在压测中和压测结束后,您可以通过全局监控查看PTS的业务监控以及施压机监控。如果您配置了全链路监控的链路追踪和云产品监控,监控大盘也会展示应用监控和各云产品的监控信息。
业务监控
吞吐量、成功率和响应时长是压测需要关注的三个黄金指标。压测时,应重点观察全场景维度的吞吐量、成功率以及95、99分位响应时长。此外,可以同时指定一个核心业务接口,在压测时同步关注核心业务的吞吐量、成功率和响应时长。当三个黄金指标出现拐点时,表示系统已遇到性能瓶颈。
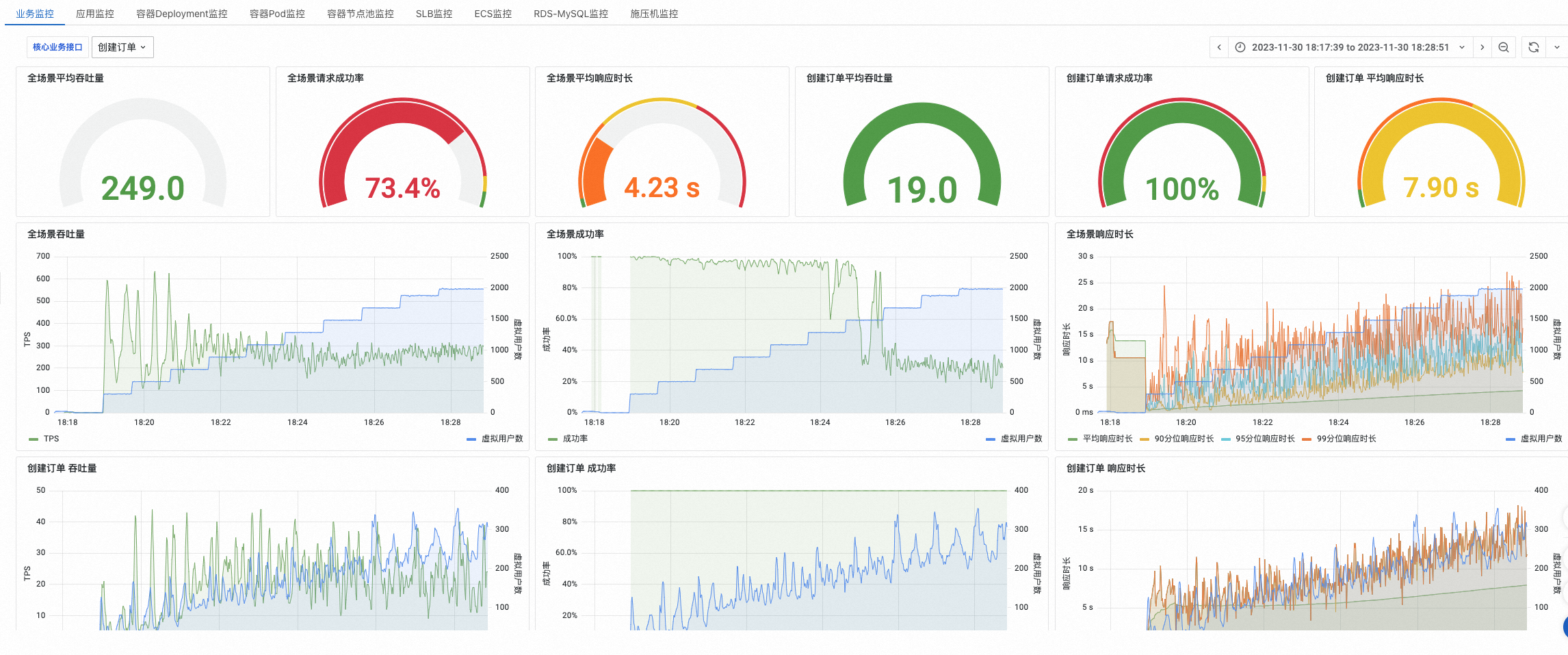
在接口监控中,查看各API的三个黄金指标、虚拟用户数以及响应各阶段耗时。

