
PTS的JDBC压测功能支持对MySQL(MySQL 5.x、MySQL 8)、SQL Server、PostgreSQL、MariaDB数据库进行压测。本文介绍如何使用JDBC压测功能。
背景信息
JDBC(Java Database Connectivity,Java数据库连接)通过Java API访问关系型数据库,并可对其进行增删改查等操作。特点包括:访问数据库便捷、跨平台性强、支持SQL语句,使底层更自由。
为什么要做JDBC压测
验证新数据库在高负载下的性能。
通常对数据库的操作都是基于HTTP、FTP或其他协议执行的,但在某些特定情况下,需要绕过这些中间协议直接测试数据库,比如您希望只测试特定High-Value查询的性能而不触发所有相关查询。
验证某些数据库连接池参数。例如,最大连接数。
使用PTS平台执行JDBC压测的优势
全球分布施压机,即压即用,可支持百万并发,千万QPS压测。
支持吞吐量模式,可以设置全局目标QPS,更直观衡量服务端性能。
支持压测中调速,可以灵活调整并发或QPS,不断逼近性能极限点。
针对分布式压测,支持自动切分文件,支持全局生效Timer、Controller组件,一键开启分布式压测。
发布JMeter PTS插件,使用JMeter GUI客户端即可发起云端分布式压测,无缝衔接脚本调试和执行阶段。
支持VPC内网压测,可以在压测时快速打通施压机与用户VPC网络,保证内网压测的网络畅通。在压测结束后,也会即时关闭网络通道,保证网络安全。
降低时间成本和资源消耗。当您想要优化SQL时,直接修改代码中的SQL语句或者执行其他数据库操作将会非常复杂且耗时。而通过JDBC压测,无需您直接侵入代码操作,能够集中精力调优SQL。
功能入口
- 登录PTS控制台,在左侧导航栏选择,然后单击JDBC压测。
在创建JDBC场景页面,填写场景名,然后配置JDBC连接。
设置
说明
压测云数据库来源
选择压测云数据库来源,然后依次选择地域、实例和数据库。
数据库类型
支持数据库类型包括:
MySQL、SQL Server、PostgreSQL、MariaDB。JDBC URL
格式为
[ip]:[port]/数据库名,例如[XX].mysql.zhangbei.rds.aliyuncs.com:3306/db。说明如果您在数据库类型中选择SQL Server,那么JDBC URL格式为
[ip]:[port];databaseName=数据库名。用户名
数据库登录用户名,例如user。
密码
数据库登录密码,例如password。
隔离级别
数据库隔离级别,您可根据MySQL数据库对应设置选择相应级别,支持的类型包括:
DEFAULT:默认
