
PAI提供自定义算法组件功能,便于您根据使用场景创建自定义组件。您可以在Designer中将自定义组件和PAI官方组件串联使用,实现更灵活的工作流编排。本文为您介绍如何创建自定义组件。
背景信息
自定义组件底层采用了阿里云开源的KubeDL,这是一个基于Kubernetes的AI工作负载管理框架。
创建自定义组件支持选择不同的任务类型(包括:Tensorflow、PyTorch、XGBoost、ElasticBatch)、创建输入输出管道、配置超参等,自定义组件创建成功后,会转换为Designer界面可视化参数配置,详情请参见操作步骤。
针对不同的任务类型,KubeDL会下发同步的环境变量,通过这些环境变量,您可以获取机器数量和拓扑信息,详情请参见附录1:任务类型介绍。
通过在执行命令中配置环境变量来读取输入输出管道数据、超参数据等,详情请参见如何读取管道及超参数据。
在执行代码中,除了通过环境变量获取输入或输出管道外,也可以直接通过容器内挂载路径进行访问,详情请参见输入输出目录结构。
前提条件
已创建工作空间,创建的自定义组件均与该工作空间绑定。具体操作,请参见创建及管理工作空间。
操作步骤
进入组件管理页面。
登录PAI控制台。
在左侧导航栏单击工作空间列表,在工作空间列表页面中单击待操作的工作空间名称,进入对应工作空间内。
在左侧导航栏,选择AI资产管理>自定义组件。
在组件列表页面,单击新建组件,并在新建组件页面配置以下参数。
基本信息配置
参数
描述
组件名称
自定义组件名称,在同一个地域下要求主账号内唯一。
组件描述
对创建的自定义组件进行简单描述,以区分不同的组件。
组件版本
创建的自定义组件版本号。
说明建议使用
x.y.z的版本号格式来管理版本。例如,第一个大版本为1.0.0,对该版本进行小问题修复时,可以将版本号升级为1.0.1;而进行小型功能升级时,则可以将版本号升级为1.1.0。这样的版本号管理方式清晰明了,便于您了解各个版本之间的差异和更新内容。版本描述
对当前创建的自定义组件版本进行描述。例如:初始版本。
执行配置
参数
描述
任务类型
创建自定义组件时,需要选择任务类型。目前支持Tensorflow、PyTorch、XGBoost、ElasticBatch四种任务类型,其分别对应了KubeDL中的TFJob、PyTorchJob、XGBoostJob、ElasticBatchJob四种任务类型。关于每种任务类型更详细的介绍,请参见附录:任务类型介绍。
执行镜像
当前支持选择社区镜像、官方镜像和自定义镜像,您也可以在镜像地址页签配置三种类型的镜像地址。
说明由于公网带宽有限,为了保证任务的稳定性,请使用同一个Region下阿里云的镜像服务(ACR)。
目前只支持ACR个人版,不支持企业版,镜像地址请填写VPC地址,格式为:
registry-vpc.${region}.aliyuncs.com。使用自定义镜像时,请勿在同一版本中频繁更新镜像,因为这会导致镜像缓存无法及时更新,从而导致任务启动时间延长。
为确保镜像正常执行,镜像中必须包含
sh shell命令。同时,镜像执行命令的方式将使用sh -c方式。如果使用了自定义镜像,请确保该镜像中包含了Python相关的执行环境和pip命令,否则可能导致任务运行失败。
执行代码
自定义组件的代码目录支持OSS目录和Git地址:
OSS挂载:组件运行时,该OSS目录中所有文件将会被下载到
/ml/usercode/目录下,您可以通过命令执行该目录下的文件。说明建议该目录只存放当前算法必需的文件,否则可能导致组件启动时间过长、甚至启动超时。
当代码目录中存在requirements.txt文件时,算法运行时会自动执行
pip install -r requirements.txt安装相关依赖。
PAI代码配置:配置Git代码库。
执行命令
组件镜像的执行命令,可以通过环境变量获取实际的值,配置格式如下:
python main.py $PAI_USER_ARGS --{CHANNEL_NAME} $PAI_INPUT_{CHANNEL_NAME} --{CHANNEL_NAME} $PAI_OUTPUT_{CHANNEL_NAME} && sleep 150 && echo "job finished"执行命令中通过配置PAI_USER_ARGS、PAI_INPUT_{CHANNEL_NAME}、PAI_OUTPUT_{CHANNEL_NAME}环境变量来读取超参、输入和输出管道数据,具体数据读取方法,请参见如何读取管道及超参数据。