在异常统计中,可以按异常状态码和异常API维度分析异常分布。同时,支持按API分析断言失败数量。

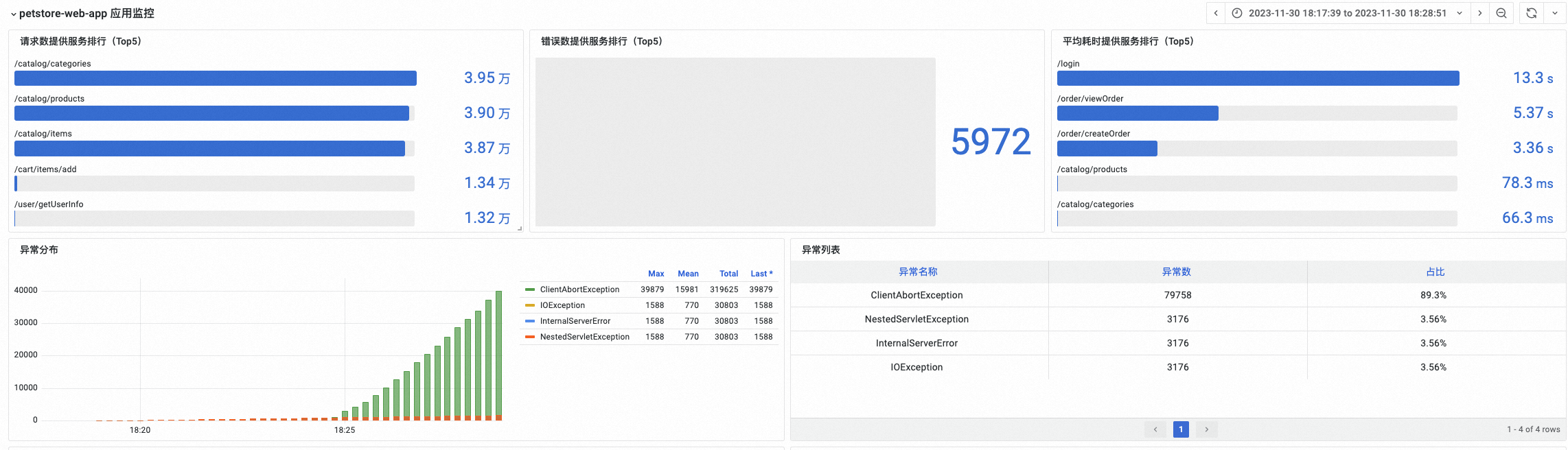
应用监控
前提条件
已开通PTS服务。更多信息,请参见开通方式。
已开通ARMS应用监控服务,并已挂载ARMS探针或已接入可观测链路追踪Opentelemetry版。具体操作,请参见开通ARMS和探针管理。
在创建压测场景时,已配置链路追踪。具体操作,请参见链路追踪。
查看应用监控
在应用监控列表,您可以查看压测时段各应用的副本数,以及CPU、内存、磁盘等资源水位。