多模态RLHF标注模板提供多模态RLHF标注的功能,在对话改写的基础上,可以接入输入机器人进行自动问答,也可以在手动问答模式输入图片等多模态类型的内容。
背景信息
OpenAI近期公布的文档中,揭示了ChatGPT在对话场景中超越Bert等自然语言处理(NLP)模型的成就,其核心优化机制是采用人类反馈强化学习(Reinforcement Learning from Human Feedback, RLHF)技术。本文从模型的训练产物和目标进行详细分析,帮助您深入理解RLHF技术在ChatGPT中的应用,以及“标注”过程的重要性。
RLHF训练机制包含三个主要阶段:
基于GPT-3.5的微调产生Fine-Tuned Model(SFT),期间高质量的提示(prompt)及其对应答案是很重要,这些数据来源于多模型预测或人工提供,因此对标注人员的素质有高要求。
构建奖励模型(Reward Model)以评估和筛选步骤1的预测结果,ChatGPT目前主要采用的是排序(Ranking)方法,并通过监督式学习优化(Supervised Learning with Ordered or Rankings,SLO)技术进行,此阶段所需的人工标注形式为排序标注,侧重于排序标注的精准度与规模。
运用近端策略优化(PPO)进行强化学习,依据奖励模型输出,此环节几乎不涉及人工标注。
这三个阶段构成ChatGPT的完整训练循环,并持续迭代优化。人工标注在初始的微调和奖励模型构建阶段发挥了重要作用,虽需求量较预训练阶段的小规模监督数据为少,但其质量和数量对模型性能影响显著。
数据格式示例
