
当您需要对保存在OSS上的Lance格式数据执行compact(合并小文件)、创建标量索引、创建向量索引等维护操作时,可以通过Ray应用提交Python作业,利用Ray的分布式调度能力对多个Lance dataset并行执行维护任务。本文介绍如何在Ray应用中提交Lance数据维护作业。
适用范围
Lance数据文件已保存在OSS上,且Ray应用与OSS Bucket位于同一地域。
已获取访问OSS所需的AccessKey ID和AccessKey Secret。
Ray Head组件和Worker组件的内存规格请至少保持16 GB,建议购买2核16 GB规格来进行试用,防止大任务出现OOM。
Ray应用需要与OSS Bucket位于同一地域,以确保可通过内网地址进行访问。
若通过公网访问地址访问不通Ray应用时,请检查是否已正确配置IP白名单。
背景信息
Ray、Lance与OSS的关系
假设您的Lance文件保存在OSS上,那么Ray、Lance和OSS三者的关系如下:
组件 | 作用 |
Ray | 负责分布式调度。Driver提交多个远程任务,Ray应用把任务分配到不同Worker上运行。 |
Lance | 负责数据格式和维护API。脚本通过Lance SDK读写dataset、执行compact、创建索引和重建索引。 |
OSS | 负责对象存储。Lance dataset的数据文件、版本元数据和索引文件都保存在OSS路径下。 |
Ray的并行适合用于多个独立dataset或shard并行维护。同一个Lance dataset的版本提交建议由一个任务负责,不建议多个Ray Task同时对同一个dataset做compact或建索引提交,避免产生版本冲突。
支持的维护操作
本文示例脚本包含以下Lance数据维护操作:
compact:合并小fragment,降低后续扫描和读取放大。
create scalar index:为结构化列创建标量索引,例如为
id列创建BTREE索引。append:向已有Lance dataset追加新数据。
reindex:append之后重建同名索引,让索引覆盖新增数据。
create vector index:为向量列创建向量索引,例如
IVF_PQ。
示例脚本会把多个shard拆成多个独立Lance dataset,并通过Ray多个Worker并行执行维护任务。您可以通过输出中的task_hostnames判断任务是否被调度到了多个节点。
操作步骤
以下步骤介绍如何通过JupyterLab Terminal提交Lance数据维护作业。JupyterLab Terminal是Ray应用提供的预置环境,已内ray job submit命令,无需在本地安装任何依赖。
使用JupyterLab Terminal提交作业时,还需将Ray应用所属集群的VPC主IPv4网段添加至应用白名单中。
登录JupyterLab
在浏览器中打开已获取的Jupyter公网地址。
在密码框(Password or token)中输入
secret.jupyterlab.password对应的密钥,进入JupyterLab界面。
准备Python脚本
在JupyterLab的文件浏览器中,创建一个工作目录(例如
src)并双击进入工作目录,创建一个Python脚本文件(例如oss_ray_run.py)。
将以下完整代码复制到脚本文件中。该脚本会将一个根目录拆成多个shard,每个shard是一个独立的Lance dataset,Ray为每个shard提交一个远程Task,从而实现多Worker并行维护。
配置OSS环境变量
由于Ray Head和Worker组件内无法直接使用本地电脑上的环境变量,需要将环境变量写成文件,通过
--runtime-env参数提交给Ray应用。在工作目录下创建
runtime_env.yaml文件,填入以下内容:env_vars: OSS_ENDPOINT: "https://oss-cn-beijing-internal.aliyuncs.com" OSS_REGION: "cn-beijing" OSS_ACCESS_KEY_ID: "XXXX" OSS_ACCESS_KEY_SECRET: "XXXX" LANCE_ROOT_URI: "oss://BUCKET/DATASET"环境变量说明如下:
变量
