概述
我们可以将关系模型的计算逻辑简单归纳为如下2点:
只有当前查询的字段和关联字段参与计算(若查询中只包含其中1张逻辑表的字段,则关系模型中其他逻辑表不会参与计算)
保证度量字段的完整性
大致的处理流程如下图所示,相比于直接物理关联,关系模型可以有效避免数据膨胀:

以上只是关系模型处理逻辑的简单介绍,在实际场景中,不同的关联基数、数据匹配度,以及拖入不同种类的字段都会触发不同的处理方法,可参考以下的具体示例。
以具体的例子介绍
模型配置
数据表字段
主表:病例表 | 从表:人数表 |
|
|
关系模型结构
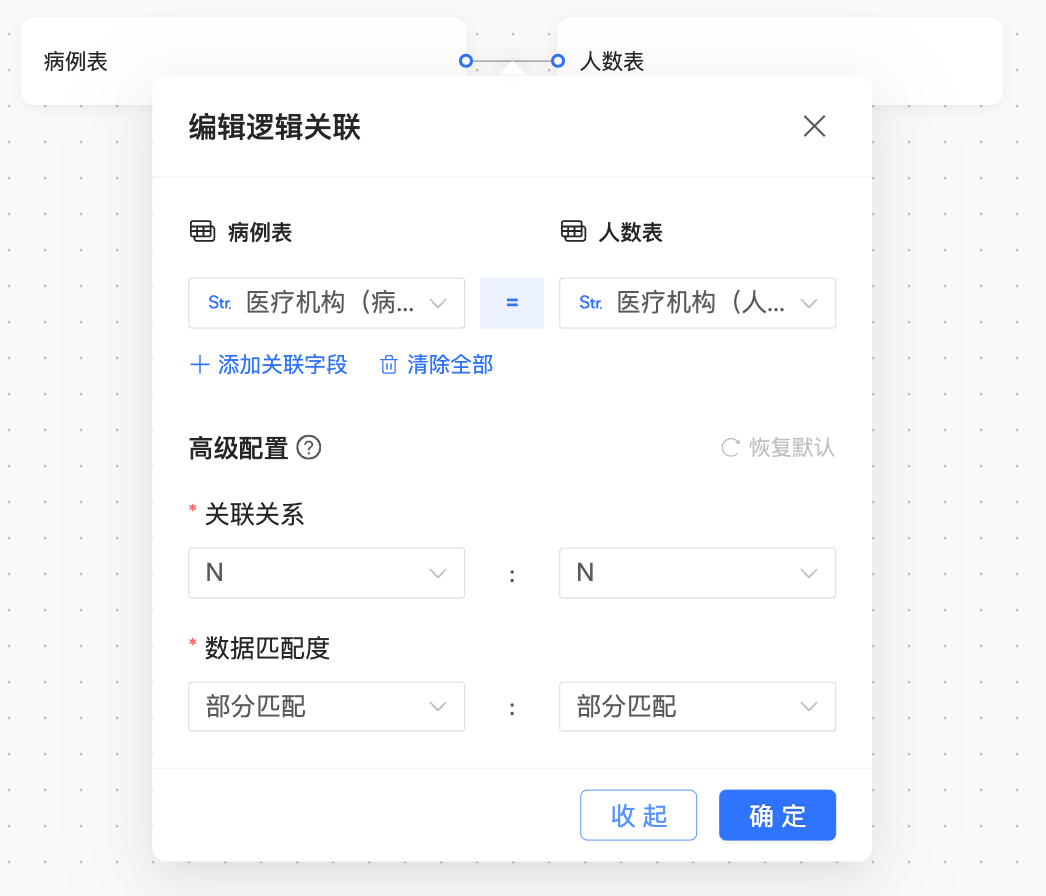
其中:
关联键:医疗机构 = 医疗机构
关联关系:N:N
数据匹配度:部分匹配:部分匹配
图表配置及计算方法
只使用单表字段:从单表中取数,不做关联
图表配置
维度 | 医疗机构(人数表)、年份(人数表) |
度量 | 人数-求和(人数表) |
结果数据

使用多表字段,只有维度:通过INNER JOIN进行关联
图表配置
维度 | 月份(病例表)、年份(人数表) |
度量 | - |
结果数据
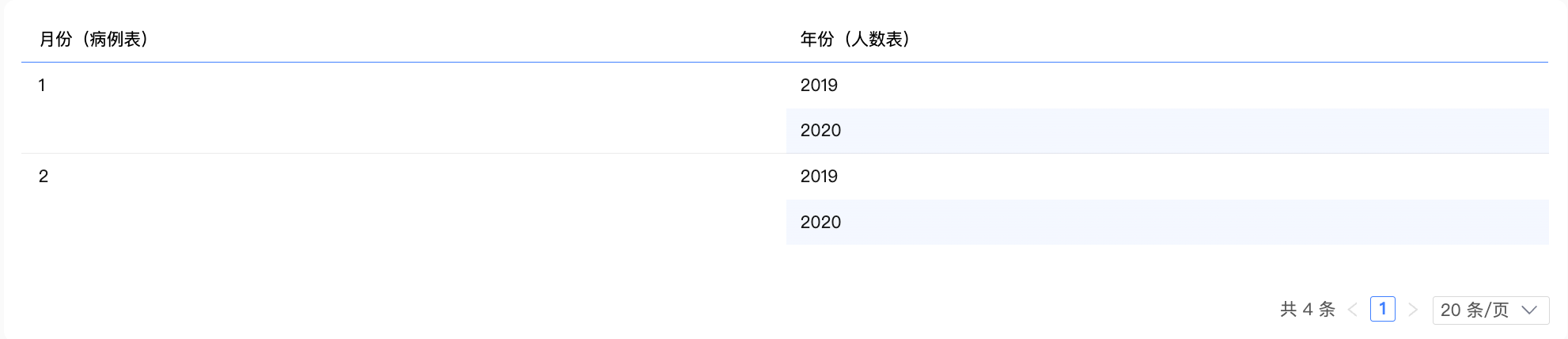
解释说明
使用INNER JOIN:图表中只有维度时,我们认为必须能够匹配上的数据才是有意义的,无法匹配的数据(比如医疗机构D和E)是没有意义的。
2张表通过“医疗机构”字段进行内关联,形成中间过程如下,去重后,展示结果数据。
医疗机构(病例表)
月份(病例表)
医疗机构(人数表)
年份(人数表)
A
1
A
2020
A
1
A
2019
B
1
B
2020
B
1
B
2019
C
1
C
2020
C
1
C
2019