结合错误请求数、数据库慢调用次数、数据库错误调用次数和FullGC次数等指标,判断负载较高,需要优化性能或扩容的应用。

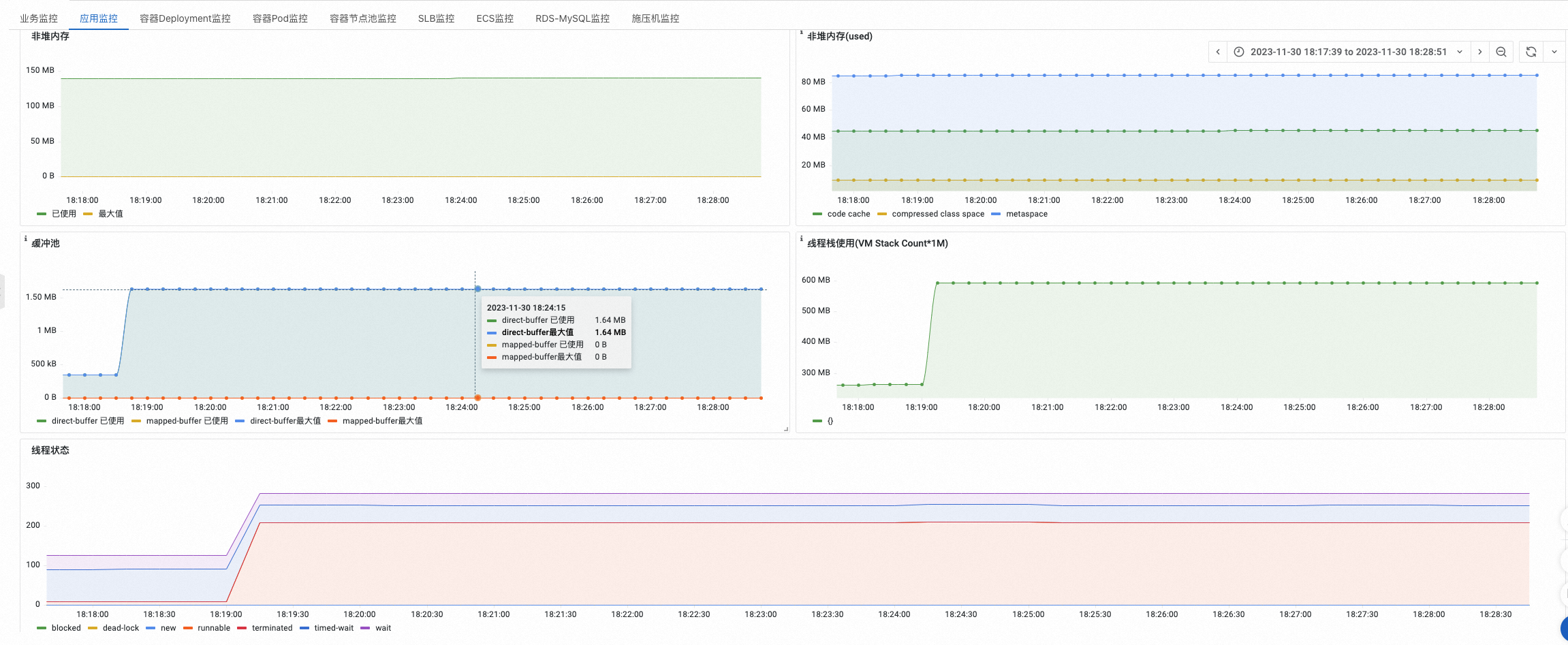
在应用下拉框,可以选择单个应用。在应用监控中,展示了指定应用的请求量和异常分布。
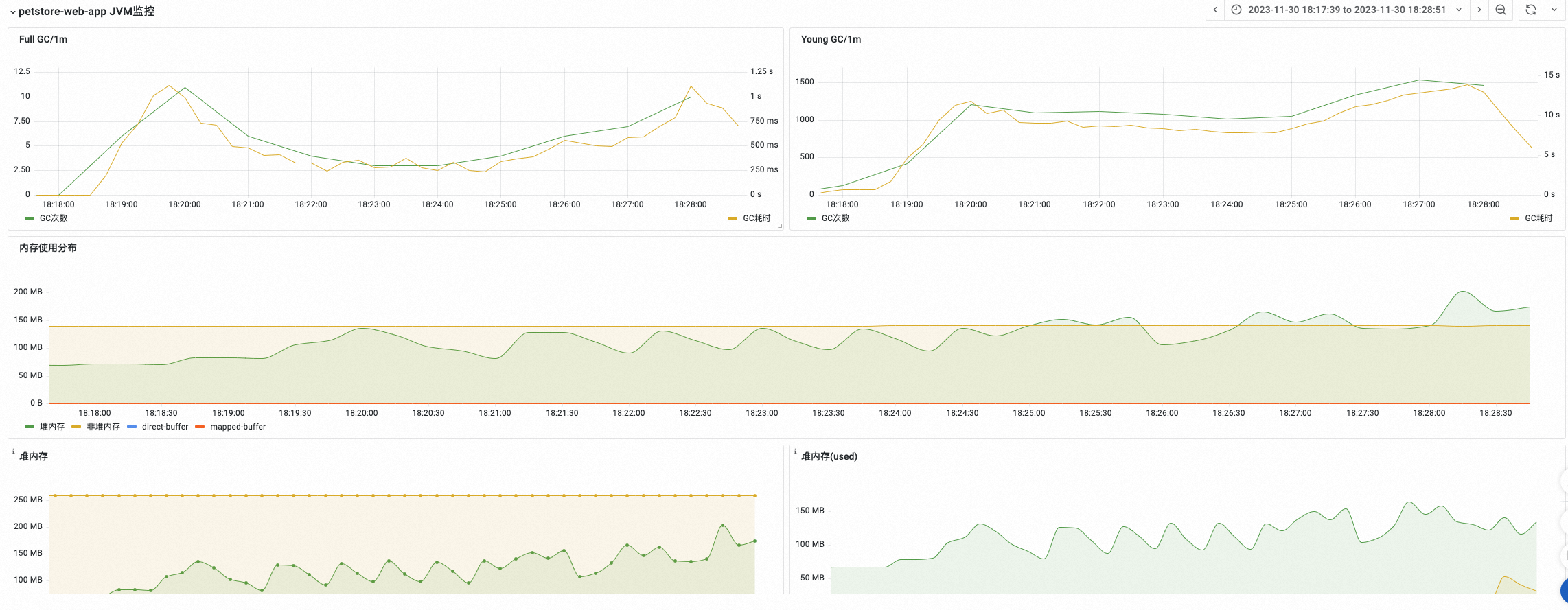
同时,您还可以观测指定应用的JVM监控,辅助JVM性能调优。
容器监控
前提条件
已开通PTS服务。更多信息,请参见开通方式。
已开通容器服务Kubernetes版和ARMS应用监控服务,并安装ack-onepilot组件。具体操作,请参见应用监控。
