
PolarDB通过DDL物理复制优化功能,在主节点写物理日志和只读节点应用物理日志的关键路径上进行了全面优化,大大缩短了主节点上DDL操作的执行时间和只读节点上解析DDL的物理日志复制延迟时间。本文介绍如何使用DDL物理复制优化功能。
前提条件
PolarDB集群版本需为以下版本之一,您可以通过查询版本号确认集群版本:
PolarDB MySQL版8.0.1版本且Revision version为8.0.1.1.10及以上。
PolarDB MySQL版5.7版本且Revision version为5.7.1.0.10及以上。
使用限制
目前并行DDL物理复制优化仅支持创建主键或二级索引(不包括全文索引和空间索引)的DDL操作。
对于只需修改元数据的DDL操作(如rename),因其本身执行速度已经很快,无需使用该优化功能。
不支持在PolarDB MySQL版8.0.2版本和5.6版本使用该优化功能。
背景信息
PolarDB通过存储计算分离架构,实现了主节点和只读节点共享同一份存储数据,既降低了存储成本,又提高了集群的可用性和可靠性。为实现这一架构,PolarDB采用了业界领先的物理复制技术,不仅实现了共享存储架构上主节点和只读节点间的数据一致性,而且减少了Binlog fsync操作带来的I/O开销。
InnoDB中的数据是通过B-Tree来维护索引的,然而大部分Slow DDL操作(如增加主键或二级索引、optimize table等)往往需要重建或新增B-Tree索引,导致大量物理日志的产生。而针对物理日志进行的操作往往出现在DDL执行的关键路径上,增加了DDL操作的执行时间。此外,物理复制技术要求只读节点解析和应用这些新生成的物理日志,由于DDL操作而产生的大量物理日志可能严重影响只读节点的日志同步进程,甚至导致只读节点不可用等问题。
针对上述问题,PolarDB提供了DDL物理复制优化功能,在主节点写物理日志和只读节点应用物理日志的关键路径上做了全面的优化,使得主节点在执行创建主键DDL操作的执行时间最多可减少20.6%,只读节点解析DDL的复制延迟时间最多约可减少至原来的0.4%。
使用方法
您可以通过设置如下参数开启DDL物理复制优化功能。
参数 | 级别 | 说明 |
innodb_bulk_load_page_grained_redo_enable | Global | DDL物理复制优化功能开关,取值范围如下:
|
性能测试
测试准备
测试环境
PolarDB MySQL版8.0版本的集群(包含1个主节点和1个只读节点)规格为16核128 GB。
集群存储空间为50 TB。
测试表结构
通过如下语句创建一张名为
