兼容PolarDB PostgreSQL版(兼容Oracle)的Debezium connector(简称Debezium PolarDBO connector),可用于捕获PolarDB PostgreSQL版(兼容Oracle)数据库中的行级别更改,生成数据更改事件记录,并将它们流式传输到Kafka Topic中。具体功能及用法请参考社区Debezium PostgreSQL connector。
由于PolarDB PostgreSQL版(兼容Oracle)与社区PostgreSQL仅在少量数据类型和内置对象处理存在差异,本文为您介绍如何基于社区Debezium PostgreSQL connector,通过少量代码适配打包出支持PolarDB PostgreSQL版(兼容Oracle)的Debezium connector。
打包Debezium PolarDBO connector
Debezium PolarDBO connector基于社区Debezium PostgreSQL connector适配开发,无论是您自行打包,还是使用本文中提供的JAR包,Debezium PolarDBO connector都不提供SLA保障。
操作前提
配置Java环境
目前Debezium各版本均要求Java11及以上版本,请在打包和正式运行时提前配置Java11环境。
确定Debezium版本
根据您使用的Kafka/Kafka Connect和PolarDB PostgreSQL版(兼容Oracle)版本,确定Debezium版本。具体的版本兼容信息,请参考Debezium发布概览。
说明Debezium代码仓库请参考Debezium。
对于PolarDB PostgreSQL版(兼容Oracle)匹配的社区版本如下:
Oracle语法兼容 2.0对应社区PostgreSQL 14。
Oracle语法兼容 1.0对应社区PostgreSQL 11。
确定PgJDBC版本
在对应版本的Debezium的
pom.xml中通过查找关键字version.postgresql.driver确定PgJDBC版本。说明PgJDBC代码仓库请参考PgJDBC。
操作步骤
社区Debezium 2.6.2.Final支持Kafka Connect 2.x、3.x版本,支持PostgreSQL 10、11、12、13、14、15、16版本。
接下来以社区Debezium 2.6.2.Final版本为例,为您介绍具体的打包步骤:
克隆对应版本的Debezium和PgJDBC的代码文件。
git clone -b v2.6.2.Final --depth=1 https://github.com/debezium/debezium.git git clone -b REL42.6.1 --depth=1 https://github.com/pgjdbc/pgjdbc.git复制PgJDBC部分文件到Debezium中。
mkdir -p debezium/debezium-connector-postgres/src/main/java/org/postgresql/core/v3 mkdir -p debezium/debezium-connector-postgres/src/main/java/org/postgresql/jdbc cp pgjdbc/pgjdbc/src/main/java/org/postgresql/core/v3/ConnectionFactoryImpl.java