在创建压测场景时,已配置链路追踪。具体操作,请参见链路追踪。
查看容器监控
PTS会根据您在链路追踪应用中的配置,自动识别您已安装ack-onepilot组件的应用,并展示对应容器服务Deployment、Pod和节点池的监控大盘。
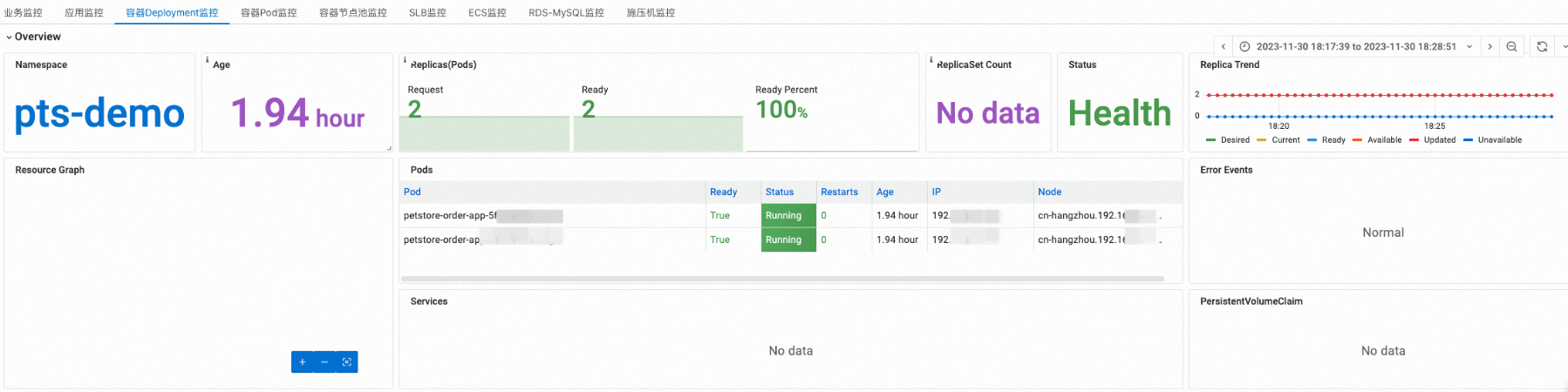
容器Deployment监控
您可以在Deployment概览区域,选择指定namespace中的一个deployment。
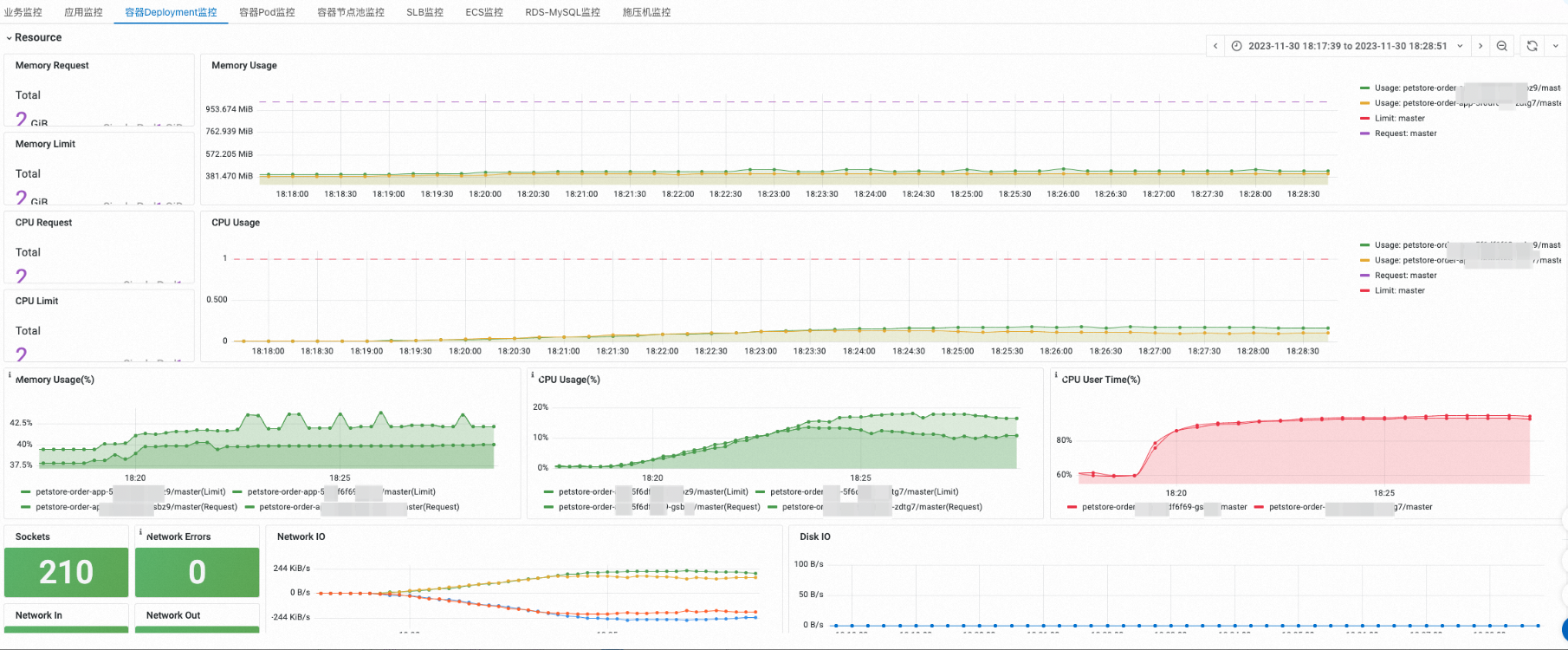
