
LLM-Copyright信息移除(DLC)组件主要用于删除文本中的Copyright信息,多用于去除代码文本中的头部Copyright注释。输入的OSS数据文件(JSONL格式,示例)需符合:每一行是一个合法的JSON对象,文件由多行JSON对象组成,整个文件本身不是合法的JSON对象。
支持的计算资源
算法说明
去除文本中的Copyright信息或者注释信息,分为以下两个步骤:
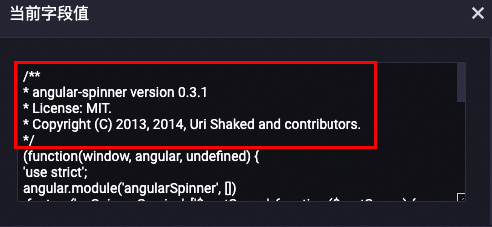
首先检测文本中是否有符合正则表达式
'/\\*[^*]*\\*+(?:[^/*][^*]*\\*+)*/'(注释字符)的字符串。如果匹配到对应字符串,则检测字符串中是否包含
copyright字段,如果包含,则删除整段字符串并返回;否则不做删除,直接返回。如果匹配不到该正则表达式,则进入步骤2继续处理。
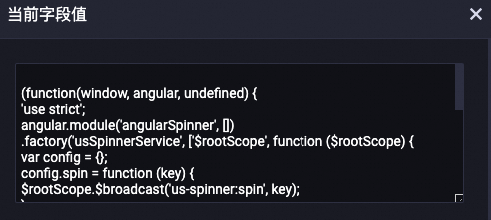
将文本用换行符分隔,按行遍历文本是否以
//、#、--注释符号开头,一旦匹配到符合条件的某行,继续统计连续的注释行,直到注释符号终止,则遍历终止。最后删除文本中的连续注释片段并返回。
以上步骤均检测第一次匹配到的注释片段,即默认检测文本的头部,剩余部分不做处理。例如:
处理前
| 处理后
|
配置组件
在Designer工作流页面添加LLM-Copyright信息移除(DLC)组件,并在界面右侧配置相关参数:
参数类型 | 参数 | 是否必选 | 描述 | 默认值 | |
字段设置 | 目标处理字段 | 是 | 要处理的字段名称。 | 无 | |
数据输出OSS目录 | 否 | 处理后数据的OSS存储目录。如果为空,使用工作空间默认路径。 | 无 | ||
执行调优 | 多进程个数 | 否 | 设置进程数。 | 8 | |
选择资源组 | 公共资源组 | 否 | 选择节点规格(CPU或GPU实例规格)、节点数量、专有网络。 | 无 | |
专有资源组 | 否 | 选择CPU核数、内存、共享内存、GPU卡数、节点数量。 | 无 | ||
最大运行时长 | 否 | 组件最大运行时长,超过这个时间,作业会被kill。 | 无 | ||
该文章对您有帮助吗?