CSV及XLSX格式中每一列数据;Manifest格式中data字段的下一级字段均对应一个数据集字段,字段名可自定义,在配置数据集字段名时选择对应的字段名即可。图片文件支持常见的JPG、PNG等格式。
手动输入模式下,不需要第二列首轮问题数据,仅需要topic数据。
CSV及XLSX格式
topic | first-question |
水果01 | 苹果好吃吗? |
水果02 | 橘子好吃吗? |
Demo:
Manifest格式(JSONL格式)
{"data":{"topic":"水果01","first-question":"苹果好吃吗?"}}
{"data":{"topic":"水果02","first-question":"橘子好吃吗?"}}Demo:
配置说明
题目区(必选)
题目区用于配置话题字段。
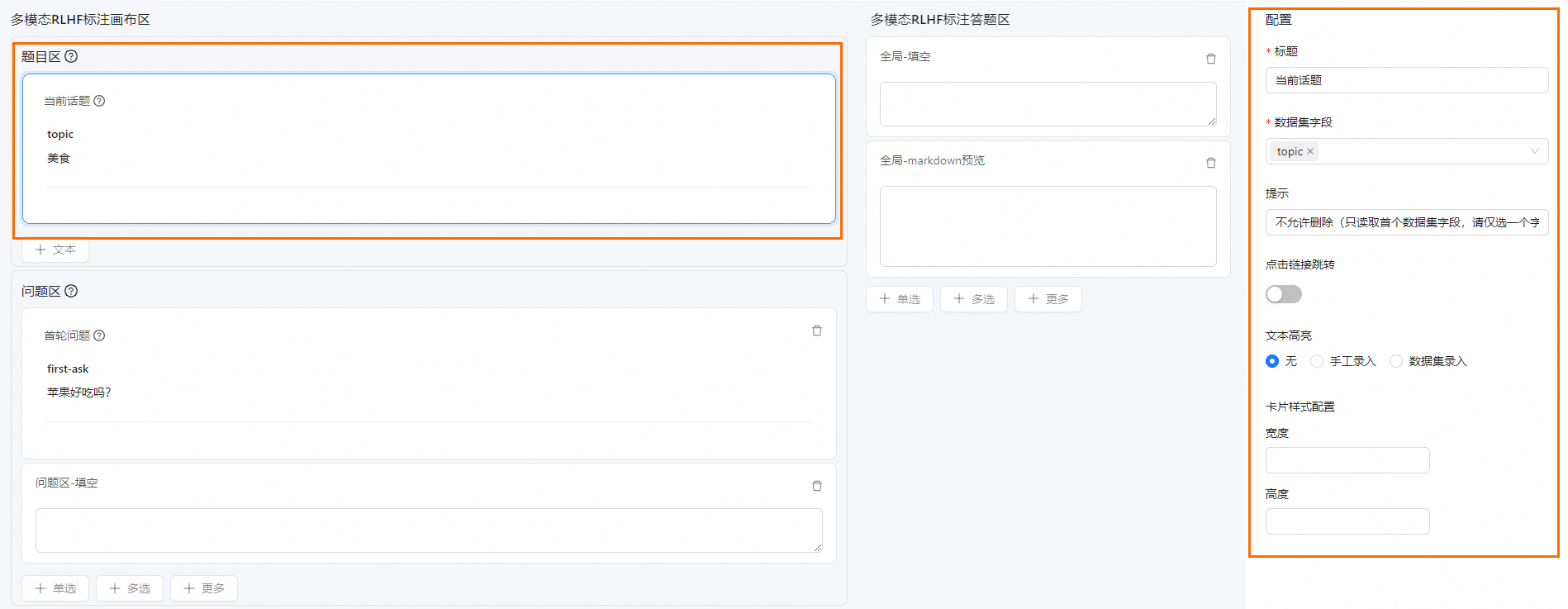