您可以在Resource区域,查看Deployment CPU、内存、磁盘和网络资源的监控信息。
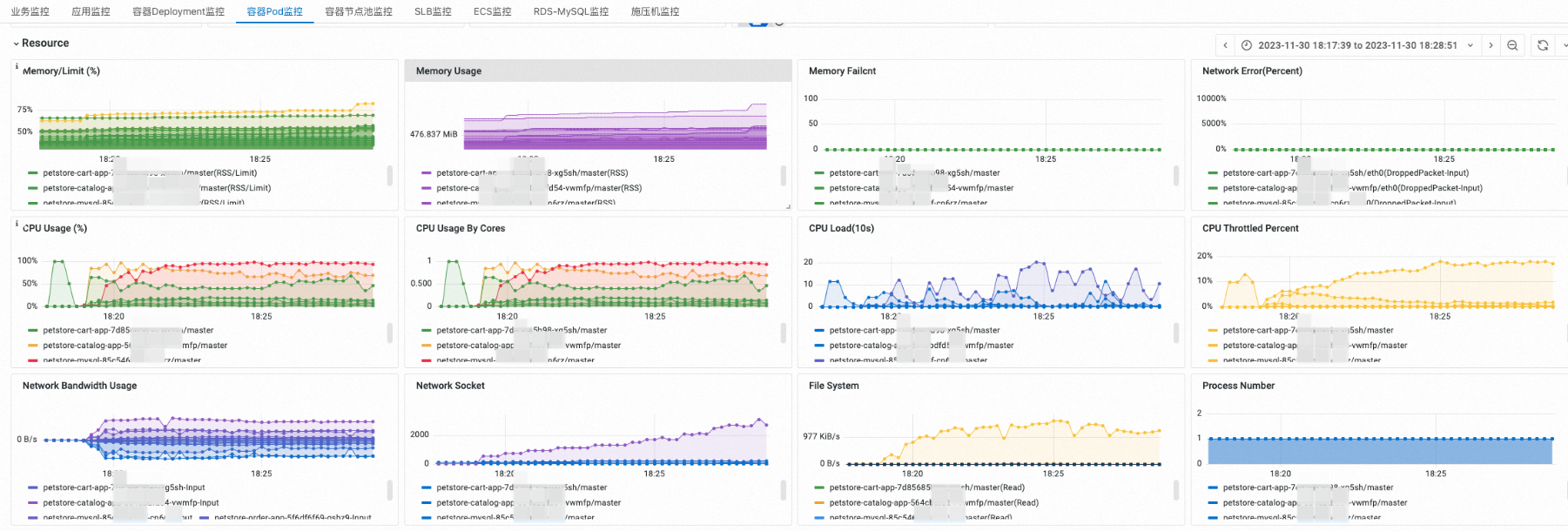
容器Pod监控
您可以在Pod监控概览区域,选择指定namespace中的一个或多个Pod。

您可以在Resource区域,查看Pod CPU、内存、磁盘和网络资源的监控信息。
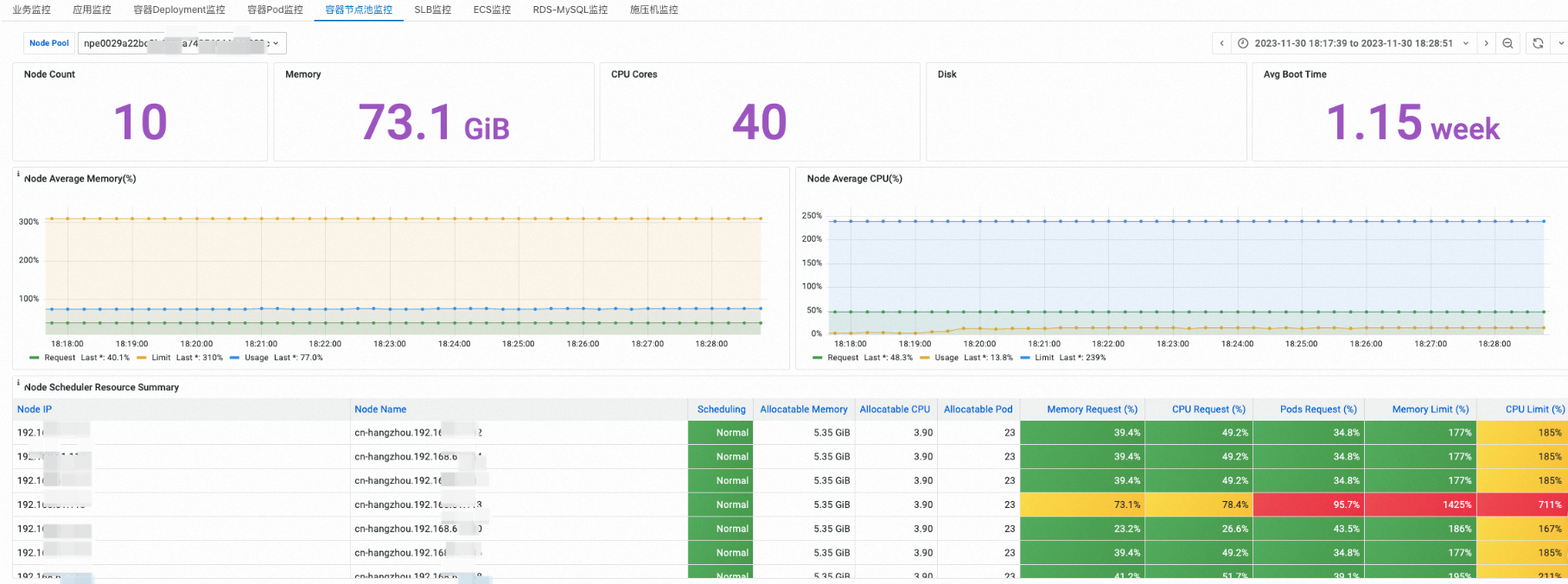
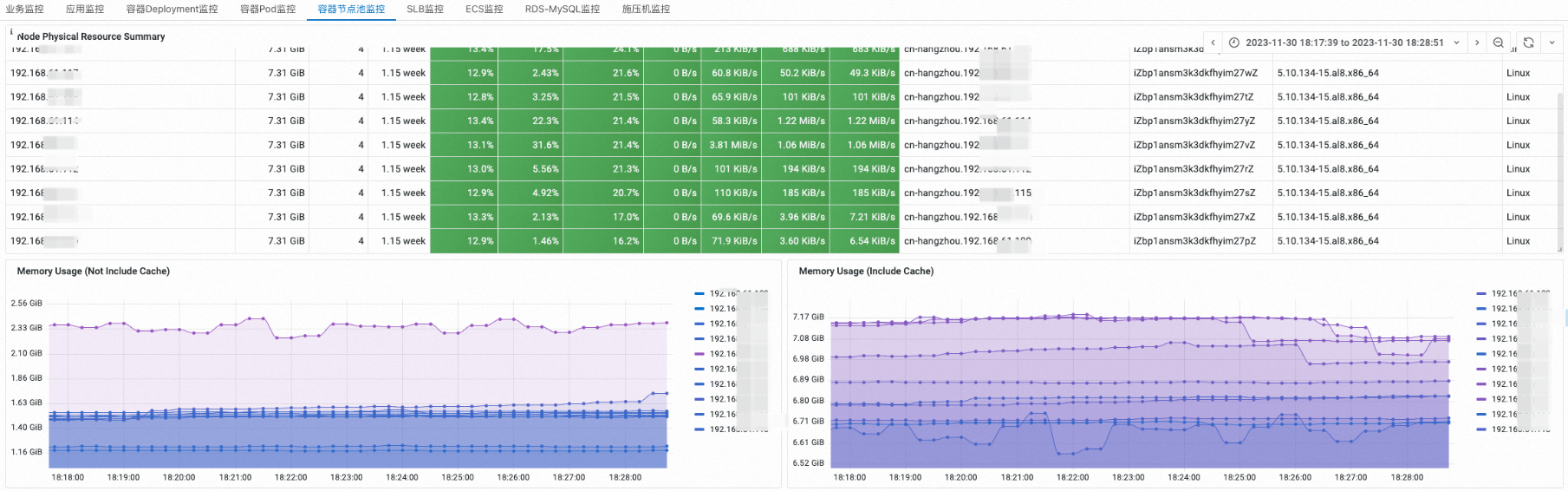
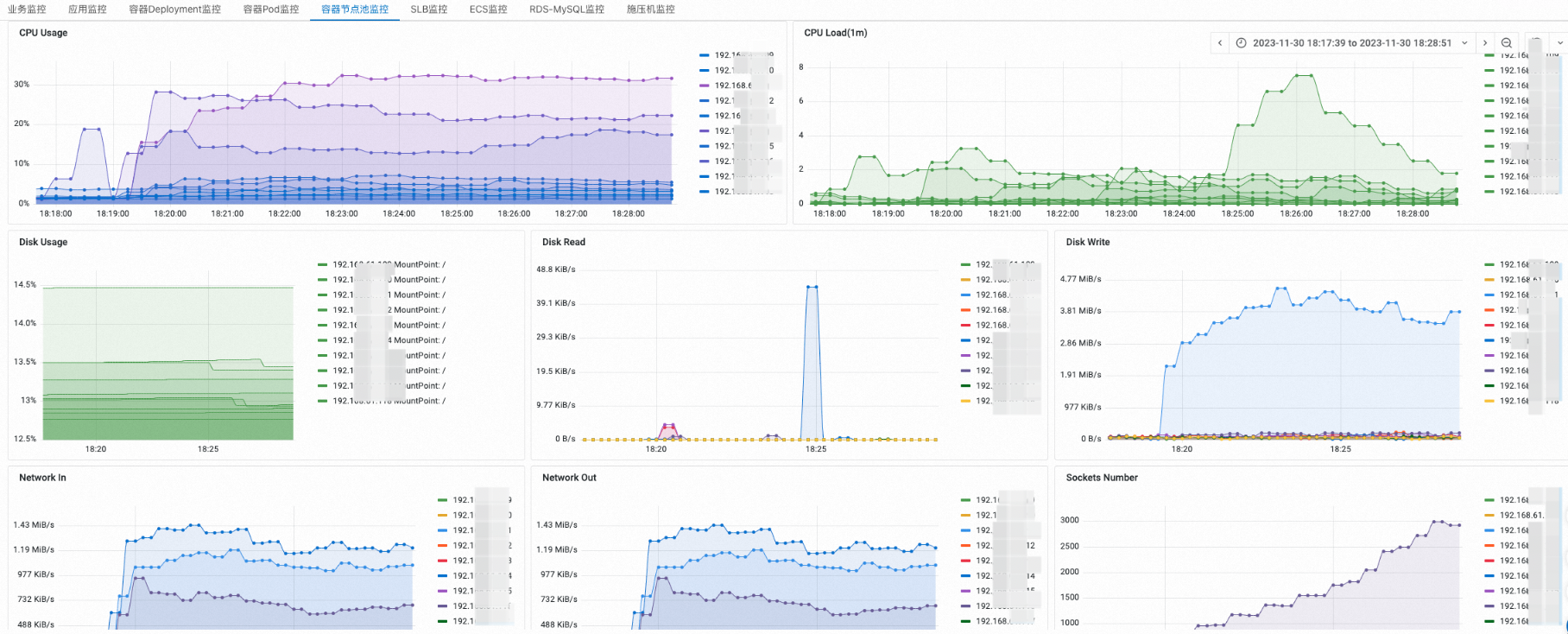
容器节点池监控
