
在大语言模型(LLM)应用场景中,存在资源需求不确定性、后端推理实例负载不均衡等问题。为了优化这类问题,EAS引入了LLM智能路由基础组件,在请求调度层,基于LLM场景所特有的Metrics(指标),来动态进行请求分发,保证后端推理实例处理的算力和显存尽可能均匀,提升集群资源使用水位。
背景信息
在大语言模型应用场景中,用户请求与模型响应的长度差异,以及模型在Prompt提示和Generate生成阶段产生的Token数量的随机性,导致单个请求所占用的GPU资源量不确定。传统网关的负载均衡策略,如轮询(Round-Robin)和最少连接(Least-Connection),因无法实时感知后端算力资源的负载压力,从而导致后端推理实例的负载不均衡,影响系统吞吐量和响应延时。尤其是耗时较长、GPU计算量较大或占用GPU显存较高的长尾请求,会进一步加剧资源分配不均衡的问题,降低了集群的整体效能。
为有效优化上述问题,EAS在请求调度层面提供了LLM智能路由这一基础组件。该组件针对LLM场景所特有的Metrics来动态进行请求分发,确保各个推理实例的计算力与显存资源得到均衡分配,从而显著提升集群资源的利用效率与稳定性。
工作原理
工作原理图

工作流程
LLM智能路由服务内部会默认内置一个LLM-Scheduler对象,用于实际汇集推理实例的Metrics(指标),并基于Metrics数据通过一定的算法来选择全局最优的实例用于LLM-智能路由转发请求。
LLM-Scheduler同时也会与推理实例之间建立保活链接,推理实例异常时会第一时间被感知到并停止转发流量。
LLM-智能路由根据LLM-Scheduler的指示进行请求转发,支持HTTP(SSE)和WebSocket协议。
Metrics接口说明
LLM智能路由的调度算法根据后端不同推理实例的Metrics进行请求调度,综合选出尽可能空闲的实例。要使用LLM智能路由,则要求推理实例中必须实现Metrics接口,并按要求输出相关的指标。目前LLM智能路由已兼容了vLLM和BladeLLM的Metrics接口。
以vLLM推理框架为例,其Metrics接口的输出结果如下:
# HELP vllm:num_requests_running Number of requests currently running on GPU.
# TYPE vllm:num_requests_running gauge
vllm:num_requests_running{model_name="Llama-2-7b-chat-hf"} 30.0
# HELP vllm:num_requests_swapped Number of requests swapped to CPU.
# TYPE vllm:num_requests_swapped gauge
vllm:num_requests_swapped{model_name="Llama-2-7b-chat-hf"} 0.0
# HELP vllm:num_requests_waiting Number of requests waiting to be processed.
# TYPE vllm:num_requests_waiting gauge
vllm:num_requests_waiting{model_name="Llama-2-7b-chat-hf"} 0.0
# HELP vllm:gpu_cache_usage_perc GPU KV-cache usage. 1 means 100 percent usage.
# TYPE vllm:gpu_cache_usage_perc gauge
vllm:gpu_cache_usage_perc{model_name="Llama-2-7b-chat-hf"} 0.8426270136307311
# HELP vllm:prompt_tokens_total Number of prefill tokens processed.
# TYPE vllm:prompt_tokens_total counter
vllm:prompt_tokens_total{model_name="Llama-2-7b-chat-hf"} 15708.0
# HELP vllm:generation_tokens_total Number of generation tokens processed.
# TYPE vllm:generation_tokens_total counter
vllm:generation_tokens_total{model_name="Llama-2-7b-chat-hf"} 13419.0LLM-Scheduler会将上述指标数据进行转换和计算,并依据计算结果对后端推理实例进行优先级排序,LLM-智能路由访问LLM-Scheduler时获取优先级最高的后端推理实例进行转发。
支持的LLM推理框架以及对应的采集指标如下:
LLM智能路由也可以与其他推理框架配合使用,只要该框架能兼容以下指标,LLM智能路由就可以正常运行并有效地进行请求调度。
LLM推理引擎 | 指标 | 说明 |
vLLM | vllm:num_requests_running | 正在运行的请求数。 |
vllm:num_requests_waiting | 在排队等待的请求数。 | |
vllm:gpu_cache_usage_perc | GPU KV Cache的使用率。 | |
vllm:prompt_tokens_total | 总Prompt的Token数。 | |
vllm:generation_tokens_total | 总Generate的Token数。 | |
BladeLLM | decode_batch_size_mean | 正在运行的请求数。 |
wait_queue_size_mean | 在排队等待的请求数。 | |
block_usage_gpu_mean | GPU KV Cache的使用率。 | |
tps_total | 每秒总共处理的Token数。 | |
tps_out | 每秒Generate的Token数。 |
部署服务
部署LLM智能路由服务
使用EASCMD客户端部署LLM智能路由服务。如何登录EASCMD客户端,请参见下载并认证客户端。准备以下部署LLM智能路由服务需要使用的JSON文件,并参考创建服务文档部署EAS服务。
为了防止单点故障,建议您将metadata.instance至少设置为2,以确保智能路由能够多实例运行。
如果先部署LLM智能路由服务,该服务将保持等待状态直至大语言模型(LLM)服务部署成功。
基础配置:
{ "cloud": { "computing": { "instance_type": "ecs.c7.large" } }, "metadata": { "type": "LLMGatewayService", "cpu": 4, "group": "llm_group", "instance": 2, "memory": 4000, "name": "llm_router" } }您只需将metadata.type配置为LLMGatewayService,即可部署LLM智能路由服务。其他参数配置说明,请参见服务模型所有相关参数说明。服务部署成功后,EAS会自动创建一个组合服务,包含LLM-智能路由和LLM-Scheduler,其中LLM-智能路由的资源配置使用的就是该服务的配置;LLM-Scheduler默认的资源配置为4核CPU和4 GiB内存。
高阶配置:如果基础配置无法满足您的需求,您还可以参考以下高阶配置,准备JSON文件:
{ "cloud": { "computing": { "instance_type": "ecs.c7.large" } }, "llm_gateway": { "infer_backend": "vllm", "max_queue_size": 128, "retry_count": 2, "wait_schedule_timeout": 5000, "wait_schedule_try_period": 500 }, "llm_scheduler": { "cpu": 4, "memory": 4000 }, "metadata": { "cpu": 2, "group": "llm_group", "instance": 2, "memory": 4000, "name": "llm_router", "type": "LLMGatewayService" } }其中关键配置说明如下,其他参数配置说明,请参见服务模型所有相关参数说明。
配置
说明
llm_gateway.infer_backend
大语言模型使用的推理框架,支持:
vllm(默认值)
bladellm
llm_gateway.max_queue_size
LLM智能路由缓存队列的最大长度,默认是128。
当超过后端推理框架处理能力时,待有可用推理实例时进行调度转发。
llm_gateway.retry_count
重试次数,默认是2。当后端推理实例异常时,进行请求重试并转发到新的实例。
llm_gateway.wait_schedule_timeout
超时时间,默认为5000毫秒。当LLM-Scheduler不可用时间达到超时时间后,LLM-智能路由使用简单的Round-Robin策略进行请求分发。
llm_gateway.wait_schedule_try_period
当LLM-Scheduler不可用时,系统在wait_schedule_timeout超时时间内的重试频率,默认为500毫秒。