debezium/debezium-connector-postgres/src/main/java/org/postgresql/core/v3 cp pgjdbc/pgjdbc/src/main/java/org/postgresql/core/v3/QueryExecutorImpl.java debezium/debezium-connector-postgres/src/main/java/org/postgresql/core/v3 cp pgjdbc/pgjdbc/src/main/java/org/postgresql/jdbc/PgDatabaseMetaData.java debezium/debezium-connector-postgres/src/main/java/org/postgresql/jdbc应用适配PolarDB PostgreSQL版(兼容Oracle)的patch文件。
git apply v2.6.2.Final-support-polardbo-v1.patch说明以上使用的Debezium PolarDBO connector兼容patch文件:v2.6.2.Final-support-polardbo-v1.patch。
该patch文档默认将依赖debezium-api、debezium-core、PgJDBC和protobuf-java打包至JAR包,如不需要可以从pom.xml中移除。
使用Maven打包Debezium PolarDBO connector。
mvn clean package -pl :debezium-connector-postgres -DskipITs -Dquick # 打包完成后可以在debezium-connector-postgres/的target目录中获取到jar包按照以上流程基于JDK11打包出Debezium PolarDBO connector的JAR包:debezium-connector-postgres-polardbo-v1.0-2.6.2.Final.jar。
使用说明
Debezium PolarDBO connector是通过PolarDB PostgreSQL版(兼容Oracle)数据库的逻辑复制读取增量变更,使用时需要满足以下条件:
wal_level参数的值需设置为logical,即在预写式日志WAL(Write-ahead logging)中增加支持逻辑复制所需的信息。
说明您可以通过控制台设置wal_level参数,详细操作请参考设置集群参数。修改该参数后集群将会重启,请在修改参数前做好业务安排,谨慎操作。
执行
ALTER TABLE schema.table REPLICA IDENTITY FULL;命令设置订阅表的REPLICA IDENTITY为FULL(发出的插入和更新操作事件包含表中所有列的旧值),以保障该表数据同步的一致性。说明REPLICA IDENTITY是PostgreSQL特有的表级设置,决定了逻辑解码插件在发生(INSERT)和更新(UPDATE)事件时,是否包含涉及的表列的旧值。REPLICA IDENTITY取值含义详情,请参见REPLICA IDENTITY。
设置订阅表的
REPLICA IDENTITY为FULL时可能需要锁表,进而影响业务,请在修改参数前做好业务安排。您可以通过以下命令查看当前配置是否为FULL:SELECT relreplident = 'f' FROM pg_class WHERE relname = 'tablename';