您可以在容器节点池监控页签,选择指定节点池,查看节点池的CPU、内存、磁盘和网络资源水位。
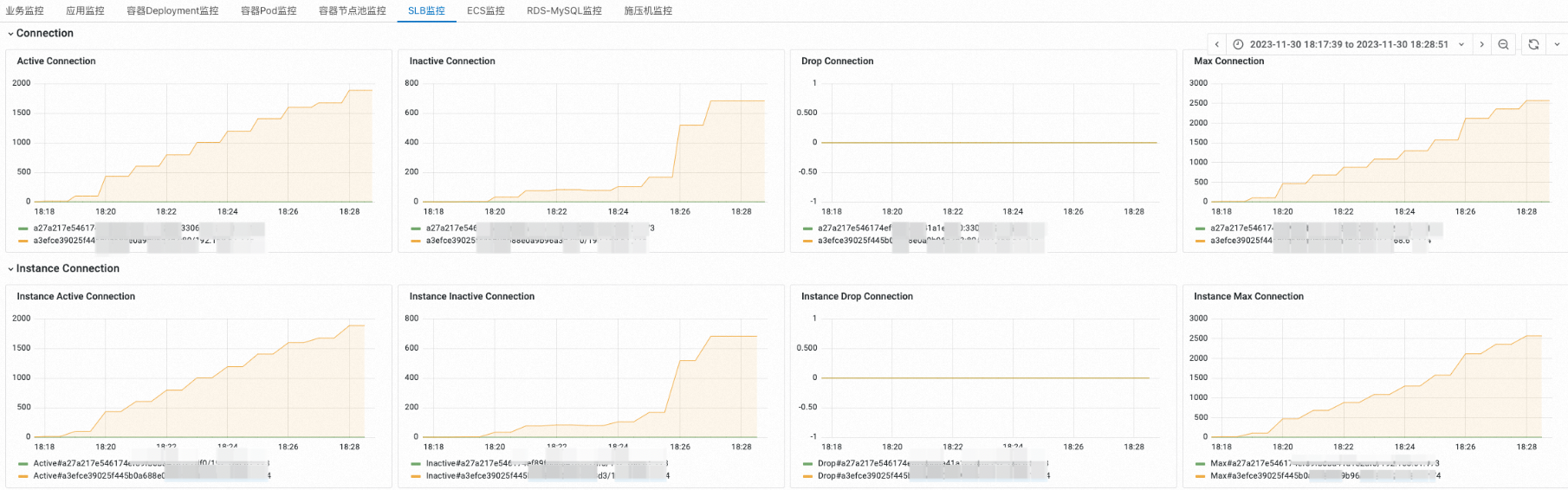
负载均衡SLB监控
前提条件
查看负载均衡SLB监控
查看实例健康状态和带宽水位。
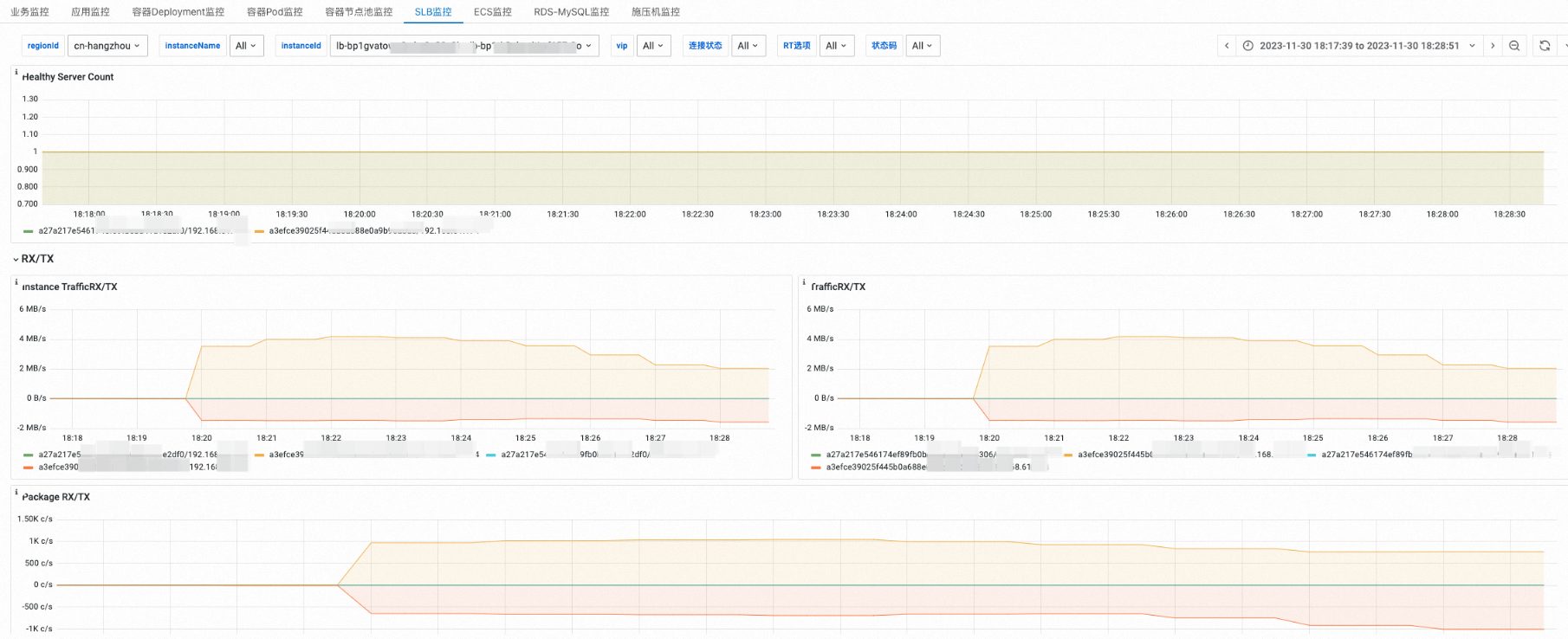
查看连接数监控。
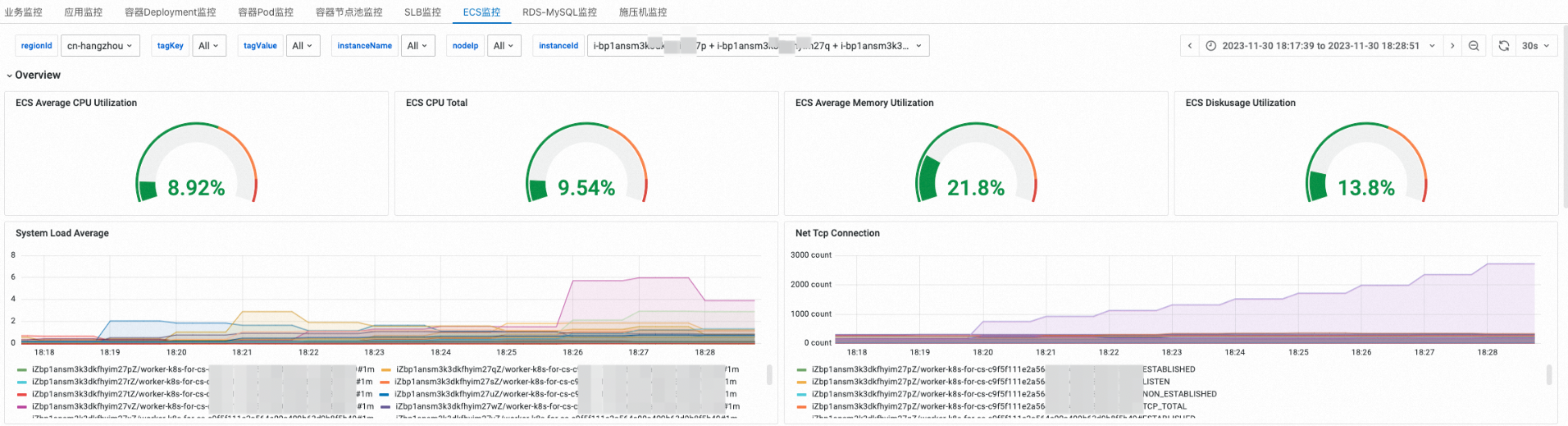
ECS监控
前提条件
查看ECS监控
在ECS监控页签的概览区域,查看指定ECS实例的整体资源水位和负载。
