
PerfTracker是大模型训练的在线性能分析诊断工具。当训练性能异常时,它能在线采集各Worker的CUDA核函数、Python函数执行记录及硬件监控数据,自动生成分析报告,定位慢节点、瓶颈函数和Hang问题。
使用限制
目前,PerfTracker相关能力仅支持PyTorch框架任务。
功能介绍
主要功能
在线获取任务执行记录:在线收集所有Worker的函数执行记录(CUDA核函数、Python函数等),以及GPU、NVLink、PCIe、DRAM等硬件的高精度(100微秒粒度)监控信息。
函数级性能分析:集中处理高精度监控数据,生成函数级性能报告,自动诊断性能损失原因(慢节点、瓶颈函数等),为深入优化提供依据。
解决方案
线上细粒度采集:将信息收集从离线复现转为在线捕获,提升实时性和准确性。
自动化性能分析算法:将人工分析经验程序化,自动诊断和定位性能问题。
实现原理
PerfTracker由Collector和PerfDisplay两部分组成。Collector运行在任务容器中,与训练进程独立;PerfDisplay提供本地可视化页面。原理如下图所示:
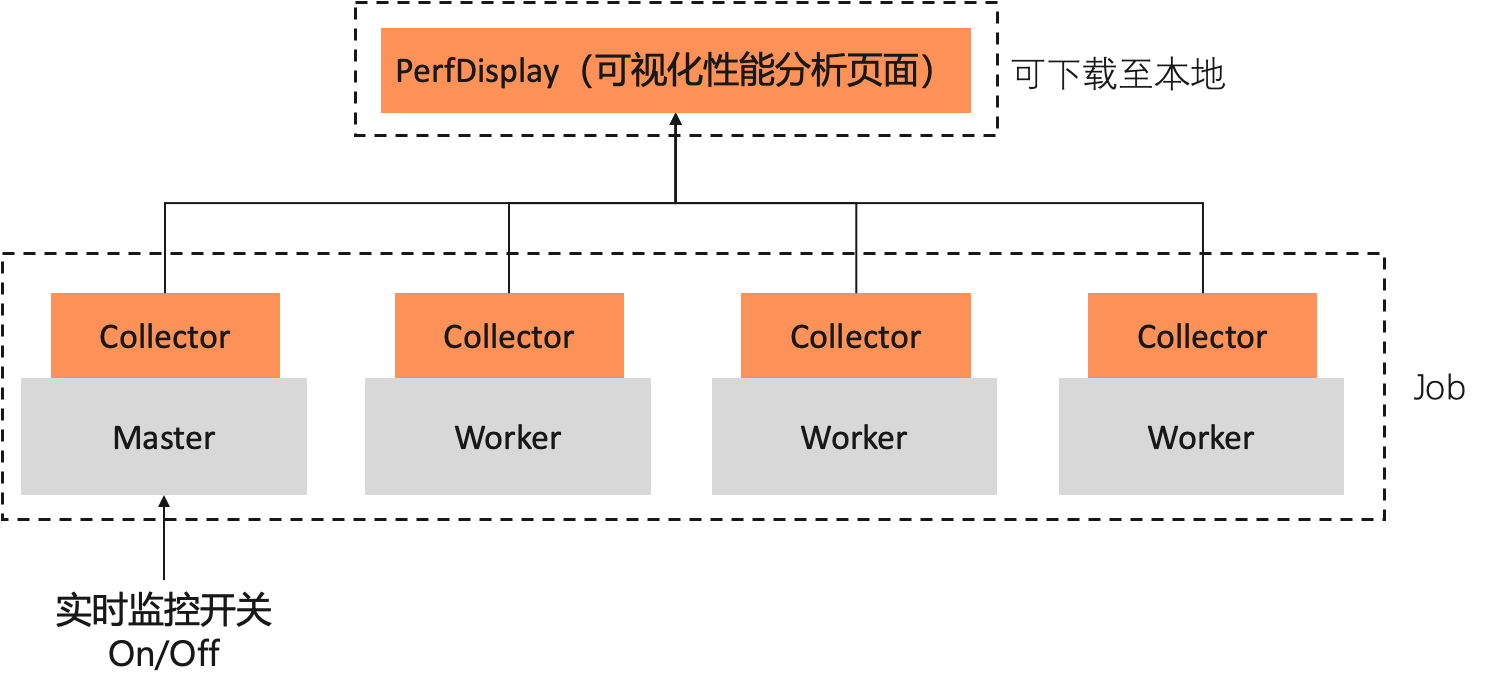
PerfTracker Collector:利用Torch profiler API和nsys采集全栈监控数据,支持以下类型:
CUDA Kernel函数(计算、通信等)、GPU launch Kernel函数、显存操作、Python函数等的执行记录,100%精确记录程序行为。
100微秒精度的GPU、NVLink、PCIe、DRAM等硬件的各种指标监控信息。
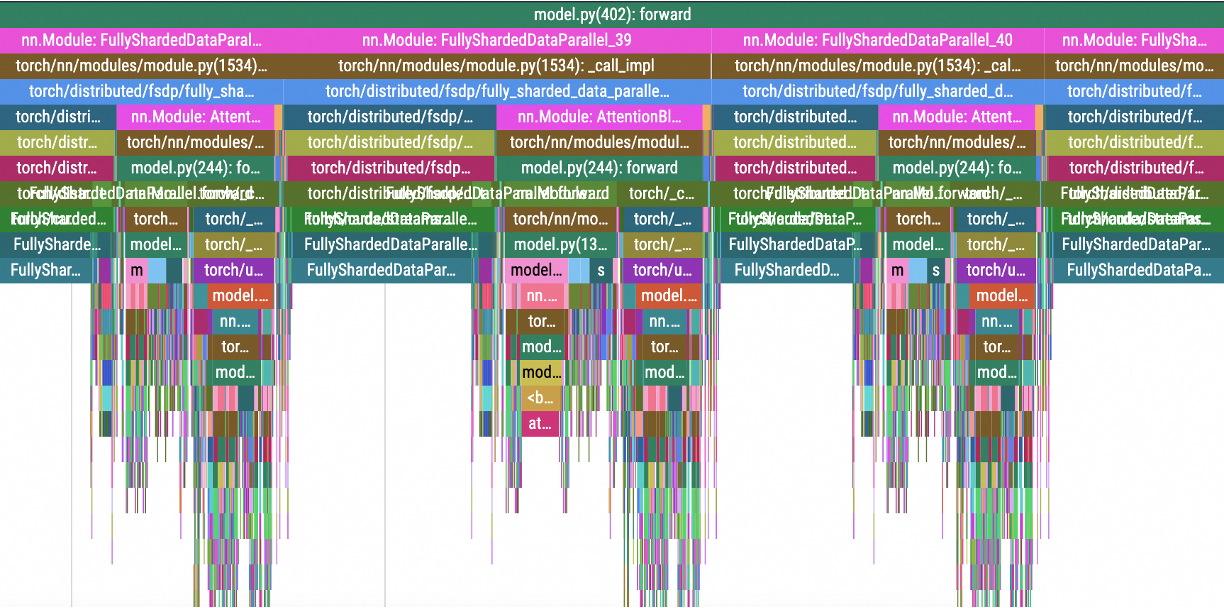
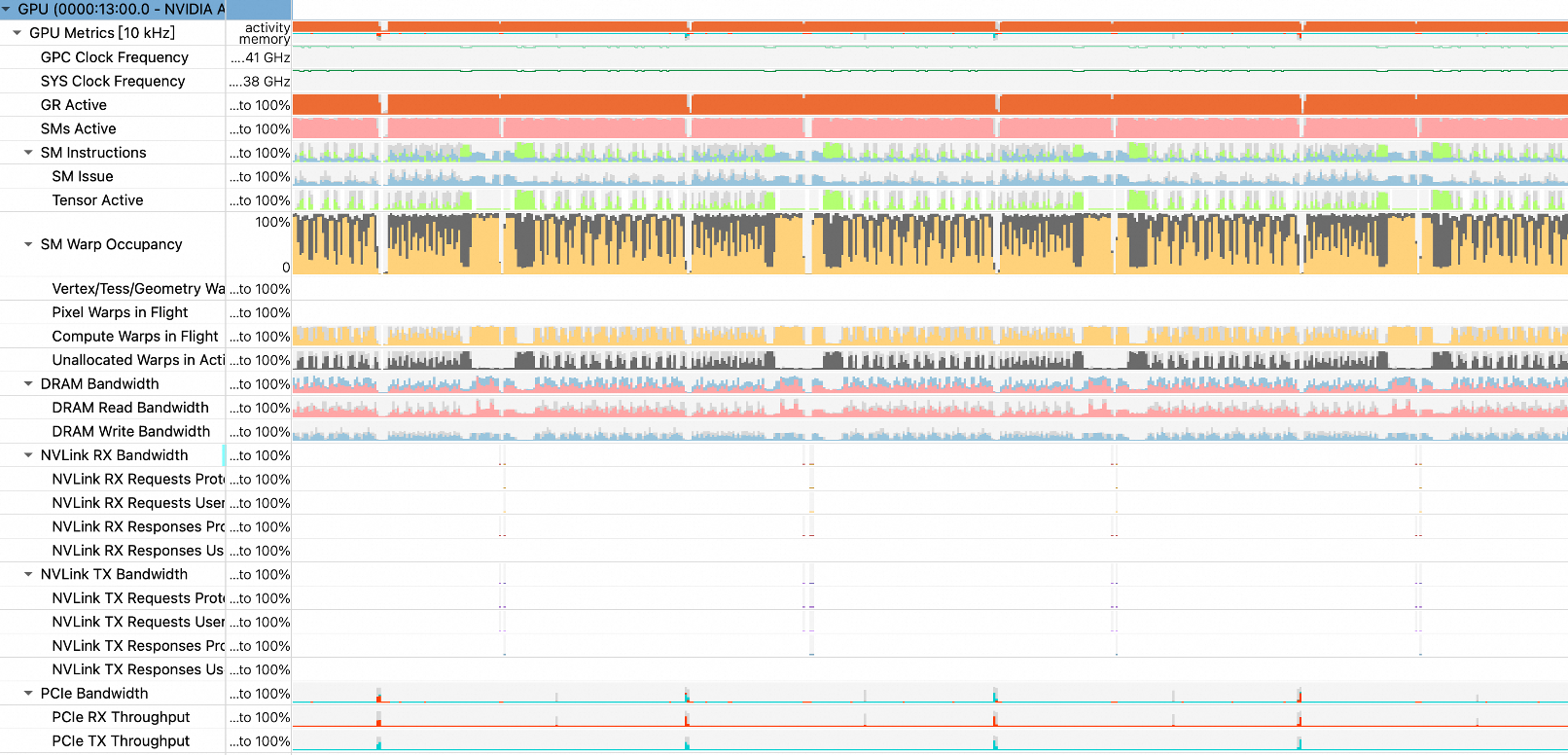
采集结果如下图所示:
CUDA Kernel函数、显存操作

Python函数、GPU launch Kernel
硬件监控信息
PerfDisplay:汇总分析采集数据,生成性能分析报告和可视化页面。
使用方法
准备工作
准备训练代码,导入PerfTracker模块并标记step。
在训练代码头部导入PerfTracker模块:
try: from c4d_perftracker_collector.PerfTracker import PerfTracker my_tracer = PerfTracker() except: my_tracer = None在训练代码中标记step。
每次调用tracer.step(),PerfTracker会记录一次,用于控制采集的iteration数量。
while iteration < args.train_iters: ... # 训练代码 if my_tracer is not None: my_tracer.step() # 标记一个step
以下是完整的training.py示例:
import torch import time import torch.distributed as dist import argparse try: from c4d_perftracker_collector.PerfTracker import PerfTracker my_tracer = PerfTracker() except: my_tracer = None dist.init_process_group("nccl") torch.cuda.set_device(dist.get_rank()) # 检查CUDA是否可用 if torch.cuda.is_available(): print("CUDA is available!") device = torch.device('cuda') # 使用默认的CUDA设备 else: print("CUDA is not available.") device = torch.device('cpu') # 如果没有CUDA,则使用CPU def matmul(): matrix_a = torch.randn(1000, 1000) matrix_b = torch.randn(1000, 1000) # 将矩阵移动到CUDA设备 matrix_a = matrix_a.to(device) matrix_b = matrix_b.to(device) # 执行矩阵乘法 result = torch.matmul(matrix_a, matrix_b) result_cpu = result.to('cpu') print(result_cpu) del matrix_a, matrix_b, result torch.cuda.empty_cache() for i in range(1000): matmul() time.sleep(dist.get_rank()) print("Epoch:", i) if my_tracer is not None: my_tracer.step() dist.barrier()将训练代码文件(training.py)上传到存储目录。本示例使用对象存储OSS存储空间。
创建训练任务
创建训练任务时,在启动命令中下载并安装PerfTracker,其余配置与普通任务相同。配置完成后单击确定创建任务。操作示例:
参数
描述
环境信息
镜像配置
选择PyTorch2.0或以上版本。本示例选择
easyanimate:1.1.5-pytorch2.2.0-gpu-py310-cu118-ubuntu22.04。存储挂载
单击OSS,选择训练代码文件所在的OSS存储目录,并配置挂载路径,本方案示例为
/mnt/data/。启动命令
# 下载PerfTracker安装包 wget -t 5 -w 2 -P /mnt/data https://network-research-lingjun-open-oss.oss-cn-hangzhou.aliyuncs.com/files/c4d_perftracker_collector-1.4.0-py3-none-any.whl # 安装PerfTracker pip3 install /mnt/data/c4d_perftracker_collector-1.4.0-py3-none-any.whl # 执行训练代码(例如训练代码为training.py) CUDA_VISIBLE_DEVICES=0,1,2,3,4,5,6,7 torchrun --nproc_per_node=4 /mnt/data/training.py其中
/mnt/data/为数据集挂载路径,可以替换成您的目录。说明大规模任务并发下载可能导致速度缓慢,建议提前将PerfTracker安装包下载到存储目录中。
资源信息
框架
选择PyTorch。
任务资源
选择资源规格。本示例选择
ecs.gn6e-c12g1.12xlarge。在任务运行期间,单击目标任务名称,并在概览页签的实例区域,单击master实例操作列下的进入容器。
执行以下命令保存分析结果,用于诊断性能问题。
方式一:仅保存分析结果,不保存原始trace。
c4d_perftracker --trigger-on --auto-analyze --output-dir /mnt/data/方式二(推荐):存储空间充足时,同时保存分析结果和原始trace,便于人工确认。注意每个Worker的trace通常超过几百MB,诊断完毕后可手动删除。
c4d_perftracker --trigger-on --auto-analyze --output-dir /mnt/data/ --save-raw-trace all其中
/mnt/data/表示原始trace保存的目录。可以将其配置为您的数据集挂载目录,原始trace将保存到数据集中。
保存分析结果后,可通过PerfDisplay查看分析报告。更多参数说明见附录。
查看分析结果
参考分析模式生成并保存分析结果。命令执行成功后,系统会在该目录中生成
<时间戳>/PerfDisplay文件夹。分析完成后,OSS Bucket 文件列表中将生成 PerfDisplay/ 和 raw_trace/ 两个文件夹。将PerfDisplay文件夹拷贝到数据源的挂载目录
/mnt/data中,参考命令行工具ossutil 2.0,将PerfDisplay下载到本地。(可以将文件夹压缩后再进行下载)。tar -cvf trace.tar PerfDisplay/ mv trace.tar /mnt/data在本地终端中,进入
PerfDisplay文件夹并运行sudo python3 app.py(Linux可能不需要sudo),然后在浏览器中打开http://127.0.0.1:5000/,即可在可视化页面中查看任务性能报告。
PerfTracker展示所有影响性能的函数报告,并标注异常。按函数类型分类展示:
GPU计算函数
GPU Compute:
[2025-03-04 06:04:00,046 PerfTracker] (compute_functions.py 131) INFO: {
"min/median/max GPU utilization (in [0,1])": [
0.27586059769318555,
0.28605496203987174,
0.2945494558115959
],
"workers with abnormal GPU utilization": {},
"major_kernel_executions": {
"void multi_tensor_apply_kernel<TensorListMetadata<4>, AdamFunctor<float, float, int>, float, float, float, float, float, float, adamMode_t, float>(long, int volatile*, TensorListMetadata<4>, AdamFunctor<float, float, int>, float, float, float, float, float, float, adamMode_t, float)320_1_1|512_1_1": {
"median cost per execution (ms)": 403.7,
"bottleneck ratio (in [0,1])": 0.01608086667957405
},
"sm80_xmma_gemm_f16f16_f16f32_f32_nn_n_tilesize160x128x32_stage4_warpsize2x2x1_tensor16x8x16_kernel7_16_1|128_1_1": {
"median cost per execution (ms)": 130.0,
"bottleneck ratio (in [0,1])": 0.015779752711771233
},
"ampere_fp16_s16816gemm_fp16_128x128_ldg8_f2f_stages_32x5_nt16_32_1|128_1_1": {
"median cost per execution (ms)": 132.60000000000002,
"bottleneck ratio (in [0,1])": 0.013880912782219888
},
"void (anonymous namespace)::indexing_backward_kernel<c10::Half, 4>(long const*, long const*, c10::Half const*, c10::Half*, long, long, long, long, bool)256_16_1|32_4_1": {
"median cost per execution (ms)": 1202.25,
"bottleneck ratio (in [0,1])": 0.012148757934008617
},
"ampere_fp16_s16816gemm_fp16_128x128_ldg8_f2f_stages_32x5_nt16_24_1|128_1_1": {
"median cost per execution (ms)": 105.6,
"bottleneck ratio (in [0,1])": 0.005656117080836238
}
},
"workers with potential GPU issues": [],
"detailed report": {}
}报告解读:
"min/median/max GPU utilization (in [0,1])"表明该任务所有Worker的GPU利用率最高为29.4%,最低为27.5%,中位数为28.6%。"workers with abnormal GPU utilization"为空,表明GPU利用率没有显著离群的Worker(如果非空,则会列出离群的Worker号及其GPU利用率)。"major_kernel_executions"列出了几个总耗时较长的GPU Kernel执行情况,包括平均单次执行耗时(median cost per execution),以及占端到端性能的百分比(bottleneck ratio)。"workers with potential GPU issues"会列出GPU核函数执行较慢的Worker号,若为空则表示所有Worker都正常。"detailed report"会在"workers with potential GPU issues"非空时,列出具体哪个Worker执行的哪个Kernel函数比正常Worker慢,以及慢多少。
GPU显存操作函数
GPU memory operations:
[2025-03-04 06:04:00,048 PerfTracker] (gpu_mem.py 37) INFO: {
"Memcpy DtoD (Device -> Device)": {
"avg bottleneck ratio (in [0,1])": 0.010486858246092,
"abnormal_workers": {
"job_x08j11173.cloud.sqa.na131_2_122482.json": 0.010614755325049817,
"job_x08j11173.cloud.sqa.na131_8_122483.json": 0.0105935370201344,
"job_x08j11173.cloud.sqa.na131_1_122484.json": 0.010571838319204434,
"job_x08j11173.cloud.sqa.na131_0_122485.json": 0.010551186610995748,
"job_x08j11173.cloud.sqa.na131_2_122487.json": 0.010408514784026183,
"job_x08j11173.cloud.sqa.na131_5_122489.json": 0.010394903160689894,
"job_x08j11173.cloud.sqa.na131_8_122486.json": 0.010387693451926115,
"job_x08j11173.cloud.sqa.na131_9_122488.json": 0.010372437296709398
}
}
}报告解读:
"avg bottleneck ratio (in [0,1])"表明该任务在监控期间Memcpy DtoD的平均时间占比为1.048%。"abnormal_workers"表明其中8个Worker的Memcpy DtoD函数耗时异常。对于GPU显存操作函数,当bottleneck ratio(即运行时长除去和计算overlap的部分)大于0.01(1%)即被认为异常。
集合通信
Communication:
{
"nvlink ring send": {
"ncclDevKernel_AllReduce_Sum_f16_RING_LL(ncclDevComm*, unsigned long, ncclWork*)": {
"example_of_normal_worker": {
"worker": "job_x08j11173.cloud.sqa.na131_0_66930.json",
"different from other workers": 0,
"features": {
"bottleneck ratio (in [0,1])": 0.2743985289797289,
"avg throughput (%)": 73.75921390374332,
"throughput std (%)": 11.384679144385027
}
},
"abnormal_workers": []
}
},
"nvlink ring recv": {
"ncclDevKernel_AllReduce_Sum_f16_RING_LL(ncclDevComm*, unsigned long, ncclWork*)": {
"example_of_normal_worker": {
"worker": "job_x08j11173.cloud.sqa.na131_3_66933.json",
"different from other workers": 2,
"features": {
"bottleneck ratio (in [0,1])": 0.27346865947352955,
"avg throughput (%)": 72.70337362637363,
"throughput std (%)": 12.658093406593407
}
},
"abnormal_workers": []
}
},
"pcie sendrecv send": {
"ncclDevKernel_SendRecv(ncclDevComm*, unsigned long, ncclWork*)": {
"example_of_normal_worker": {
"worker": "job_x08j11173.cloud.sqa.na131_0_66930.json",
"different from other workers": 3,
"features": {
"bottleneck ratio (in [0,1])": 0.07248997985478658,
"avg throughput (%)": 46.667,
"throughput std (%)": 14.636000000000001
}
},
"abnormal_workers": []
}
},
"pcie sendrecv recv": {
"ncclDevKernel_SendRecv(ncclDevComm*, unsigned long, ncclWork*)": {
"example_of_normal_worker": {
"worker": "job_x08j11173.cloud.sqa.na131_7_66936.json",
"different from other workers": 1,
"features": {
"bottleneck ratio (in [0,1])": 0.0643436909425455,
"avg throughput (%)": 54.833333333333336,
"throughput std (%)": 14.166666666666666
}
},
"abnormal_workers": []
}
},
"pcie ring send": {
"ncclDevKernel_AllReduce_Sum_f16_RING_LL(ncclDevComm*, unsigned long, ncclWork*)": {
"example_of_normal_worker": {
"worker": "job_x08j11173.cloud.sqa.na131_0_66930.json",
"different from other workers": 0,
"features": {
"bottleneck ratio (in [0,1])": 0.2743985289797289,
"avg throughput (%)": 41.36698734177215,
"throughput std (%)": 14.653768987341774
}
},
"abnormal_workers": []
}
},
"pcie ring recv": {
"ncclDevKernel_AllReduce_Sum_f16_RING_LL(ncclDevComm*, unsigned long, ncclWork*)": {
"example_of_normal_worker": {
"worker": "job_x08j11173.cloud.sqa.na131_0_66930.json",
"different from other workers": 0,
"features": {
"bottleneck ratio (in [0,1])": 0.2743985289797289,
"avg throughput (%)": 41.5311475409836,
"throughput std (%)": 15.282721311475411
}
},
"abnormal_workers": []
}
}
}报告按通信类型分类展示集合通信函数的性能分析:
"example_of_normal_worker"列出了该函数执行的常态性能参数,包括bottleneck ratio(指占端到端时间的占比,已除去和计算overlap的时间)、avg throughput和throughput std。"abnormal_workers"若非空,则会列出所有该通信函数性能异常的Worker及其性能指标。
CUDA runtime
CUDA Runtime:
[2025-03-04 06:04:00,047 PerfTracker] (cuda_runtimes.py 43) INFO: {
"cudaLaunchKernel": {
"avg bottleneck ratio (in [0,1])": 0.039727736621541394,
"avg execution time / monitoring duration (in [0,1])": 0.06956947111288565,
"abnormal_workers": {
"job_x08j11173.cloud.sqa.na131_5_122489.json": 0.05342638907019616,
"job_x08j11173.cloud.sqa.na131_8_122483.json": 0.05125160206973098,
"job_x08j11173.cloud.sqa.na131_2_122487.json": 0.04770049253555521,
"job_x08j11173.cloud.sqa.na131_8_122486.json": 0.04358845044879828,
"job_x08j11173.cloud.sqa.na131_0_122485.json": 0.042635952262081556,
"job_x08j11173.cloud.sqa.na131_9_122488.json": 0.0354174573296689,
"job_x08j11173.cloud.sqa.na131_1_122484.json": 0.023585242093250733,
"job_x08j11173.cloud.sqa.na131_2_122482.json": 0.02021630716304934
}
}
}报告解读:
"avg bottleneck ratio (in [0,1])"表明该任务在监控期间cudaLaunchKernel的平均时间占比(已排除和计算overlap的部分)为3.97%。"avg execution time / monitoring duration (in [0,1])"表示cudaLaunchKernel的平均时间占比(不排除和计算overlap的部分)为6.95%。"abnormal_workers"表明其中8个Worker的cudaLaunchKernel函数耗时异常。对于CUDA Runtime函数、bottleneck ratio(即运行时长除去和计算overlap的部分)大于0.01(1%)即被认为异常。
Python函数
Python functions:
[2025-03-04 06:04:00,048 PerfTracker] (python_functions.py 43) INFO: {
"pretrain_gpt.py: <module>|megatron/training.py: pretrain|megatron/training.py: train|megatron/training.py: train_step|megatron/core/pipeline_parallel/schedules.py: forward_backward_pipelining_without_interleaving|megatron/core/pipeline_parallel/schedules.py: backward_step|megatron/core/pipeline_parallel/schedules.py: custom_backward|<built-in method run_backward of torch._C._EngineBase object at 0x>": {
"job_x08j11173.cloud.sqa.na131_2_122487.json": 0.16970858578301054,
"job_x08j11173.cloud.sqa.na131_5_122489.json": 0.16821543761561655,
"job_x08j11173.cloud.sqa.na131_0_122485.json": 0.16787961852913025,
"job_x08j11173.cloud.sqa.na131_8_122483.json": 0.16769273336153187,
"job_x08j11173.cloud.sqa.na131_8_122486.json": 0.14482595694389258,
"job_x08j11173.cloud.sqa.na131_9_122488.json": 0.10359829140378449,
"job_x08j11173.cloud.sqa.na131_1_122484.json": 0.06543764774209325,
"job_x08j11173.cloud.sqa.na131_2_122482.json": 0.06217541348063737
},
"pretrain_gpt.py: <module>|megatron/training.py: pretrain|megatron/training.py: train|megatron/training.py: train_step|megatron/core/pipeline_parallel/schedules.py: forward_backward_pipelining_without_interleaving|megatron/core/pipeline_parallel/schedules.py: forward_step|pretrain_gpt.py: forward_step|nn.Module: DistributedDataParallel_0|torch/nn/modules/module.py: _call_impl|megatron/core/distributed/distributed_data_parallel.py: forward|nn.Module: Float16Module_0|torch/nn/modules/module.py: _call_impl|megatron/model/module.py: forward|nn.Module: GPTModel_0|torch/nn/modules/module.py: _call_impl|megatron/model/gpt_model.py: forward|nn.Module: TransformerLanguageModel_0|torch/nn/modules/module.py: _call_impl|megatron/model/language_model.py: forward|nn.Module: ParallelTransformer_0|torch/nn/modules/module.py: _call_impl|megatron/model/transformer.py: forward": {