单击选中当前话题,并选择相应的数据集后,在右侧配置区域配置具体参数。参数说明如下:
参数 | 说明 |
标题 | 默认标题区域无需修改。 |
数据集字段 | 在数据集字段中选择题目展示字段。(字段名可自定义) |
提示 | 默认提示区域无需修改。 |
点击链接跳转 | 无需配置,不生效。 |
文本高亮 | 无需配置,不生效。 |
卡片样式配置 | 无需配置,不生效。 |
问题区(自动问答模式下,首轮问题必选)
问题区可以在自动问答模式配置首轮问题和问题区域题目,手动输入模式配置无效。
自动问答机器人包含首轮问题组件,需要进行配置;手动提问不包含此组件。配置首轮问题后,还需要配置提问机器人的UDF信息。
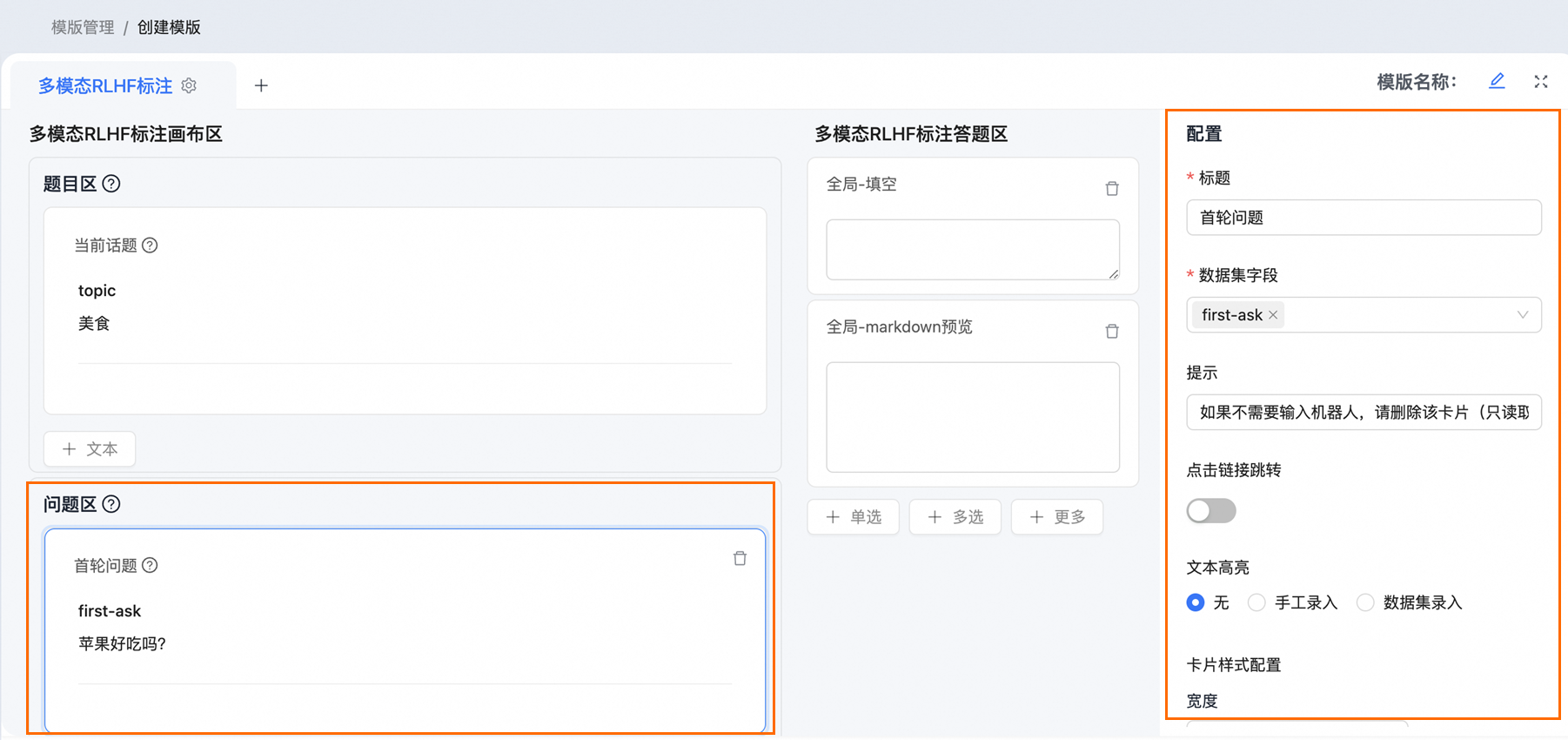
单击选中首轮问题后,在右侧配置区域配置具体参数。参数说明如下:
参数 | 说明 |
