
本指南为您提供了从Amazon DynamoDB迁移至PolarDB PostgreSQL版详尽的操作步骤和最佳实践。PolarDB提供了一套专用的迁移工具,通过全量同步与增量同步相结合的方式,帮助您实现平滑、低停机时间的数据迁移。
迁移流程概述
迁移过程主要分为五个阶段,由nimo-shake(数据同步,包括全量同步与增量同步)、nimo-full-check(数据校验)和PolarDBBackSync(数据反向同步)三个核心工具协同完成。
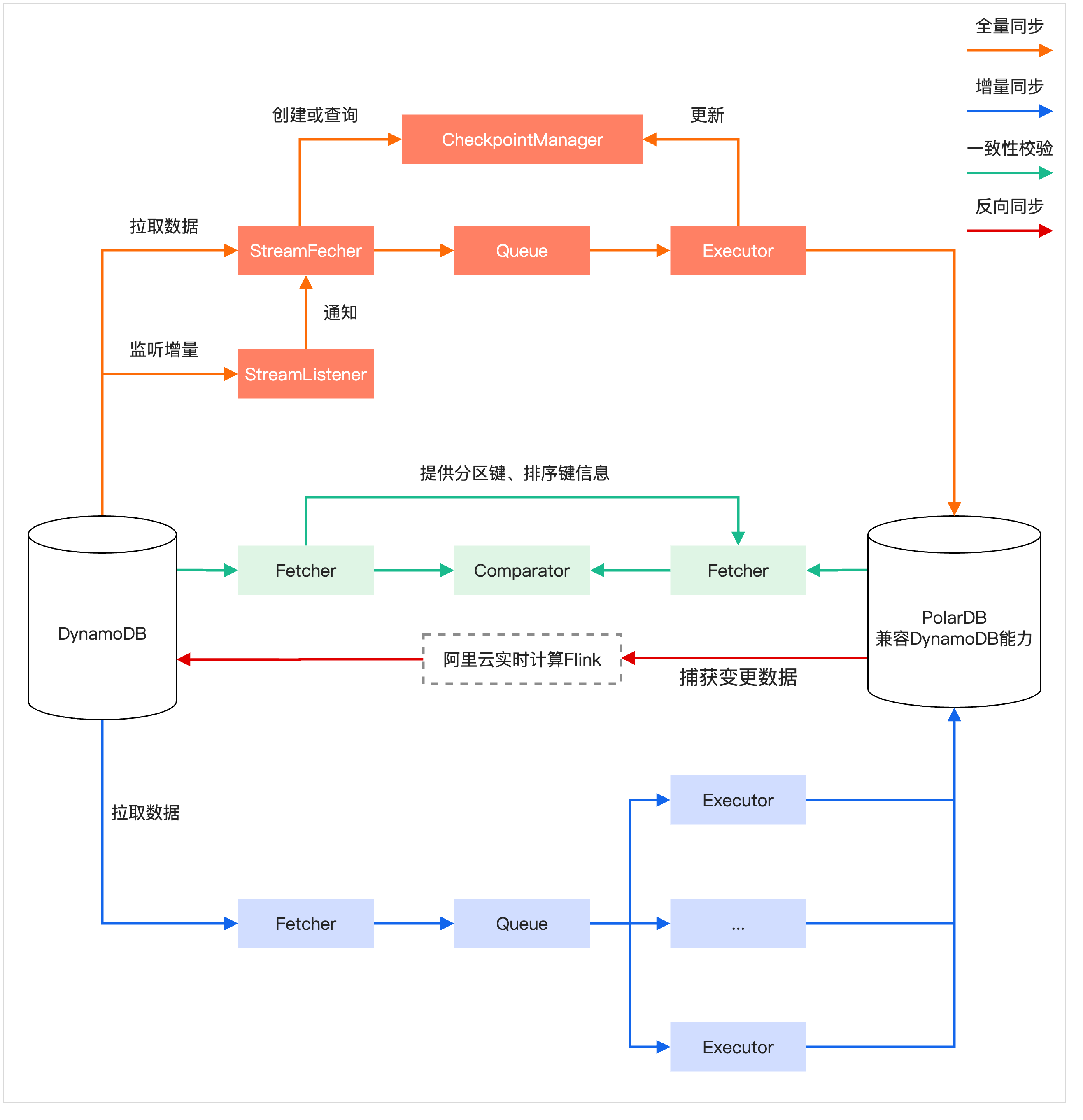
全量同步(Full Synchronization)
工具:
nimo-shake过程:工具首先自动在目标PolarDB集群中创建与源端一致的表结构。随后,通过并发
Scan操作高效读取源端数据库的全量数据,并使用BatchWriteItem批量写入目标集群。
增量同步(Incremental Synchronization)
工具:
nimo-shake过程:全量同步完成后,工具会自动利用AWS DynamoDB Streams机制,实时捕获源端自迁移启动以来的所有数据变更(增、删、改),并将其同步到目标集群,确保数据最终一致。该过程支持断点续传。
一致性校验(Consistency Validation)
工具:
nimo-full-check过程:在数据同步期间或之后,可随时运行此工具。它会并发地从源端和目标端读取数据,按主键进行比对,并生成详细的差异报告,以验证数据完整性。
(可选)反向同步(Reverse Synchronization)
工具:
PolarDBBackSync.jar(基于阿里云实时计算Flink版)过程:验证完数据一致性后,为确保业务回滚时数据的完整性,可以创建从PolarDB PostgreSQL版到源端DynamoDB的反向同步。该工具基于Flink实时捕获源端PolarDB的变更数据,并根据变更类型调用DynamoDB的PutItem或DeleteItem接口同步更新DynamoDB的数据。
业务割接(Business Cutover)
过程:当增量数据延迟极低且一致性校验无差异后,短暂停止业务写入,待所有数据同步完毕,即可将应用连接切换至PolarDB集群,完成迁移。
注意事项
性能影响:数据迁移过程,尤其是全量同步阶段,会对源数据库和目标数据库产生一定的读写负载。建议您在业务低峰期执行迁移,并提前评估数据库的承载能力。
安全配置:在业务割接前,建议对目标PolarDB集群的写入权限进行管控,仅允许数据同步工具的账号写入,防止意外数据污染。
准备工作
在开始迁移前,请确保您已完成以下准备工作:
获取工具包:
迁移工具包:NimoShake_v20260616.zip。其中包含
nimo-shake,nimo-full-check和nimo-repair三种迁移工具包。(可选)反向迁移工具包:PolarDBBackSync.jar。
PolarDB集群:
为已有集群或新集群开启兼容DynamoDB能力,并获取DynamoDB访问地址和创建DynamoDB专用账号用于API访问的身份凭证(AccessKey)。
(可选)参数配置:若需配置反向同步,则需将PolarDB集群的
wal_level参数修改为logical。由于该参数的调整需重启集群,建议在整体迁移流程开始之前完成此项设置。
AWS DynamoDB:
获取AWS DynamoDB的访问凭证(AccessKey ID和Secret Access Key)。
运行环境:准备一台ECS实例或其他能够与PolarDB集群及AWS DynamoDB连接的服务器,以便运行迁移工具包。
迁移实施步骤
步骤一:配置并启动数据同步
解压
NimoShake.zip,进入NimoShake目录,编辑统一配置文件conf/nimo.conf。nimo-shake、nimo-full-check、nimo-repair三个工具共用此文件,每个工具只读取自己能识别的参数。以下是启动同步所需的核心配置项:参数