"job_x08j11173.cloud.sqa.na131_9_122488.json": 0.02471835416438489,
"job_x08j11173.cloud.sqa.na131_0_122485.json": 0.02022024568555683,
"job_x08j11173.cloud.sqa.na131_2_122482.json": 0.015394834126935101,
"job_x08j11173.cloud.sqa.na131_2_122487.json": 0.011625367332189284
},
"pretrain_gpt.py: <module>|megatron/training.py: pretrain|megatron/training.py: train|megatron/training.py: train_step": {
"job_x08j11173.cloud.sqa.na131_0_122485.json": 0.012272193902698852
},
"autograd::engine::evaluate_function: LinearWithGradAccumulationAndAsyncCommunicationBackward|LinearWithGradAccumulationAndAsyncCommunicationBackward|torch/autograd/function.py: apply|torch/cuda/amp/autocast_mode.py: decorate_bwd|megatron/core/tensor_parallel/layers.py: backward|<built-in method matmul of Tensor object at 0x>|aten::matmul|aten::mm": {
"job_x08j11173.cloud.sqa.na131_2_122487.json": 0.014066713574814782,
"job_x08j11173.cloud.sqa.na131_0_122485.json": 0.013168949365116213,
"job_x08j11173.cloud.sqa.na131_8_122483.json": 0.013000378454189552,
"job_x08j11173.cloud.sqa.na131_5_122489.json": 0.012500119397472594,
"job_x08j11173.cloud.sqa.na131_8_122486.json": 0.012470581043494208
},
"autograd::engine::evaluate_function: FastLayerNormFNBackward|FastLayerNormFNBackward|torch/autograd/function.py: apply|apex/contrib/layer_norm/layer_norm.py: backward|<built-in method ln_bwd of PyCapsule object at 0x>": {
"job_x08j11173.cloud.sqa.na131_0_122485.json": 0.010127612754279463
},
"pretrain_gpt.py: <module>|megatron/training.py: pretrain|megatron/training.py: train|megatron/training.py: train_step|megatron/core/pipeline_parallel/schedules.py: forward_backward_pipelining_without_interleaving": {
"job_x08j11173.cloud.sqa.na131_2_122487.json": 0.01041679269251709
},
"autograd::engine::evaluate_function: torch::autograd::AccumulateGrad": {
"job_x08j11173.cloud.sqa.na131_8_122486.json": 0.013633967050768714
}
}报告列出执行时间占比超过1%(排除与GPU计算、通信重叠的时间)的Python函数,按函数名聚类,展示各Worker上的执行时间占比。
附录
PerfTracker更多参数使用说明
相关参考
PerfTracker原理详见:PerfTracker: Online Performance Troubleshooting for Large-scale Model Training in Production。