t0的表:CREATE TABLE t0(a INT PRIMARY KEY, b INT) ENGINE=InnoDB;测试表数据
使用如下语句生成随机测试数据:
DELIMITER // CREATE PROCEDURE populate_t0() BEGIN DECLARE i int DEFAULT 1; WHILE (i <= $table_size) DO INSERT INTO t0 VALUES (i, 1000000 * RAND()); SET i = i + 1; END WHILE; END // DELIMITER ; CALL populate_t0();说明实际测试时请将
$table_size替换成具体的表内记录数,如1000000。本测试分别使用了包含1000000行、10000000行、100000000行、1000000000行记录数的表。
测试使用的DDL操作
add primary keyadd secondary Indexoptimize table
测试方法
测试一:测试当物理复制DDL优化功能开启或关闭时,在不同数据量的表中执行不同DDL操作所需的时间。
测试二:测试当物理复制DDL优化功能与并行DDL配合使用时,在包含10亿数据量的表中执行
add secondary Index操作所需的时间。测试三:测试当物理复制DDL优化功能开启或关闭时,集群(包含10亿数据量的表)中主节点的并发执行DDL操作数量不同的情况下(1、2、4、6和8),只读节点的性能(如节点状态是否正常、CPU使用率峰值和复制延迟时间等)。
测试结果
测试一
当innodb_bulk_load_page_grained_redo_enable参数开启或关闭时,测试在不同数据量(1百万、1千万、1亿和10亿)的表中执行
add primary key(a)操作所需的时间(单位:秒),结果如下图所示。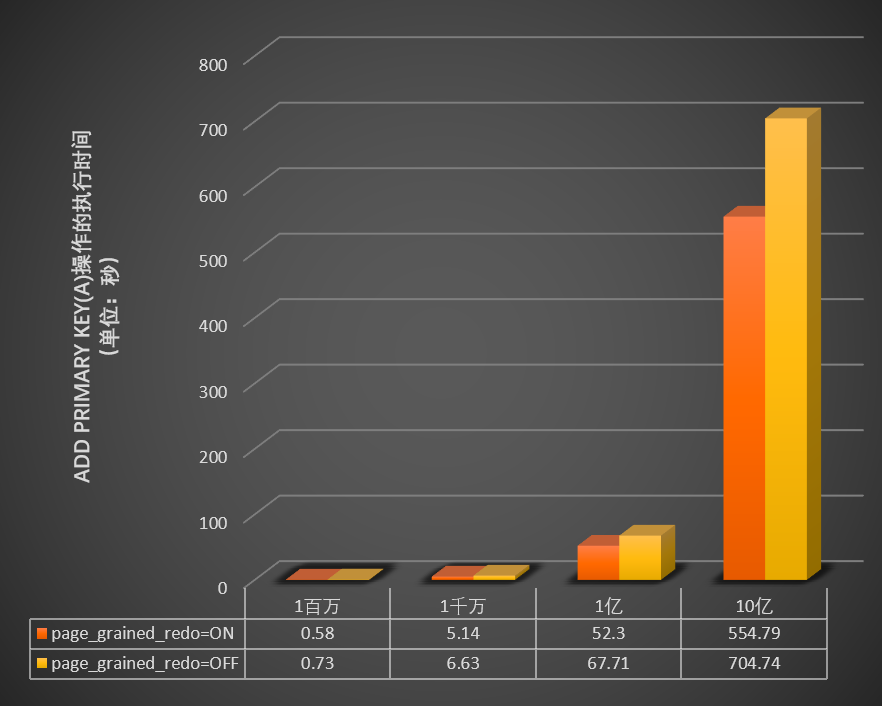
当innodb_bulk_load_page_grained_redo_enable参数开启或关闭时,测试在不同数据量(1百万、1千万、1亿和10亿)的表中执行
optimize table操作所需的时间(单位:秒),结果如下图所示。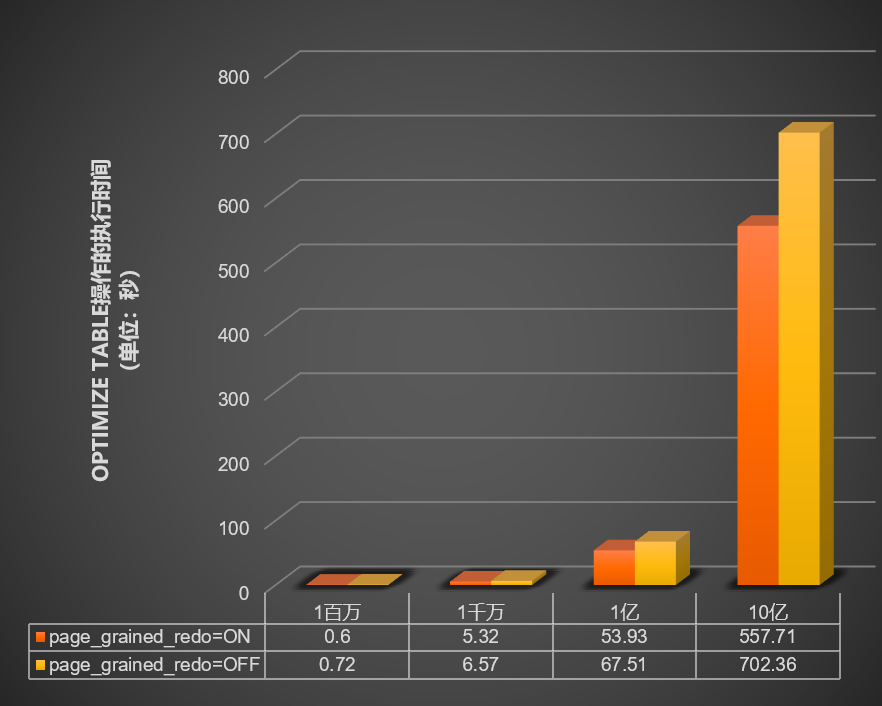
测试二
并行DDL的innodb_polar_use_sample_sort和innodb_polar_use_parallel_bulk_load参数开启的情况下,测试innodb_bulk_load_page_grained_redo_enable参数开启或关闭后,在包含10亿数据量的表中使用不同并行线程数(即设置innodb_polar_parallel_ddl_threads参数为1、2、4、8、16和32),执行