说明
示例值
sync_mode同步模式。
all表示全量+增量,full表示仅全量。allsource.access_key_id源端AWS DynamoDB的AccessKey ID。
AKIAIOSFODNN7...source.secret_access_key源端AWS DynamoDB的Secret Access Key。
wJalrXUtnFEMI...source.region源端AWS DynamoDB所在的区域。
cn-north-1target.endpoint_url目标PolarDB的DynamoDB访问地址(含端口)。
http://pe-xxx.rwlb.rds...target.access_key_id目标PolarDB的DynamoDB账号AccessKey。
your-polardb-access-keytarget.secret_access_key目标PolarDB的DynamoDB账号SecretKey。
your-polardb-secret-keyfilter.collection.white表过滤白名单,多个表之间用
;相隔,与黑名单不可同时使用。c1;c2filter.collection.black表过滤黑名单,多个表之间用
;相隔,与白名单不可同时使用。c1;c2若您希望使用 基于 S3 快照的校验模式(推荐,详见步骤二),还需配置以下 PostgreSQL 原生连接参数:
参数
说明
示例值
s3.export_state_file导出状态文件路径,由
nimo-shake写入,nimo-full-check读取。../nimo-shake-s3-exports.jsons3.export_bucketDynamoDB数据导出的目标S3存储桶名称。
my-export-buckets3.export_prefixS3路径前缀,用于组织导出文件。
exports/my-project/target.pg.endpoint_urlPolarDB PostgreSQL原生端口地址(
host:port格式)。pc-xxx.pg.polardb.rds...:5432target.pg.userPolarDB PostgreSQL用户名(同时作为schema名)。
说明DynamoDB 账号本质上是普通数据库账号,其访问密钥(SK)由用户设定的密码按兼容算法加密生成,因此 target.pg.user 与 target.access_key_id 实际对应同一账号,而 target.pg.password 是用户自定义密码,SK 则是基于该密码派生的密钥。
your-usernametarget.pg.passwordPolarDB PostgreSQL密码。
your-password(可选)全量同步 PG 直写模式
默认情况下,全量同步使用原生 PostgreSQL 直写模式,通过标准 PostgreSQL 协议直接将数据写入 PolarDB,绕过 DynamoDB 兼容层 API,性能更高。如需回退到 DynamoDB 层 API(
BatchWriteItem,每次最多写入 25 条),可手动将该参数改为dynamodb。可在conf/nimo.conf的[SHAKE]区块中配置以下参数:参数
说明
默认值
full.write_protocol全量写入协议。
postgresql(默认)为 PG 直写高性能模式;dynamodb为 DynamoDB 层 API(BatchWriteItem,单次最大 25 条)。postgresqlfull.document.write.batch每次批量写入的文档数。PG 直写时不受 25 条限制,可适当调大以进一步提升写入吞吐。如切回
dynamodb协议,请将此值改回 25。1000full.document.concurrency每张表的并发写入线程数。PG 直写模式下,工具会自动按此值设置连接池大小,确保线程与连接一一对应。
