
宽表模式下,一张表拥有数十个列甚至上百个列,但查询负载中只需要统计/分析部分列,此时可以使用列存索引进行加速。
背景
在很多SaaS业务系统中,一张表有几十甚至上百个列,在查询时往往会面临较大的技术挑战:
查询时只需要分析其中的几个列,但在使用行存结构时,会读取大量无关的列,增加IO负担。
查询模式不固定,上百个列在查询时会存在多种过滤条件,构建组合索引时需要预先匹配所有的查询场景,一旦改变查询条件,组合索引将失效。
列存索引可以很好地应对上述两个场景。由于列存索引的内部结构以列为单位,所以读取一个列时并不会影响另一个列,同时列之间也没有顺序关系,所以多个查询条件的顺序性也不会影响列存索引的效果。
效果展示
在一亿条数据规模和4并行度模式下,采用列存索引方式的查询性能为PostgreSQL原生并行执行的30倍。
查询语句 | PostgreSQL原生并行 | 列存索引 |
Q1 | 243 s | 7.9 s |
实施步骤
步骤一:环境准备
请确认您的集群版本与配置是否满足以下条件:
集群版本:
PostgreSQL 16(内核小版本为2.0.16.8.3.0及以上)
PostgreSQL 14(内核小版本为2.0.14.10.20.0及以上)
原表必须包含主键,且在创建列存索引时需要将主键列加入列存索引中。
wal_level参数的值需设置为logical,即在预写式日志WAL(Write-Ahead Logging)中增加支持逻辑编码所需的信息。说明您可以通过控制台设置wal_level参数。修改该参数后集群将会重启,请在修改参数前做好业务安排,谨慎操作。
开启列存索引功能。
对于不同的PolarDB PostgreSQL版内核版本,开启列存索引的方式不同:
当前版本下的PolarDB PostgreSQL版集群,支持两种开启方式,具体差异如下,请按需选择:
对比项
【推荐】添加列存索引只读节点
直接使用预安装的列存索引插件
操作方式
通过控制台实现可视化操作,手动添加列存索引节点。
无需任何操作,即可直接使用。
资源分配
列存引擎独占所有资源,能够充分利用所有内存。
列存引擎只能使用25%的内存,其余内存则分配给行存引擎使用。
业务影响
TP(事务)与AP(分析)业务在不同节点上相互隔离,互不影响。
TP(事务)与AP(分析)业务在同一节点,会互相影响。
费用
需额外收取列存索引只读节点的费用,按照普通计算节点收费。
无费用。
添加列存索引只读节点
您可选择以下两种方式中任意一种方式添加列存索引只读节点:
说明集群中应包含一个只读节点,即单节点集群不支持添加列存索引只读节点。
控制台添加
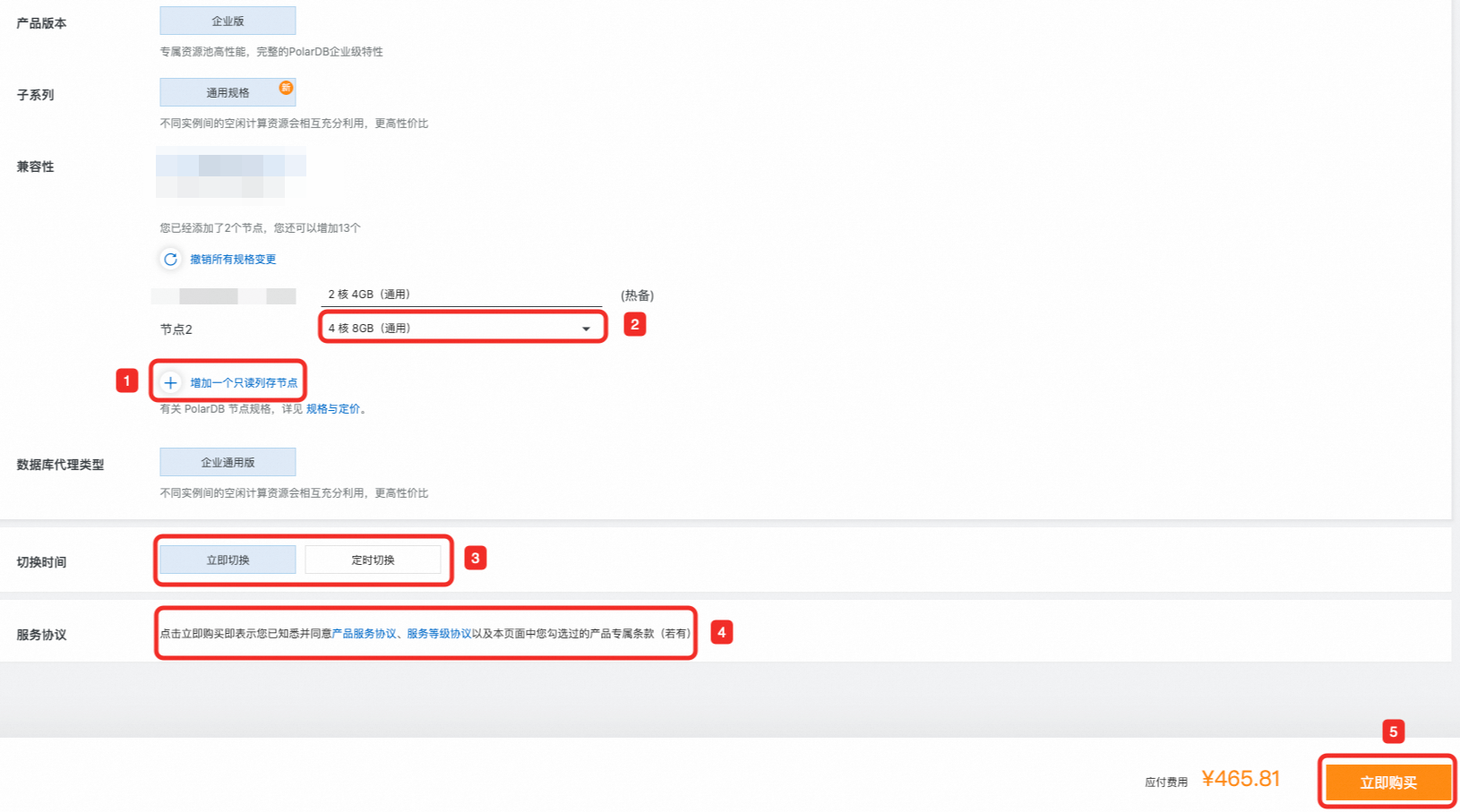
登录PolarDB控制台,选择集群所在地域。您可以按照如下两种方式中的任意一种进入增删节点向导页面:
在集群列表页面,单击操作栏的增删节点。

在目标集群的基本信息页面,数据库节点区域,单击增删节点。

选择增加列存索引只读节点选项,并单击确定。
在集群变配页面,添加列存索引只读节点并支付。
单击增加一个列存索引只读节点,选择节点规格。
选择切换时间。
(可选)查看产品服务协议、服务等级协议。
单击立即购买。
支付完成后,返回集群详情页等待列存索引只读节点添加成功,即节点状态为运行中。

购买时添加
在PolarDB购买页的节点个数配置项中自行选择列存索引只读节点数量。

当前版本下的PolarDB PostgreSQL版集群,列存索引作为插件
polar_csi部署在数据库集群中,在使用之前需要在指定的数据库中创建插件。说明polar_csi插件的作用域是Database级别,如果需要在集群的多个Database中使用列存索引,需要为每个Database分别创建polar_csi插件。安装插件使用的数据库账号必须为高权限账号。
您可以选择以下两种方式中的任意一种安装
polar_csi插件。控制台安装
登录PolarDB控制台,在左侧导航栏单击集群列表,选择集群所在地域,并单击目标集群ID进入集群详情页。
在左侧导航栏选择,在管理插件页签,选中未安装插件。
在页面右上角选择目标数据库,单击
polar_csi插件操作列安装,在弹出的安装插件对话框,选择目标数据库账号,单击确定,即将插件安装到目标数据库中。
命令行安装
连接数据库集群,并在具有相应权限的目标数据库中执行以下语句,创建
polar_csi插件。CREATE EXTENSION polar_csi;

步骤二:数据准备
以一张包含24个列的widecolumntable表为例,包含BIGINT、DECIMAL、TEXT、JSONB、TEXT[]等类型,现要对其中的id_1、domain、consumption、start_time和end_time等五个列进行统计分析,统计每个客户在过去一年多个domain里消费的金额。
创建一张名为
widecolumntable表,表结构定义如下,然后按照您的需求插入测试数据。CREATE TABLE widecolumntable ( id_1 BIGINT NOT NULL PRIMARY KEY, id_2 BIGINT, id_3 BIGINT, id_4 BIGINT, id_5 BIGINT, id_6 BIGINT, version INT, domain TEXT, consumption DECIMAL(18,3), c_level CHARACTER varying(1) NOT NULL, priority BIGINT, operator TEXT, notify_policy TEXT, call_id UUID NOT NULL, provider_id BIGINT NOT NULL, name_1 TEXT NOT NULL, name_2 TEXT NOT NULL, name_3 TEXT, start_time TIMESTAMP WITH TIME ZONE NOT NULL, end_time TIMESTAMP WITH TIME ZONE NOT NULL, comment JSONB NOT NULL, description TEXT[] NOT NULL, created_at TIMESTAMP WITH TIME ZONE DEFAULT now() NOT NULL, updated_at TIMESTAMP WITH TIME ZONE DEFAULT now() NOT NULL );将
id_1、domain、consumption、start_time和end_time列加入到列存索引中。CREATE INDEX idx_wide_csi ON widecolumntable USING CSI(id_1, domain, consumption, start_time, end_time);
步骤三:执行查询
使用不同执行引擎统计过去一年客户在不同domain中消费金额,并按消费额进行排序。
使用列存索引。
---开启列存索引,设置查询并行度为4 SET polar_csi.enable_query to on; SET polar_csi.exec_parallel to 4; ---Q1 EXPLAIN ANALYZE SELECT id_1, domain,SUM(consumption) FROM widecolumntable WHERE start_time > '20230101' and end_time < '20240101' GROUP BY id_1, domain Order By SUM(consumption);关闭列存索引,使用行存引擎。
---关闭列存索引,使用行存引擎,并设置查询并行度为4 SET polar_csi.enable_query to off; SET max_parallel_workers_per_gather to 4; ---Q1 EXPLAIN ANALYZE SELECT id_1, domain,SUM(consumption) FROM widecolumntable WHERE start_time > '20230101' and end_time < '20240101' GROUP BY id_1, domain Order By SUM(consumption);