标题 | 默认标题区域无需修改。 |
数据集字段 | 配置首轮问题对应的数据集字段。(字段名可自定义) |
提示 | 默认提示区域无需修改。 |
点击链接跳转 | 无需配置,不生效。 |
文本高亮 | 无需配置,不生效。 |
卡片样式配置 | 无需配置,不生效。 |
答题区(可选)
答题区用于配置回答机器人回复文本相关问题。
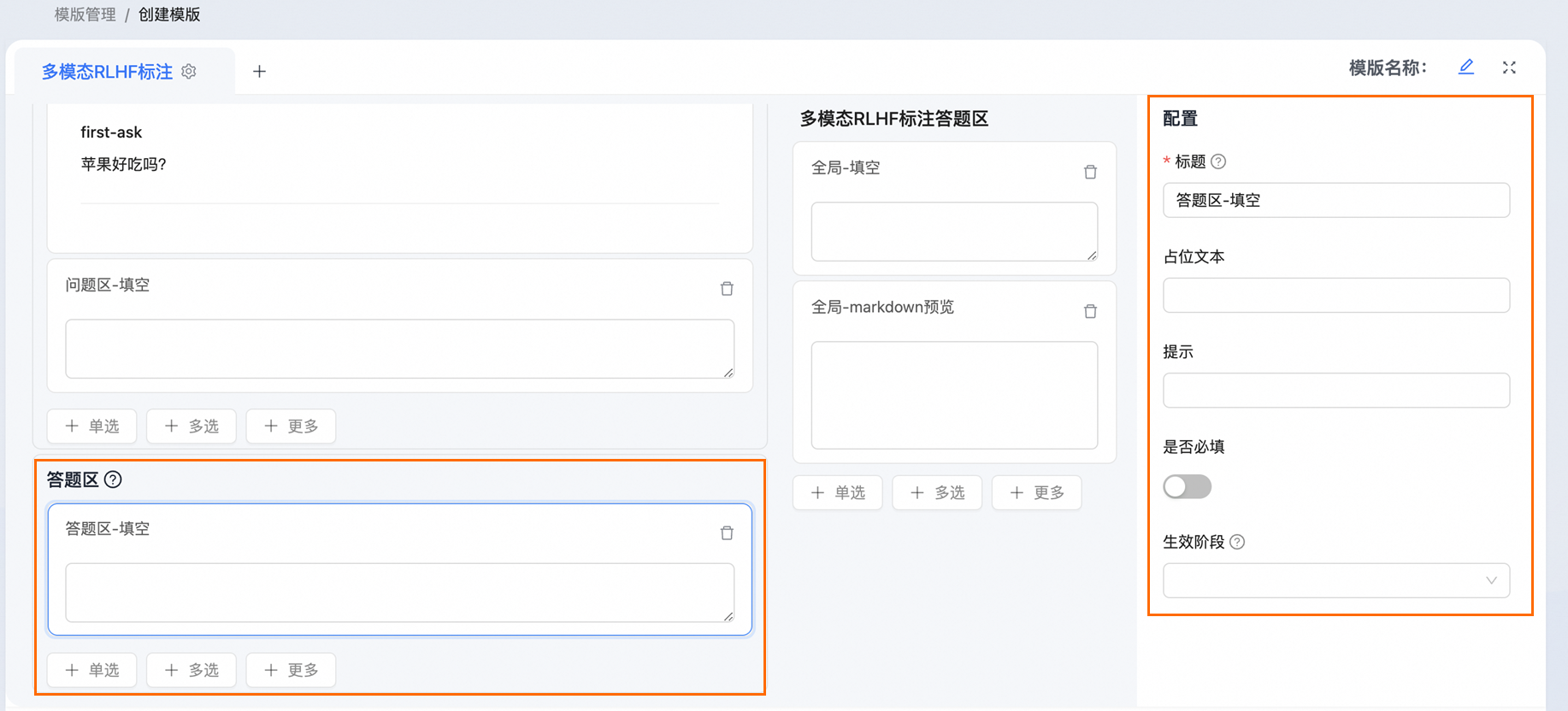
单击选中答题区后,在右侧配置区域配置具体参数。参数说明如下:
参数 | 说明 |
标题 | 可根据需要配置问题标题。 |
选项 说明 当答题类型为单选、多选或树选择时,需要配置此参数。 |
|
占位文本 说明 当答题类型为单行输入框或输入框-Markdown预览时,需要配置此参数。 | 填空题占位文字,用于引导用户输入内容。 |