4说明PG 直写模式同样需要配置
target.pg.*三项参数(与 s3/incr 校验模式共用同一组配置,无需重复填写)。该模式仅影响全量同步阶段的写入路径;增量同步始终通过 DynamoDB 兼容层 API 写入。
根据您的操作系统架构,选择对应的二进制文件启动同步任务。
说明建议您在后台
nohup运行,避免因终端服务断开而导致同步任务中断。# 在NimoShake目录下执行 nohup ./bin/nimo-shake.linux.amd64 -conf=./conf/nimo.conf > /dev/null 2>&1 &程序将首先进行全量同步,完成后自动转入增量同步阶段,并持续运行。
步骤二:执行数据一致性校验
nimo-full-check与nimo-shake共用同一份conf/nimo.conf,无需切换目录或编辑额外的配置文件。通过mode参数选择校验模式:scan:实时扫描源端与目标端数据进行对比。配置最简单,无需额外基础设施,但校验期间会持续消耗 DynamoDB 读取配额。s3(推荐):全量同步完成时,nimo-shake会自动将源端数据导出至 S3,并生成一份时间点快照。nimo-full-check以该快照为基准进行校验,无需再次扫描源端 DynamoDB。需在步骤一中配置 S3 相关参数。incr(配合s3模式使用):增量同步阶段,nimo-shake会将每条变更记录的主键写入 PolarDB 中的检查表(ct_{user}_{table})。nimo-full-check读取检查表,仅对这些发生过变更的记录进行定向校验。两种校验方式对比
scan 模式
s3 / incr 模式
所需停机时间
较长。校验期间须停止业务写入,避免源端数据在扫描过程中发生变化。
更短。基于快照校验,停机后仅需确认增量追平即可割接。
对源端的影响
持续消耗 DynamoDB 读取配额。
全量校验基于 S3 快照,不消耗 DynamoDB 配额;增量校验(incr 模式)仅对有变更的记录发起查询,配额消耗较少。
配置复杂度
低。
较高,需额外配置 S3 和 PolarDB PostgreSQL 连接。
启动校验任务。
nohup ./bin/nimo-full-check.linux.amd64 -conf=./conf/nimo.conf > /dev/null 2>&1 &校验工具会将详细日志和数据差异报告分别存放在默认目录
logs/和nimo-full-check-diff/中。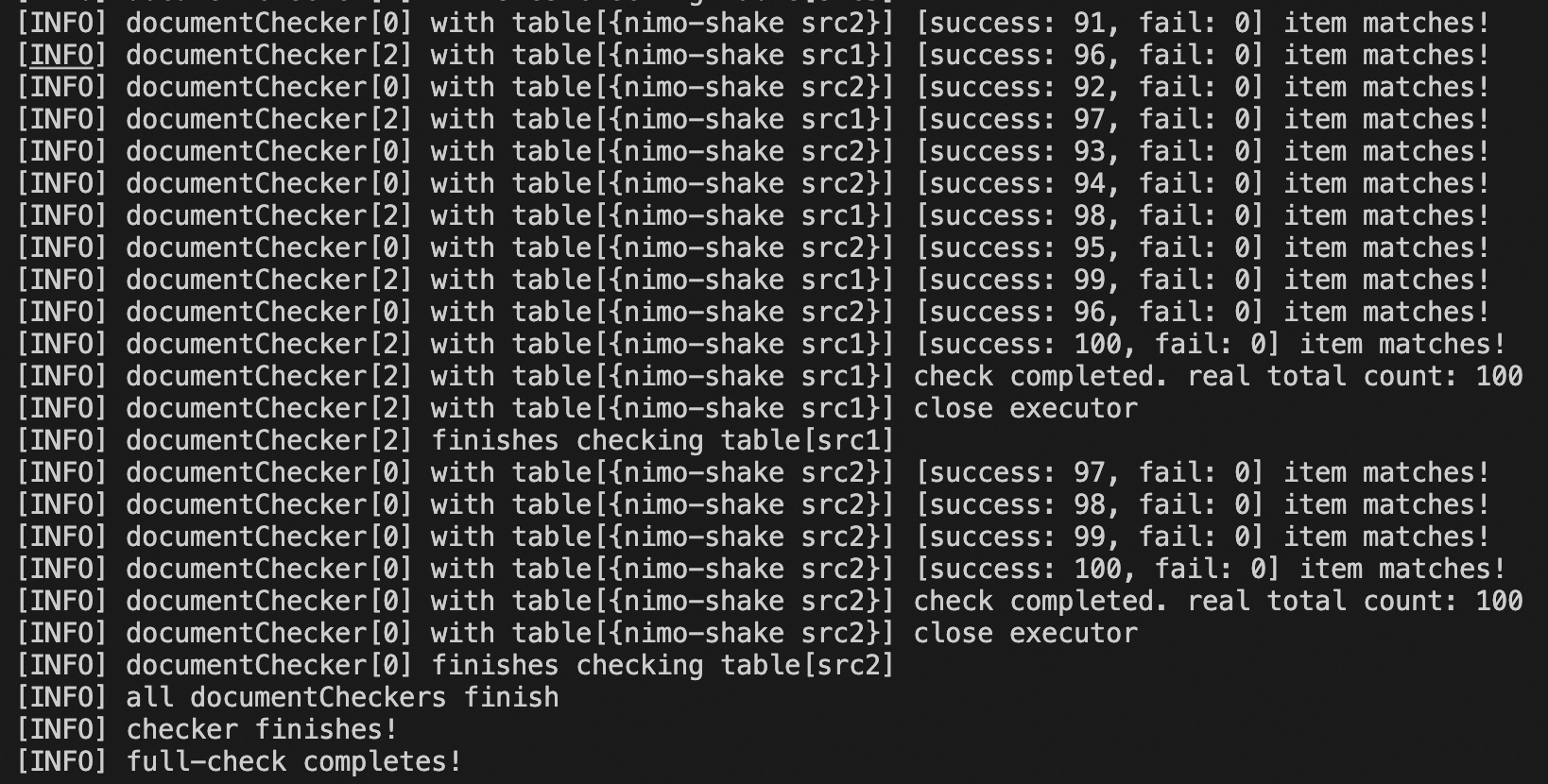
(可选)修复不一致数据:
当源端DynamoDB与目前PolarDB PostgreSQL版集群中的数据不一致时,将在指定的diff目录中展示不一致的表,例如:
说明diff目录默认为
nimo-full-check-diff,您可以在conf/nimo.conf中进行配置,参数为diff_output_file。nimo-full-check-diff/ └── testtable-0 └── testtable-1执行修复任务:
nohup ./bin/nimo-repair.linux.amd64 -conf=./conf/nimo-repair.conf > /dev/null 2>&1 &
步骤三:(可选)配置反向同步
在准备进行业务割接前,您可以预先配置从PolarDB PostgreSQL版到源端DynamoDB的反向同步链路。该链路在业务正式切换至PolarDB期间启动,用于实现数据的反向回流,为业务回滚提供保障。配置流程如下:
环境准备
确保PolarDB参数
wal_level的值为logical。创建高权限数据库账号并授权:
(可选)如果您尚未创建高权限账号,请前往PolarDB控制台,在集群的中创建高权限账号。
创建逻辑复制槽和发布:使用高权限账号连接至
