Model Gallery预置了多种LLM预训练模型。本文为您介绍如何在Model Gallery中,通过模型评测功能全方位评估模型能力查找适合您业务需求的大语言模型。
简介
模型评测功能支持从两个维度对大语言模型进行评测:基于自定义数据集和公开数据集评测。
基于自定义数据集的评测包括:
基于规则的评测,用ROUGE和BLEU系列指标计算模型预测结果和真实结果之间的差距;
基于裁判员模型的评测,基于PAI提供的裁判员模型,对问答对【问题-模型输出】逐条打分,并统计得分情况,用于评价模型性能;
基于公开数据集的评测是通过在多种公开数据集上加载并执行模型预测,根据每个数据集特定的评价框架,为您提供行业标准的评估参考。
当前模型评测支持HuggingFace所有AutoModelForCausalLM类型的模型。
最新特性:
现已支持裁判员模型打分,使用基于Qwen2定制的大模型作为裁判员,对被评估模型的生成结果进行打分,适用于开放性、复杂问答场景。限时免费中,欢迎在模型评测-专家模式中试用。[2024.09.01]
使用场景
模型评测是模型开发中重要的环节,您可以结合实际业务挖掘模型评测应用。例如在以下场景中使用模型评测功能:
模型基准测试,基于公开数据集对模型通用能力进行评估,并与业界模型或基准进行对比;
领域能力评估,将模型应用到特定领域,比较不同领域内预训练和微调后的模型效果,以评估模型应用领域知识的能力;
