
PolarDB PostgreSQL分布式版的列存索引(IMCI)功能内置DuckDB分析引擎,可将分析查询性能提升60倍以上。结合分布式架构的透明分片机制,查询可下推至多个数据节点(DN)并行处理,分析性能随节点数线性扩展。在TB/PB级大数据量场景下,分布式+IMCI的组合相较于行存,整体分析性能可实现近100倍的提升,满足HTAP(混合事务与分析处理)场景需求。
架构

分布式+IMCI的架构包含以下核心角色:
CN(协调节点):负责处理请求、生成分布式执行计划、下推查询SQL到各个数据节点,并最终汇聚各DN的结果返回给客户端。
DN(数据节点):负责存储行存(Row-Store)和列存(IMCI)数据。行存数据通过逻辑复制机制异步写入到列存,确保分析加速与实时数据写入兼容。
以一个典型的分析型聚合查询为例,整体流程如下:
CN节点生成分布式计划并下发SQL:业务SQL请求发送到CN节点,CN根据全局元数据生成分布式执行计划,决定如何将查询SQL拆分下发到各个数据节点。
DN节点基于IMCI列存数据并行查询:CN将查询下推到各目标DN节点,DN基于本地的IMCI列存数据进行高效并行查询和初步聚合,完成后返回中间结果给CN。
CN节点进行二次聚合,返回最终结果:CN收集所有DN的查询结果,并按需进行最终聚合、排序,最后将汇总结果返回给用户或应用程序。
适用场景
该功能适用于多租户数据库场景,尤其是在需要对租户数据进行高效汇总和全局聚合时,能够显著提升分析性能。具体适用两种拆分场景:
水平拆分(Sharding by tenant_id)
假设存在业务表orders,并以tenant_id作为分片键。
单租户信息聚合:统计某一租户的本地订单总金额与平均金额。
SELECT SUM(amount) AS total_amount, AVG(amount) AS avg_amount FROM orders WHERE tenant_id = 1001;全局租户信息统计:统计所有租户的订单总金额与平均金额,按租户分组。
SELECT tenant_id, SUM(amount) AS total_amount, AVG(amount) AS avg_amount FROM orders GROUP BY tenant_id;
垂直拆分(Sharding by schema)
假设每个租户的数据分布在单独的Schema中,表名同为orders。
单个Schema信息聚合:针对某个Schema的订单总金额与平均金额聚合。
SELECT SUM(amount) AS total_amount, AVG(amount) AS avg_amount FROM tenant_a.orders;全局租户信息统计:汇总所有租户的订单总金额与平均金额,通过UNION ALL实现。