TRANSACTION_NONE:未开启事务
TRANSACTION_READ_UNCOMMITTED:读未提交
TRANSACTION_READ_COMMITTED:读已提交
TRANSACTION_SERIALIZABLE:可串行化
TRANSACTION_REPEATABLE_READ:可重复读
自动提交SQL
打开开关:自动提交事务,即结束当前事务开始下一个事务。
说明事务通常是指用SQL脚本对数据库表进行一系列操作。
关闭开关:修改数据库时,将用户操作一直处于某个事务中,直到执行一条commit提交或rollback回滚语句才会结束当前事务重新开始一个新的事务。
在场景配置页签下,单击+添加JDBC请求节点,为目标串联链路添加所需测试节点。
场景配置
单击串联链路右侧的 图标,展开串联链路,并配置基本信息、出参、检查点等信息。
图标,展开串联链路,并配置基本信息、出参、检查点等信息。
基本配置
在串联链路的基本配置页签设置压测基本参数。具体配置如下。
相关基本配置 | 说明 |
查询 | 填写需要被压测的SQL语句。 说明 如果要在一个JDBC请求节点中执行多条SQL语句,查询类型必须选择Callable Statement,每条语句用半角分号(;)隔开,JDBC URL后还要添加?allowMultiQueries=true。 |
查询类型 | JDBC中被压测SQL语句类型,包括:
说明 使用占位参数时,选择对应查询的Prepared类型。 |
查询超时时间 | 施压端等待被压测端响应的时间限制,单位为秒。例如5。 |
占位参数
在JDBC中使用占位参数能防止SQL注入、提高SQL执行效率。您可以在串联链路的占位参数页签设置相关参数值。
设置 | 说明 |
参数类型 | 输入占位参数的类型。 说明 支持MySQL数据库的数据类型。 |
参数值 | 输入占位参数值。 |
示例:
以被压测SQL语句select * from mydb where id = ?为例,在占位参数的参数类型处输入Integer,在参数值处输入1,则最后生效的SQL为select * from mydb where id = 1。该SQL会在数据库中生效,并显示在数据库中。
参数类型与参数值要和SQL语句中的半角问号(?)严格对应。
出参设置
在串联链路的出参设置页签设置出参。具体操作,请参见接口出参。
检查点设置
在串联链路的检查点设置页签设置检查点。具体操作,请参见检查点(断言)。
控制器和定时器(可选)
您可以根据不同压测场景的需求,添加控制器和定时器。
在场景配置页签下,单击+添加控制器选择所需的控制器。
循环控制器:控制所含测试节点应循环执行的次数。