模型回归测试,您可以构建回归测试集,通过模型评测功能来评估模型在实际业务场景下的表现,是否满足上线标准。
前提条件
如果您需要对模型进行评测,则需要创建OSS Bucket存储空间。具体操作请参见控制台快速入门。
计费说明
使用模型评测时需要收取OSS存储费用和DLC的评测任务费用,计费详情参见OSS计费概述和分布式训练(DLC)计费说明。
数据准备
模型评测功能支持基于自定义数据集和公开数据集(例如C-Eval)完成评测。
公开数据集:已经由PAI上传并维护,可以直接使用。
目前PAI维护了MMLU、TriviaQA、HellaSwag、GSM8K、C-Eval、TruthfulQA,其他公开数据集陆续接入中。
自定义数据集:如果需要基于自定义评测文件,需要提供JSONL格式的评测文件,可自行上传至OSS,并创建自定义数据集,详情参见上传OSS文件和创建及管理数据集。文件格式如下:
使用
question标识问题列,answer标识答案列,也可以在评测页面选择指定列。如果仅需要自定义数据集-裁判员模型评测,则answer列选填。{"question": "中国发明了造纸术,是否正确?", "answer": "正确"} {"question": "中国发明了火药,是否正确?", "answer": "正确"}文件示例:eval.jsonl