示例
说明
OSS_ENDPOINThttps://oss-cn-beijing-internal.aliyuncs.comOSS访问地址。Ray应用和OSS在同一地域时,建议使用VPC内网访问地址,减少公网访问成本和延迟。
OSS_REGIONcn-beijingOSS Bucket所在地域,需要和Endpoint匹配。
OSS_ACCESS_KEY_IDXXXX访问OSS的AccessKey ID。生产环境建议使用最小权限账号或STS临时凭证。
OSS_ACCESS_KEY_SECRETXXXX访问OSS的AccessKey Secret。不要把真实密钥提交到代码仓库。
OSS_SECURITY_TOKENXXXX(可选)使用STS临时凭证时需要配置。
LANCE_ROOT_URIoss://BUCKET/DATASETLance dataset根路径。
BUCKET为OSS Bucket名称,DATASET为Lance dataset的目录前缀。脚本会在该路径下创建多个shard=xx.lance子目录。提交作业并查看结果
在JupyterLab中,通过File > New Launcher打开一个新的Terminal。
在JupyterLab的Terminal中执行以下命令,提交作业并查看日志。
# 1. 返回上层目录,为演示提交作业中的 --working-dir 参数。 cd .. # 2. 设置环境变量。请替换为您的真实信息。 # 作业提交匿名密钥:secret.jwt.anonKey ANON_KEY="<YOUR_ANON_KEY>" # 3. 提交任务,并等待执行结果。 ray job submit --headers "{\"Authorization\": \"Bearer $ANON_KEY\"}" --working-dir ./src --runtime-env ./src/runtime_env.yaml -- python oss_ray_run.py作业执行成功后,输出中会包含以下关键信息:
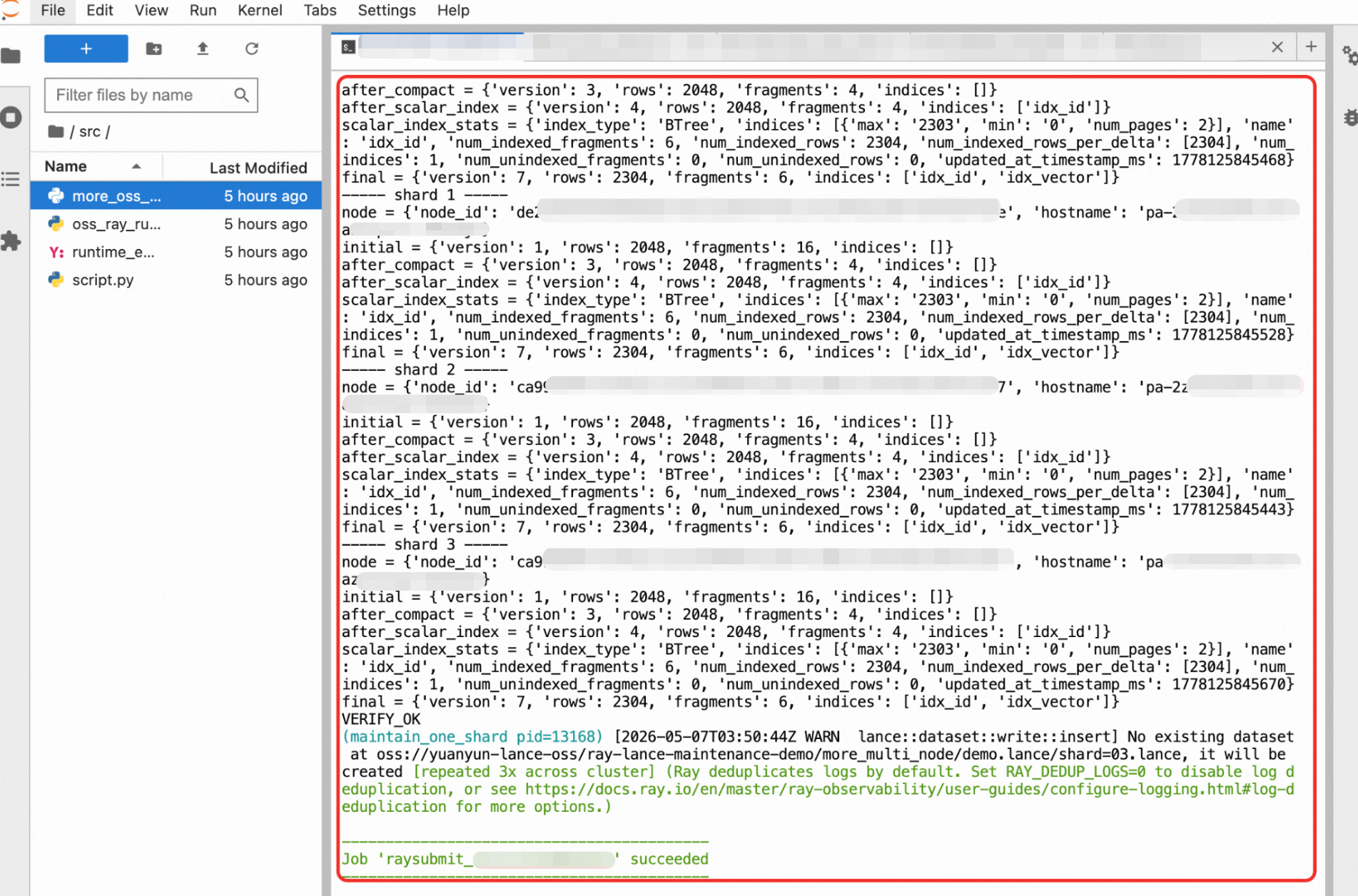
task_hostnames:显示任务实际运行的节点。如果出现多个hostname,说明任务已经分散到多个Ray节点。每个shard的
initial和after_compact对比:可以看到compact后fragment数量下降,但行数不变。VERIFY_OK:表示所有维护操作和校验均通过。
说明如果输出中出现
WARN_SINGLE_NODE_TASKS警告,表示所有任务只落在了一个节点上。常见原因是Worker数不足、LANCE_DEMO_SHARDS设置过小或每个Task资源需求较低。可以增加Ray Worker数量或调大LANCE_DEMO_SHARDS环境变量的值来实现多节点调度。
代码块说明
以下分别说明脚本中各Lance维护操作对应的核心代码及含义。
compact
compact操作将多个小fragment合并成更少的fragment,减少后续读取开销。
ds = lance.dataset(uri, storage_options=storage_options())
ds.optimize.compact_files(
target_rows_per_fragment=512,
max_rows_per_group=512,
materialize_deletions=True,
num_threads=2,
)target_rows_per_fragment=512:控制compact后每个fragment的目标行数。num_threads=2:Lance在当前Ray Worker进程内部使用的线程数,不是Ray的Worker数量。
num_threads不是Ray的Worker数。假设有4个Ray Task,每个Task内num_threads=2,则最多出现4个dataset并行维护,每个dataset内部再使用2个本地线程做compact。
create scalar index
为结构化列创建标量索引。首次创建使用replace=False,append数据后重建索引使用replace=True。
首次创建标量索引:
ds = lance.dataset(uri, storage_options=storage_options()) ds.create_scalar_index("id", "BTREE", name="idx_id", replace=False)append之后重建同名索引(reindex):
ds = lance.dataset(uri, storage_options=storage_options()) ds.create_scalar_index("id", "BTREE", name="idx_id", replace=True) scalar_index_stats = lance.dataset(uri, storage_options=storage_options()).index_statistics("idx_id")参数说明
"id":要建索引的列名。"BTREE":索引类型,适合数值、字符串等结构化列的过滤查询。replace=False:如果同名索引已存在则不覆盖,适合首次创建。replace=True:重建同名索引,即reindex操作。index_statistics("idx_id"):用于检查索引覆盖情况,num_unindexed_rows == 0表示索引已覆盖全部行。
create vector index
为向量列创建向量索引,用于近似最近邻(ANN)搜索。
ds = lance.dataset(uri, storage_options=storage_options())
ds.create_index(
"vector",
"IVF_PQ",
name="idx_vector",
metric="cosine",
replace=True,
num_partitions=16,
num_sub_vectors=2,
)参数说明
"vector":向量列名。"IVF_PQ":向量索引类型。metric="cosine":使用cosine距离。num_partitions=16:IVF分区数。num_sub_vectors=2:PQ子向量数,需要和向量维度匹配。replace=True:适合Demo或重建索引。生产环境应结合版本和任务状态谨慎使用。
Ray多Worker并行维护的实践与约束
Ray并行维护多个dataset的核心代码如下:
refs = [maintain_one_shard.remote(root_uri, shard) for shard in range(SHARDS)]
results = ray.get(refs)推荐实践
每个Ray Task负责一个独立的dataset或shard,同一个dataset内按顺序执行维护操作:
Ray task 1 -> compact oss://BUCKET/DATASET/shard=00.lance
Ray task 2 -> compact oss://BUCKET/DATASET/shard=01.lance
Ray task 3 -> compact oss://BUCKET/DATASET/shard=02.lance
Ray task 4 -> compact oss://BUCKET/DATASET/shard=03.lance一个Ray Task负责一个独立dataset或shard。
同一个dataset内按顺序执行
compact>create index>append>reindex>verify。多个dataset之间交给Ray并行调度。
不推荐实践
不要让多个Ray Task同时对同一个dataset执行不同的维护操作:
Ray task 1 -> compact oss://BUCKET/DATASET/main.lance
Ray task 2 -> create index oss://BUCKET/DATASET/main.lance
Ray task 3 -> append oss://BUCKET/DATASET/main.lance同一个Lance dataset的compact、append、create index都可能提交新版本。多个任务同时对同一个dataset提交版本,容易产生冲突或不可控的重试成本。
更多信息
除了通过JupyterLab Terminal提交作业外,您也可以通过本地环境提交Ray任务。具体操作方法请参见提交作业到Ray应用中关于Ray Python SDK和Ray CLI的说明。