本文为您介绍如何使用Kohya训练LoRA模型。
点击登录PAI ArtLab控制台。
背景信息
Stable Diffusion(SD)是一个开源的深度学习文生图模型。SD WebUI是SD的可视化界面,支持网页端文生图、图生图操作,并通过插件和模型导入实现高度定制化。
使用SD WebUI生成图片需要使用多种模型,不同模型有各自的特色与适用领域,需要针对性地采用不同的训练数据集及训练策略进行培养。其中,LoRA是一种轻量化的模型微调方法,速度较快,文件大小适中,对配置要求低。
Kohya是广泛应用的LoRA模型训练开源服务,Kohya's GUI程序包提供了训练环境和模型训练的用户界面,避免与其他程序干扰。SD WebUI也支持通过插件进行模型训练,但可能会产生干扰,导致报错 。
其他模型微调方法请参见PAI ArtLab 模型使用说明。
LoRA模型介绍
LoRA(Low-Rank Adaptation of Large Language Models)可以基于基础模型通过对数据集的训练,得到一个风格化的模型,从而实现高度定制化的图像生成效果。
文件规格如下:
-
文件大小:通常为个位到百级MB,具体大小取决于受训练参数与基础模型的复杂度。
-
文件格式:采用.safetensors作为标准后缀。
-
文件应用:需与特定的Checkpoint基础模型结合使用。
-
文件版本:需要明确区分Stable Diffusion v1.5与Stable Diffusion XL版本,各版本间模型不通用。
LoRA微调模型
如果将基础模型(如Stable Diffusion v1.5 Model、v2.1 Model或Stable Diffusion XL base 1.0 Model等)视作基础原生态的自然食材,那么LoRA模型则是某种特殊风味的调味料,旨在为这些食材赋予独特的风味与创新。为了使料理具备多样性和创新性,LoRA模型作为关键的创新催化剂,可以突破基础模型在创造过程中遭遇的局限性,使内容创作更加灵活高效,个性十足。
以Stable Diffusion v1.5模型为例,其局限性包括:
-
生成内容细节精准度缺失:在生成特定细节或复杂内容时,可能难以精准复现所有细节,导致生成图像缺乏细节或不够逼真。
-
生成内容逻辑性构建不足:生成图像中的物体布局、尺寸比例及光影逻辑可能不符合现实规律。
-
生成内容风格不一致:高度复杂且随机的生成过程,使得维持特定风格或执行风格转移时,难以确保风格的统一与连贯。
当前模型生态社区已有众多优秀的微调模型,此类模型均基于基础模型微调训练产生。相较于原始基础模型,生成图像细节更丰富,风格特征也更加鲜明,且生成内容更加可控。例如,下图展示了Stable Diffusion v1.5模型和微调模型生成图像效果对比,可以直观感受到图像生成质量的显著提升。

LoRA模型的不同类型
-
LyCORIS(LoHa/LoCon的前身)
LyCORIS作为LoRA的增强版,能够对26层的神经网络进行精细调整,相比LoRA仅支持17层的微调,在性能上显著提升。因此,相较于LoRA,LyCORIS表现力更强,有更多的参数,可以承载更多的信息量。LyCORIS的核心优势在于LoHa与LoCon。其中,LoCon专注于针对SD模型的每一层级进行调整,而LoHa则在原基础上实现双倍数据信息量。
用法和LoRA相同,进阶用法可以通过调整文本编码的权重、Unet的权重和DyLoRa的权重实现。
-
LoCon
LoRA(Conventional LoRA)只调整了cross-attention layers,LoCon用同样的方法调整了ResNet矩阵。目前LoCon已经被LyCORIS合并,过去扩展的LoCon已经不再需要。更多信息,参见 LoCon-LoRA for Convolution Network。
-
LoHa
LoHa(LoRA with Hadamard Product)用Hadamard Product替换了原方法中的矩阵点乘,理论上在相同的情况下能容纳更多信息。更多信息,请参见FedPara Low-Rank Hadamard Product For Communication-Efficient Federated Learning。
-
DyLoRA
LoRA的rank并非越高越好,其最优值需依据具体模型、数据集特性和所执行任务共同决定。DyLoRA能够在指定维度(rank)下灵活探索并学习多种rank的LoRA配置,简化了寻找最适rank的复杂度,从而提升了模型调优的效率与精准度。
准备数据集
确定LoRA类型
首先您需要确定希望训练的LoRA模型的类型,比如是角色类型还是风格类型。
例如,需要训练一个阿里云进化设计语言体系下的阿里云3D产品图标风格的风格模型。
数据集内容要求
数据集由图片和图片对应的文本描述标注两种文件组成。
准备数据集内容:图片
-
图片要求
-
数量:15张以上。
-
质量:分辨率适中,画质清晰。
-
风格:需要一套风格统一的图片内容。
-
内容:图片需凸显要训练的主体物形象,不宜有复杂背景以及其他无关的内容,尤其是文字。
-
尺寸:分辨率是64的倍数,范围为512~768。显存低可以裁剪为512*512,显存高可以裁剪为768*768。
-
-
图片预处理
-
质量调整:图片分辨率适中,保证画质清晰即可。如果图片分辨率较小,可以使用SD WebUI中Extras或图像处理工具进行分辨率放大。
-
尺寸调整:可以使用批量裁剪工具进行裁剪。
-
-
图片部分准备完毕示例

将图片存放至本地文件夹中。

创建数据集并上传文件
上传前需要注意文件的属性和命名要求,如果只是用平台管理数据集文件或者给图片打标,直接上传文件或文件夹都可以,对这些文件和文件夹的命名没有特殊要求。
如果数据集打标完之后,需要用平台的Kohya做LoRA模型训练,对于上传的文件属性和命名要求如下。
-
命名格式:数字+下划线+任意名称
-
命名含义:自定义。
-
数字:每张图片重复训练次数,一般要求≥100。总训练次数一般要求>1500,因此若文件夹内包含10张图片,则每张图片训练1500/10=150次,图片文件夹名数字部分可为150;若文件夹内包含20张图片,则每张图片训练1500/20=75(<100)次,图片文件夹名数字部分可为100。