提示 | 配置悬停在题目标题上时出现的提示文字。 |
是否必填 | 配置题目是否为必填项,若为必填则答题时会进行必填校验。 |
支持搜索选项 说明 当答题类型为单选或多选时,需要配置此参数。 | 配置后可以进行选项的搜索。 |
生效阶段 | 题目的生效阶段,不选时默认全流程生效。 |
全局题目(可选)
全局题目用于根据需要针对整个主题提出问题。
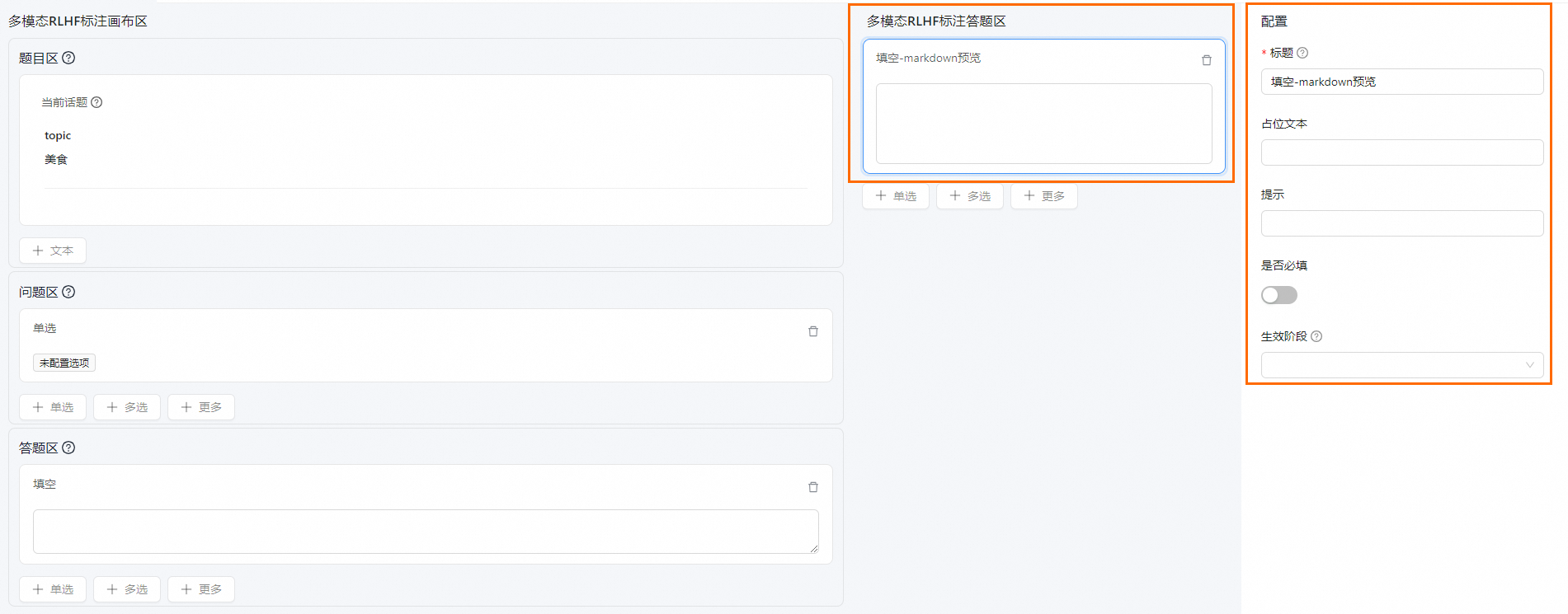
单击选中题目后,在右侧配置区域配置具体参数。参数说明如下:
参数 | 说明 |
标题 | 可根据需要配置问题标题。 |
占位文本 说明 当答题类型为输入框-Markdown预览或单行输入框时需要配置此参数。 | 填空题占位文字,用于引导用户输入内容。 |
选项 说明 当答题类型为单选、多选、树选择或多选树选择时,需要配置此参数。 |