操作流程
选定模型
查找模型的具体操作步骤如下:
进入Model Gallery页面。
登录PAI控制台。
在左侧导航栏单击工作空间列表,在工作空间列表页面中单击待操作的工作空间名称,进入对应工作空间内。
在左侧导航栏选择快速开始 > Model Gallery,进入Model Gallery页面。
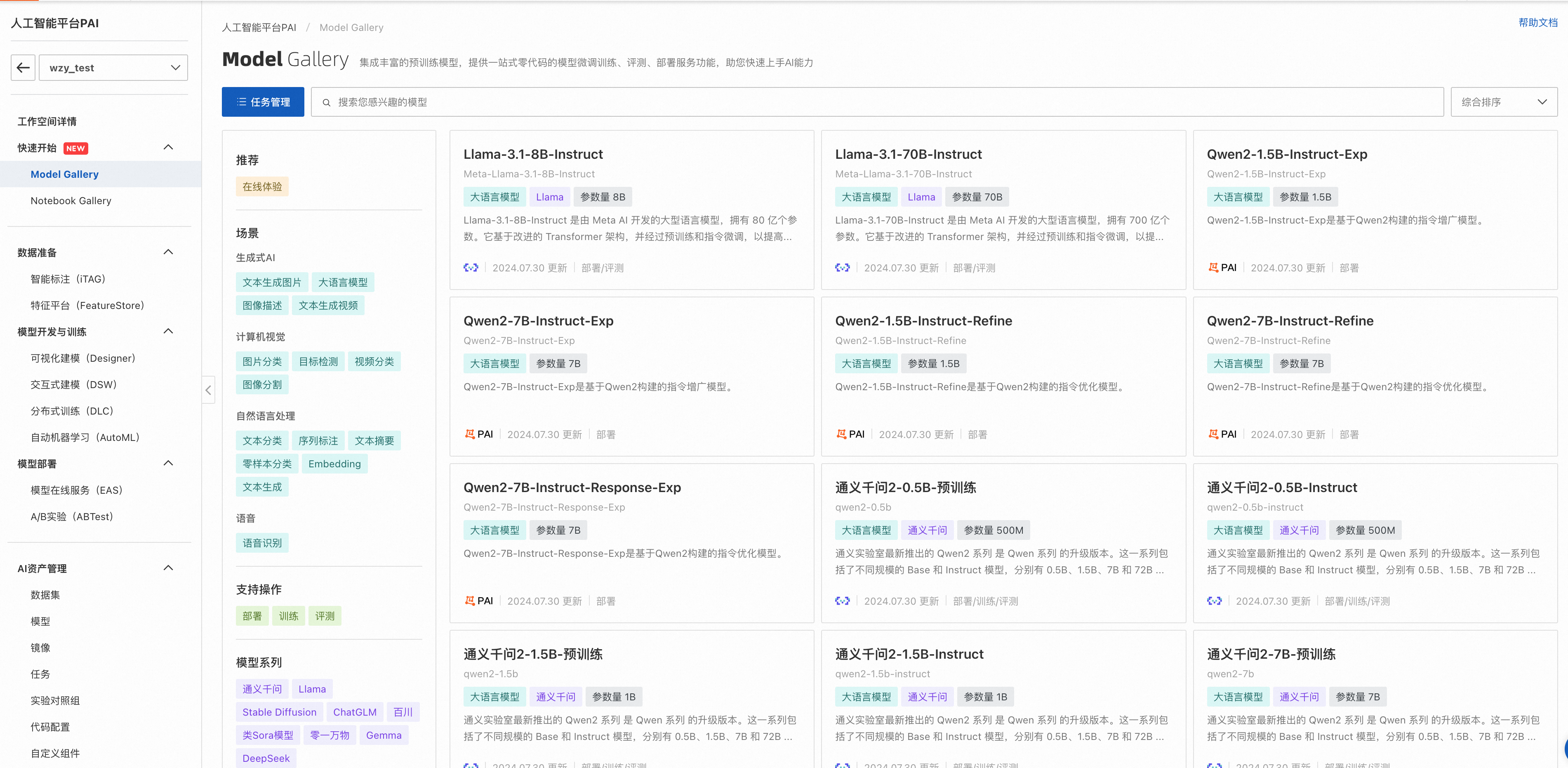
查找适合业务的模型。
在模型列表中,根据模型描述信息进行查看,对于可评测的模型,会展示评测按钮。
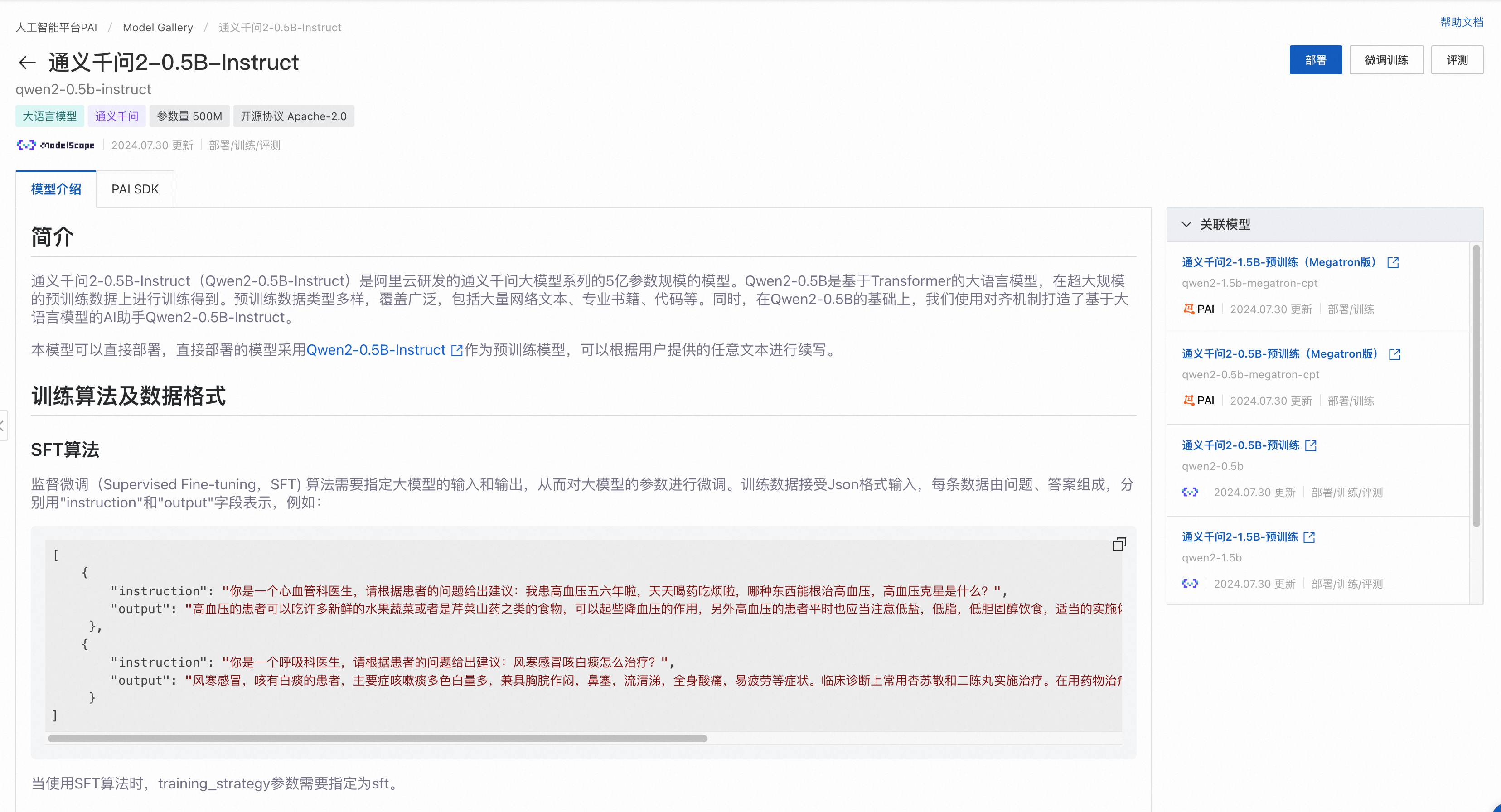
点击左上角任务管理,打开训练任务列表页,点击进入LLM训练任务详情页,对于支持评测的模型,基于其二次训练的模型也支持评测:

评测模型
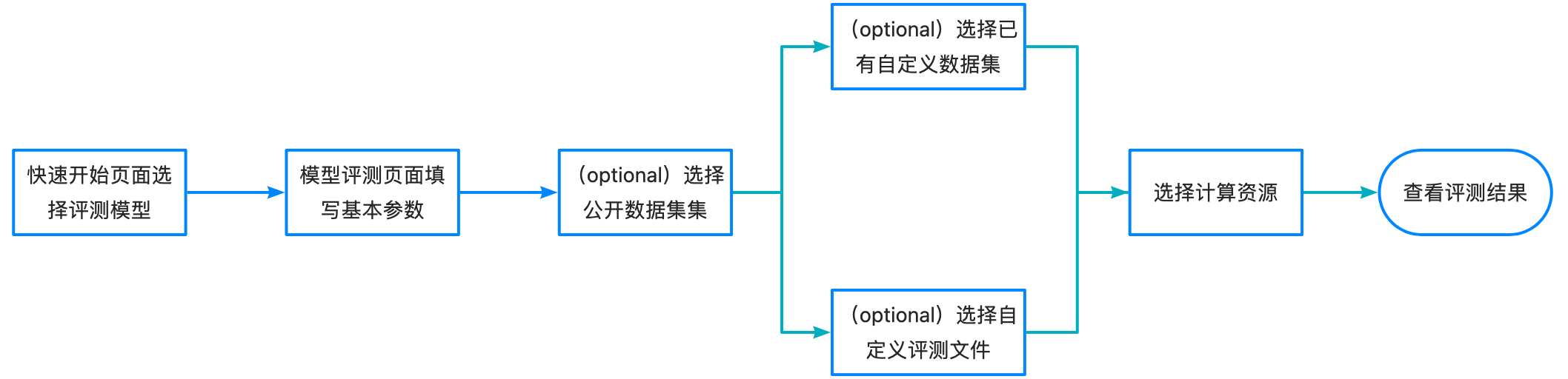
模型评测具有两种模式,极简模式和专家模式。
极简模式
可直接选择公开评测集或者已创建好的自定义数据集,快速使用模型评测功能(如需裁判员评测,请切换到专家模式)。
![]()
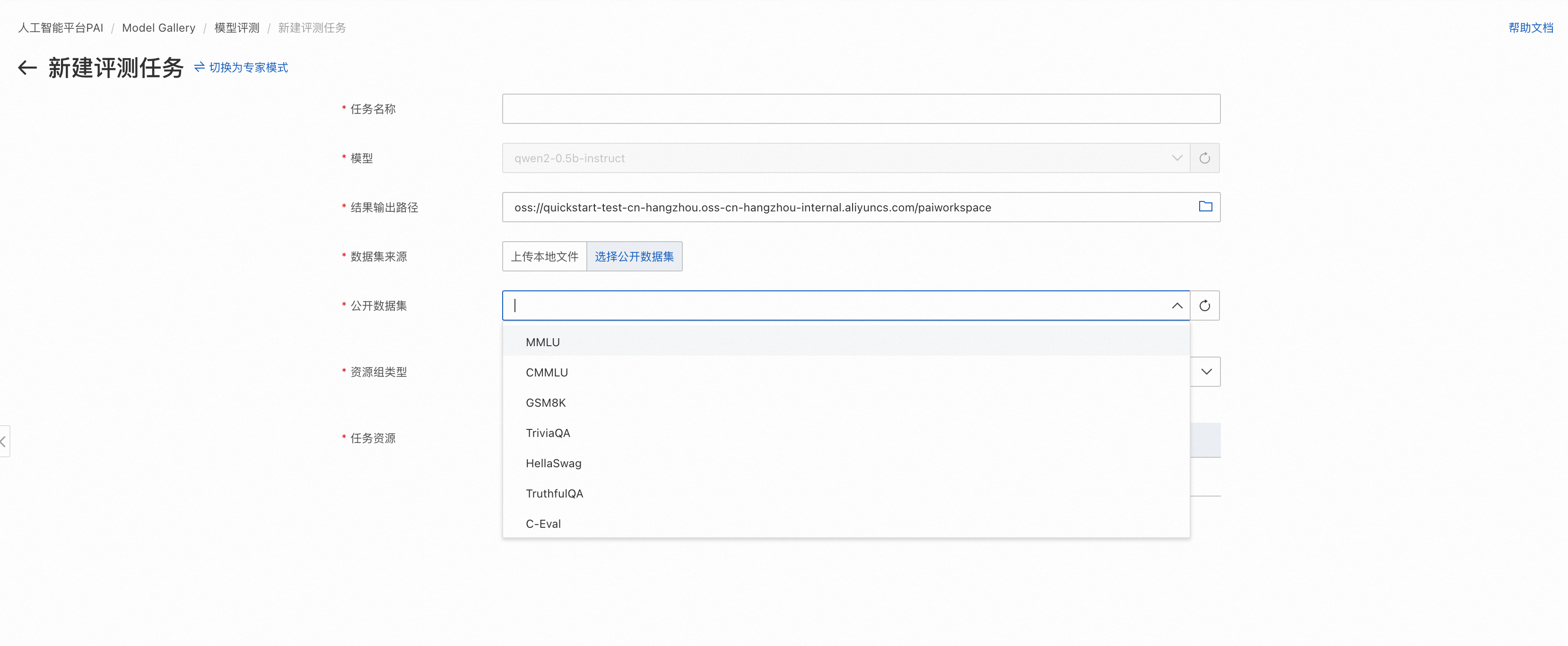
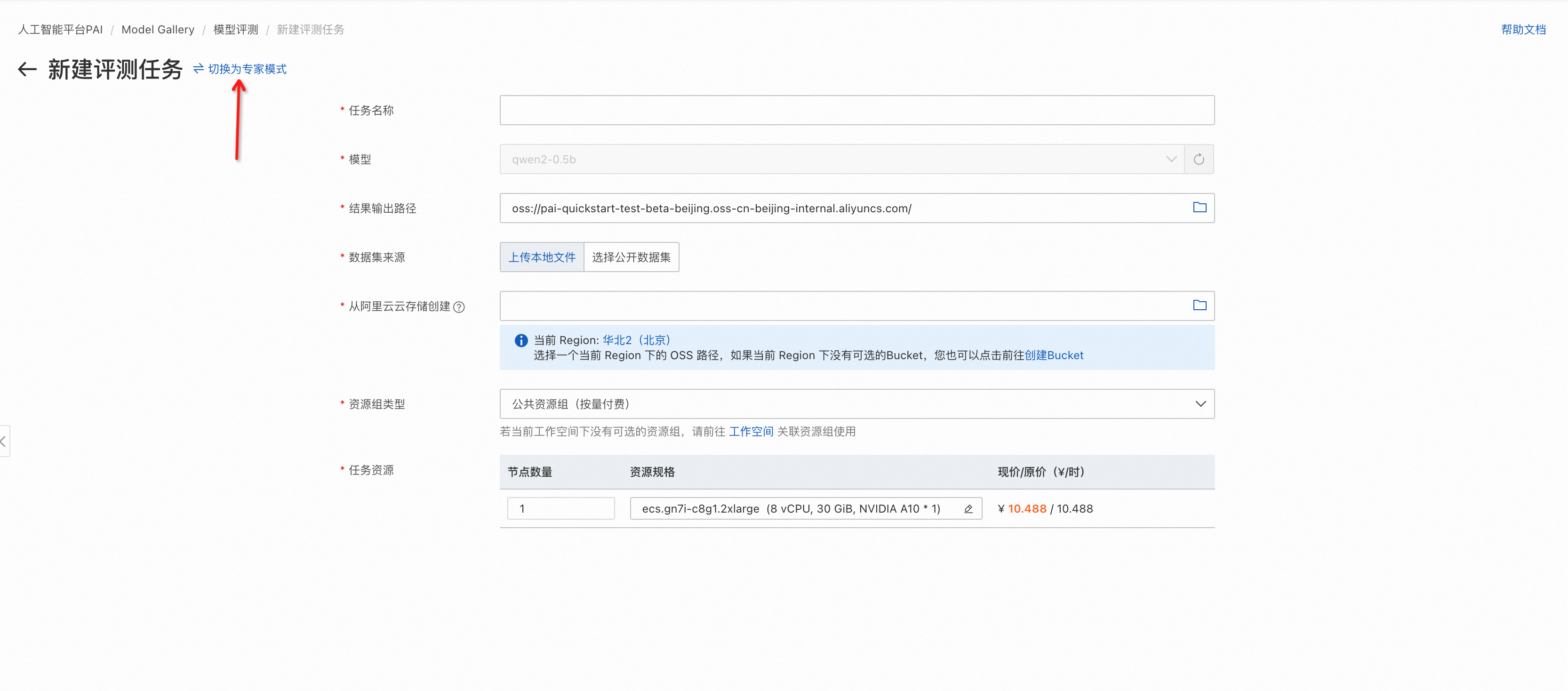
模型评测页面填写评测任务名。