SELECT 'tenant_a' AS tenant, SUM(amount) AS total_amount, AVG(amount) AS avg_amount FROM tenant_a.orders UNION ALL SELECT 'tenant_b' AS tenant, SUM(amount) AS total_amount, AVG(amount) AS avg_amount FROM tenant_b.orders;
适用范围
已为租户表配置好分片,具体分片方法请参见创建与管理分布表和复制表。
集群版本:
PostgreSQL 16,且内核小版本需为2.0.16.11.14.0及以上版本。
PostgreSQL 14,且内核小版本需为2.0.14.20.43.0及以上版本。
配置分布式列存索引
步骤一:开启分布式IMCI功能
您可以在PolarDB控制台或在数据库会话中进行修改:
参数 | 说明 |
| 是否开启分布式列存索引。
|
| 是否允许WHERE条件中的IN表达式执行分布式列存索引。
|
| 是否开启分布式hint功能。
|
SET polar_cluster_enable_imci = on;
SET polar_csi.enable_anyall_to_in = on;
SET pg_hint_plan.polar_enable_distributed_hint = on;步骤二:创建行列同步复制槽
用高权限账户在主CN上执行以下命令,为所有节点创建行列同步复制槽:
SELECT run_command_on_all_nodes($$ SELECT polar_csi_start_sync() $$);此操作为幂等操作,可多次执行无副作用。
步骤三:创建并分片租户表
水平拆分
以tenant_id作为分片键,创建分布式表:
如果以tenant_id作为分片键,必须为主键或者主键的一部分。
-- 创建初始业务表(以 tenant_id 作为主键一部分)
CREATE TABLE orders (
order_id bigint,
tenant_id int NOT NULL,
amount numeric(20,2),
status text,
create_time timestamp,
PRIMARY KEY (tenant_id, order_id)
);
-- 转为分布式分片表
SELECT create_distributed_table('orders', 'tenant_id');垂直拆分
每个租户的数据存储在独立的Schema中:
-- 创建租户 schema
CREATE SCHEMA tenant1;
-- 转为分布式管理
SELECT polar_cluster_schema_distribute('tenant1');
-- 创建业务表
SET search_path TO tenant1;