add secondary Index操作所需的时间(单位:秒),结果如下图所示。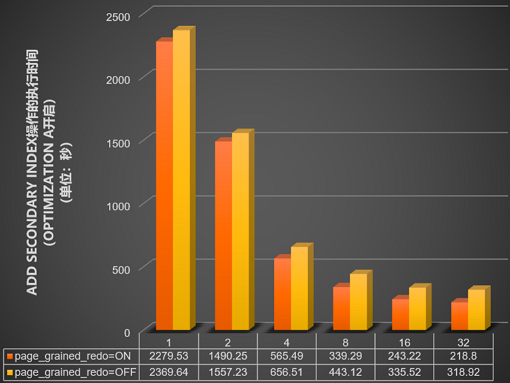
并行DDL的innodb_polar_use_sample_sort和innodb_polar_use_parallel_bulk_load参数关闭的情况下,测试innodb_bulk_load_page_grained_redo_enable参数开启或关闭后,在包含10亿数据量的表中使用不同并行线程数(1、2、4、8、16和32),执行
add secondary Index操作所需的时间(单位:秒),结果如下图所示。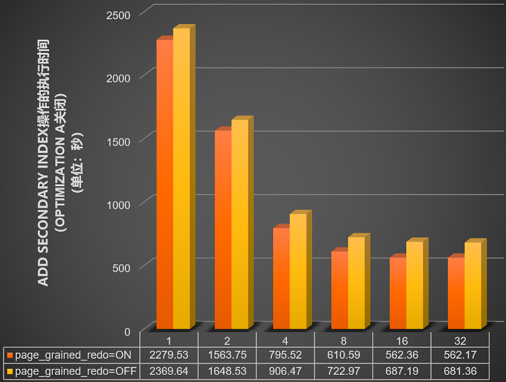
测试三
innodb_bulk_load_page_grained_redo_enable参数开启的情况下,测试当集群(包含10亿数据量的表)中主节点的并发执行DDL操作数量不同(1、2、4、6和8)时只读节点的性能,结果如下表所示。
并发DDL数量
1
2
4
6
8
只读节点状态
正常
正常
正常
正常
正常
CPU使用率峰值(单位:%)
1.86
1.71
1.76
2.25
2.36
内存使用率峰值(单位:%)
10.37
10.80
10.88
11
11.1
读IOPS峰值(单位:次/每秒)
10965
10762
10305
10611
10751
复制延迟峰值(单位:秒)
0
0.73
0.87
0.93
0.03
innodb_bulk_load_page_grained_redo_enable参数关闭的情况下,测试当集群(包含10亿数据量的表)中主节点的并发执行DDL操作数量不同(1、2、4、6和8)时只读节点的性能,结果如下表所示。
说明并发DDL数为4时的数据为只读节点不可用前的测试数据。
表中
-符号表示在当前并发DDL数场景下未能执行相关DDL操作,因此无相应测试数据。
并发DDL数
1
2
4
6
8
只读节点状态
正常
正常
不可用
不可用
不可用
CPU使用率峰值(单位:%)
4.2
9.5
10.3
-
-
内存使用率峰值(单位:%)
22.15
23.55
68.61
-
-
读IOPS峰值(单位:次/每秒)
9243
7578
7669
-
-
复制延迟峰值(单位:秒)
0.8
14.67
211
-
-
联系我们
若您对DDL操作有任何疑问,可通过钉钉搜索群号入群咨询。您可以直接@群内专家,并附上您要咨询的问题;同时群内也有PolarDB MySQL版小助手24*7小时在线回答您的问题。钉钉群号:15375044501。