llm_scheduler.cpu
指定LLM-Scheduler的CPU,默认为4核。
llm_scheduler.memory
指定LLM-Scheduler的Memory,默认为4 GiB。
llm_scheduler.instance_type
指定LLM-Scheduler的实例规格。该规格已经定义了CPU核数和内存大小,无需单独配置CPU和Memory。
部署大语言模型(LLM)服务
本方案以PAI提供的预置镜像-开源vLLM-0.3.3版本为例,使用EASCMD客户端部署大语言模型(LLM)服务。如何登录EASCMD客户端,请参见下载并认证客户端。
准备以下JSON文件,并参考创建服务文档部署EAS服务。
{
"cloud": {
"computing": {
"instance_type": "ecs.gn7i-c16g1.4xlarge"
}
},
"containers": [
{
"image": "eas-registry-vpc.<regionid>.cr.aliyuncs.com/pai-eas/chat-llm:vllm-0.3.3",
"port": 8000,
"script": "python3 -m vllm.entrypoints.openai.api_server --served-model-name llama2 --model /huggingface/models--meta-llama--Llama-2-7b-chat-hf/snapshots/c1d3cabadba7ec7f1a9ef2ba5467ad31b3b84ff0/"
}
],
"features": {
"eas.aliyun.com/extra-ephemeral-storage": "50Gi"
},
"metadata": {
"cpu": 16,
"gpu": 1,
"instance": 5,
"memory": 60000,
"group": "llm_group",
"name": "vllm_service"
}
}其中关键配置说明如下,其他参数配置说明,请参见服务模型所有相关参数说明。
metadata.group:本方案配置为llm_group,您也可以修改为其他群组名称,但必须与LLM智能路由在同一个群组下。这样LLM服务才能向LLM-Scheduler进行注册,并上报相关的Metric(指标),同时LLM智能路由才能进行流量转发。
containers.image:本方案使用PAI提供的预置镜像,您需要将<regionid>替换为实际服务所在地域的ID,例如华北2(北京)配置为cn-beijing。
访问服务
获取服务访问地址和Token
进入模型在线服务页面。
登录PAI控制台。
在左侧导航栏单击工作空间列表,在工作空间列表页面中单击待操作的工作空间名称,进入对应工作空间内。
在工作空间页面的左侧导航栏选择模型部署>模型在线服务(EAS),进入模型在线服务(EAS)页面。

单击LLM智能路由服务的服务方式列下的调用信息。
在调用信息对话框的公网地址调用页签,查询服务访问地址和Token。
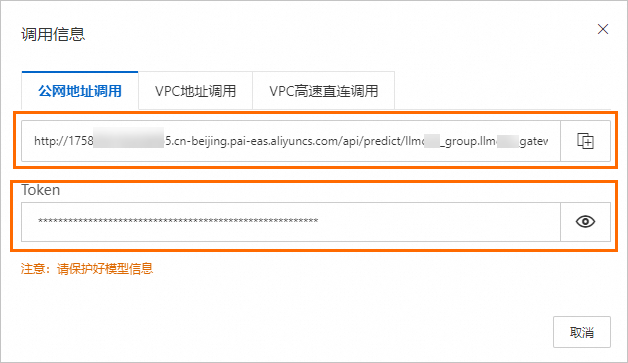
配置访问LLM智能路由服务的访问地址。
访问地址配置规则
示例值
配置规则为:
{domain}/api/predict/{group_name}.{router_service_name}_llm_gateway/{endpoint}其中{endpoint}值需要根据您的LLM服务的API接口支持情况来进行配置,例如:
v1/completions。以上述部署的LLM智能路由服务为例,步骤3的查询结果为
http://175805416243****.cn-beijing.pai-eas.aliyuncs.com/api/predict/llm_group.llm_router,则服务访问地址为http://175805416243****.cn-beijing.pai-eas.aliyuncs.com/api/predict/llm_group.llm_router_llm_gateway/v1/completions。
访问测试
在终端中,执行以下命令访问服务。
$curl -H "Authorization: xxxxxx" -H "Content-Type: application/json" http://***http://********.cn-beijing.pai-eas.aliyuncs.com/api/predict/{group_name}.{router_service_name}_llm_gateway/v1/completions -d '{"model": "llama2", "prompt": "I need your help writing an article. I will provide you with some background information to begin with. And then I will provide you with directions to help me write the article.", "temperature": 0.0, "best_of": 1, "n_predict": 34, "max_tokens": 34, "stream": true}'其中:
"Authorization: xxxxxx":需要配置为上述步骤已获取的Token。
http://********.cn-beijing.pai-eas.aliyuncs.com/api/predict/{group_name}.{router_service_name}_llm_gateway/v1/completions:更新为上述步骤已配置的访问地址。
返回结果示例如下:
data: {"id":"0d9e74cf-1025-446c-8aac-89711b2e9a38","choices":[{"finish_reason":"","index":0,"logprobs":null,"text":"\n"}],"object":"text_completion","usage":{"prompt_tokens":36,"completion_tokens":1,"total_tokens":37},"error_info":null}
data: {"id":"0d9e74cf-1025-446c-8aac-89711b2e9a38","choices":[{"finish_reason":"","index":0,"logprobs":null,"text":"\n"}],"object":"text_completion","usage":{"prompt_tokens":36,"completion_tokens":2,"total_tokens":38},"error_info":null}
data: {"id":"0d9e74cf-1025-446c-8aac-89711b2e9a38","choices":[{"finish_reason":"","index":0,"logprobs":null,"text":""}],"object":"text_completion","usage":{"prompt_tokens":36,"completion_tokens":3,"total_tokens":39},"error_info":null}
...