例如:输入管道名称分别为test、train;输出管道名称分别为model、checkpoints,则配置示例如下:
python main.py $PAI_USER_ARGS --train $PAI_INPUT_TRAIN --test $PAI_INPUT_TEST --model $PAI_OUTPUT_MODEL --checkpoints $PAI_OUTPUT_CHECKPOINTS && sleep 150 && echo "job finished"其中配套的代码入口文件main.py中主要提供了解析参数的逻辑示例,在实际使用时,您将自己的算法逻辑整合进去即可,示例内容如下所示:
import os import argparse import json def parse_args(): """解析给到脚本的arguments.""" parser = argparse.ArgumentParser(description="PythonV2 component script example.") # input & output channels parser.add_argument("--train", type=str, default=None, help="input channel train.") parser.add_argument("--test", type=str, default=None, help="input channel test.") parser.add_argument("--model", type=str, default=None, help="output channel model.") parser.add_argument("--checkpoints", type=str, default=None, help="output channel checkpoints.") # parameters parser.add_argument("--param1", type=int, default=None, help="param1") parser.add_argument("--param2", type=float, default=None, help="param2") parser.add_argument("--param3", type=str, default=None, help="param3") parser.add_argument("--param4", type=bool, default=None, help="param4") parser.add_argument("--param5", type=int, default=None, help="param5") args, _ = parser.parse_known_args() return args if __name__ == "__main__": args = parse_args() print("Input channel train={}".format(args.train)) print("Input channel test={}".format(args.test)) print("Output channel model={}".format(args.model)) print("Output channel checkpoints={}".format(args.checkpoints)) print("Parameters param1={}".format(args.param1)) print("Parameters param2={}".format(args.param2)) print("Parameters param3={}".format(args.param3)) print("Parameters param4={}".format(args.param4)) print("Parameters param5={}".format(args.param5))下面是上述示例代码实际运行中打印的日志,您可以看到通过以上方式能够获取到任务实例的参数信息:
Input channel train=/ml/input/data/train Input channel test=/ml/input/data/test/easyrec_config.config Output channel model=/ml/output/model/ Output channel checkpoints=/ml/output/checkpoints/ Parameters param1=6 Parameters param2=0.3 Parameters param3=test1 Parameters param4=True Parameters param5=2 job finished管道及参数