填写评测结果存储路径。选择评测结果输出路径时,请保证路径仅被该评测任务使用,否则会导致不同评测任务间结果的互相覆盖。

选择评测数据集。数据集可选择自定义数据集和PAI提供的公开数据集,其中自定义数据集需要满足数据准备章节中的格式要求。
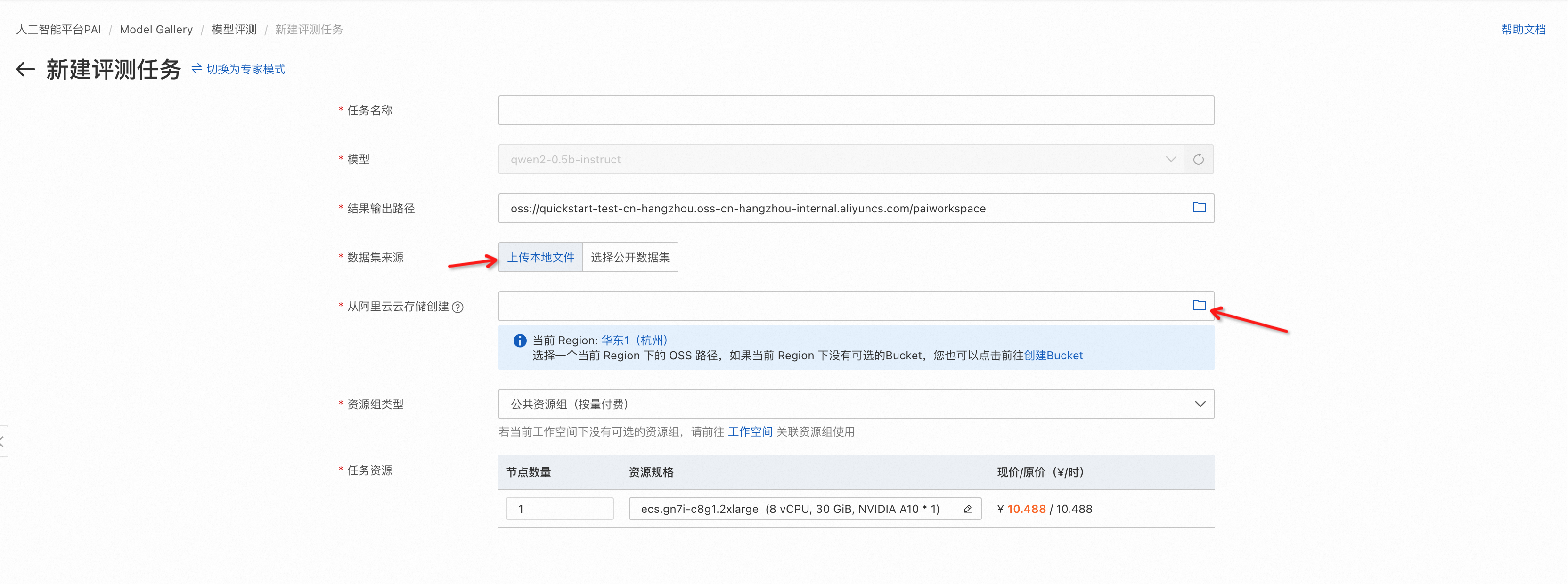
选择计算资源,需要GPU类型计算资源(推荐选择A10或者V100),在左下角提交评测任务,提交成功后自动跳转到评测任务详情页,等待任务成功,查看评测报告。
专家模式
支持同时选择公开数据集和自定义数据集完成评测,支持设置超参数,支持裁判员模型评测,支持选择多个公开数据集。
左上角选项切换到专家模式
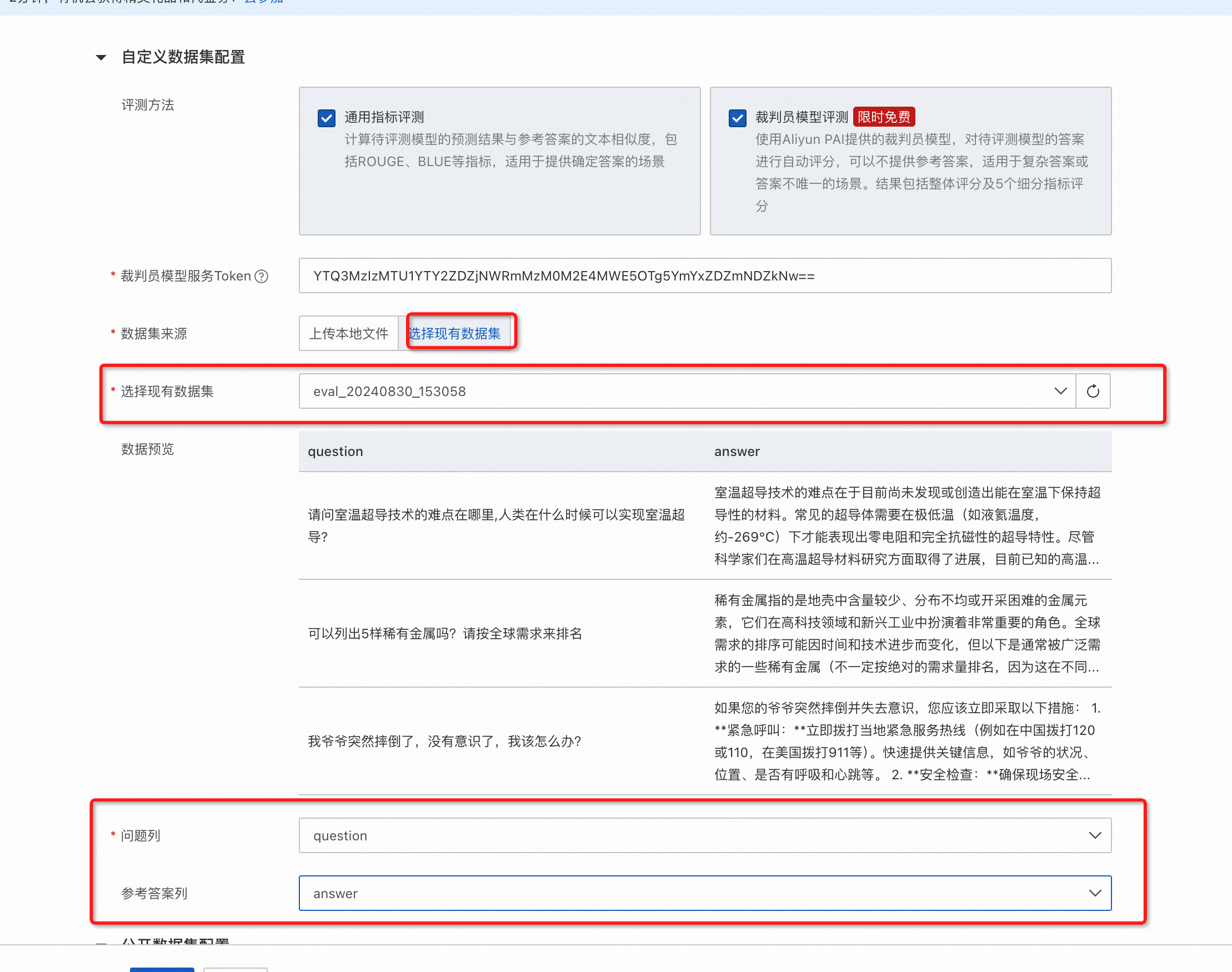
专家模式支持同时选择公开数据集和自定义数据集,其中:
公开数据集可以选择多个。
自定义数据集支持裁判员模型评测和通用指标评测。
自定义数据集支持指定问题和参考答案列,其中如果仅需要裁判员模型评测,则参考答案列可空。
支持直接使用OSS中符合格式要求的数据文件。
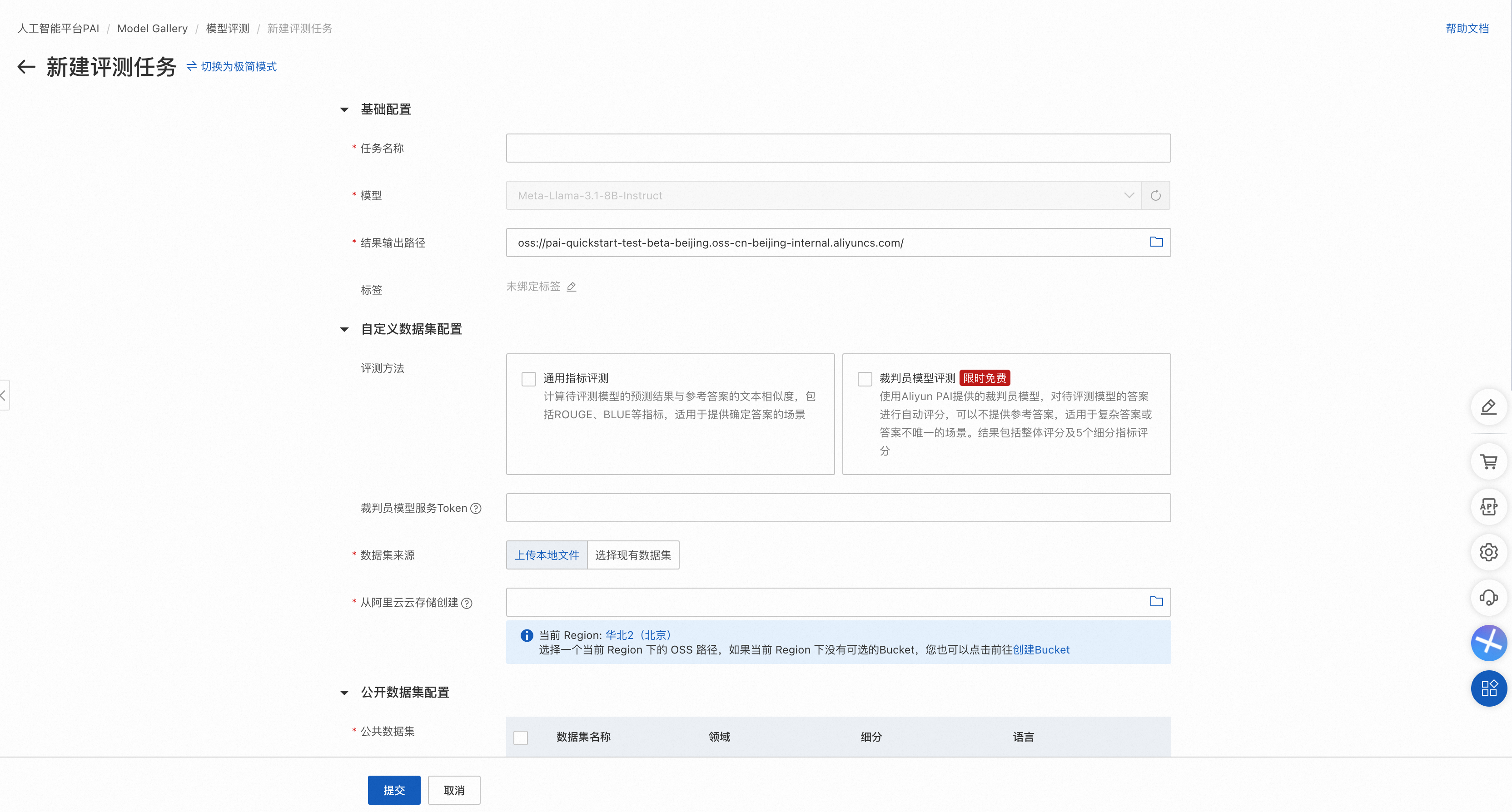
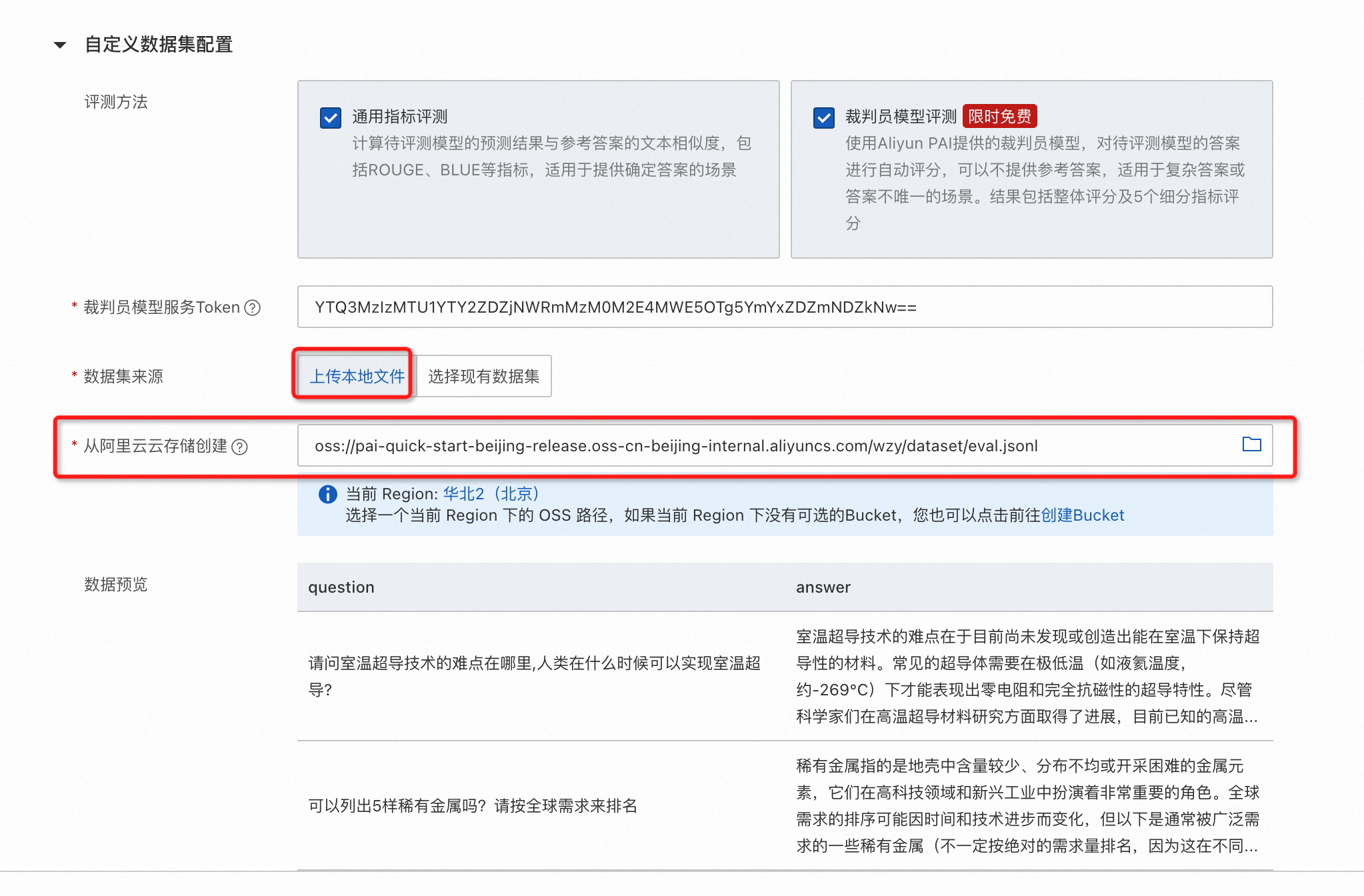
配置被评测模型推理超参数。