[DONE]请查阅附录:测试结果对比,了解采用LLM智能路由与否的性能差异详情。
查看服务监控指标
服务测试完成后,您可以通过查看服务监控指标,来了解服务的性能。具体操作步骤如下:
在模型在线服务(EAS)页面,单击已部署的LLM智能路由服务的服务监控列下的
 。
。在服务监控页签,查看以下指标信息。
Token Throughput
LLM输入和输出Token的Throughout
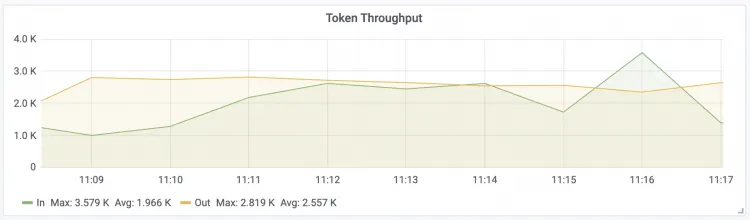
IN:表示LLM输入Token的吞吐量。
OUT:表示LLM输出Token的吞吐量。
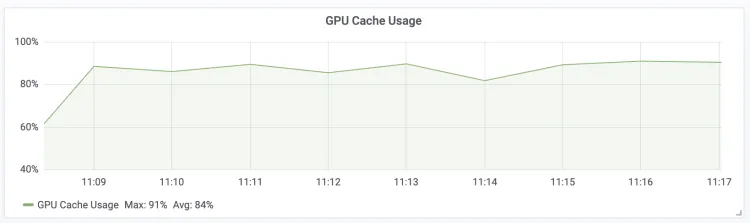
GPU Cache Usage
LLM Engine GPU KV Cache的使用率
Engine Current Requests
LLM Engine实时请求并发数
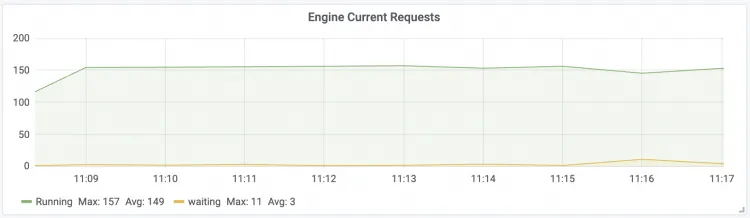
Running:LLM Engine正在执行的请求数量。
Waiting:LLM Engine等待队列中的请求数量。
Gateway Current Requests
LLM智能路由实时请求数
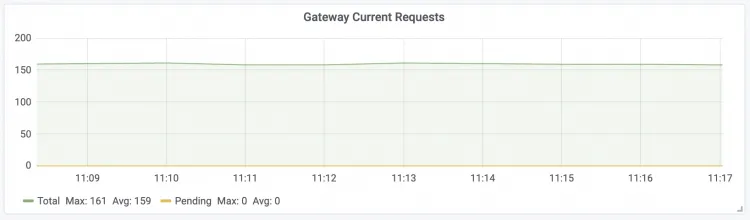
Total:LLM智能路由当前总共接收的请求数量(总实时并发数)。
Pending:LLM Engine未处理的缓存在LLM智能路由中的请求数。
Time To First Token
请求的首包延时
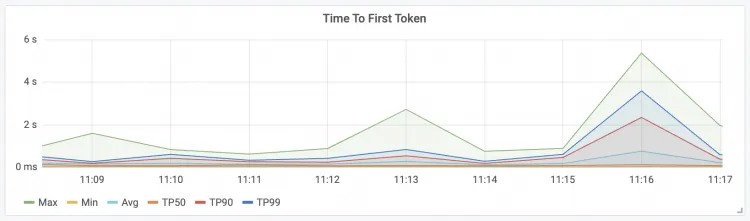
Max:请求首包延迟的最大值。
Avg:请求首包延迟的平均值。
Min:请求首包延迟的最小值。
TPxx:请求首包延迟的各个分位点值。
Time Per Output Token
请求的每包延时
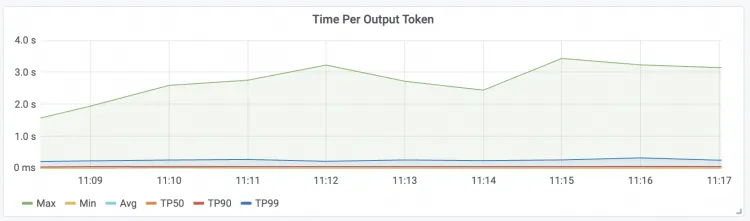
Max:请求每包延迟的最大值。
Avg:请求每包延迟的平均值。
Min:请求每包延迟的最小值。
TPxx:请求每包延迟的各个分位点值。