单击
 配置自定义组件的输入管道(Input Channel)、输出管道(Output Channel)和参数。名称命名格式如下:
配置自定义组件的输入管道(Input Channel)、输出管道(Output Channel)和参数。名称命名格式如下:要求全局唯一,且互相不能重复。
支持数字、字母、下划线(_)和减号(-),不能以下划线开头。
说明如果名称中包含了环境变量不支持的字符(仅支持字母、数字和下划线),在生成环境变量时,这些字符将被替换为下划线。此外,名称中的小写字母将被转换为大写字母。因此,应避免出现转换为环境变量后可能产生冲突的情况。例如:如果参数名分别为test_model、test-model,在转换为环境变量后,它们将全部变为PAI_HPS_TEST_MODEL,可能会出现冲突。
管道及参数配置与Designer组件界面化参数对应关系如下图所示:
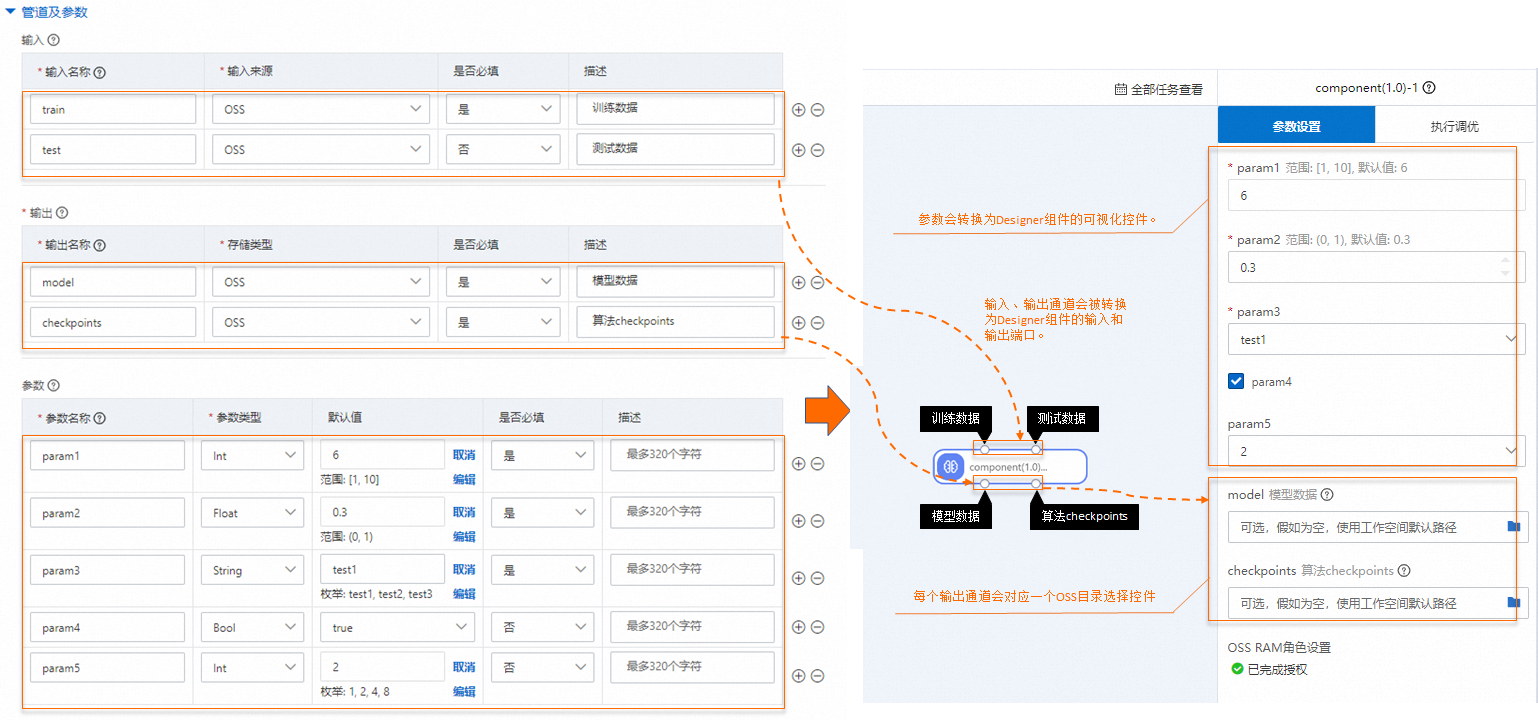
具体参数配置说明如下:
参数
描述
输入
自定义组件通过输入管道获取输入数据或finetune的模型,支持配置以下参数:
输入名称:参照界面提示配置输入管道名称。
输入来源:指定输入管道读取OSS、NAS或MaxCompute路径的数据。输入数据会以挂载的形式,挂载到训练容器的
/ml/input/data/{channel_name}/目录下,组件可以通过读取本地文件的方式读取到OSS、NAS或MaxCompute上的数据。
输出
输出管道用于保存训练模型、Checkpoints等结果,支持配置以下参数:
输出名称:参照界面提示配置输出管道名称。
存储类型:每个输出管道需要指定一个OSS或MaxCompute目录,该目录将会以挂载的方式挂载到训练容器的
/ml/output/{channel_name}/下。
参数
超参信息,支持配置以下参数:
参数名称:参照界面提示配置参数名称。
参数类型:目前支持配置Int、Float、String、Bool四种类型。
约束:选择除Bool外的参数类型(包括Int、Float、String)后,在默认值列,单击约束,来配置参数约束关系。约束类型取值如下:
范围:通过配置最大值和最小值来指定取值范围。
枚举:为参数配置枚举值。
训练约束
训练约束用于定义训练任务需要的计算资源,您可以打开开启训练约束开关进行配置。
训练约束配置转换为Designer组件界面化参数执行调优配置:配置训练约束后,在工作流中使用该组件时,右侧执行调优面板中的机器实例类型、规格选择、机器数量及最大运行时长(秒)等参数将受训练约束的配置限制。
具体参数说明如下:
参数
描述
机器类型
配置自定义组件支持CPU或GPU机器。
支持多机
组件是否支持多机分布式运行:
支持:组件运行时,支持配置节点数。
不支持:组件运行时,节点数只能为1,不支持修改。
支持多卡
仅当机器类型选择GPU时,支持配置该参数。
自定义组件是否支持多卡:
支持:机器类型支持选择单卡或多卡GPU机器。
不支持:机器类型仅支持选择单卡GPU机器。
单击提交。
组件列表页面显示已创建的自定义组件。
组件创建成功后,后续您可以在Designer中使用该自定义组件,详情请参见使用自定义组件。
附录1:任务类型介绍
Tensorflow(TFJob)
如果自定义组件任务类型是Tensorflow(TFJob),任务启动的节点的拓扑信息会通过环境变量TF_CONFIG注入,环境变量值格式示例如下:
{
"cluster": {
"chief": [
"dlc17****iui3e94-chief-0.t104140334615****.svc:2222"
],
"evaluator": [
"dlc17****iui3e94-evaluator-0.t104140334615****.svc:2222"
],
"ps": [
"dlc17****iui3e94-ps-0.t104140334615****.svc:2222"
],
"worker": [
"dlc17****iui3e94-worker-0.t104140334615****.svc:2222",
"dlc17****iui3e94-worker-1.t104140334615****.svc:2222",
"dlc17****iui3e94-worker-2.t104140334615****.svc:2222",
"dlc17****iui3e94-worker-3.t104140334615****.svc:2222"
]
},
"task": {
"type": "chief",
"index": 0
}
}其中关键参数说明如下:
参数 | 描述 |
cluster | TensorFlow集群描述,Map类型:
|
task |
|
Pytorch(PyTorchJob)
如果自定义组件任务类型是Pytorch(PyTorchJob),将会有如下的环境变量注入:
RANK:例如配置为0,表示当前节点是Master节点,非0为Worker节点。
WORLD_SIZE:任务中机器的总数量。
MASTER_ADDR:Master节点的地址。
MASTER_PORT:Master节点的端口。
XGBoost(XGBoostJob)
如果自定义组件任务类型是XGBoost(XGBoostJob),将会有如下的环境变量注入:
RANK:例如配置为0,表示当前节点是Master节点,非0为Worker节点。
WORLD_SIZE:任务中机器的总数量。
MASTER_ADDR:Master节点的地址。
MASTER_PORT:Master节点的端口。
WORKER_ADDRS:Worker节点的地址,按RANK的顺序进行排序。
WORKER_PORT:Worker节点的端口。
示例如下:
分布式任务(节点数超过1)
WORLD_SIZE=6 WORKER_ADDRS=train1pt84cj****-worker-0,train1pt84cj****-worker-1,train1pt84cj****-worker-2,train1pt84cj****-worker-3,train1pt84cj****-worker-4 MASTER_PORT=9999 MASTER_ADDR=train1pt84cj****-master-0 RANK=0 WORKER_PORT=9999单节点运行
说明如果只有一个节点,则节点为Master节点,此时没有WORKER_ADDRS和WORKER_PORT环境变量。
WORLD_SIZE=1 MASTER_PORT=9999 MASTER_ADDR=train1pt84cj****-master-0 RANK=0
ElasticBatch(ElasticBatchJob)
ElasticBatch是一种分布式离线弹性批量推理作业类型。ElasticBatch Job具有以下特点:
轻松并行,吞吐量翻倍。
任务等待时间大大降低, 部分Worker有资源即可运行。
支持自动监测慢机并启动Backup Worker替换,避免任务长尾(即尾延迟)或者Hang(即挂起)。
支持数据分片全局动态分发,让快节点处理更多数据。
支持任务早停,数据全部处理完成后,未启动的Worker不再启动,避免增加任务结束时间。
支持容错处理,单Worker偶发失败会被重新拉起执行。
ElasticBatch Job包含AIMaster和Worker两类节点:
AIMaster:负责Job的全局管控,包括数据分片动态分发、各Worker数据吞吐性能监测以及容错处理。
Worker:工作节点,从AIMaster获取分片后,进行数据读取、数据处理以及数据写回,然后获取下一个要处理的分片。数据分片的动态获取使得快机器处理更多数据,慢机器少处理数据。
ElasticBatch任务启动后,会启动AIMaster节点和Worker节点,您的代码会运行在Worker节点中。Worker节点中会注入ELASTICBATCH_CONFIG 环境变量,环境变量值格式示例如下:
{
"task": {
"type": "worker",
"index": 0
},
"environment": "cloud"
}参数说明如下:
task.type:表示当前节点的任务类型。
task.index:当前节点在其角色对应的网络地址列表中的Index。
附录2:自定义组件实现原理
如何读取管道及超参数据
读取输入管道数据
对于每一个输入管道的数据,会以PAI_INPUT_{CHANNEL_NAME}的环境变量注入到训练作业的容器中。
例如自定义组件有train、test两个输入管道,其值分别为:oss://<YourOssBucket>.<OssEndpoint>/path-to-data/和oss://<YourOssBucket>.<OssEndpoint>/path-to-data/test.csv,则注入的环境变量如下:
PAI_INPUT_TRAIN=/ml/input/data/train/
PAI_INPUT_TEST=/ml/input/data/test/test.csv读取输出管道数据
组件可以通过PAI_OUTPUT_{CHANNEL_NAME}环境变量,获取到对应的路径。
例如自定义组件有model和checkpoints两个输出管道,则注入的环境变量如下:
PAI_OUTPUT_MODEL=/ml/output/model/
PAI_OUTPUT_CHECKPOINTS=/ml/output/checkpoints/读取超参数据
通过以下环境变量读取超参数据:
PAI_USER_ARGS
组件运行时,作业的所有超参信息会以PAI_USER_ARGS环境变量,使用
--{hyperparameter_name} {hyperparameter_value}的形式,注入到训练作业的容器中。例如训练作业指定了超参
{"epochs": 10, "batch-size": 32, "learning-rate": 0.001},则PAI_USER_ARGS环境变量的值为:PAI_USER_ARGS="--epochs 10 --batch-size 32 --learning-rate 0.001"PAI_HPS_{HYPERPARAMETER_NAME}
单个参数的值,也会以环境变量的形式注入到训练作业的容器中。对于超参名中,环境变量中不支持的字符(仅支持字母、数字和下划线)会被替换为下划线。
例如训练作业指定了超参
{"epochs": 10, "batch-size": 32, "train.learning_rate": 0.001},对应的环境变量信息如下:PAI_HPS_EPOCHS=10 PAI_HPS_BATCH_SIZE=32 PAI_HPS_TRAIN_LEARNING_RATE=0.001PAI_HPS
训练作业的超参信息会以JSON格式通过PAI_HPS环境变量注入到训练作业的容器中。
例如训练作业传递了超参
{"epochs": 10, "batch-size": 32},则PAI_HPS环境变量的值为:PAI_HPS={"epochs": 10, "batch-size": 32}
输入输出目录结构
在执行代码中,除了通过环境变量获取输入或输出管道外,也可以直接通过容器内挂载路径进行访问。组件提交的任务在容器内执行时,会按照以下规则创建相应路径:
代码路径:
/ml/usercode/。超参配置文件:
/ml/input/config/hyperparameters.json。训练作业的完整配置文件:
/ml/input/config/training_job.json。输入管道的目录路径:
/ml/input/data/{channel_name}/。输出管道的目录路径:
/ml/output/{channel_name}/。
自定义组件执行作业的输入输出目录结构完整示例如下:
/ml
|-- usercode # 用户代码加载到/ml/usercode目录,这里也是用户代码的工作目录. 可以通过环境变量PAI_WORKING_DIR获得。
| |-- requirements.txt
| |-- main.py
|-- input # 作业输入数据和配置信息
| |-- config # config目录包含了作业的配置信息, 可以通过PAI_CONFIG_DIR获取。
| |-- training_job.json # 作业的完整配置。
| |-- hyperparameters.json # 训练作业超参.
| |-- data # 作业的InputChannels: 以下目录包含了两个channel: train_data和test_data。
| |-- test_data
| | |-- test.csv
| |-- train_data
| |-- train.csv
|-- output # 作业的输出Channels: 这里有model/checkpoints两个输出channel。
|-- model # 通过环境变量PAI_OUTPUT_{OUTPUT_CHANNEL_NAME}可以获输出路径。
|-- checkpoints如何判断是否是GPU机器以及GPU卡数
任务启动后,可以通过环境变量NVIDIA_VISIBLE_DEVICES来判断当前机器是否具有GPU以及GPU卡数。例如:NVIDIA_VISIBLE_DEVICES=0,1,2,3表示当前机器具有4张GPU卡。