
PolarDB提供了最终一致性和会话读一致性两种一致性级别,满足您在不同场景下对一致性级别的要求。
PolarDB架构
PolarDB是一个由多个节点构成的数据库集群,一个主节点,多个读节点。对外默认提供两个地址,一个是集群地址,一个是主地址,推荐使用集群地址,因为它具备读写分离功能可以把所有节点的资源整合到一起对外提供服务。
PostgreSQL读写分离解决和引入
PostgreSQL具有主从复制简单易用的特点,通过把主库的WAL异步地传输到备库并实时应用,一方面可以实现高可用,另一方面备库也可以提供查询,来减轻对主库的压力。
虽然备库可以提供查询,但存在两个问题:
问题1:主库和备库一般提供两个不同的访问地址,应用程序端需要选择使用哪一个,对应用有侵入。
问题2:PostgreSQL的复制是异步的。客户端提交commit并且成功之后,数据可能还没有同步到只读节点。因此备库的数据并不是最新的,无法保证查询的一致性。
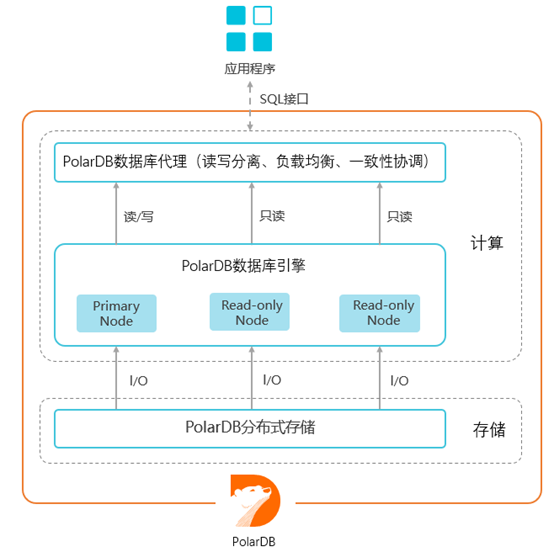
为了解决问题1,PolarDB引入了读写分离代理。代理会伪造成PostgreSQL与应用程序建立连接,解析发送进来的每一条SQL,如果是UPDATE、DELETE、INSERT、CREATE等写操作则直接发往主节点,如果是SELECT则发送到只读节点。
但是问题2,延迟导致的查询不一致还是没有解决,使用时就不可避免遇到备库SELECT查询数据不一致的现象(因为主备有延迟)。PostgreSQL负载低的时候延迟可以控制在5秒内,但当负载很高时,尤其是对大表做DDL(比如加字段)或者大批量插入的时候,延迟会非常严重。
PolarDB最终一致性和会话一致性
最终一致性:PolarDB采用异步物理复制方式在主库和只读库间做数据同步, 在主库更新后,相关的更新会apply到只读库,具体的延迟时间与写入压力有关, 一般在ms级别, 通过异步复制的方式实现主库和只读库之间的最终数据一致。
会话一致性:为了解决最终一致性会出现的查询不一致,PolarDB利用自身物理复制速度快的优点,将查询发给已经更新了数据的只读节点,详细原理请参见实现原理。
PolarDB读写分离的会话一致性
PolarDB是读写分离的架构,传统的读写分离都只提供最终一致性的保证,主从复制延迟会导致从不同节点查询到的结果不同,比如一个会话内连续执行以下QUERY:
INSERT INTO t1(id, price) VALUES(111, 96);
UPDATE t1 SET price = 100 WHERE id=111;
SELECT price FROM t1;在读写分离的情况下,最后一个查询的结果是不确定的,因为读会发到只读库,在执行SELECT时之前的更新是否同步到了只读库是不确定的,因此结果也是不确定的。因为存在查询结果不确定的问题,所以就要求应用程序去适应最终一致性,而一般的解决方法是:将业务做拆分,有高一致性要求的请求直连到主库,可以接受最终一致性的部分走读写分离。这样会增加应用开发的负担,还会增大主库的压力,影响读写分离的效果。
为了解决这个问题,PolarDB提供了会话一致性或者说因果一致性的保证,会话一致性即保证同一个会话内,后面的请求一定能够看到此前更新所产生版本的数据或者比这个版本更新的数据,保证单调性,就很好的解决了上面这个例子里的问题。
实现原理
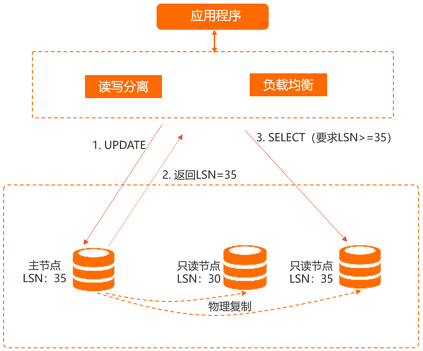
PolarDB链路的中间层做读写分离的同时,中间层会跟踪各个节点已经apply了的redolog位点并产生LSN,同时每次更新时会记录此次更新的位点为Session LSN,当有新请求到来时PolarDB会比较Session LSN 和当前各个节点的LSN,仅将请求发往LSN >= Session LSN的节点,从而保证了会话一致性;表面上看该方案可能导致主库压力大,但是因为PolarDB是物理复制,速度极快,在上述场景中,当更新完成后,返回客户端结果时复制就同步在进行,而当下一个读请求到来时主从极有可能已经完成,然后大多数应用场景都是读多写少,所以经验证在该机制下既保证了会话一致性,也保证了读写分离负载均衡的效果。
一致性级别选择最佳实践
PolarDB会话一致性,该级别对性能影响很小而且能满足绝大多数应用场景的需求。
如果您有不同会话间一致性需求的可以选择以下方案:
使用Hint将特定查询强制发到主库。
/*FORCE_MASTER*/ select * from user;