选择循环控制器后,单击其右侧的
 图标,选择添加需循环执行的测试节点,并设置循环次数。压测时,会将此循环控制器下的测试节点按序执行设置的次数。
图标,选择添加需循环执行的测试节点,并设置循环次数。压测时,会将此循环控制器下的测试节点按序执行设置的次数。事务控制器:事务控制器下所包含的所有测试节点将会被算作为一个事务。其包含生成父样本和是否包含样品中定时器和前后程序的持续时间两个设置项。
生成父样本:
开启开关:该事务控制器下各测试节点自身的压测结果不会在压测报告中独立输出,而会被聚合作为事务控制器的结果呈现在报告中。
关闭开关:该事务控制器以及其包含的测试节点的压测结果均会显示在报告中。
是否包含样品中定时器和前后程序的持续时间:若选择开启此开关,则压测报告中事务控制器的平均响应时间为所有测试节点、定时器以及前后置处理器的平均响应时间之和。若不开启此开关,则事务控制器的平均响应时间仅为所有测试节点平均响应时间之和。
仅一次控制器:仅一次控制器下添加的节点仅会被执行一次。
在场景配置页签下,单击+添加定时器选择所需的定时器。
常量定时器:可设置停顿时长,表示压测过程中,在此处停顿的时长,单位为毫秒。
同步定时器:可设置停顿时长和模拟用户数,表示在一定时间内先等待达到一定用户数然后触发测试,但若在设定时间内未达到指定用户数,则不会继续等待,直接触发测试。
统一随机定时器:统一随机定时器用于控制停顿时长,可设置延迟基准和可变跨度。延迟基准为固定停顿时间,可变跨度为随机停顿时间的最大值。统一随机定时器的停顿时长为延迟基准所设的固定停顿时间加上可变跨度所设时间范围内的随机值。各随机值出现的概率相等。
高斯定时器:高斯定时器与统一随机定时器类似,同样用于设置停顿时长,可设置延迟基准和可变跨度。若要求随机停顿时间符合正态分布,可使用高斯定时器。
固定吞吐量定时器:固定吞吐量定时器用于控制吞吐量,使测试节点按吞吐量执行。可设置条件和对应的吞吐量。条件包含仅当前线程、所有活跃线程、当前链路下活跃线程、全局活跃线程和当前链路下全局活跃线程。
施压配置
单击施压配置页签,设置压测模式。
压测配置 | 描述 |
压力来源 | 本次压测使用的网络类型,包括公网和阿里云VPC内网两种类型。具体详情,请参见压力来源(公网和VPC)。 |
并发数 | 虚拟用户发起请求的个数。例如:100个并发数就是100个虚拟用户同时发起了请求。 |
压测时长 | 建议压测时长不低于2分钟,总时长默认不可超过24小时。 |
流量模型 | 并发数的递增模型。选择不同的流量模型,页面右侧的压力预估图会同时刷新。
|
递增时长 | 全部并发从0到全部运行起来的时间。当流量模型选择的是均匀递增或者阶梯递增时,需要配置该递增时长。 |