A
2
A
2020
A
2
A
2019
B
2
B
2020
B
2
B
2019
C
2
C
2020
C
2
C
2019
A
1
A
2020
A
1
A
2019
使用多表字段,只有度量:两表数据分别聚合后再拼接
图表配置
维度 | - |
度量 | 病例数-求和(病例表)、人数-求和(人数表) |
结果数据

解释说明
只有度量,没有维度时,聚合后只会有1行数据。
此时只需要病例表、人数表的度量分别进行聚合,拼接展示即可。
使用多表字段,包含维度和度量
示例1 - 左表维度(关联键)、右表度量
图表配置
维度 | 医疗机构(病例表) |
度量 | 人数-求和(人数表) |
结果数据

解释说明
第1步:取图表中的维度字段【医疗机构(病例表)】和度量所在表的关联字段【医疗机构(人数表)】,计算出维度组合。
因为该查询中包含了“人数表”的度量,所以在该步骤进行关联时需要保留“人数表”完整的维度,从而保证后续的计算中“人数表”的度量也是完整的。
医疗机构(人数表) | 医疗机构(病例表) |
A | A |
B | B |
C | C |
E | - |
第2步:将维度组合关联到“人数表”,形成中间表。由于只关联了维度组合,且维度组合中每个“医疗机构”都只有唯一一行,此时并不会产生数据膨胀。
医疗机构(人数表) | 医疗机构(病例表) | 人数(人数表) |
A | A | 100 |
B | B | 80 |
C | C | 70 |
A | A | 110 |
B | B | 75 |
C | C | 90 |
- | E | 60 |
- | E | 60 |
第3步:将中间表按照图表中拖入的维度进行聚合,得出最终结果。
因“医疗机构E”未能与“医疗数据”匹配,因此结果中会存在一行数据,医疗机构为空值。