需要确保max_wal_senders和max_replication_slots的参数值均大于当前数据库复制槽已使用数和Kafka作业所需要的slot数量。
确保使用的是高权限账号或者同时拥有LOGIN和REPLICATION权限的普通账号,并且具有订阅表的SELECT权限用于全量数据查询。
只能连接PolarDB集群的主地址,集群地址不支持逻辑复制。
connector.class参数指定为
io.debezium.connector.postgresql.PolarDBOConnector。建议将
plugin.name参数设置为pgoutput,否则非UTF-8编码的数据库可能会发生增量解析乱码,详细介绍请参考社区文档。
示例
以下示例用于说明,如何通过Debezium PolarDBO connector,将PolarDB PostgreSQL版Oracle语法兼容 2.0集群中dbz_db库的t1和t2表,同步到Kafka消息队列中。
前提准备
Kafka准备
部署Kafka实例,并确保在Kafka Connect的主机上能够成功访问。您也可以直接使用云消息队列 Kafka 版,详情请参考快速入门。
在Kafka实例中创建一个名为pg_dbz_event的Topic,用于接收消息。
说明测试场景为便于查看可以创建单分区Topic,对于生产环境请创建多分区Topic。
在本地以distributed模式启动Kafka Connect,端口为8083。
将上文打包的Debezium PolarDBO connectorJAR包拷贝到Kafka Connect的
plugin.path目录中。# ${plugin.path} 请替换为具体的路径 mkdir ${plugin.path}/debezium-connector-polardbo cp debezium-connector-postgres-polardbo-v1.0-2.6.2.Final.jar ${plugin.path}/debezium-connector-polardbo
PolarDB PostgreSQL版(兼容Oracle)准备
在PolarDB集群购买页面,购买PolarDB PostgreSQL版(兼容Oracle) 2.0集群。
按照使用说明,完成PolarDB集群配置,满足Debezium PolarDBO connector使用前提。
创建高权限账户,详细操作请参考创建账号。
获取集群主地址,详细操作请参考查看连接地址。如果PolarDB集群和Kafka Connect在同一可用区,可直接使用私网地址,否则需要申请公网地址。将Kafka Connect实例地址添加到PolarDB集群白名单中,请参考设置集群白名单。
在控制台创建数据库dbz_db,详细步骤请参考创建数据库。
执行如下语句,在数据库dbz_db中创建表t1、t2,并写入数据。
CREATE TABLE public.t1 (a int PRIMARY KEY, b text, c TIMESTAMP); ALTER TABLE public.t1 REPLICA IDENTITY FULL; INSERT INTO public.t1(a, b, c) VALUES(1, 'a', now()); CREATE TABLE public.t2 (a int PRIMARY KEY, b text, c DATE); ALTER TABLE public.t2 REPLICA IDENTITY FULL; INSERT INTO public.t2(a, b, c) VALUES(1, 'a', now());