|
提示 | 配置悬停在题目标题上时出现的提示文字。 |
是否必填 | 配置题目是否为必填项,若为必填则答题时会进行必填校验。 |
支持搜索选项 说明 当答题类型为单选或多选时,需要配置此参数。 | 配置后可以进行选项的搜索。 |
生效阶段 | 题目的生效阶段,不选时默认全流程生效。 |
全局配置
全局配置用于配置模板中会使用到的UDF。
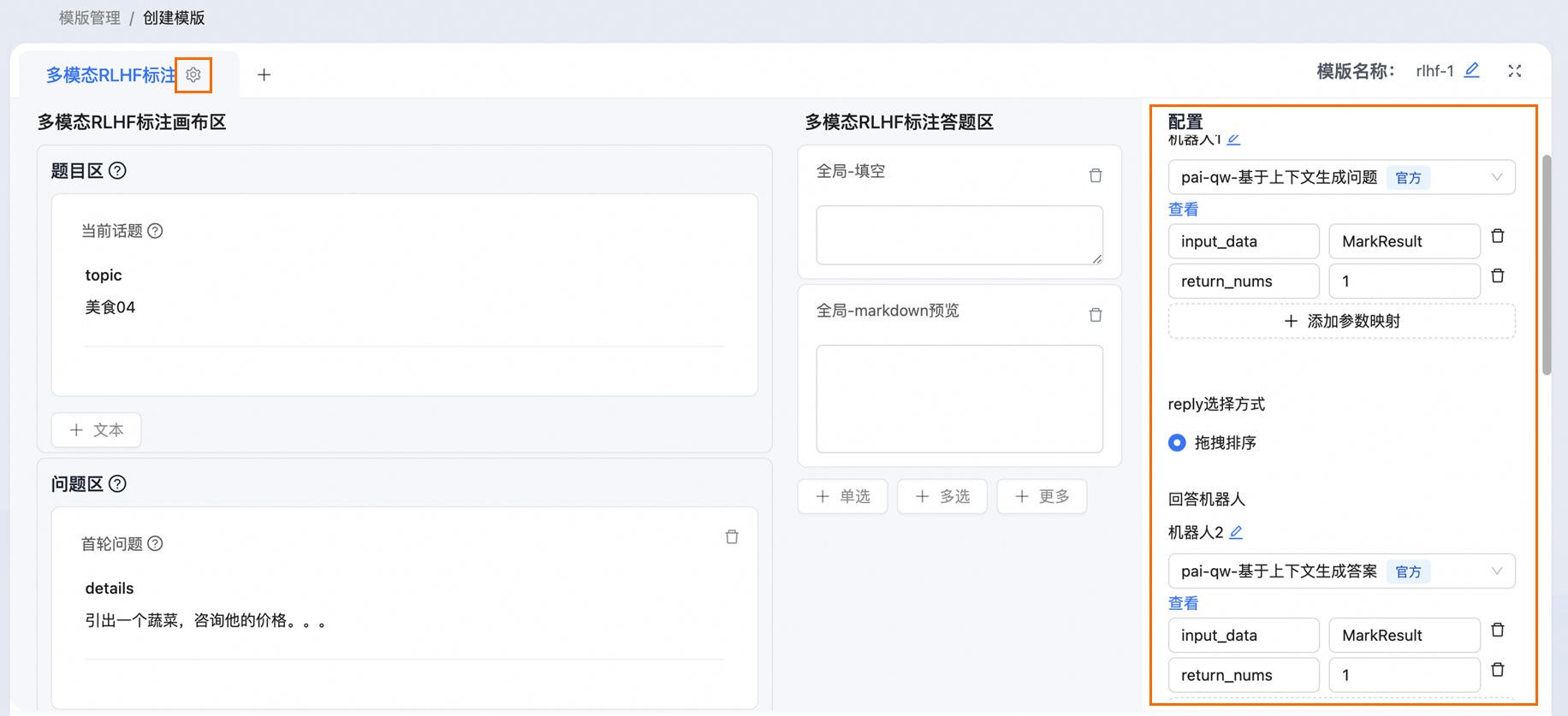
单击 ,在右侧配置问答机器人,回答机器人最多可以配置3个。选择机器人的UDF之后添加配置参数即可。
,在右侧配置问答机器人,回答机器人最多可以配置3个。选择机器人的UDF之后添加配置参数即可。