示例2 - 左表维度(非关联键)、右表度量【错误示范】
图表配置
维度 | 年份(病例表) |
度量 | 人数-求和(人数表) |
结果数据

解释说明
第1步:取图表中的维度字段【年份(病例表)】和度量所在表的关联字段【医疗机构(人数表)】,计算出维度组合(为了便于理解,此处我们把【医疗机构(病例表)】也展示出来)。
因为该查询中包含了“人数表”的度量,所以在该步骤进行关联时需要保留“人数表”完整的维度,从而保证后续的计算中“人数表”的度量也是完整的。
医疗机构(人数表) | 医疗机构(病例表) | 年份(病例表) |
A | A | 2019 |
A | A | 2020 |
B | B | 2020 |
C | C | 2020 |
E | - | - |
由于在“病例表”中,医疗机构A有2019、2020两行数据,导致维度组合中“医疗机构(人数表)”出现2行“A”。
第2步:将维度组合关联到“人数表”,形成中间表。
年份(病例表) | 医疗机构(人数表) | 人数(人数表) |
2019 | A | 100 |
2020 | A | 100 |
2020 | B | 80 |
2020 | C | 70 |
2019 | A | 110 |
2020 | A | 110 |
2020 | B | 75 |
2020 | C | 90 |
- | E | 60 |
- | E | 60 |
维度表中重复的2行“A”在关联到人数表时,将会造成“医疗机构A”的人数产生重复行,这将导致最终结果的膨胀。
第3步:将中间表按照图表中拖入的维度进行聚合,得出最终结果。
在该场景中,即使用户使用了关系模型,却还是造成了数据膨胀。为尽可能规避类似的问题,我们建议:
关联键配置正确:比如在当前示例中,应当把“医疗机构”、“年份”设置成关联键,这样在“第2步”生成中间表时,将不会形成错误的数据膨胀。
在不需要跨表的情况下,使用同一个逻辑表中的维度、度量:比如在当前示例中,选择“人数表”中的医疗机构、人数进行查询,数据将能正确呈现。
示例3 - 右表维度(非关联键)、左表度量【错误示范】
图表配置
维度 | 年份(人数表) |
度量 | 覆盖区域数-求和(病例表) |
结果数据

解释说明
第1步:取图表中的维度字段【年份(人数表)】和度量所在表的关联字段【医疗机构(病例表)】,计算出维度组合(为了便于理解,此处我们把【医疗机构(人数表)】也展示出来)。
因为该查询中包含了“病例表”的度量,所以在该步骤进行关联时需要保留“病例表”完整的维度,从而保证后续的计算中“病例表”的度量也是完整的。
医疗机构(病例表) | 医疗机构(人数表) | 年份(人数表) |
A | A | 2020 |
A | A | 2019 |
B | B | 2020 |
B | B | 2019 |
C | C | 2020 |
C | C | 2019 |
D | - | - |
由于在“人数表”中,医疗机构A、B、C、E都有2019、2020两行数据,导致维度组合中“医疗机构(病例表)”出现2行“A”、2行“B”和2行“C”(医疗机构E没有关联上)。
第2步:将维度组合关联到“病例表”,形成中间表。
医疗机构(病例表) | 年份(人数表) | 覆盖区域数(病例表) |
A | 2020 | 1 |
A | 2019 | 1 |
B | 2020 | 1 |
B | 2019 | 1 |
C | 2020 | 2 |
C | 2019 | 2 |
A | 2020 | 1 |
A | 2019 | 1 |
B | 2020 | 1 |
B | 2019 | 1 |
C | 2020 | 2 |
C | 2019 | 2 |
D | - | 1 |
A | 2020 | 1 |
A | 2019 | 1 |
维度表中重复的医疗机构A、B、C在关联到病例表时,将会造成的覆盖区域数产生重复行,这将导致最终结果的膨胀。
第3步:将中间表按照图表中拖入的维度进行聚合,得出最终结果。
该查询对医疗机构A、B、C的“覆盖区域总数”都进行了重复计算,导致数据不正确,原因和建议同“示例2”
关联键配置正确:应当把“医疗机构”、“年份”设置成关联键。
在不需要跨表的情况下,使用同一个逻辑表中的维度、度量:应当选择“病例表”中的年份、覆盖区域数进行查询。
与物理建模对比
Quick BI旧版本提供的数据集建模能力是物理建模,即:通过可视化配置,构造出多表关联、合并的数据集模型,形成一整张数据大宽表。
物理建模需要明确指定关联方式,如:左关联(Left Join)、内关联(Inner Join)、全关联(Full Join)等等,这要求用户在进行数据建模时,对数据情况要有清晰的掌控,对数据完整性、唯一性进行提前处理,否则将出现严重的数据膨胀等问题。
以具体的例子介绍
模型配置
数据表字段
主表:病例表 | 从表:人数表 |
|
|
物理模型结构
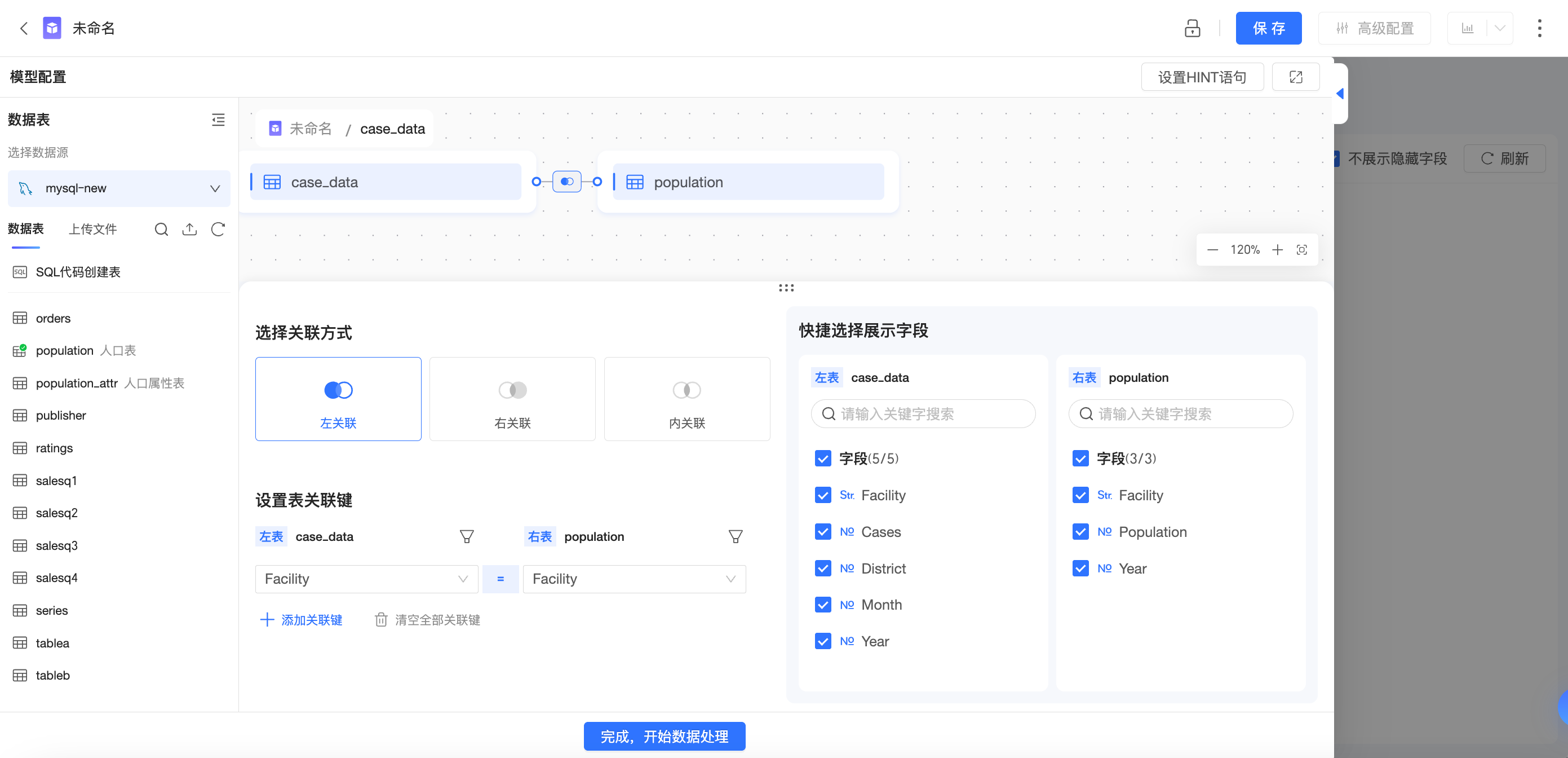
物理模型宽表
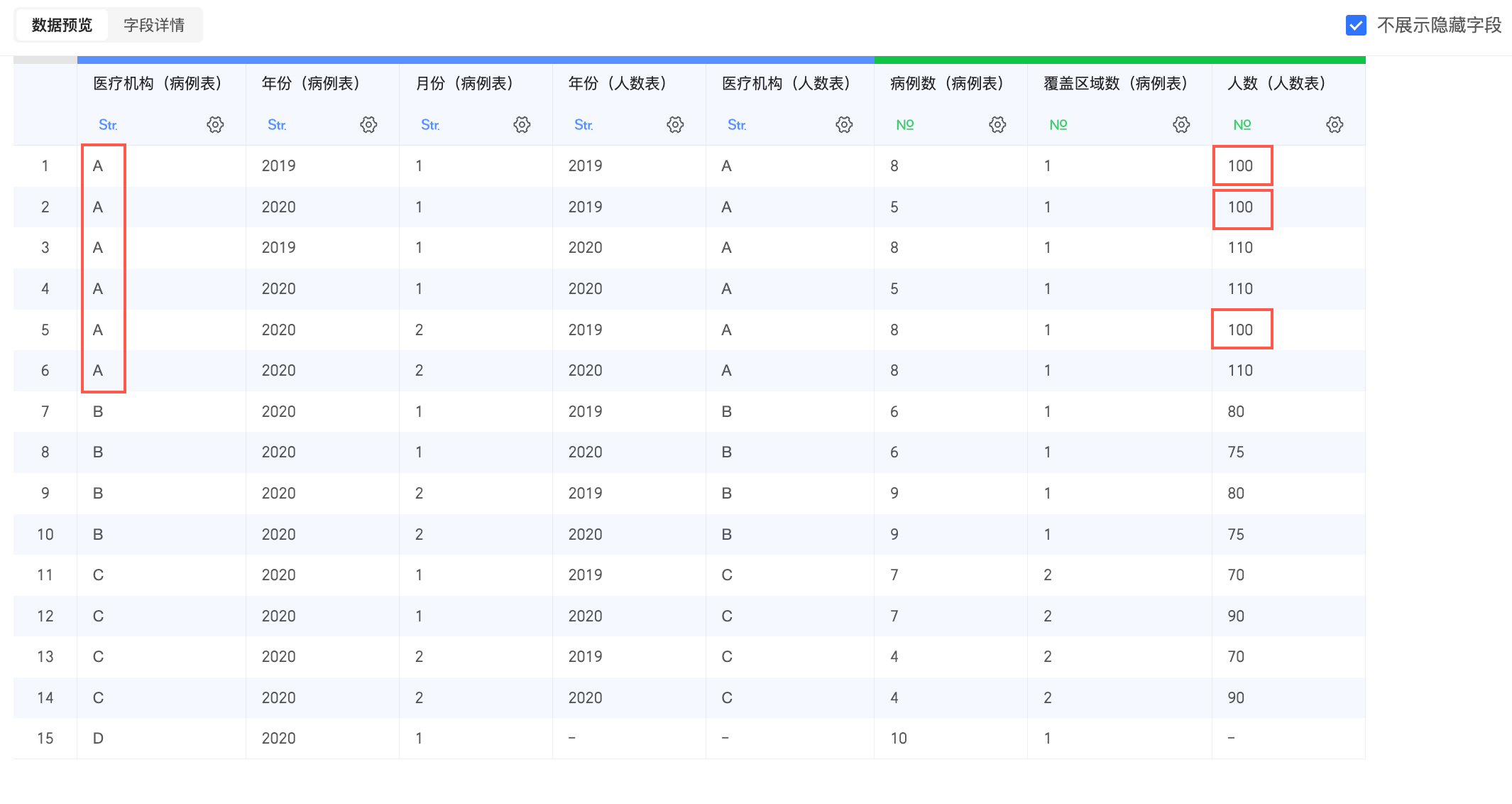
因“医疗机构”字段不唯一,在物理建模后出现严重的数据膨胀,比如下图中医疗机构为“A”,年份(人数表)为“2019”的人数(人数表),被错误地计算了3次。