测试
创建配置文件config/postgresql-connector.json,配置说明请参考社区文档。
{ "name": "dbz-polardb", "config": { "connector.class": "io.debezium.connector.postgresql.PolarDBOConnector", "database.hostname": "<yourHostname>", "database.port": "<yourPort>", "database.user": "<yourUserName>", "database.password": "<yourPassWord>", "database.dbname" : "dbz_db", "plugin.name": "pgoutput", "slot.name": "dbz_polardb", "table.include.list": "public.t1,public.t2", "topic.prefix": "polardb" "transforms": "Combine", "transforms.Combine.type": "io.debezium.transforms.ByLogicalTableRouter", "transforms.Combine.topic.regex": "(.*)", "transforms.Combine.topic.replacement": "pg_dbz_event" } }说明默认需要为每个表创建一个Topic,以上配置对Topic做了聚合。
添加connector。
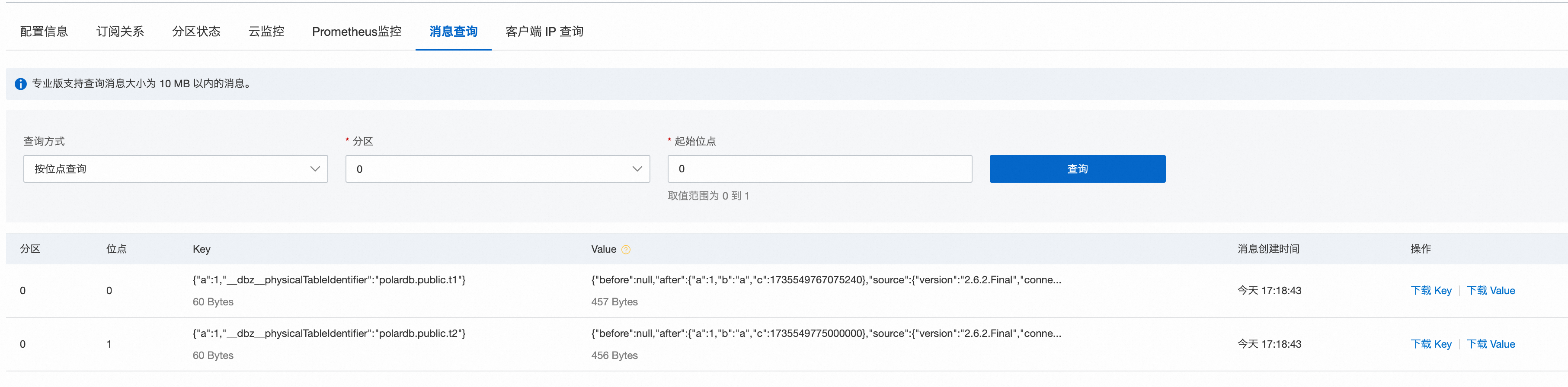
curl -i -X POST -H "Accept:application/json" -H "Content-Type:application/json" 'http://localhost:8083/connectors' -d @config/postgresql-connector.json成功添加后,能够在Kafka的Topic中查询到全量数据。
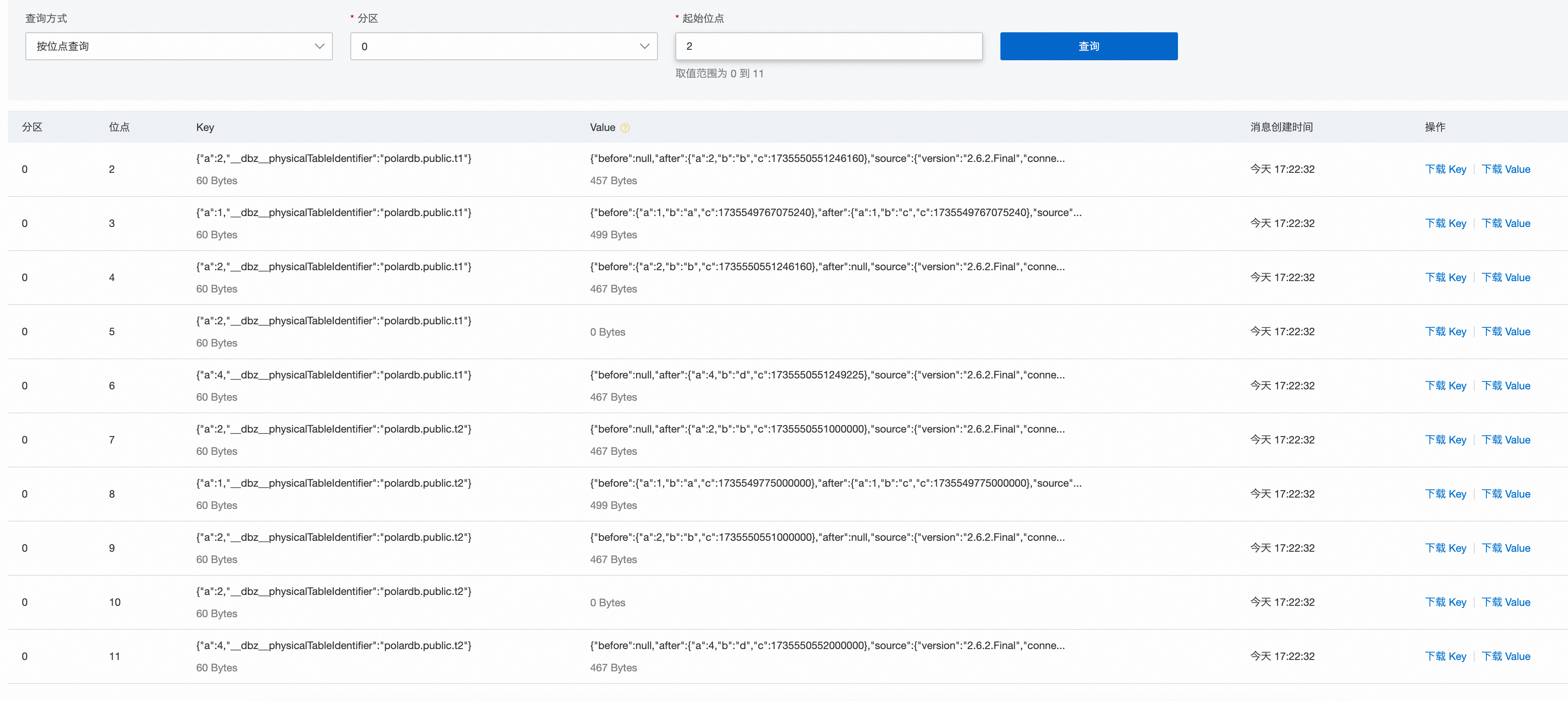
在PolarDB集群的dbz_db库中执行以下DML语句:
INSERT INTO public.t1(a, b, c) VALUES(2, 'b', now()); UPDATE public.t1 SET b = 'c' WHERE a = 1; DELETE FROM public.t1 WHERE a = 2; INSERT INTO public.t1(a, b, c) VALUES(4, 'd', now()); INSERT INTO public.t2(a, b, c) VALUES(2, 'b', now()); UPDATE public.t2 SET b = 'c' WHERE a = 1; DELETE FROM public.t2 WHERE a = 2; INSERT INTO public.t2(a, b, c) VALUES(4, 'd', now());能够在Kafka的Topic中查询到增量数据。