左下角点击提交任务,提交成功后自动跳转到评测任务详情页,等待任务成功,点击评测报告,即可查看评测报告。
查看评测结果
评测任务列表
在Model Gallery页面,单击搜索框左侧的任务管理。
在任务管理页面,选择模型评测标签页。

单任务结果
在模型评测列表页,点击评测任务的查看报告选项,即可进入评测任务详情页,在详情页评测报告一栏会展示模型在自定义数据集和公开数据集上的评测得分。
自定义数据集评测结果页面
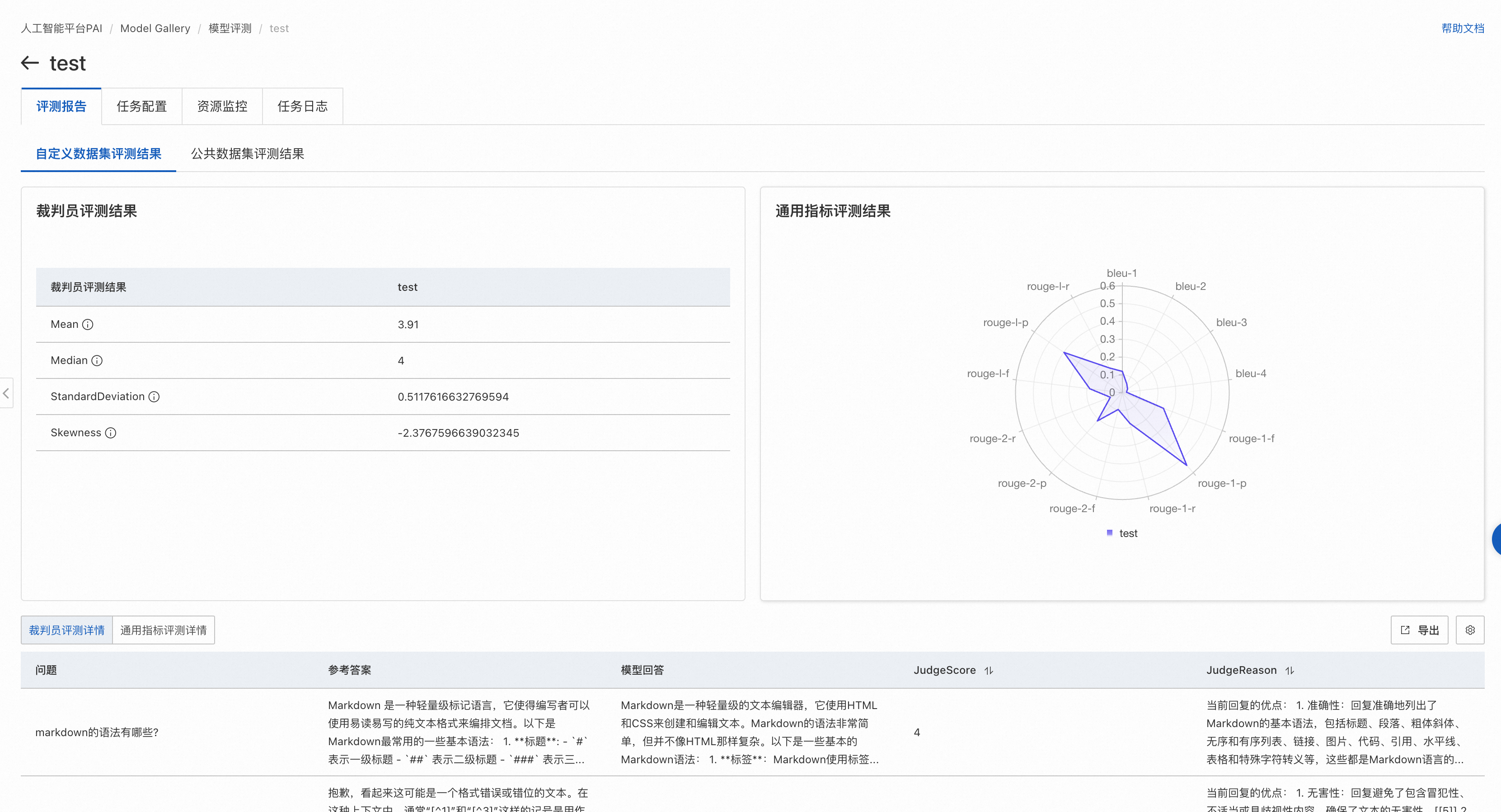
如果评测任务选中了通用指标评测,则通过雷达图展示了该模型在ROUGE和BLEU系列指标上的得分。自定义数据集的默认评测指标包括:rouge-1-f,rouge-1-p,rouge-1-r,rouge-2-f,rouge-2-p,rouge-2-r,rouge-l-f,rouge-l-p,rouge-l-r,bleu-1,bleu-2,bleu-3,bleu-4。
rouge指标:
rouge-n类指标计算N-gram(连续的N个词)的重叠度,其中rouge-1和rouge-2是最常用的,分别对应unigram和bigram:
rouge-1-p (Precision):系统摘要中的unigrams与参考摘要中的unigrams匹配的比例。
rouge-1-r (Recall):参考摘要中的unigrams在系统摘要中出现的比例。