polardb_internal_dynamodb数据库,执行以下SQL命令以创建一个逻辑复制槽,并向DynamoDB账号授予复制权限,最终发布包含该数据库下所有表的订阅。您可以查看所创建逻辑复制槽的活跃状态。-- 创建逻辑复制槽,'flink_slot' 名称需与后续 Flink 配置保持一致 SELECT * FROM pg_create_logical_replication_slot('flink_slot', 'pgoutput'); -- 为之前创建的 DynamoDB 专用账号授予 REPLICATION 权限 -- 将 <your_dynamodb_user> 替换为您的 DynamoDB 专用账号名 ALTER ROLE <your_dynamodb_user> REPLICATION; -- 检查复制槽状态,此时 flink_slot 的 active 应为 f (false) SELECT * FROM pg_replication_slots;开通并配置Flink:
开通实时计算Flink版,并创建一个Flink工作空间。
重要Flink工作空间需与PolarDB集群位于同一个VPC下。
为Flink工作空间配置公网访问,使其能够连接AWS DynamoDB。
配置PolarDB集群的IP白名单:
在Flink控制台,单击工作空间的详情按钮,在工作空间详情页面获取其网段信息。
前往PolarDB控制台,在集群的中新增IP白名单分组,将Flink的网段信息添加进去。
验证PolarDB集群与Flink工作空间连通性:
在Flink控制台,进入工作空间,单击右上角的网络探测图标。
填写PolarDB集群主节点的私有地址与端口,单击探测。
弹窗提示网络探测成功连通,即集群白名单配置正确。
部署Flink作业
下载反向同步工具:PolarDBBackSync.jar。
准备配置文件:创建名为
application.yaml的配置文件,内容如下:snapshot: mode: never source: # PolarDB主节点的私网地址 hostname: pc-xxx.pg.polardb.rds.aliyuncs.com # PolarDB主节点的私网端口 port: 5432 # 之前创建的逻辑复制槽的名称 slotName: flink_slot target: # 目标 AWS DynamoDB 的 region region: cn-north-1 # (可选) 表过滤配置,whiteTableSet 和 blackTableSet 只能声明一个 filter: # whiteTableSet: 需要反向回流的表 # blackTableSet: 不需要反向回流的表 whiteTableSet: blackTableSet: # Flink 作业的检查点(checkpoint)间隔,单位毫秒 checkpoint: interval: 3000上传文件:进入Flink控制台,找到并进入目标工作空间,在文件管理页面上传
PolarDBBackSync.jar和application.yaml。安全存储凭证:为避免明文暴露密钥,建议使用Flink的变量管理功能存储敏感信息。在变量管理页面新增以下四个变量:
变量名称
变量值
polardbusernamePolarDB的DynamoDB账号。
polardbpasswordPolarDB的DynamoDB账号的原始密码,并非DynamoDB账号密钥。
dynamodbakAWS DynamoDB的AccessKey。
dynamodbskAWS DynamoDB的SecretKey。
configfilename(可选)附加依赖文件名称,默认为
application.yaml。部署并启动作业:
进入作业运维页面,选择部署作业 > JAR作业。
填写以下主要参数,其他参数可根据业务环境进行配置。然后单击部署。
参数名称
填写参考
部署模式
固定为流模式。
部署名称
填写作业部署名称,此处以PolarDBBackSync为例。
引擎版本
固定为vvr-11.3-jdk11-flink-1.20。
