
服务部署完成后,您可以使用控制台的在线调试功能测试服务是否运行正常。它提供了图形化界面,无需编写任何代码即可直接发送测试请求并查看返回结果。
如何在线调试
进入在线调试页面。
登录PAI控制台,在页面上方选择目标地域,并在右侧选择目标工作空间,然后单击进入EAS。
在推理服务页签,找到您想测试的服务,单击目标服务操作列下的
 > 在线调试。
> 在线调试。
构造并发送请求 (关键步骤)。不同类型的模型,其API接口定义(尤其是URL路径和请求体格式)千差万别,请确保正确填写请求参数。一个标准的请求包含以下要素:
请求方法 (Method):通常为
POST、GET。请求路径(URL):在线调试已自动填充基础地址,需判断是否需要拼接具体的接口路径。路径错误是导致
404 Not Found的最常见原因。请求头 (Headers):
AuthorizationToken 通常会自动填充,无需修改。请求体 (Body):必须是符合接口要求、格式正确。格式错误是导致
400 Bad Request或500 Internal Server Error的主要原因。
使用示例
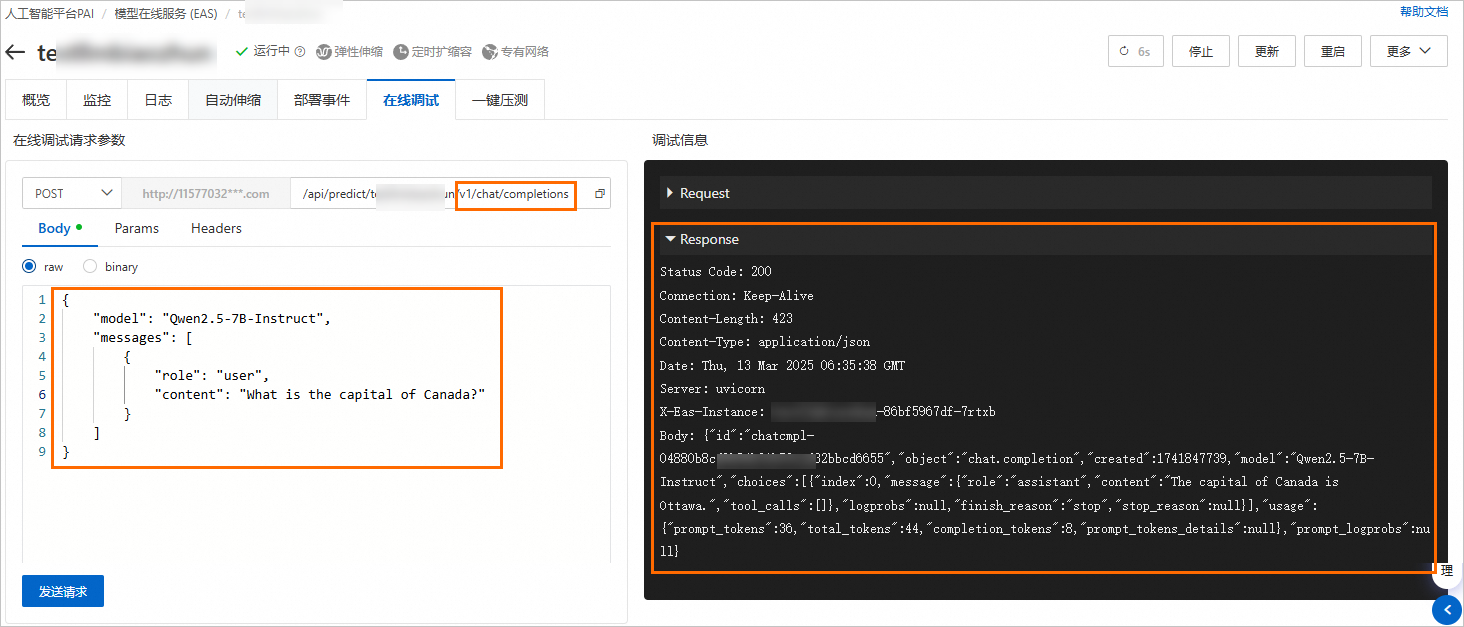
以vLLM部署的Qwen2.5-7B-Instruct模型服务为例,测试其对话接口,参数如下:
请求方式(Method):POST
请求路径(URL):
http://***********/v1/chat/completions(在线调试已自动填充的URL后需添加/v1/chat/completions)请求体(Body):
{ "model": "Qwen2.5-7B-Instruct", "messages": [ { "role": "user", "content": "What is the captial of Canada?" } ] }
结果如下:
常见问题
如何确定正确的URL和请求体?
这完全取决于您部署的模型,可参见典型场景的请求构造。
下一步
该文章对您有帮助吗?