rouge-1-f (F-score):精确率和召回率的调和平均数。
rouge-2-p (Precision):系统摘要中的bigrams与参考摘要中的bigrams匹配的比例。
rouge-2-r (Recall):参考摘要中的bigrams在系统摘要中出现的比例。
rouge-2-f (F-score):精确率和召回率的调和平均数。
rouge-l 指标基于最长公共子序列(LCS):
rouge-l-p (Precision):基于LCS的系统摘要与参考摘要的匹配程度的精确率。
rouge-l-r (Recall):基于LCS的系统摘要与参考摘要的匹配程度的召回率。
rouge-l-f (F-score):基于LCS的系统摘要与参考摘要的匹配程度的F-score。
bleu指标:
bleu (Bilingual Evaluation Understudy) 是另一种流行的评估机器翻译质量的指标,它通过测量机器翻译输出与一组参考翻译之间的N-gram重叠度来评分。
bleu-1:考察unigram的匹配。
bleu-2:考察bigram的匹配。
bleu-3:考察trigram(连续三个词)的匹配。
bleu-4:考察4-gram的匹配。
如果评测任务选中了裁判员模型评测,则通过列表展示裁判员模型评分的统计指标。
裁判员模型是PAI基于Qwen2模型微调后得到,在开源的Alighbench等数据集上表现与GPT-4持平,部分场景优于GPT-4的评测效果。
页面展示了裁判员模型对被评测模型的打分的四个统计指标:
Mean,表示裁判员大模型对模型生成结果打分的平均值(不含无效打分),最低值1,最大值5,越大表示模型回答越好。
Median,表示裁判员大模型对模型生成结果打分的中位数(不含无效打分),最低值1,最大值5,越大表示模型回答越好。
StandardDeviation,表示裁判员大模型对模型生成结果打分的标准差(不含无效打分),在均值和中位数相同情况下,标准差越小,模型越好。
Skewness,表示裁判员大模型打分结果的分布偏度(不含无效打分),正偏度表示分布右侧(高分段)有较长尾部;负偏度则表示左侧(低分段)有较长尾部。
此外还会在页面底部展示评测文件每条数据的评测详情。
公开数据集评测结果页面
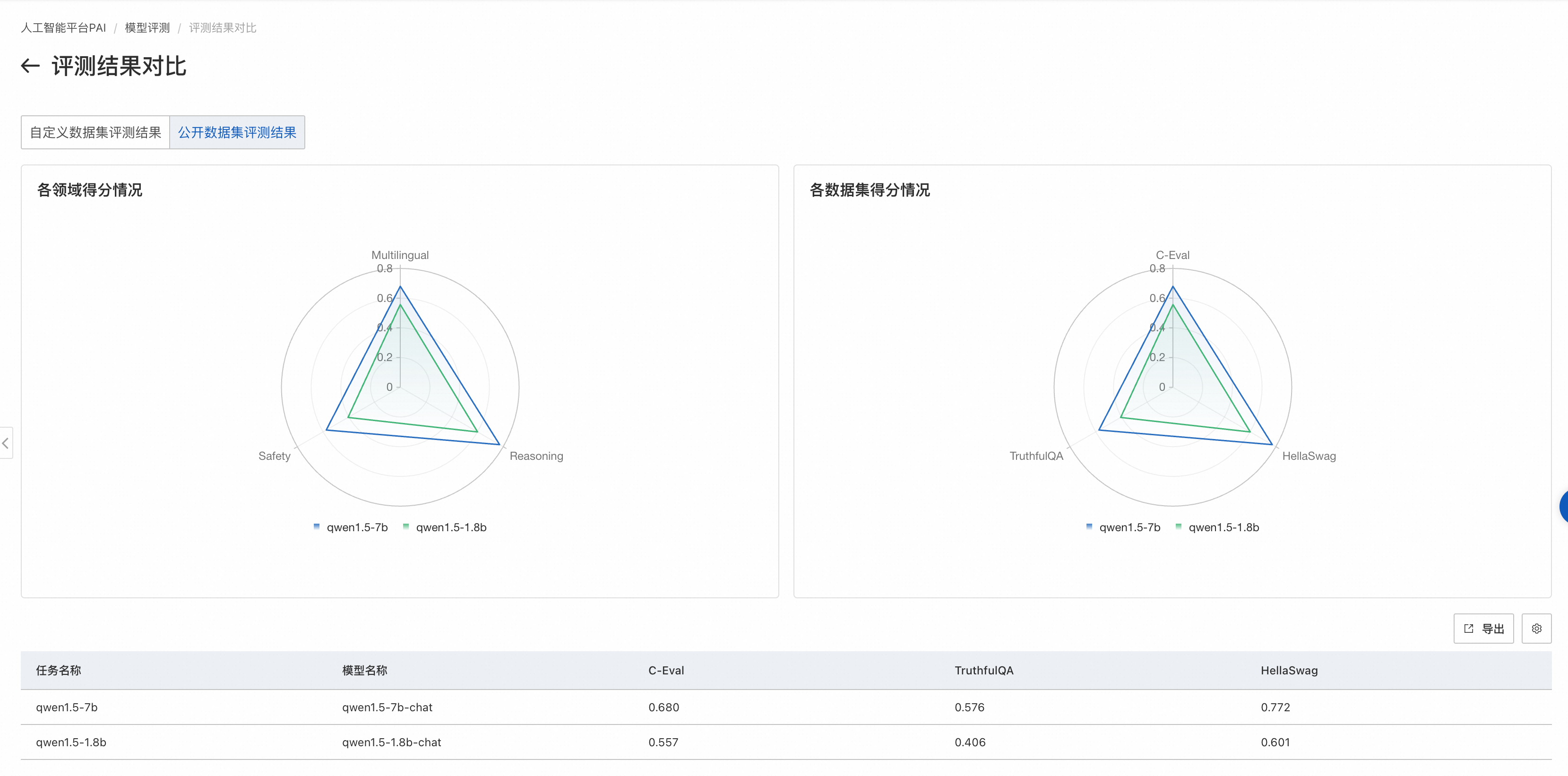
如果评测任务选择了公开数据集,则在雷达图展示该模型在公开数据集上的得分。
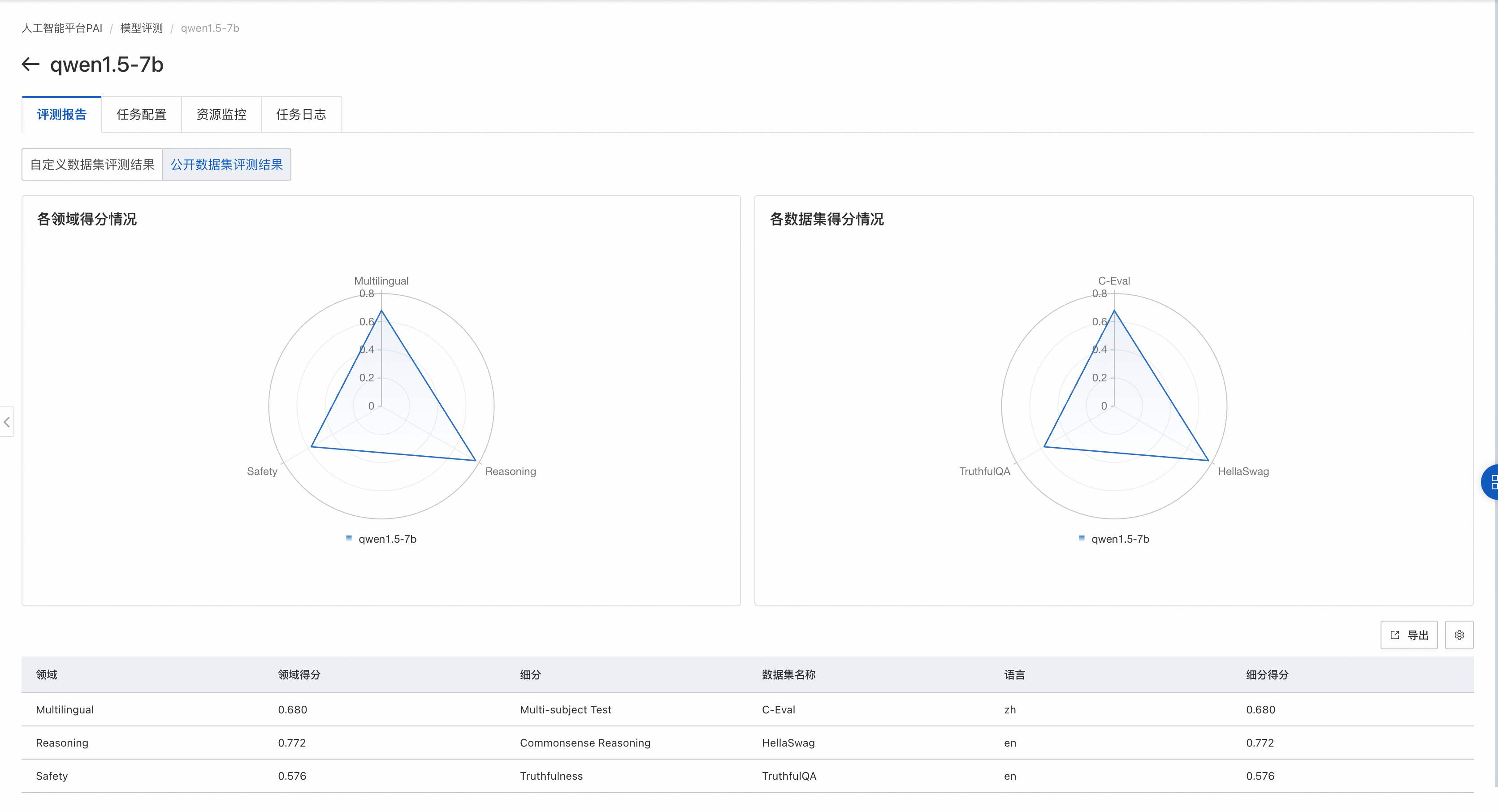
左侧图片展示了模型在不同领域的得分情况。每个领域可能会有多个与之相关的数据集,对属于同一领域的数据集,我们会把模型在这些数据集上的评测得分取均值,作为领域得分。