-
任意名称:本文以100_ACD3DICON为例,您可以根据实际情况自定义。
-
登录PAI ArtLab,选择Kohya(专享版),进入Kohya-SS页面。
-
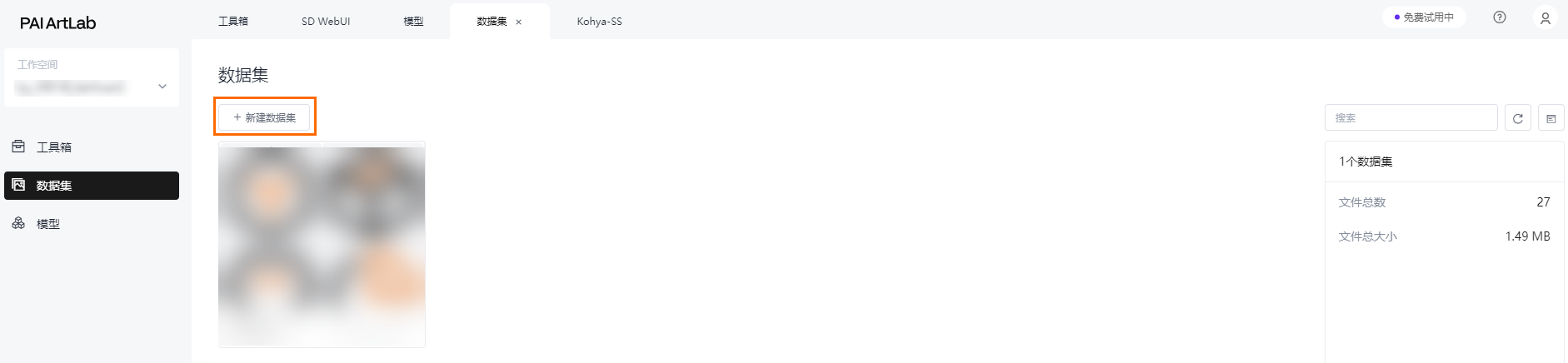
创建数据集
在数据集页面,单击新建数据集,并输入数据集名称,此处以acd3dicon为例。
-
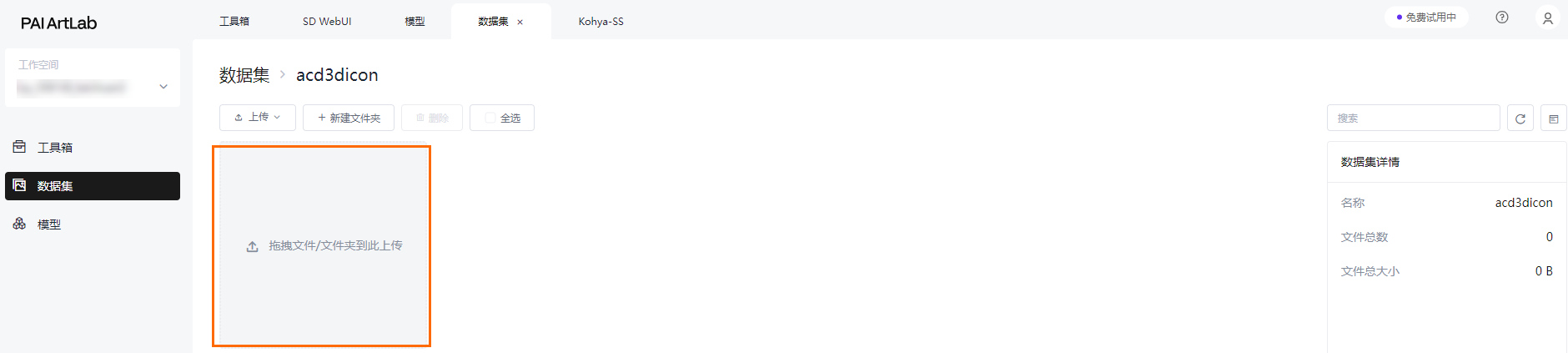
上传数据集文件
单击已创建的数据集,将整理好的数据集图片文件夹从本地拖拽上传。

上传成功。
-
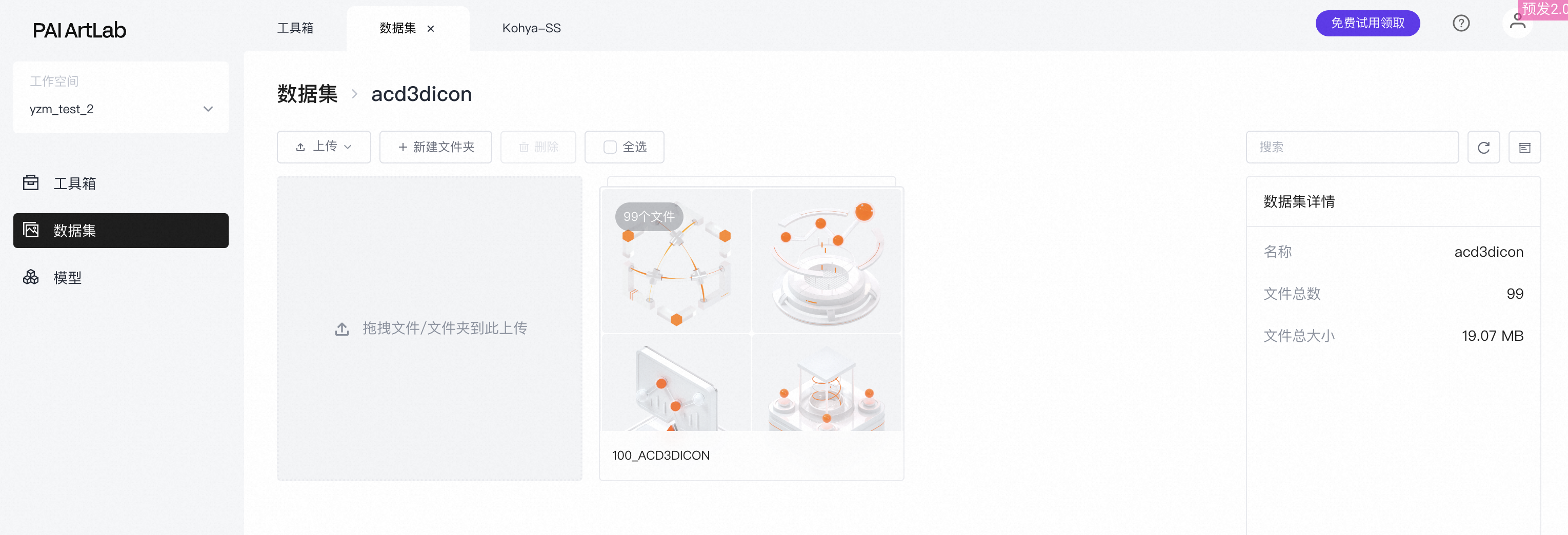
进入到文件夹里可以查看到已上传的图片。
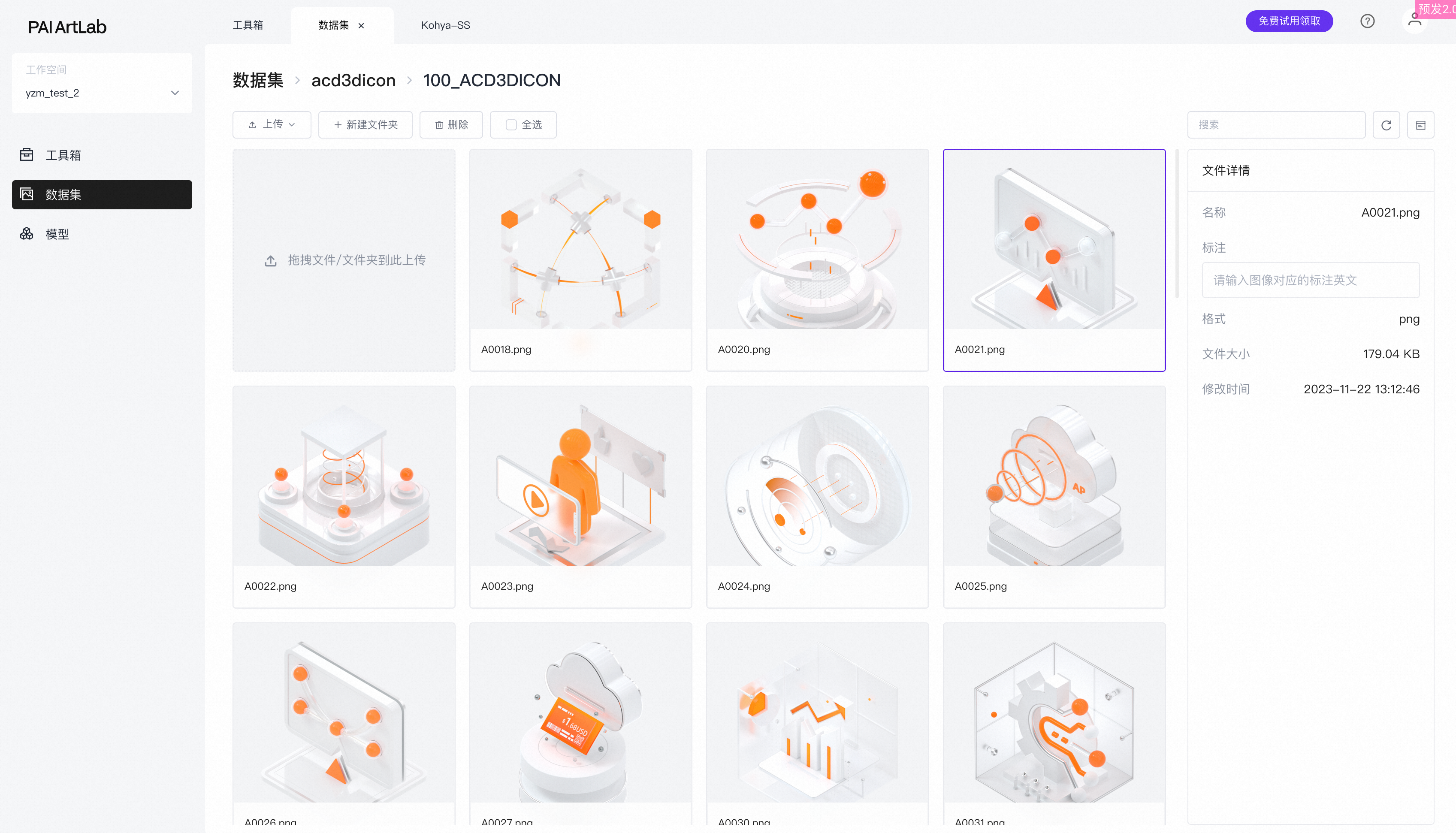
准备数据集内容:图片标注
图片标注是指每张图片对应的文字描述,文字描述的标注文件,是与图片同名的TXT格式的文件。
-
图片标注要求
B端元素通常具备清晰的结构布局、规范的透视效果及特定的光影,因此在进行标注处理时,需要区别于人像、风景等类型的数据集图像处理方法。建议采取基础的描绘打标,集中关注并标注元素的顶层、中层及底部的简单几何形态,如“球形”、“立方体”等。
分类
关键词
业务
产品/业务
数据库、云安全、计算平台、容器、云原生等(英文)
云计算元素
Data processing、Storage、Computing、Cloud computing、Elastic computing、Distributed storage、Cloud database、Virtualization、Containerization、Cloud security、Cloud architecture、Cloud services、Server、Load balancing、Automated management、Scalability、Disaster recovery、High availability、Cloud monitoring、Cloud billing
设计(质感)
环境&构图
viewfinder、isometric、hdri environment、white background、negative space
材质
glossy texture、matte texture、metallic texture、glass texture、frosted glass texture
照明
studio lighting、soft lighting
色彩
alibaba cloud orange、white、black、gradient orange、transparent、silver
情绪
rational、orderly、energetic、vibrant
质量
UHD、accurate、high details、best quality、1080P、16k、8k
设计(氛围)
...