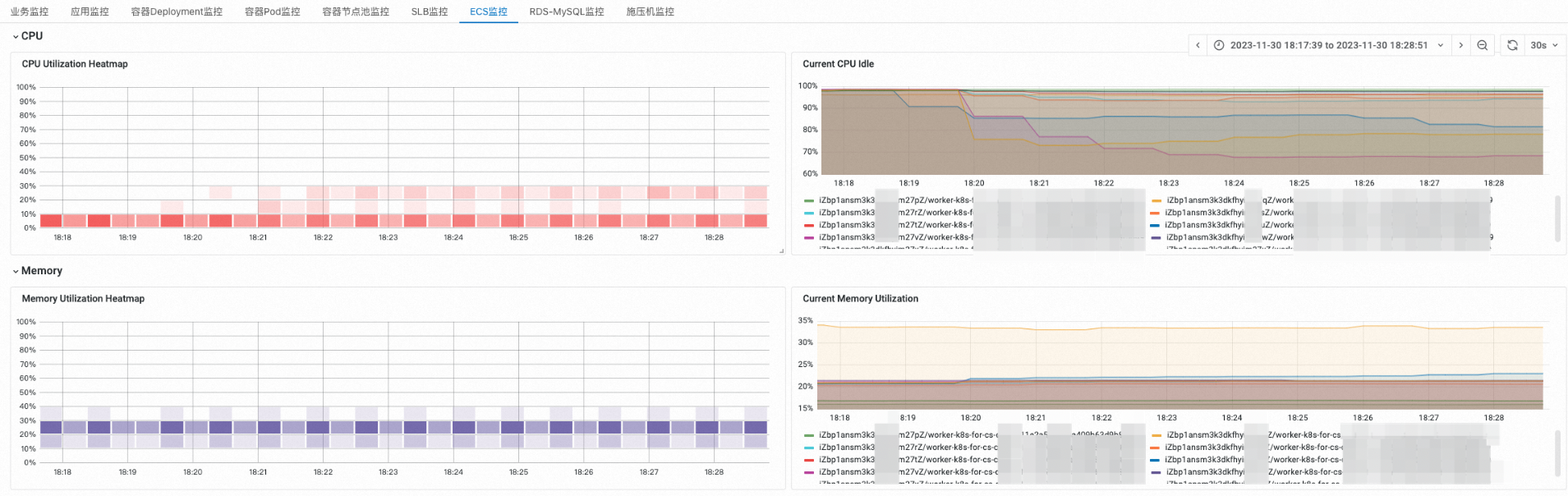
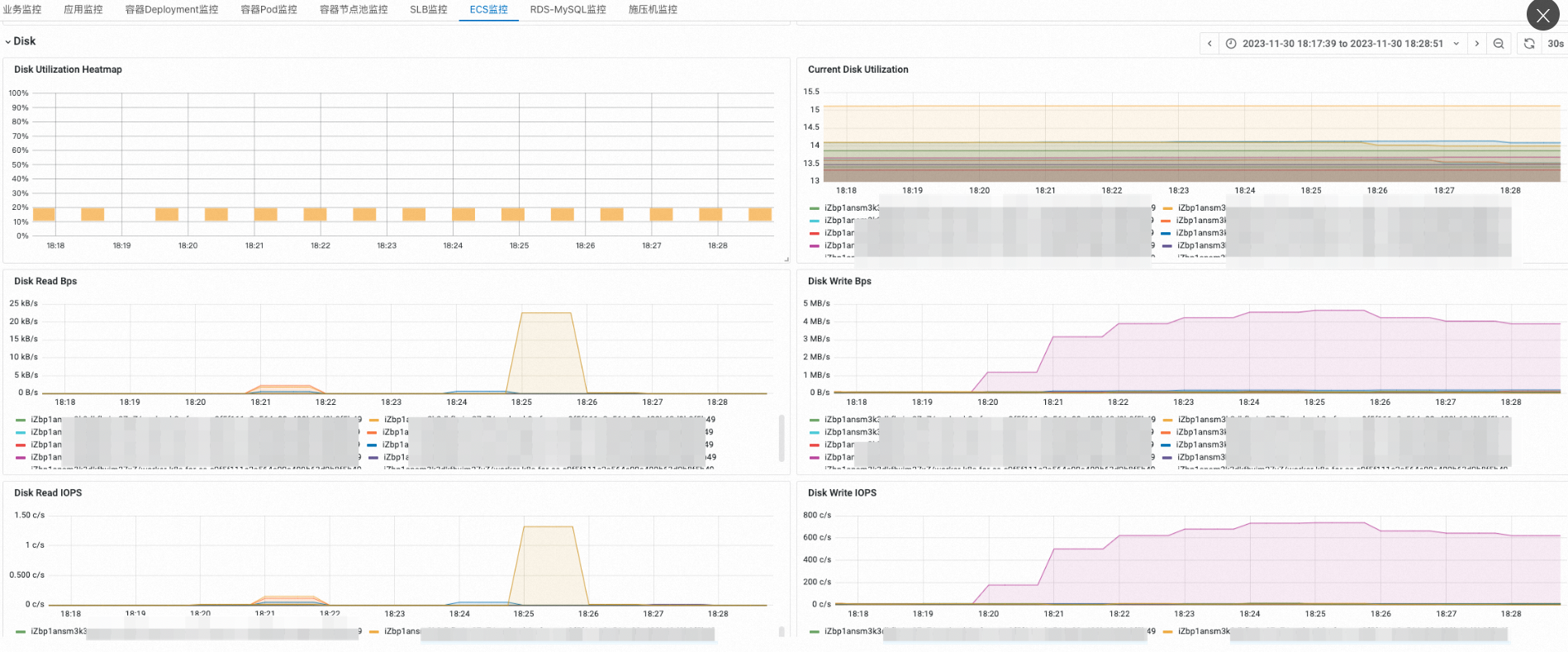
在ECS监控页签,查看各资源的时序监控指标,分析性能拐点。
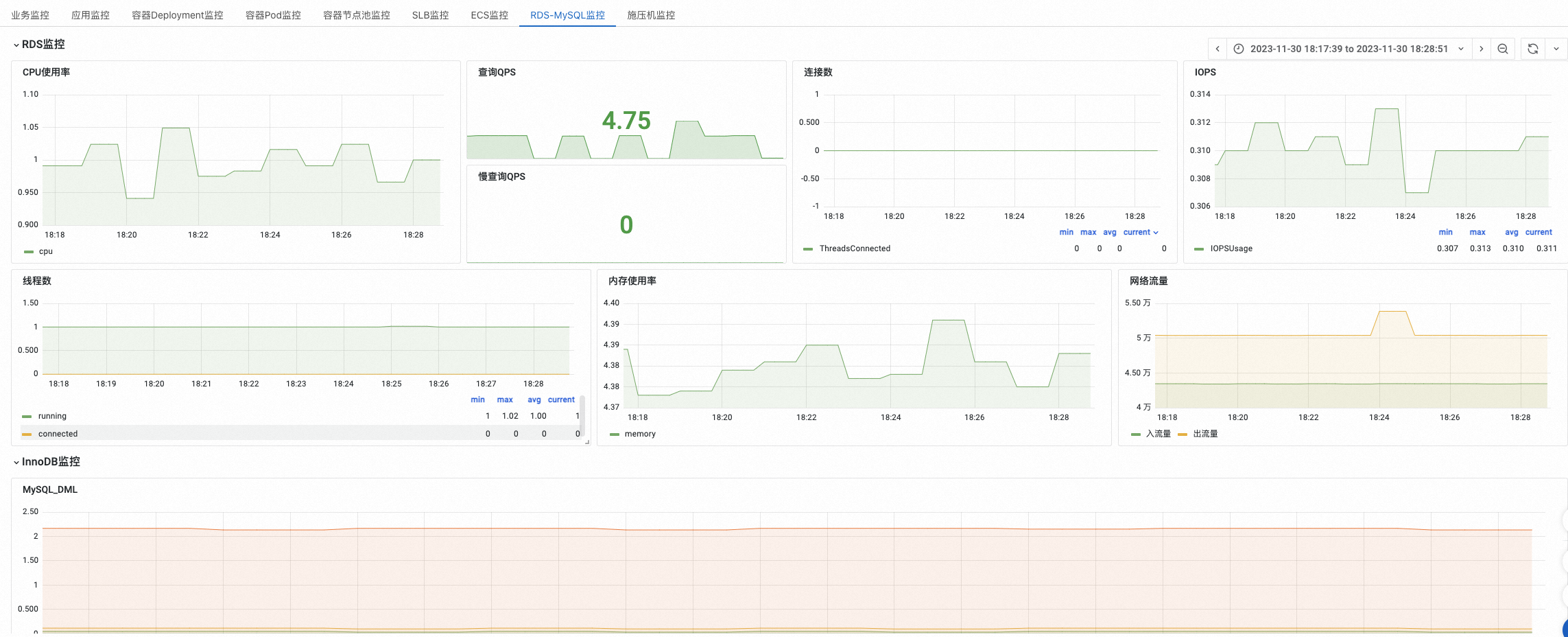
RDS-MySQL监控
前提条件
已开通PTS服务。更多信息,请参见开通方式。
在对应地域创建Prometheus实例for云服务,并已集成RDS-MySQL产品。
在创建压测场景时,已配置RDS-MySQL云产品监控。具体操作,请参见云产品监控。
查看RDS-MySQL监控