在自动问答模式下,配置了首轮问题后需要配置提问机器人的UDF信息。提问机器人的UDF使用pai-qw-基于上下文生成问题,其余参数与回答机器人相同,input_data及MarkResult用于让UDF正确接收输入参数,不可随意更改;return_nums为返回个数,可自行修改,最多不超过5。
操作演示
多模态RLHF标注-自动问答
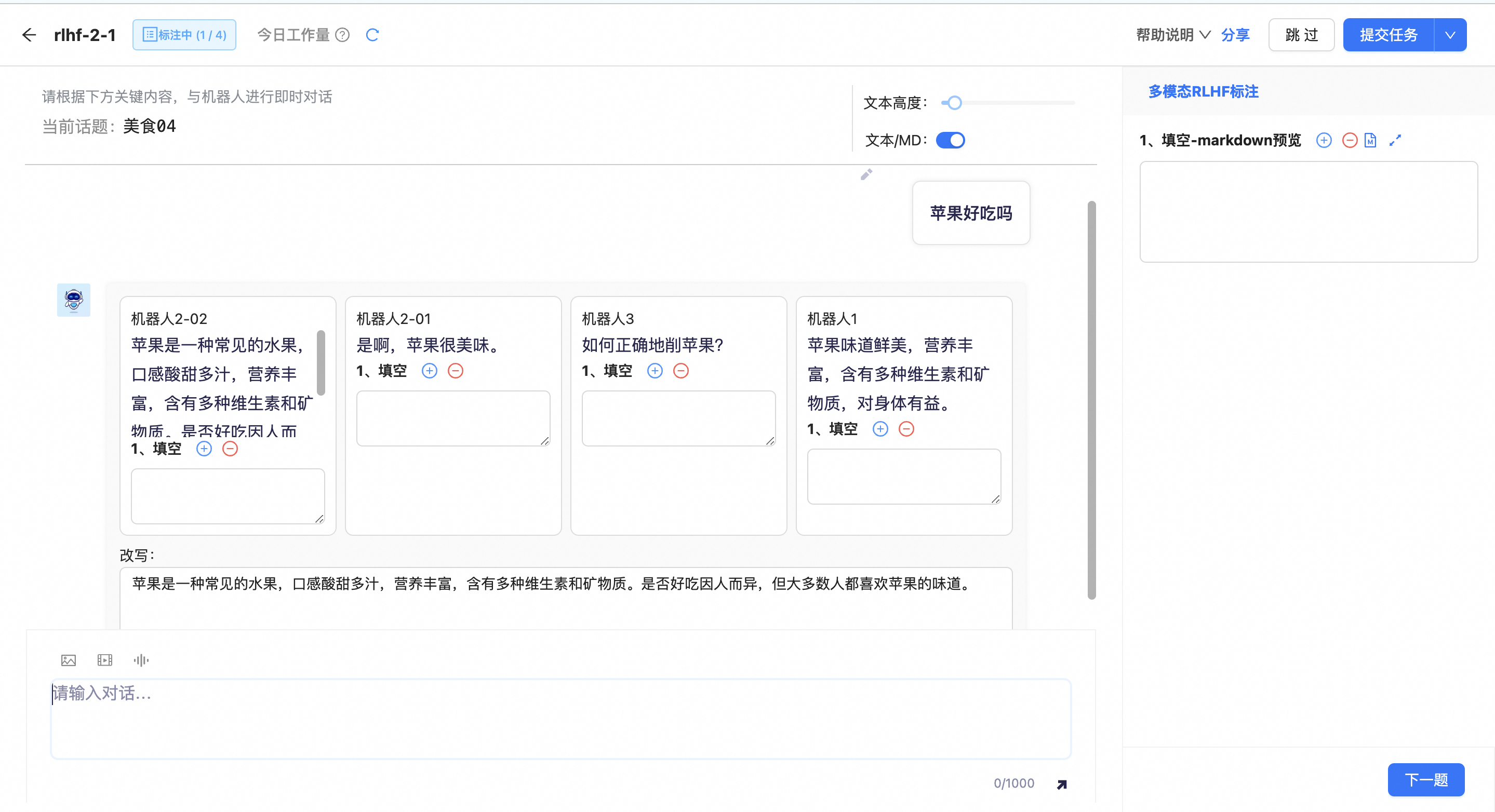
单击发起问答后,机器人会自动发起问答。
用户可对发起的问题进行改写,同时也可对机器人的回答进行改写,并完成配置好的答题。
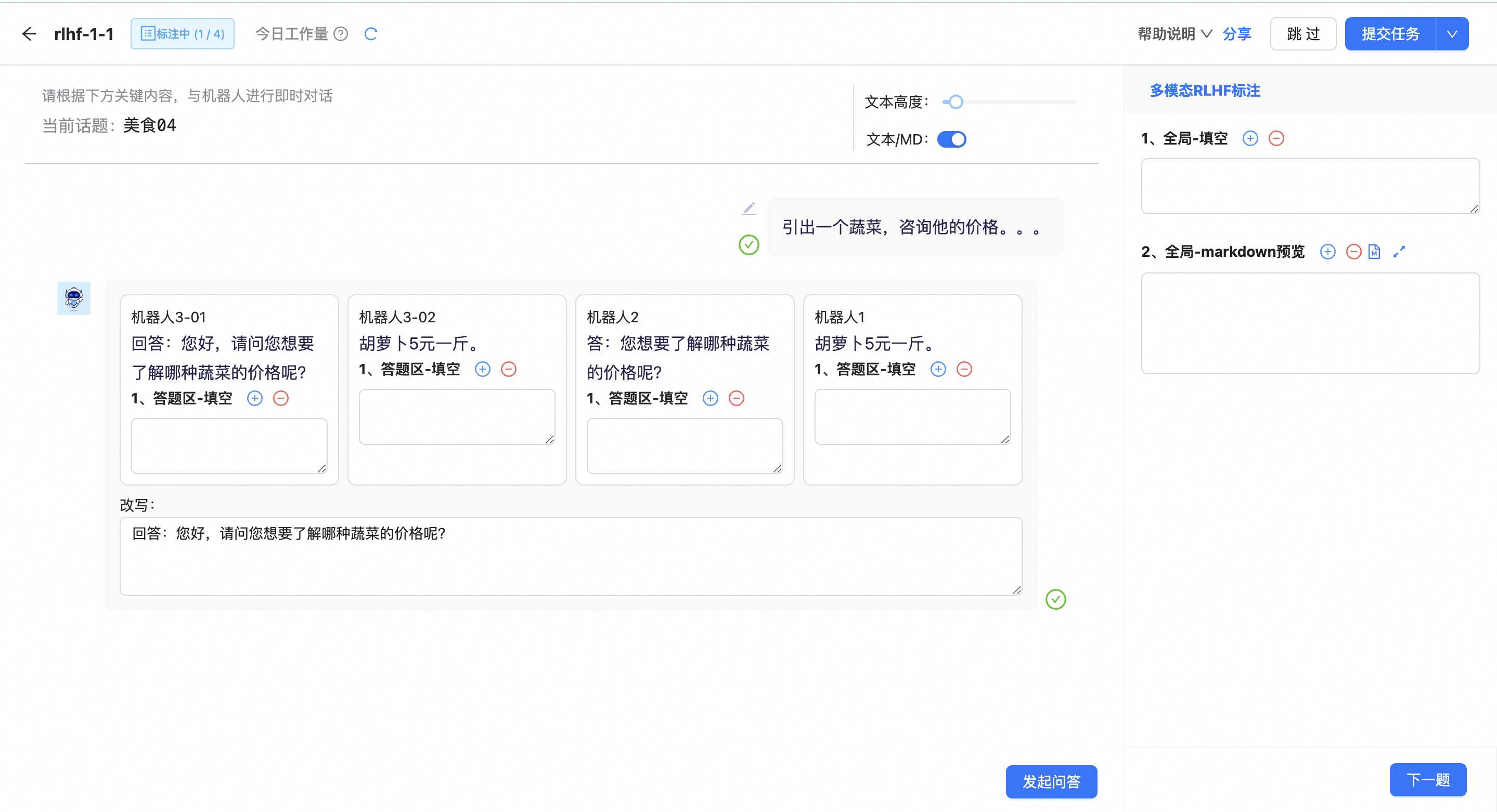
多模态RLHF标注-输入问答
用户可在对话框内输入文字,或上传图片、视频、音频等。
用户可根据机器人的回答,对其进行改写并进行答题;单击历史发送输入框,可对已经发送的post进行修改,使机器人重新回答。