...
-
示例一:针对3D图标画面打标的信息维度的拆分。
-
示例二:针对紫砂壶物品打标的信息维度的拆分。
-
-
给图片添加标注
您可以手动为每张图片添加对应的文字描述,但当图片数量非常大时,手动打标非常耗时耗力,此时您可以选择借助神经网络,完成对所有图片批量生成文本描述的工作,或者在Kohya中选择使用BLIP的图像打标模型,搭配手动微调,满足您的业务需求。

打标数据集
-
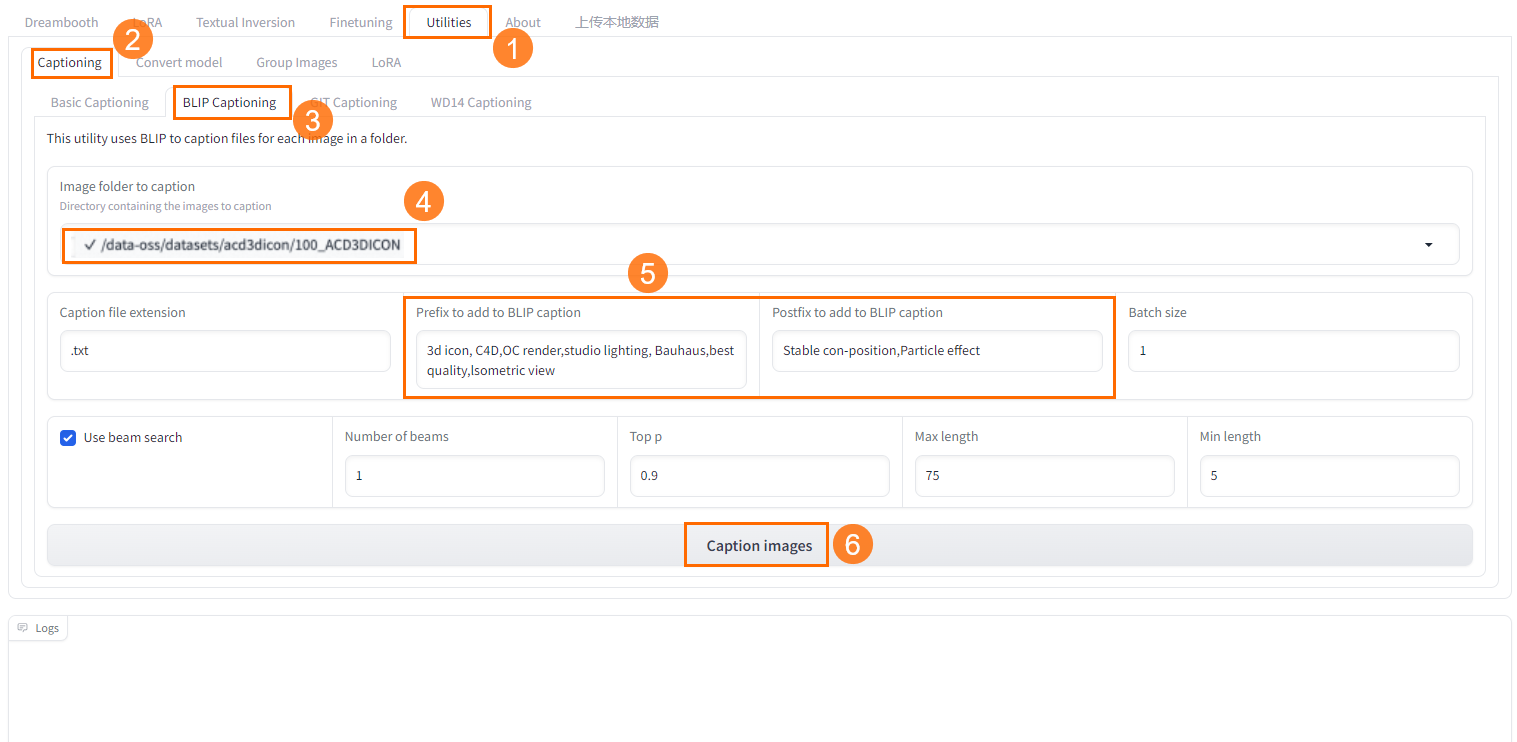
在Kohya-SS页面,选择Utilities>Captioning>BLIP Captioning。
-
选择已创建的数据集中上传的图片文件夹。
-
输入一些预置词,让机器给每一张图片都批量加上您输入的标注文本。您可以结合自己对数据集图片拆分的维度去添加预置词,不同类型的图片打标的维度也不同。
-
单击Caption Image即可开始打标。
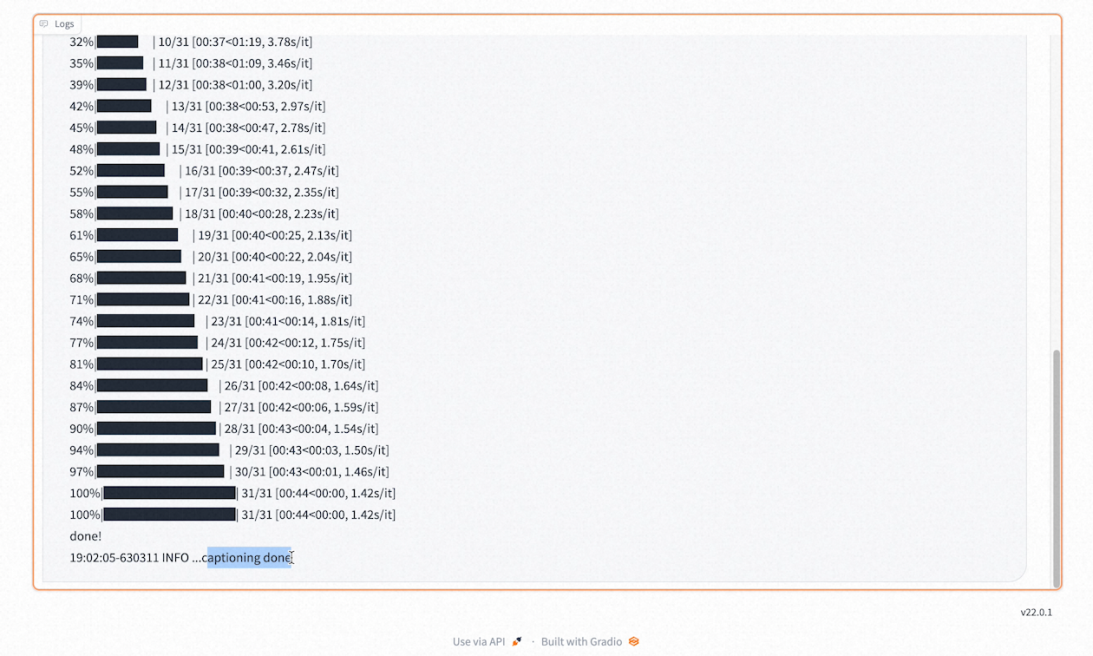
-
在下方的日志里可以查看打标的进度和打标完成的提示。
-
返回数据集,可以看到刚才上传的图片已经有对应的标注文件。
-
(可选)对于不合适的标注,可以手动修改。
训练LoRA模型
-
在Kohya-SS页面,选择LoRA(LoRA)>Training(训练)>Source Model(模型来源)。
-
配置以下参数:
-
Model Quick Pick(快速选择模型):runwayml/stable-diffusion-v1-5
-
Save trained model as(保存训练模型为):safetensors
