
XGBoost算法在Boosting算法的基础上进行了扩展和升级,具有较好的易用性和鲁棒性,被广泛用在各种机器学习生产系统和竞赛领域,该算法支持分类和回归。XGBoost训练组件在XGBoost算法的基础上进行了包装,使功能和PAI更兼容,更易用。本文为您介绍XGBoost训练组件的配置方法。
使用限制
支持的计算引擎为MaxCompute、Flink和DLC。
数据格式
当前支持Table格式和LibSVM格式的数据。
Table格式示例如下:
f0
f1
label
0.1
1
0
0.9
2
1
LibSVM格式示例如下:
示例数据
2:1 9:1 10:1 20:1 29:1 33:1 35:1 39:1 40:1 52:1 57:1 64:1 68:1 76:1 85:1 87:1 91:1 94:1 101:1 104:1 116:1 123:1
0:1 9:1 18:1 20:1 23:1 33:1 35:1 38:1 41:1 52:1 55:1 64:1 68:1 76:1 85:1 87:1 91:1 94:1 101:1 105:1 115:1 121:1
2:1 8:1 18:1 20:1 29:1 33:1 35:1 39:1 41:1 52:1 57:1 64:1 68:1 76:1 85:1 87:1 91:1 94:1 101:1 104:1 116:1 123:1
2:1 9:1 13:1 21:1 28:1 33:1 36:1 38:1 40:1 53:1 57:1 64:1 68:1 76:1 85:1 87:1 91:1 94:1 97:1 105:1 113:1 119:1
0:1 9:1 18:1 20:1 22:1 33:1 35:1 38:1 44:1 52:1 55:1 64:1 68:1 76:1 85:1 87:1 91:1 94:1 101:1 104:1 115:1 121:1
0:1 8:1 18:1 20:1 23:1 33:1 35:1 38:1 41:1 52:1 55:1 64:1 68:1 76:1 85:1 87:1 91:1 94:1 101:1 105:1 116:1 121:1
可视化配置组件参数
Designer支持通过可视化方式,配置XGBoost训练组件参数。
页签 | 参数名称 | 类型 | 参数描述 |
字段设置 | 标签列名 | 字符串 | 标签列名。 |
特征列名数组 | 字符串数组 | 表格数据中特征列。和向量列名互斥,代表输入数据的格式为表格数据。 | |
向量列名 | 字符串 | LibSVM格式数据列名,和特征列名数组互斥。代表输入数据的格式为LibSVM数据。 | |
权重列名 | 字符串 | 权重列对应的列名。 | |
设置模型路径 | 字符串 | 设置模型存储的OSS Bucket路径。 | |
参数设置 | 训练的轮数 | 整型数值 | 训练的轮数。 |
objective | 字符串 | 目标函数,默认值为binary:logistic。 | |
Base score | 浮点数值 | 全局bias,默认值为0.5。 | |
类别数 | 整型数值 | 多分类中类别个数。 | |
构建树的方法 | 字符串 | 构建树的方法,取值如下。
| |
L1 正则项 | 浮点数值 | L1正则项,默认值为0.0。 | |
L2 正则项 | 浮点数值 | L2正则项,默认值为1.0。 | |