JAR URI
选择已上传的
PolarDBBackSync.jar。Entry Point Class
固定为
org.example.PolarDBCdcJob。Entry Point Main Arguments
固定为:
--polardbusername ${secret_values.polardbusername}--polardbpassword ${secret_values.polardbpassword}--dynamodbak ${secret_values.dynamodbak}--dynamodbsk ${secret_values.dynamodbsk}(可选)
--configfilename ${secret_values.configfilename}附加依赖文件
选择已上传的
application.yaml。重要如果您的密码或其他参数值中包含特殊字符,可能会导致 Flink 作业解析参数失败。为防止此问题,请在作业创建完成后,在部署详情 > 运行参数配置 中点击编辑按钮,在其他配置中,添加以下配置来防止此类问题:
env.java.opts: -Dconfig.disable-inline-comment=true。部署成功后,单击启动 > 无状态。
验证与清理
验证:在作业启动后,使用高权限账号连接至PolarDB集群的
polardb_internal_dynamodb数据库,并执行SELECT * FROM pg_replication_slots;。若复制槽flink_slot的active字段变为t(true),则表示Flink作业已成功连接。此时即可在PolarDB集群内开始导入业务流量。清理:当不再需要进行反向同步时,您可执行以下步骤以释放相关资源节省费用。
实时计算Flink版:
停止作业:前往Flink控制台,在目标工作空间中,进入作业运维页面,找到目标作业并单击停止
释放实例:返回Flink控制台,找到目标工作空间,单击释放资源。
PolarDB集群:使用高权限账号连接至
polardb_internal_dynamodb数据库,执行以下命令删除逻辑复制槽。SELECT pg_drop_replication_slot('flink_slot');
步骤四:执行业务割接
增量同步延迟较低且数据一致性校验无差异后,可计划业务割接。当您准备好进行最终的业务切换时,请遵循以下严谨的步骤:
最终校验:在计划的停机窗口前,反复运行一致性校验工具,直至确认增量同步延迟极低,且数据差异数量降至0或可接受的范围内。
停止源端写入:在停机窗口开始时,暂停所有向源端AWS DynamoDB写入数据的业务应用。
等待同步完成:观察
nimo-shake的日志,确认已无新的增量数据需要同步。最后一次校验:再次运行
nimo-full-check工具,确保源端和目标端的数据完全一致。停止同步工具:在确认数据完全同步后,停止
nimo-shake进程。切换应用连接:停止业务应用,将业务应用的数据库连接配置,从AWS DynamoDB的地址切换为PolarDB的DynamoDB访问地址。
(可选)开启反向同步任务:在业务正式切换至PolarDB期间开启反向同步任务,基于阿里云实时计算Flink版实现数据的反向回流,为业务回滚提供保障。
启动业务:重启业务应用。至此,割接完成。
(可选)停止反向同步任务:在割接完成且业务稳定运行一段时间后,确认数据一致性满足业务需求后,即可安全停止反向同步任务(停止Flink作业与释放相关资源)。
附录:为测试环境模拟实时业务流量
如果您希望在测试环境中模拟一个真实的、持续有数据写入的迁移场景,可以使用以下Go语言示例代码。该代码会向源端DynamoDB表周期性地写入和更新数据。
此步骤仅用于测试和验证迁移流程,在实际生产迁移中无需执行。
package main
import (
"context"
"fmt"
"log"
"math/rand"
"time"
"github.com/aws/aws-sdk-go-v2/aws"