右侧图片展示模型在各个公开数据集的得分情况。每个公开数据集的评测范围见数据集官方介绍。
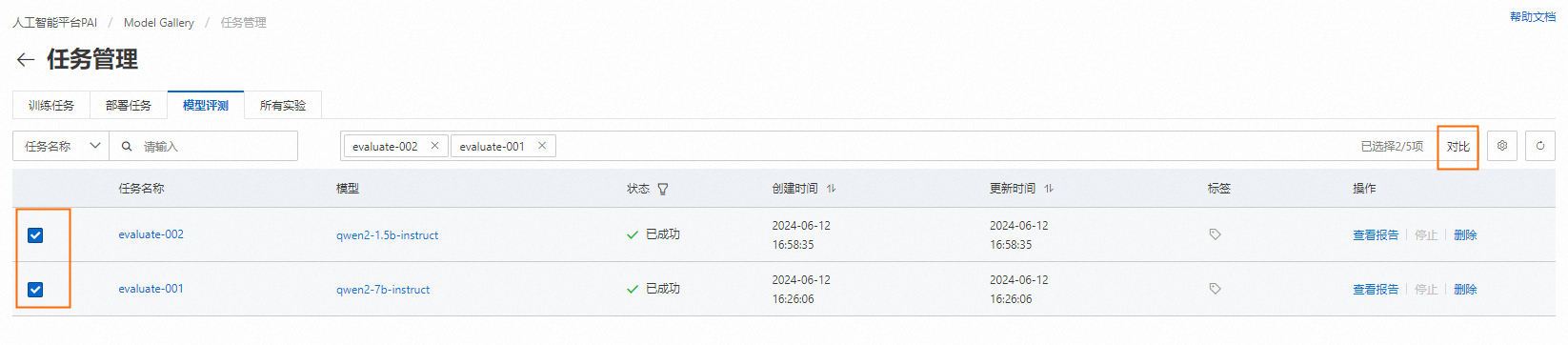
多评测任务对比
当需要对比多个模型的评测结果时,可以将它们在聚合在一个页面上展示,以便于比较效果。具体操作为在评测任务列表页左侧选择想要对比的模型评测任务,右上角点击对比,进入对比页面:
自定义数据集对比结果
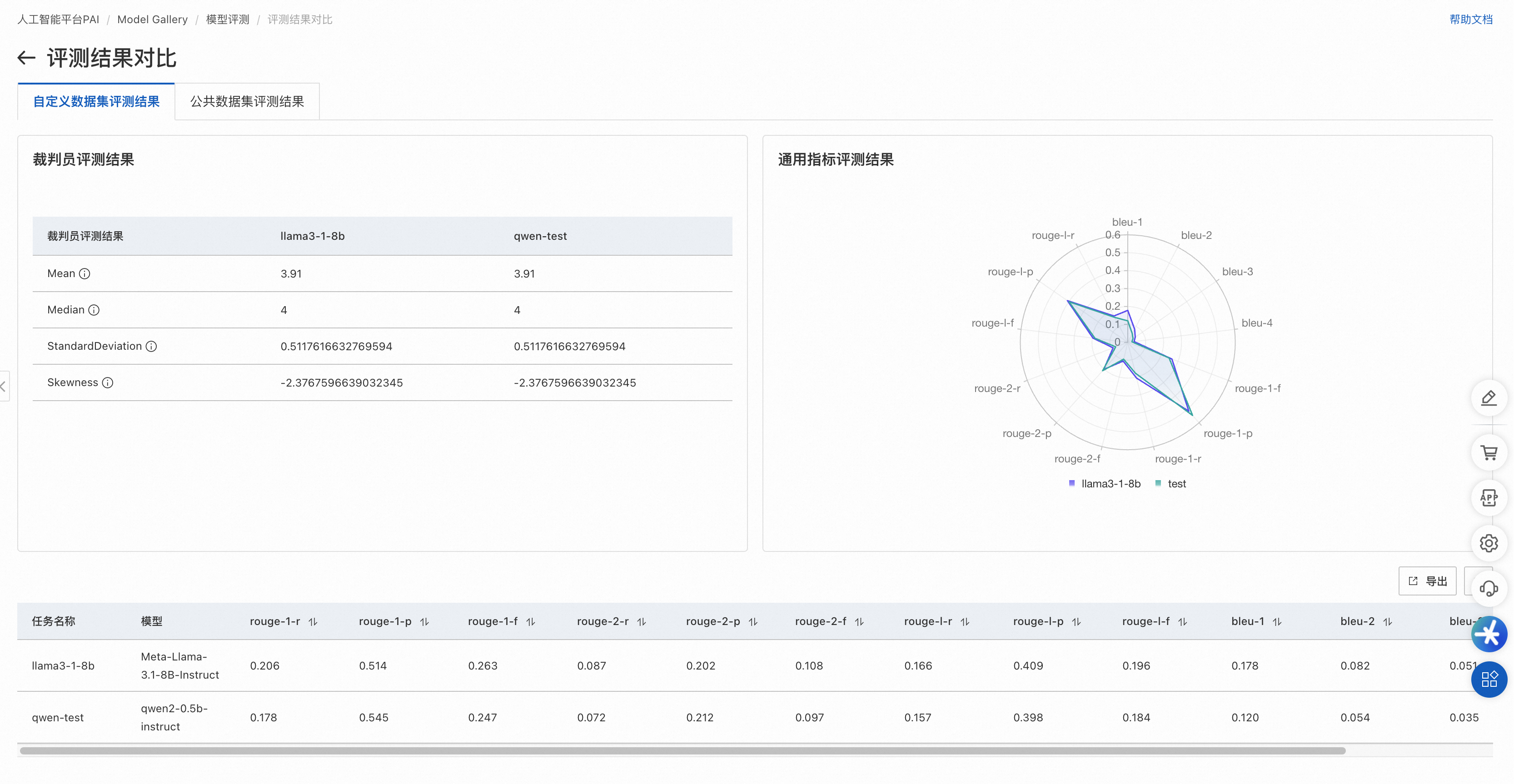
公开数据集对比结果
结果分析
模型评测包含自定义数据集和公开数据集的结果:
自定义数据集评测:
使用NLP领域标准的文本匹配方式,计算模型输出结果和真实结果的匹配度,值越大,模型越好。
使用裁判员模型评价被评测模型的输出,可以发挥大语言模型的优势,从语意层面更准确的评价模型输出的好坏。均值和中位数越高,标准差越小,模型越好。
使用该评测方式,基于自己场景的独特数据,可以评测所选模型是否适合自己的场景。
公开数据集评测:使用开源的各领域评测数据集,对LLM模型进行综合能力评估,例如数学能力、代码能力等,值越大,模型越好,这种评测方式是LLM领域最常见的评测方式。PAI正在跟随业界逐步接入更多公开评测集。
附录
除了控制台页面,也可以通过PAI Python SDK使用模型评测功能,详情可参考如下NoteBook: