
PolarDB PostgreSQL版(兼容Oracle)支持分区表的并行查询(Parallel Append)功能,可以更好地处理大规模数据的查询。
概述
当代计算机往往有更多的核心可以使用,并行查询是现代数据库必不可少的能力。PolarDB PostgreSQL版(兼容Oracle)对分区表的并行查询,和普通表相比有更加优异的性能。
使用说明
PolarDB PostgreSQL版(兼容Oracle)的并行查询功能默认开启。
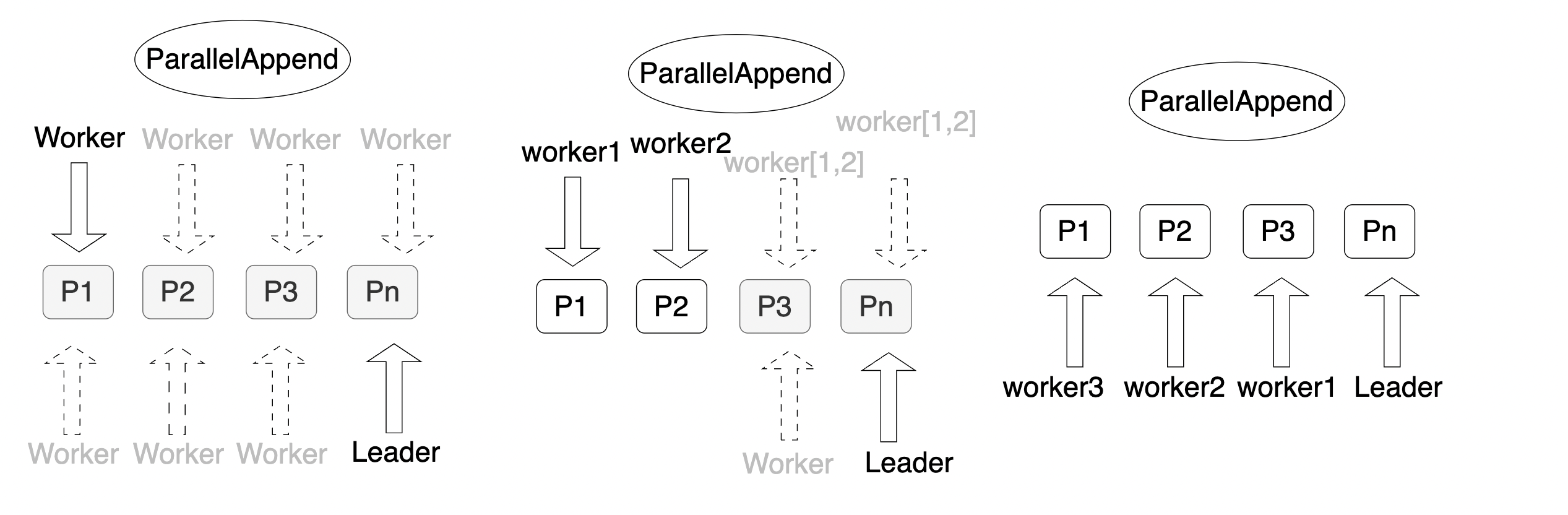
根据并行的方式,分区并行可分为分区间并行、分区内并行和混合并行。
以上三种并行方式都有自己的代价模型,优化器会根据实际情况选择最优的一种。
分区间并行
分区间并行是指每个worker查询一个分区,从而实现多个worker并行查询整个分区表。
示例:
EXPLAIN (COSTS OFF) select * from prt1;
QUERY PLAN
-----------------------------------------------
Gather
Workers Planned: 6
-> Parallel Append
-> Seq Scan on prt1_p5
-> Seq Scan on prt1_default
-> Seq Scan on prt1_p4
-> Seq Scan on prt1_p1
-> Seq Scan on prt1_p2
-> Seq Scan on prt1_p3
(9 rows)如上所示,prt1分区表中有6个分区:prt1_p1、prt1_p2、prt1_p3、prt1_p4、prt1_p5、prt1_default。整个分区表启动了6个并行的Worker(Workers Planned: 6)。每个worker负责查询一个分区。其中,明显的标志是有一个名为Parallel Append的算子。
分区内并行
分区内并行是指每个分区内部并行查询,但是整个分区表是串行的。
EXPLAIN (COSTS OFF) select * from prt1;
QUERY PLAN
-----------------------------------------------
Gather
Workers Planned: 6
-> Append
-> Parallel Seq Scan on prt1_p5
-> Parallel Seq Scan on prt1_default
-> Parallel Seq Scan on prt1_p4
-> Parallel Seq Scan on prt1_p1
-> Parallel Seq Scan on prt1_p2
-> Parallel Seq Scan on prt1_p3
(9 rows)如上所示,6个worker分别查询分区prt1_p1、prt1_p2、prt1_p3、prt1_p4、prt1_p5、prt1_default。分区间是串行执行的,因此也能实现分区表的并行查询。
混合并行
混合并行是指分区间和分区内都可以并行执行,以达到分区表整体的并行执行,这是并行度最高的一种并行查询。
EXPLAIN (COSTS OFF) select * from prt1;
QUERY PLAN
-----------------------------------------------
Gather
Workers Planned: 8
-> Parallel Append
-> Parallel Seq Scan on prt1_p5
-> Parallel Seq Scan on prt1_default
-> Parallel Seq Scan on prt1_p4
-> Parallel Seq Scan on prt1_p1
-> Parallel Seq Scan on prt1_p2
-> Parallel Seq Scan on prt1_p3
(9 rows)如上所示,整个查询使用了8个worker进行并行查询(Workers Planned: 8),每个分区之间可以并行查询,每个分区内部也可以并行查询。
该文章对您有帮助吗?