"github.com/aws/aws-sdk-go-v2/config"
"github.com/aws/aws-sdk-go-v2/credentials"
"github.com/aws/aws-sdk-go-v2/service/dynamodb"
"github.com/aws/aws-sdk-go-v2/service/dynamodb/types"
)
// --- Configuration for your source AWS DynamoDB ---
var (
region = "cn-north-1" // AWS DynamoDB region
accessKey = "your-aws-access-key" // AWS DynamoDB access key
secretKey = "your-aws-secret-key" // AWS DynamoDB secret key
)
// --- Helper function to create a DynamoDB client ---
func createClient() (*dynamodb.Client, context.Context) {
ctx := context.Background()
sdkConfig, err := config.LoadDefaultConfig(ctx, config.WithRegion(region))
if err != nil {
log.Fatalf("Failed to load AWS config: %v", err)
}
client := dynamodb.NewFromConfig(sdkConfig, func(o *dynamodb.Options) {
o.Credentials = credentials.NewStaticCredentialsProvider(accessKey, secretKey, "")
})
return client, ctx
}
// --- Function to create a table and populate it with initial data ---
func initializeData(client *dynamodb.Client, ctx context.Context) {
tableName := "src1" // Example table name
// Create table if not exists
_, err := client.CreateTable(ctx, &dynamodb.CreateTableInput{
TableName: &tableName,
AttributeDefinitions: [ ]types.AttributeDefinition{
{AttributeName: aws.String("pk"), AttributeType: types.ScalarAttributeTypeS},
},
KeySchema: [ ]types.KeySchemaElement{
{AttributeName: aws.String("pk"), KeyType: types.KeyTypeHash},
},
ProvisionedThroughput: &types.ProvisionedThroughput{
ReadCapacityUnits: aws.Int64(100),
WriteCapacityUnits: aws.Int64(100),
},
})
if err != nil {
// Ignore if table already exists, fail on other errors
if _, ok := err.(*types.ResourceInUseException); !ok {
log.Fatalf("CreateTable failed for %s: %v", tableName, err)