通过分析实例的CPU、内存、连接、QPS和MySQL DML判断资源水位和容量。
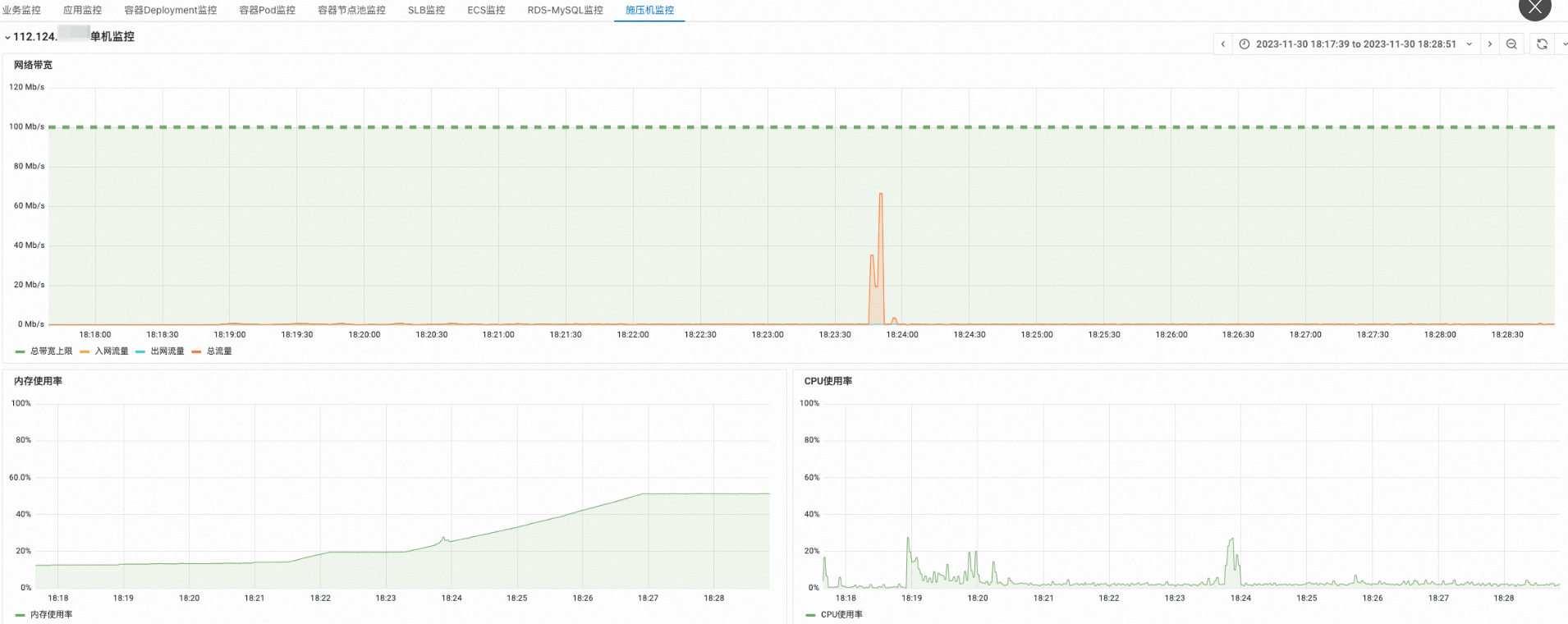
施压机监控
在施压机监控的集群监控区域,查看集群整体带宽、CPU和内存资源水位。如果带宽达到上限,施压机可能成为性能瓶颈,影响压测业务的监控指标。此时,需要扩展施压机数量,降低施压集群负载。
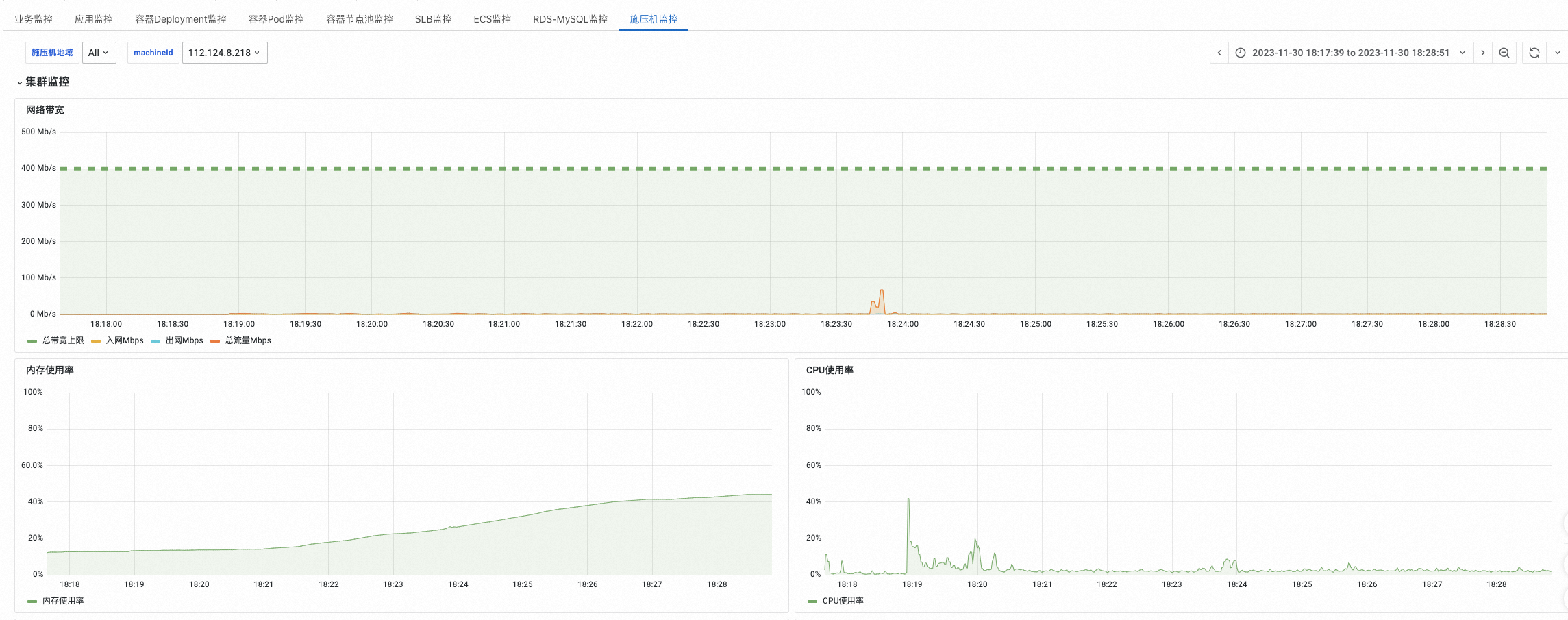
集群垃圾回收次数也可以作为集群负载参考。如果持续出现Full GC,需要检查脚本或扩展施压机数量,以提升施压集群性能。

在概览中选择machineId,查看指定施压机的单机监控。