说明如果Model Quick Pick(快速选择模型)下拉选择中没有自己想要的模型,可以选择custom之后再选择模型。从模型广场添加到我的模型的底模以及本地上传到我的模型的底模,在custom路径里可以找到。
-
-
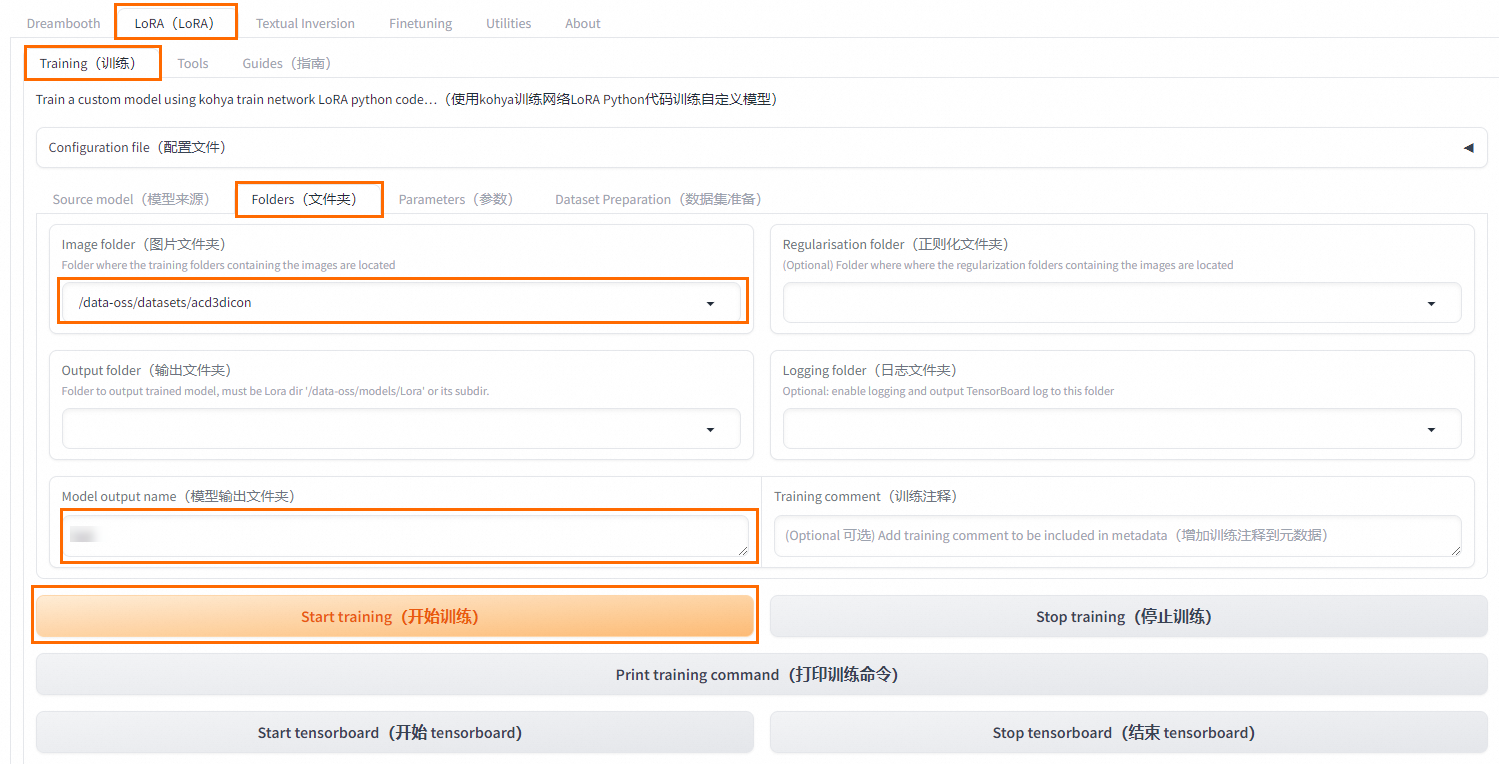
在Kohya-SS页面,选择LoRA(LoRA)>Training(训练)>Folders(文件夹)。
-
选择已上传了数据集文件夹的数据集,并配置训练参数。
说明数据集文件打标时,要选到数据集下面图片的文件夹;做模型训练时,要选择放置数据集文件夹的数据集。
-
单击Start training,开始训练。
更多参数信息,请参见常用训练参数介绍说明。
-
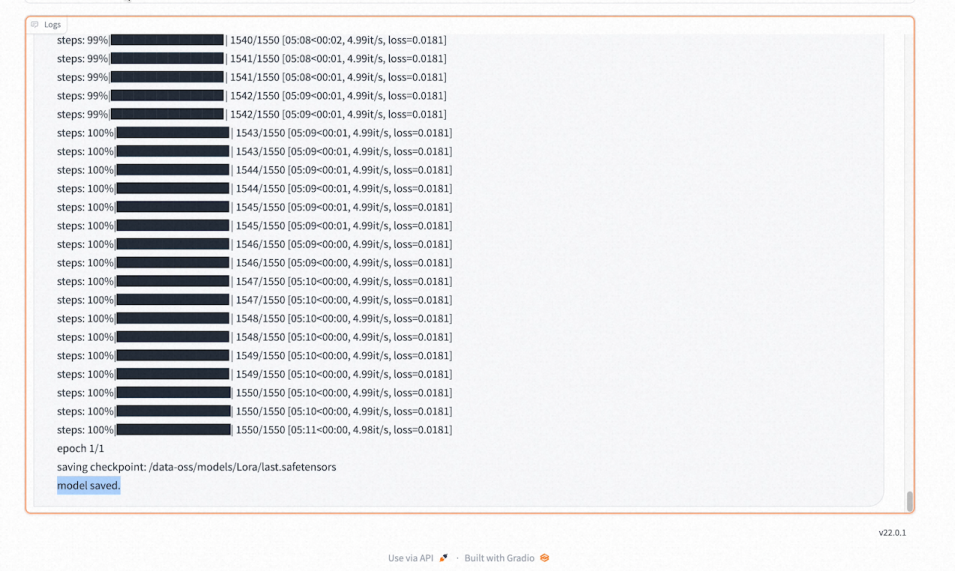
在下方的日志里可以查看模型训练进度和模型训练完成的提示。
常用训练参数介绍说明
参数介绍
图片数量*repeat数量*设置的epoch/batch_size=模型训练总步数
例如,10张图*20步*10个循环/2并行数=1000步。
在Kohya-SS页面,选择LoRA(LoRA)>Training(训练)>Parameters(参数),即可配置模型训练参数,常用参数说明如下:
-
Basic(基础)页签
参数
功能
设置说明
repeat
读取图像次数
在文件夹命名时设置读取图像的次数,次数越多学习效果越好。初期训练时建议设置如下:
-
二次元:7~15
-
人像:20~30
-
实物:30~100
LoRA type
选择LoRA类型
保持默认选择Standard。
LoRA network weights
LoRA网络权重
选填。如果要接着训练则选用最后训练的LoRA。
Train batch size
训练批量大小
根据显卡性能选择。12G显存最大为2,8G显存最大为1。
Epoch
训练轮数,将所有数据训练一次为一轮
自行计算。一般:
-
Kohya中总训练次数=训练图片数量x重复次数x训练轮数/训练批量大小
-
WebUI中总训练次数=训练图片数量x重复次数
使用类别图像时,在Kohya或在WebUI中总训练次数都会乘2;在Kohya中模型存储次数会减半。
Save every N epochs
每N个训练周期保存一次结果
如设为2,则每完成2轮训练保存一次训练结果。
Caption Extension
打标文件扩展名
选填。 训练图集中注解/提示文件的格式为.txt。
如图:
Mixed precision
混合精度
根据显卡性能决定。取值如下:
-
no
-
fp16(默认)
-
bf16(RTX30以上显卡可选bf16)
Save precision
保存精度
根据显卡性能决定。取值如下:
-
no
-
fp16(默认)
-
bf16(RTX30以上显卡可选bf16)
Number of CPU threads per core
CPU每核线程数
主要根据CPU性能,根据所购实例和需求调整,保持默认即可。
Seed
随机数种子
可以用于生图验证。
Cache latents
缓存潜变量
默认开启,训练后图像信息会缓存为latens文件。
LR Scheduler
学习率调度器
理论上没有最佳学习点,为了能够找到一个最佳的假设值,一般可以使用cosine(余弦函数)。
Optimizer
优化器
默认AdamW8bit。如果基于sd1.5的基础模型训练,保持默认值即可。
Learning rate
学习率
初期训练时,建议设置学习率为0.01~0.001。默认值为0.0001。
可以根据损失函数(loss)调整学习率:当loss值偏高时,可以适度提升学习率;若loss值较低,可以逐步减少学习率有助于精细调优模型。
-
高学习率加速训练但可能因学习粗糙引发过拟合,即模型对训练数据过度适应而泛化能力差。
-
低学习率虽能细致学习,减少过拟合,但可能导致训练时间长和欠拟合,即模型简化而未能把握数据特性。
LR Warmup(% of steps)
学习率预热(%的步数)
默认值为10。
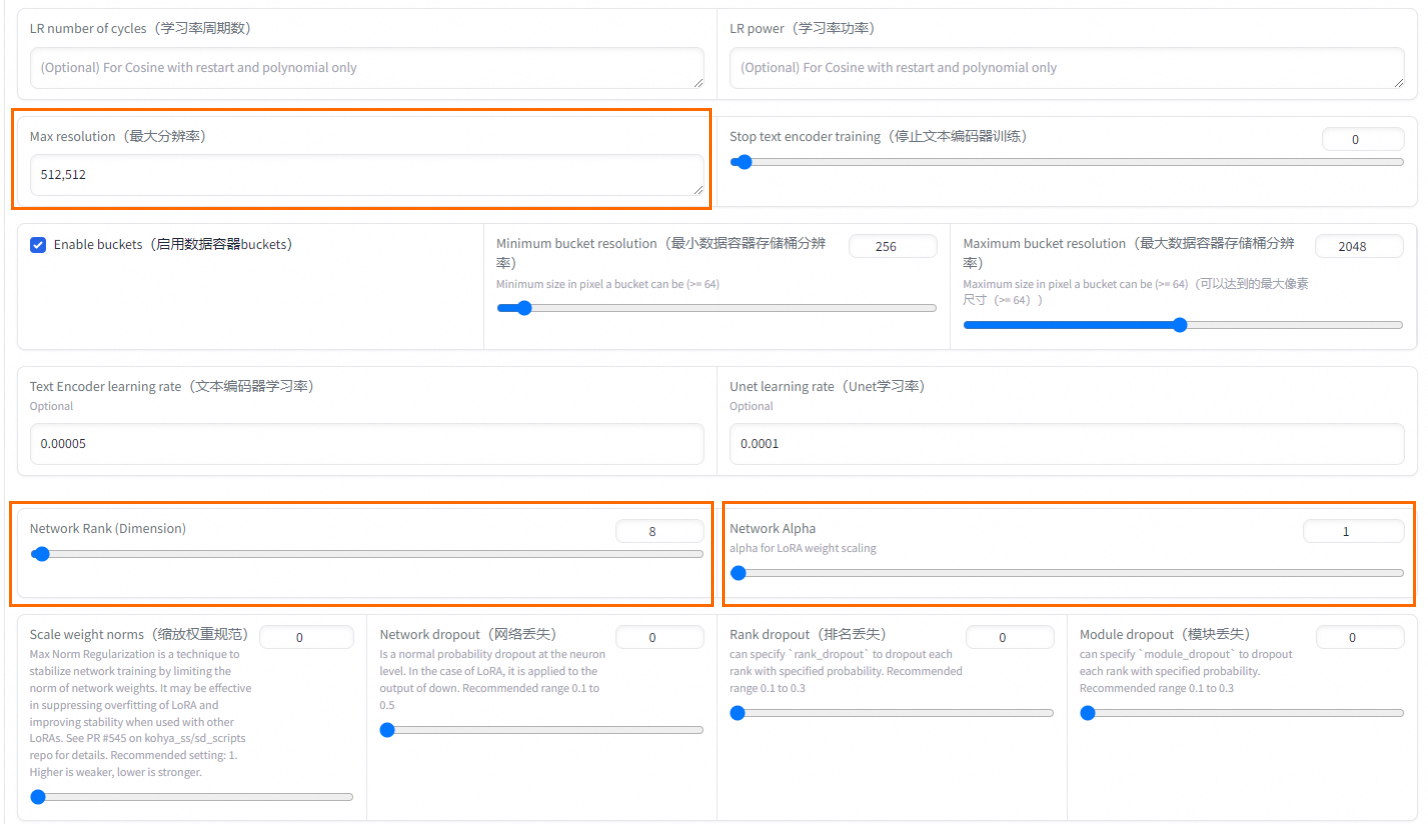
Max Resolution
最大分辨率
根据图片情况设置。默认值为512,512。
Network Rank (Dimension)
模型复杂度
一般设置为64即可适应大部分场景。
Network Alpha
网络Alpha
建议可以设置较小值,Rank和Alpha设置会影响最终输出LoRA的大小。
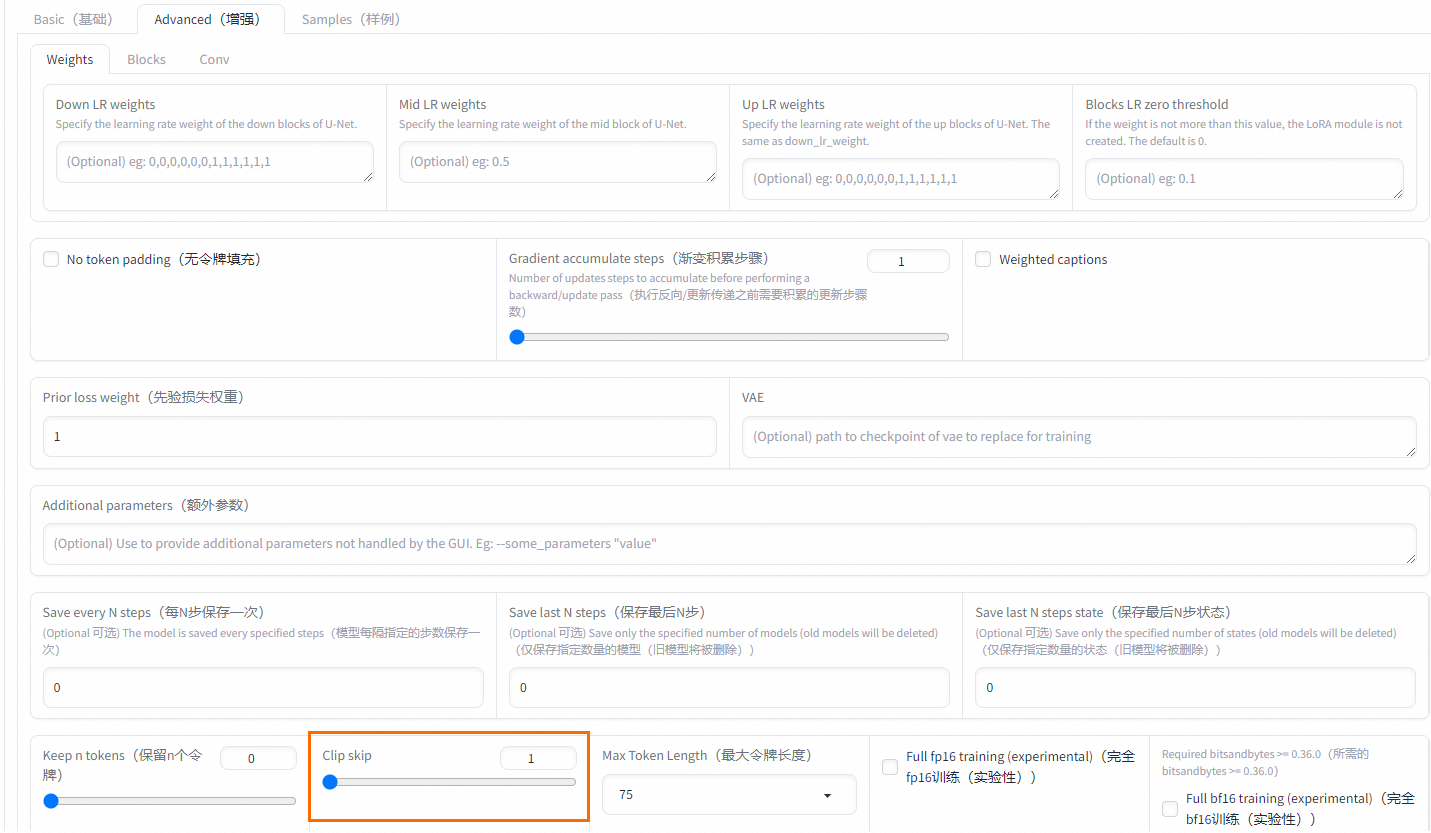
Clip skip
文本编码器跳过层数
二次元选2,写实模型选1,动漫模型训练最初就有跳过一层,如使用训练素材也是二次元图像,再跳一层=2。
Sample every n epochs
每n个训练周期采样一次
每几轮保存一次样本。
Sample prompts
样本提示
提示词样本。需要使用命令,参数如下:
-
--n:反向提示词。
-
--w:图片宽度。
-
--h:图片高度。
-
--d:图像种子。
-
--l:提示词相关性(cfg比例)。
-
--s:迭代步数(steps)。
-
-
Advanced(增强)页签
参数
功能
设置说明
Clip skip
文本编码器跳过层数
二次元选2,写实模型选1,动漫模型训练最初就有跳过一层,如使用训练素材也是二次元图像,再跳一层=2。
-
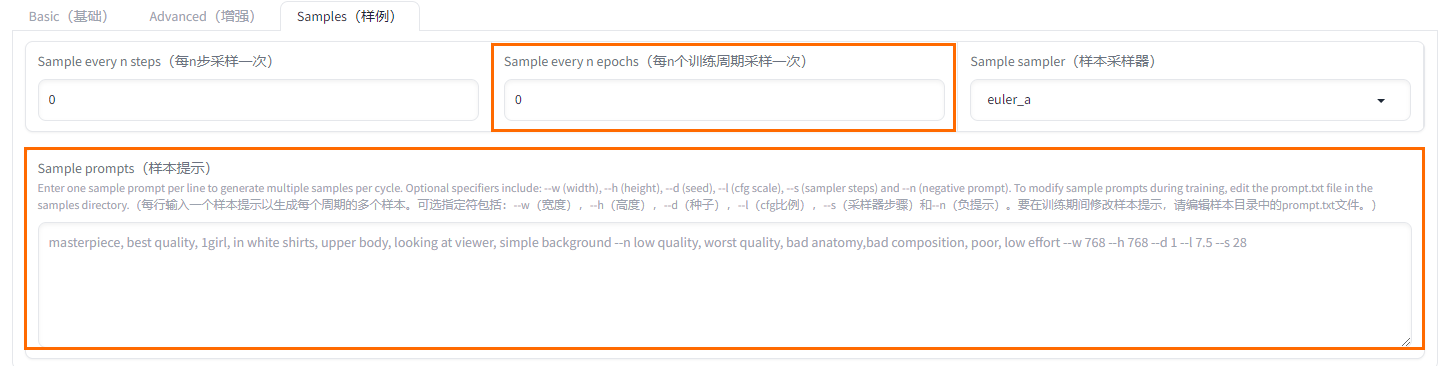
Samples(样例)页签
参数
功能
设置说明
Sample every N epochs
每N个训练周期采样一次
每几轮保存一次样本。
Sample prompts
样本提示
提示词样本。需要使用命令,参数如下:
-
--n:反向提示词。
-
--w:图片宽度。
-
--h:图片高度。
-
--d:图像种子。
-
--l:提示词相关性(cfg比例)。
-
--s:迭代步数(steps)。
-
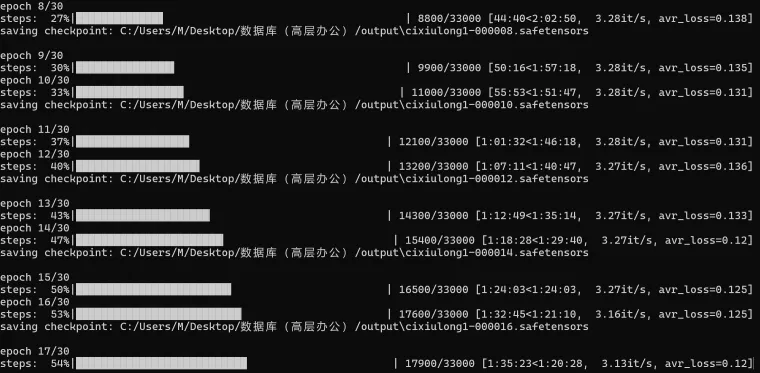
Loss值介绍
在微调模型训练过程中(LoRA),Loss值可以算是一个比较重要的衡量模型优劣的指标。理想状况下,随着训练的进程,Loss值应呈现逐渐下降的趋势,这代表训练过程机器正在有效学习并逐渐去贴合用户提供的训练数据。一般Loss值维持在0.08至0.1之间,表明模型训练的结果较好,Loss值为0.08时,模型训练的结果比较理想。
可以说LoRA学习就是Loss值从高到低的过程。假设训练周期Epoch为30,如果目标是获取Loss值位于0.09至0.07区间的模型,则有望在第20至24个Epoch之间实现这一目标。这样设置可以避免因训练轮次过少而导致的Loss快速骤降。例如,仅经历两轮训练Loss就从0.1骤减至0.06,可能会错过期望的Loss区间。