递增阶梯数 | 完成递增时间段的阶梯数。当流量模型选择的是阶梯递增时,需要配置该递增阶梯数。 |
指定IP数 | 指定压测来源的IP个数。具体详情,请参见指定施压IP数。 |
流量地域定制 | 通过指定施压机的地理位置,即可模拟当地的用户流量。开启后可对施压机地域分布进行配置,从而实现施压流量地域分布的定制化。具体详情,请参见定制地域流量。 |
启动压测
您可以在创建压测场景页面左下方,单击调试场景,对配置的场景进行调试,验证配置是否正确。具体操作,请参见调试场景。然后单击保存去压测,在弹出的对话框中单击确定,启动压测。
后续操作
查看压测报告。具体操作,请参见查看多协议压测报告。
场景示例
此处以阿里云RDS数据库为例,若您需要验证所用的RDS数据库实例规格是否能承受住大量读写请求,以此来决定您是否要对该实例进行扩容,您仅需在PTS控制台执行简单操作,即可通过PTS发起压测。以下为此场景下发起数据库压测时的具体操作步骤。
配置RDS数据安全性。
创建JDBC压测场景。
登录PTS控制台,在左侧导航栏选择,然后单击JDBC压测。
在创建JDBC场景页面,填写场景名,选择压测云数据库来源为RDS,然后依次选择地域、实例和数据库。
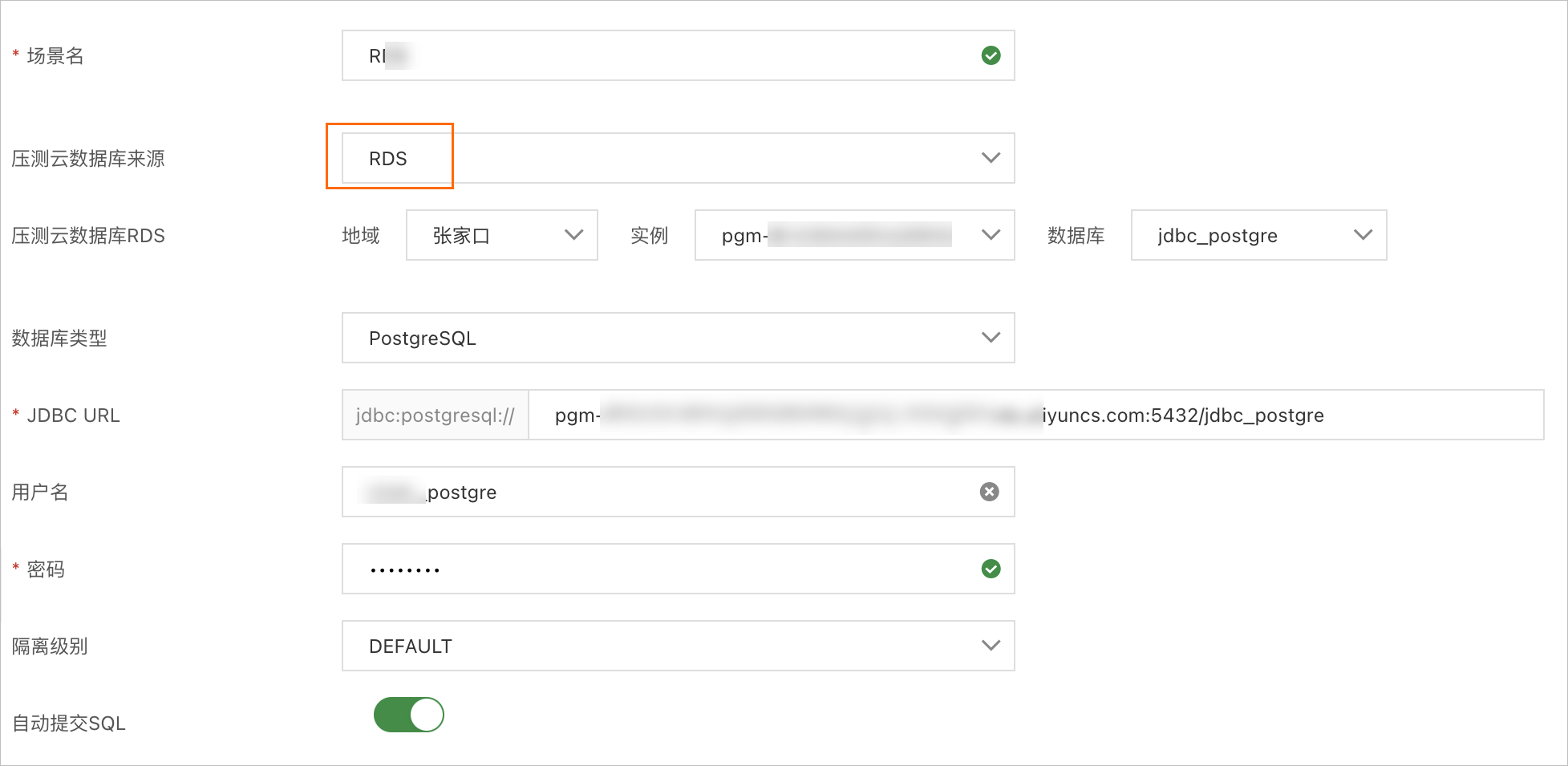
系统会默认生成对应的数据库类型、JDBC URL和用户名。然后您只需要自行设置密码。
在场景配置页签下,单击+添加JDBC请求节点,为目标串联链路添加所需测试节点。具体操作,请参见场景配置。
单击施压配置页面,选择压力来源为阿里云VPC内网,然后选择步骤1中添加的VPC和安全组,并配置其他项。
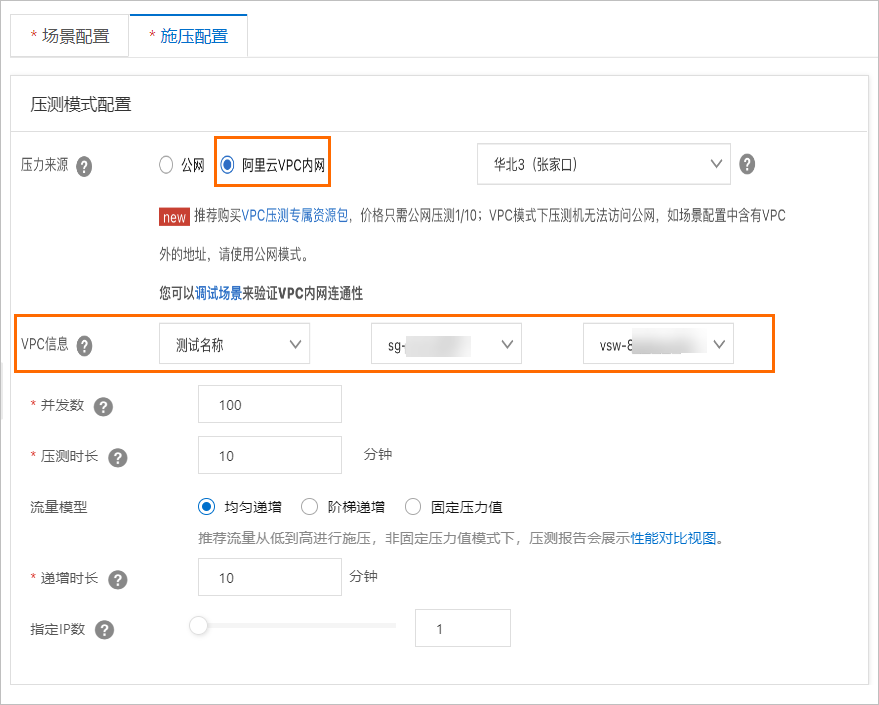 说明
说明PTS支持的流量模型有脉冲模型、阶梯递增和均匀递增。
脉冲模型会模拟流量在瞬间突然增大,常用于秒杀、抢购等业务场景。
递增模型可以模拟在一定时间段内,用户量不断增大,常用于模拟有预热的业务场景。
单击保存去压测,在弹出的对话框中单击确定。
压测开始后,您可以观察以下指标情况:
压测中的核心指标有:请求成功率、请求响应时间(RT)和系统吞吐量(QPS)。
请求成功率:您不仅需要查看全局的请求成功率,还需要关注一些核心API的成功率,避免整体成功率达标,但核心API成功率不足的情况。
请求响应时间:您需要关注99、95、90、80等一些关键分位的指标是否符合预期,相对来说平均响应时间对您没有太大的参考意义,因为压测需要保证绝大部分用户的体验,在不清楚离散程度的情况下,平均值容易导致误判。
系统吞吐量:是衡量系统能承受多大访问量的指标,是压测不可缺少的标准。