学习率 | 浮点数值 | 学习率,默认值为0.3。 | |
scale_pos_weight | 浮点数值 | 控制正负样本比例,默认值为1.0。 | |
sketch_eps | 浮点数值 | 构建树方法为approx时,控制分箱个数,默认值为0.03。 | |
连续特征的最大分割箱数 | 整型数值 | 构建树方法为hist时,控制分箱个数,默认值为256。 | |
树的最大深度 | 整型数值 | 树的最大深度,默认值为6。 | |
最大节点个数 | 整型数值 | 叶节点最大个数,默认值为0。 | |
节点的最小权重 | 浮点数值 | 节点的最小权重,默认值为1.0。 | |
Max delta step | 浮点数值 | 叶节点的最大步长,可以调节模型精细度,默认值为0.0。 | |
样本采样比例 | 浮点数值 | 样本采样比例,默认值为1。 | |
采样方法 | 字符串 | 样本采样方法,取值如下。
| |
每一层的列采样比例 | 浮点数值 | 按层进行列采样的比例,默认值为1.0。 | |
每个节点的列采样比例 | 浮点数值 | 按节点进行列采样的比例,默认值为1.0。 | |
每棵树的列采样比例 | 浮点数值 | 按树进行列采样的比例,默认值为1.0。 | |
Grow Policy | 字符串 | 树生长的规则,取值如下。
| |
节点分裂最小损失变化 | 浮点数值 | 最小分裂loss,默认值为0.0。 | |
交互约束 | 字符串 | interaction约束。 | |
单调约束 | 字符串 | monotone约束。 | |
Tweedie variance power | 浮点数值 | Tweedie分布方差。Tweedie分布中有效。默认值为1.5。 | |
执行调优 | 节点个数 | 正整数 | 与单个节点内存大小参数配对使用。取值范围为[1, 9999]。 |
单个节点内存大小 | 正整数 | 单位为兆。取值范围为[1024, 64*1024]。 |
使用示例
本示例使用Designer预置模板,通过希格斯玻色子事件的分类场景,介绍如何在Designer中使用XGBoost算法。关于如何创建使用XGBoost算法探究希格斯玻色子事件分类案例工作流,请参见创建工作流:预置模板。
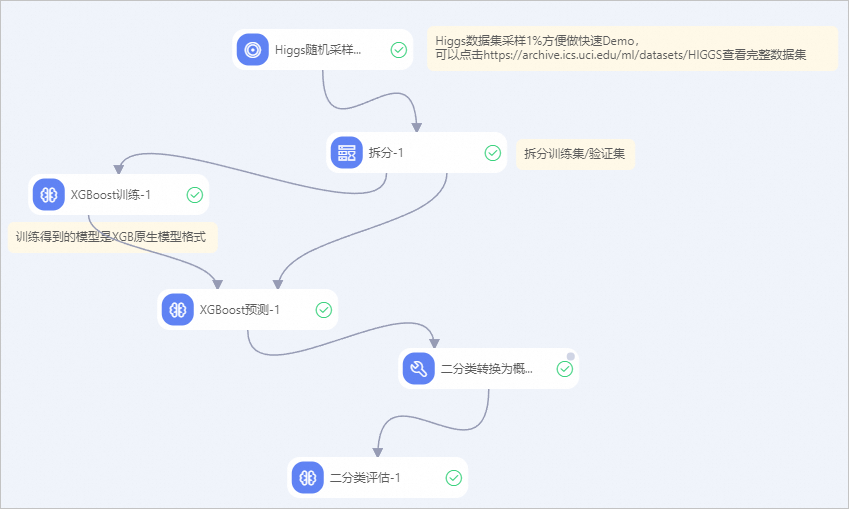
其中:
XGBoost预测组件输出为原生XGBoost库输出的JSON序列化,如果您想在工作流中接入二分类评估组件,您需要在XGBoost预测组件的下游接入SQL脚本组件,并配置以下代码,将XGBoost预测组件输出的JSON序列化转换为二分类评估组件需要的格式。
set odps.sql.udf.getjsonobj.new=true;
select *, CONCAT("{\"0\":", 1.0-prob, ",\"1\":", prob, "}") as detail
FROM (
select *, cast(get_json_object(pred, '$[0]') as double) as prob FROM ${t1})相关文档
您可以使用XGBoost预测组件对生成的XGB原生格式的模型进行离线推理。关于XGBoost预测组件的配置方法,请参见XGBoost预测。
Designer预置了多种算法组件,您可以根据不同的使用场景选择合适的组件进行数据处理,详情请参见组件参考:所有组件汇总。