CREATE TABLE orders (
order_id bigint,
tenant_id int NOT NULL,
amount numeric(20,2),
status text,
create_time timestamp,
PRIMARY KEY (tenant_id, order_id)
);步骤四:创建列存索引
为表创建CSI列存索引:
-- 对所有列创建列存索引
CREATE INDEX csi_orders ON orders USING CSI;
-- 仅对部分列创建列存索引(如仅查询 tenant_id, amount)
CREATE INDEX csi_orders_part ON orders1 USING CSI(tenant_id, order_id, amount);
-- 支持不锁表创建列存索引(推荐)
CREATE INDEX CONCURRENTLY csi_orders ON orders USING CSI;推荐为所有列创建CSI索引,避免因列缺失造成列存查询失效。
步骤五:使用列存索引执行查询
有两个参数控制是否执行列存查询:
参数 | 说明 |
| 是否允许查询语句使用列存索引。
|
| 查询代价阈值。如果查询代价小于当前设置阈值,使用行存引擎,反之使用列存引擎。
|
推荐通过HINT控制某次查询强制使用列存索引:
/*+SET (polar_csi.enable_query on) SET(polar_csi.cost_threshold 0)*/
SELECT tenant_id, SUM(amount) AS total_amount, AVG(amount) AS avg_amount
FROM orders
GROUP BY tenant_id;也可以全局或按账号设置参数。全局设置参数需要在控制台修改,按账号设置参数需要在主CN上执行以下语句:
-- 以 test 用户优先启用列存索引
ALTER ROLE test SET polar_csi.enable_query = ON;
ALTER ROLE test SET polar_csi.cost_threshold = 0;步骤六:确认查询是否使用列存索引
可用EXPLAIN分析,若计划中出现CSI Executor字样说明已成功使用列存索引:
/*+SET (polar_csi.enable_query on) SET(polar_csi.cost_threshold 0)*/
EXPLAIN (COSTS OFF) SELECT tenant_id, SUM(amount) AS total_amount, AVG(amount) AS avg_amount
FROM orders
GROUP BY tenant_id;示例输出片段(含有CSI Executor说明使用了列存查询):
QUERY PLAN