}
}
fmt.Printf("Waiting for table '%s' to become active...\n", tableName)
waiter := dynamodb.NewTableExistsWaiter(client)
err = waiter.Wait(ctx, &dynamodb.DescribeTableInput{TableName: &tableName}, 5*time.Minute)
if err != nil {
log.Fatalf("Waiter failed for table %s: %v", tableName, err)
}
// Insert 100 sample items
for i := 0; i < 100; i++ {
pk := fmt.Sprintf("%s_user_%03d", tableName, i)
item := map[string]types.AttributeValue{
"pk": &types.AttributeValueMemberS{Value: pk},
"val": &types.AttributeValueMemberN{Value: fmt.Sprintf("%d", i)},
}
client.PutItem(ctx, &dynamodb.PutItemInput{TableName: &tableName, Item: item})
}
fmt.Printf("Inserted 100 initial items into '%s'.\n", tableName)
}
// --- Function to simulate continuous business traffic ---
func simulateTraffic(client *dynamodb.Client, ctx context.Context) {
tableName := "src1"
fmt.Println("Starting periodic updates to simulate traffic. Press Ctrl+C to stop.")
i := 0
for {
pk := fmt.Sprintf("%s_user_%03d", tableName, i%100)
newValue := fmt.Sprintf("%d", rand.Intn(1000))
_, err := client.UpdateItem(ctx, &dynamodb.UpdateItemInput{
TableName: &tableName,
Key: map[string]types.AttributeValue{
"pk": &types.AttributeValueMemberS{Value: pk},
},
ExpressionAttributeValues: map[string]types.AttributeValue{
":newval": &types.AttributeValueMemberN{Value: newValue},
},
UpdateExpression: aws.String("SET val = :newval"),
})
if err != nil {
fmt.Printf("Update error: %v\n", err)
} else {
fmt.Printf("Updated pk=%s with new val=%s\n", pk, newValue)
}
i++
time.Sleep(1 * time.Second) // Update one record per second
}
}
func main() {
client, ctx := createClient()
initializeData(client, ctx)
simulateTraffic(client, ctx)
}