在打开的教程文件emr_connect.ipynb中,您可以查看教程内容以及直接运行教程。
在教程文件中单击 运行对应步骤的命令,当成功运行结束一个步骤命令后,再顺次运行下个步骤的命令。
运行对应步骤的命令,当成功运行结束一个步骤命令后,再顺次运行下个步骤的命令。
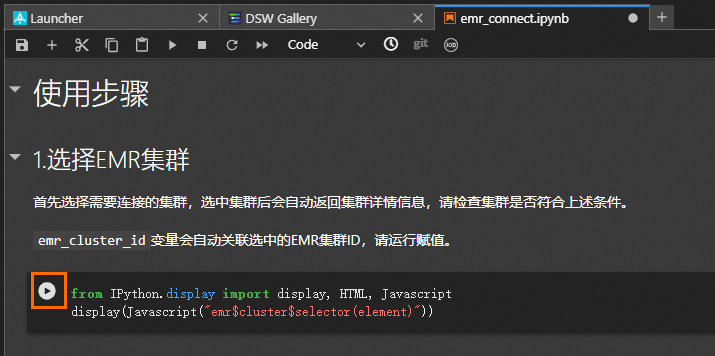
本教程包括以下4个运行步骤:
选择EMR集群。
连接指定集群。
使用spark-submit提交作业。
运行PySpark交互式应用。
常见问题
Q:DSW实例重启后,运行Spark作业报错,应如何解决?
Q:报错spark-submit: command not found,应如何解决?
执行EMR集群连接操作成功后,需要新建Terminal加载Spark相关的环境参数。可以执行以下命令检查当前会话中Spark配置是否生效,如果返回为空,说明未生效。
env | grep -i SPARK_HOMEQ:报错Python in worker has different version * than that in driver *,应如何解决?
该错误表示Driver所在客户端的Python版本与集群Worker节点的Python版本不匹配。
Q:ModuleNotFoundError: No module named ***,应如何解决?
集群中Executor使用的Python环境中没有安装PySpark应用中依赖的包,推荐使用spark.archives配置将本地Python环境同步到远端,或者手动在集群每个Worker节点安装相关依赖。
Q:创建PySpark内核并初始化完成后,新建Notebook时,下拉列表里没有PySpark选项,应如何解决?
在Notebook页签的工具栏,选择Kernel>Restart Kernel。