---------------------------------------------------------
Custom Scan (PolarCluster Adaptive)
Task Count: 32
Tasks Shown: One of 32
-> Task
Node: host=127.0.0.1 port=45719 dbname=postgres
-> CSI Executor:
┌───────────────────────────┐
│ HASH_GROUP_BY │
│ ──────────────────── │
│ Aggregates: │
│ sum(#1) │
│ avg(#2) │
└─────────────┬─────────────┘
┌─────────────┴─────────────┐
│ SEQ_SCAN │
│ ──────────────────── │
│ Table: orders_102008 │
│ Type: Sequential Scan │
└───────────────────────────┘性能表现
以下测试展示分布式+IMCI组合在不同数据处理场景下的横向扩展能力和性能表现。测试环境中每个DN规格为16核64 GB。
Sysbench OLTP(联机交易处理)测试:主要用于评估数据库在高并发插入、更新和删除等事务型操作下的性能。通过增加数据节点(DN)的数量,系统的写入能力实现接近线性扩展,以满足不断增长的业务流量需求。
TPC-H OLAP(联机分析处理)测试:重点关注大规模数据聚合和复杂查询分析的性能表现。IMCI显著提升了单节点的分析能力,而分布式架构则进一步将查询下推至多个DN节点进行并行处理,从而使总体查询性能随节点数量线性提升,适用于海量数据的分析与洞察。
TPC-H性能测试
使用1 TB TPC-H数据集,分别测试1、2、4、8、12个DN下的查询时延。
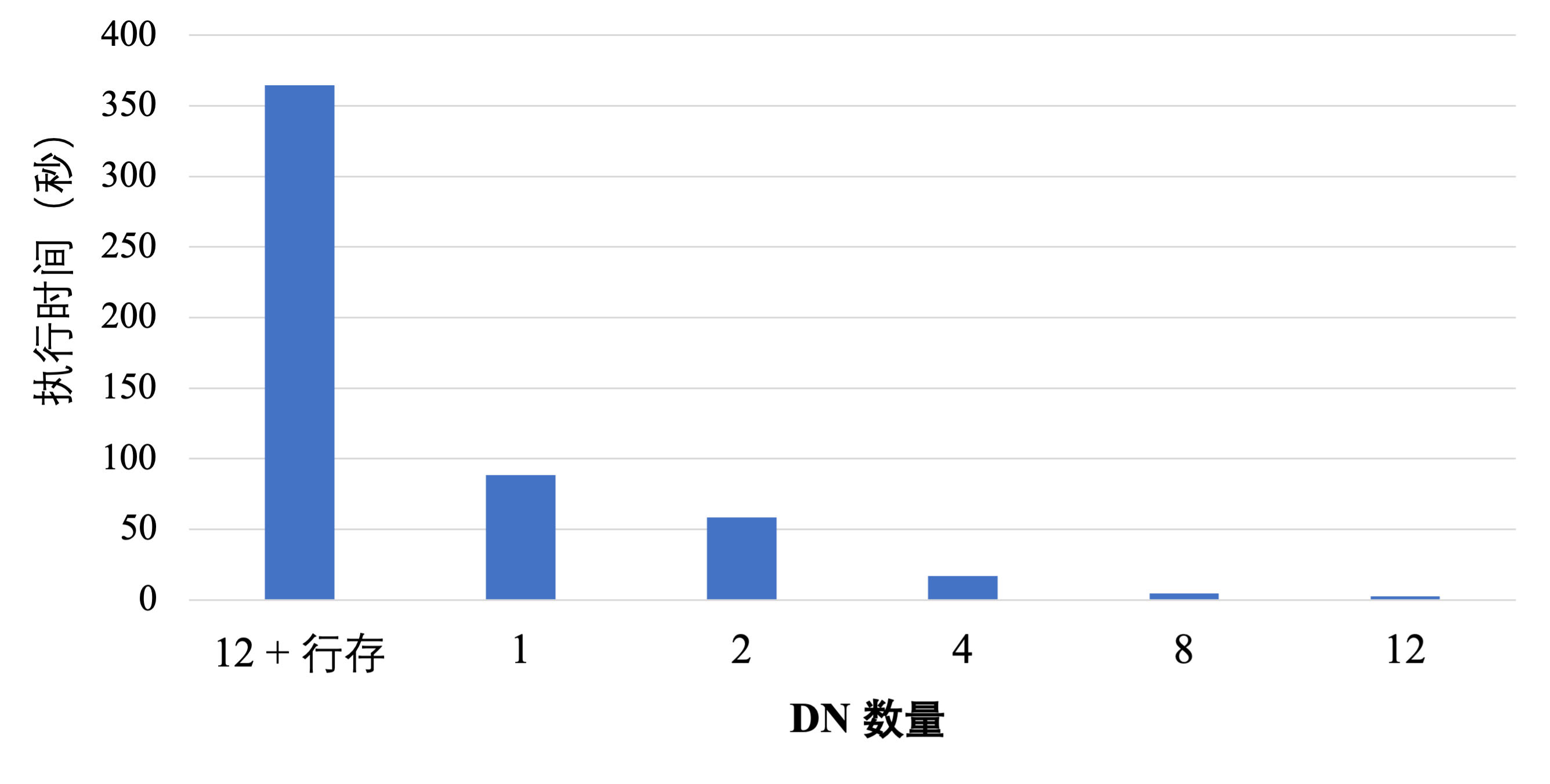
测试结果表明:
分布式列存的查询时延相较于分布式行存可以提升100倍以上,并且可以做到线性扩展。
相较于单节点列存查询,分布式+IMCI也可随DN节点数做到线性倍数提升,12 DN相较于单节点能提升数10倍。
Sysbench OLTP_INSERT测试
分别在1、2、4、8、12个DN的配置下,测量分布式集群的写入QPS。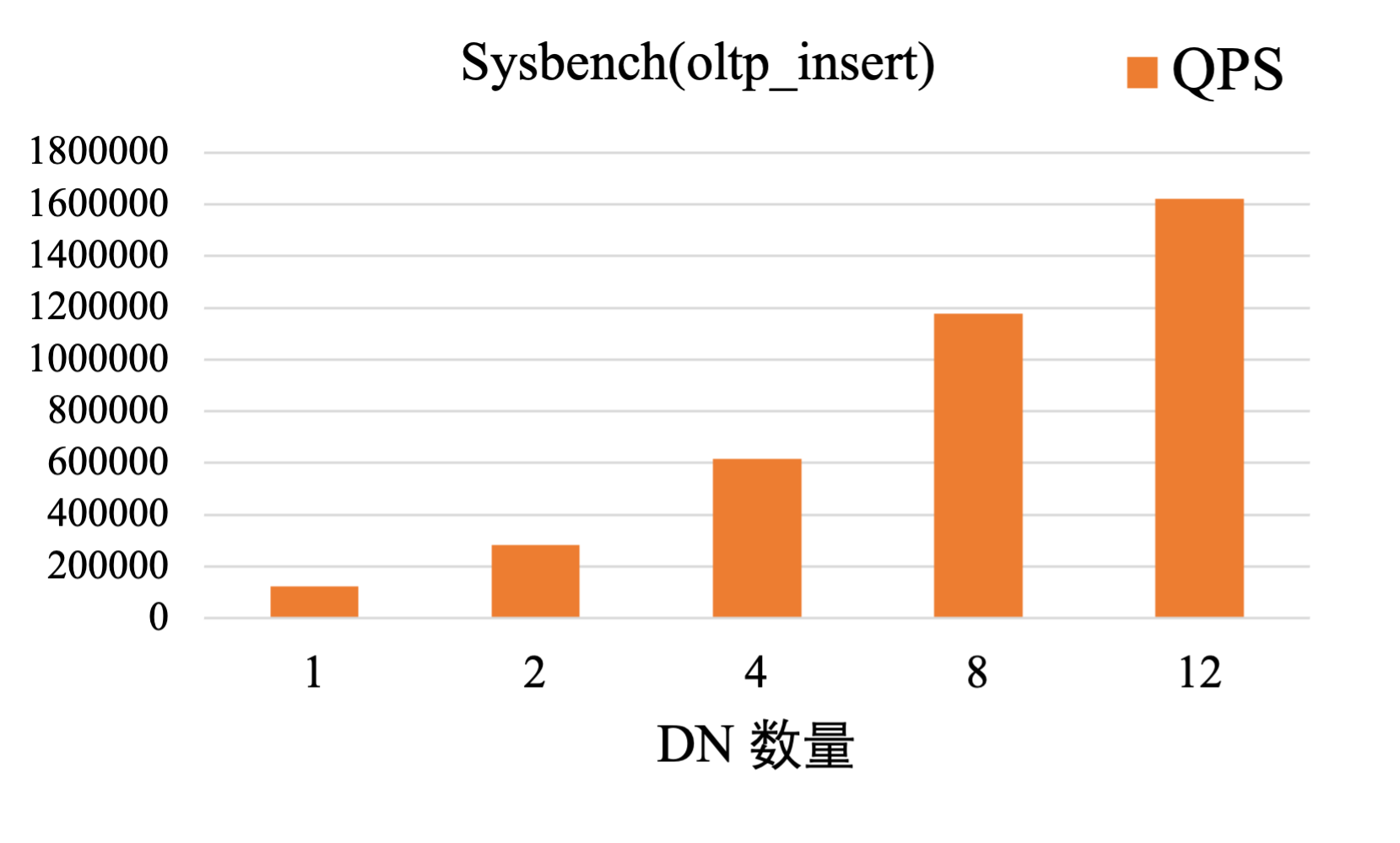
测试结果表明:
写入QPS随DN数量线性扩展:随着DN节点从1增加到12,写入QPS实现近乎线性增长,12个DN下最高QPS可达160万。
分布式架构横向扩展行列同步能力:多DN并行架构不仅提升写入性能,同时也显著增强逻辑复制回放能力,使行存到列存(IMCI)的数据同步时延接近实时。