图表配置及计算方法
示例1
图表配置
维度 | 医疗机构(病例表) |
度量 | 人数-求和(人数表) |
结果数据

正确结果
示例2
图表配置
维度 | 年份(病例表) |
度量 | 人数-求和(人数表) |
结果数据

正确结果
物理建模缺点
物理建模时,需要用户自己对建模结果的正确性进行判断和把控。当数据不唯一,或存在数据缺失时,需要用户进行特殊的处理来避免数据错误,比如:
关联前,通过SQL对不唯一的数据进行聚合
通过LOD函数指定聚合粒度,避免最终的计算结果错误
通过SQL对缺失数据进行补充,或根据数据缺失情况调整关联方式,避免数据丢失
以上操作都需要一定的SQL处理能力,对于零基础的业务人员来说是比较困难的。并且,在物理建模的过程中,用户需要反复核对结果以保证正确性,非常繁琐和复杂。
由于物理建模的特性,当关联的数据表越多时,越容易出现数据膨胀的问题。而且当建模复杂时,问题的排查和解决也将变得困难。因此,物理建模适用于针对独立的分析场景分别建模,从而尽可能减少关联表的数量。这就导致数据集的数量随着分析场景变多而逐渐堆积,最终难以治理和维护。
关系模型特殊说明
跨表字段的处理
当计算字段表达式中使用了来自多个逻辑表的字段时,将生成跨表字段。跨表字段不属于任何一张逻辑表,在数据集中将单独归类。
跨表字段的计算一定会涉及到多个逻辑表,并且依赖当前逻辑表的关联方式(取决于参与计算的度量、维度)。换句话说,只有在明确的查询场景下才能计算出跨表字段的数据,因此跨表字段无法进行明细的预览。
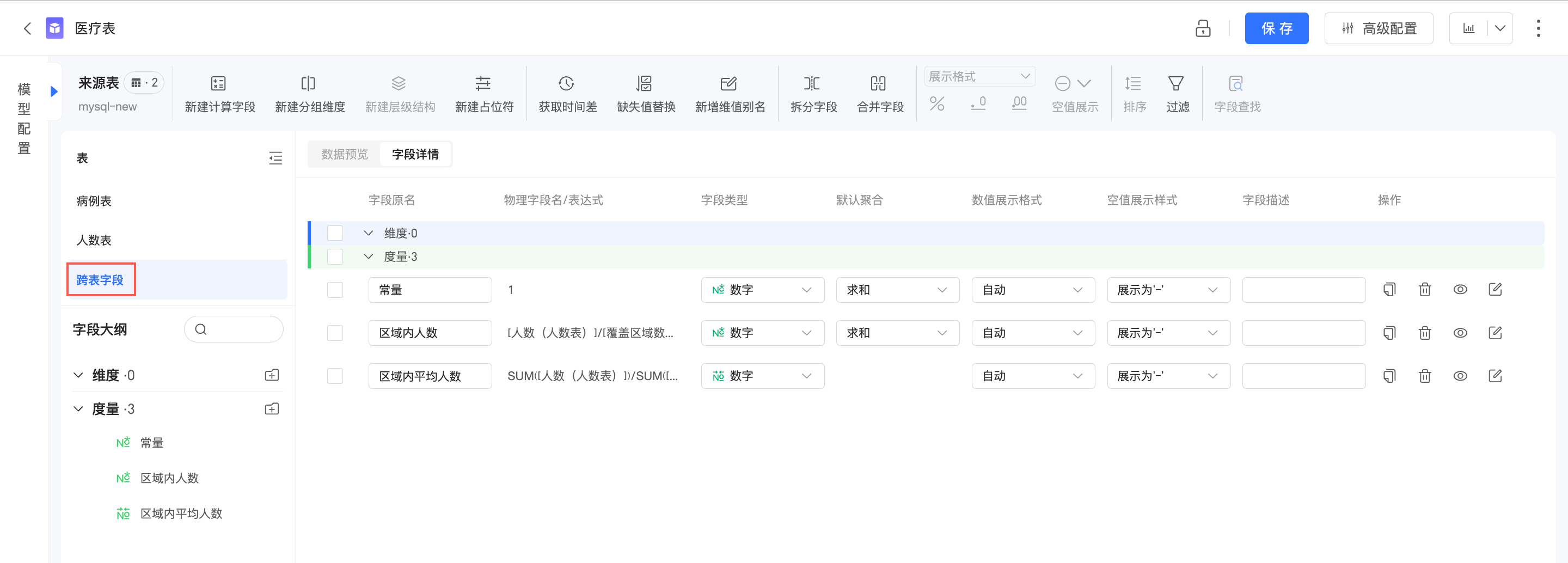
聚合后跨表
当单表的字段分别聚合后再进行跨表的加减乘除计算时,该计算字段为聚合后的跨表计算字段。
例如:
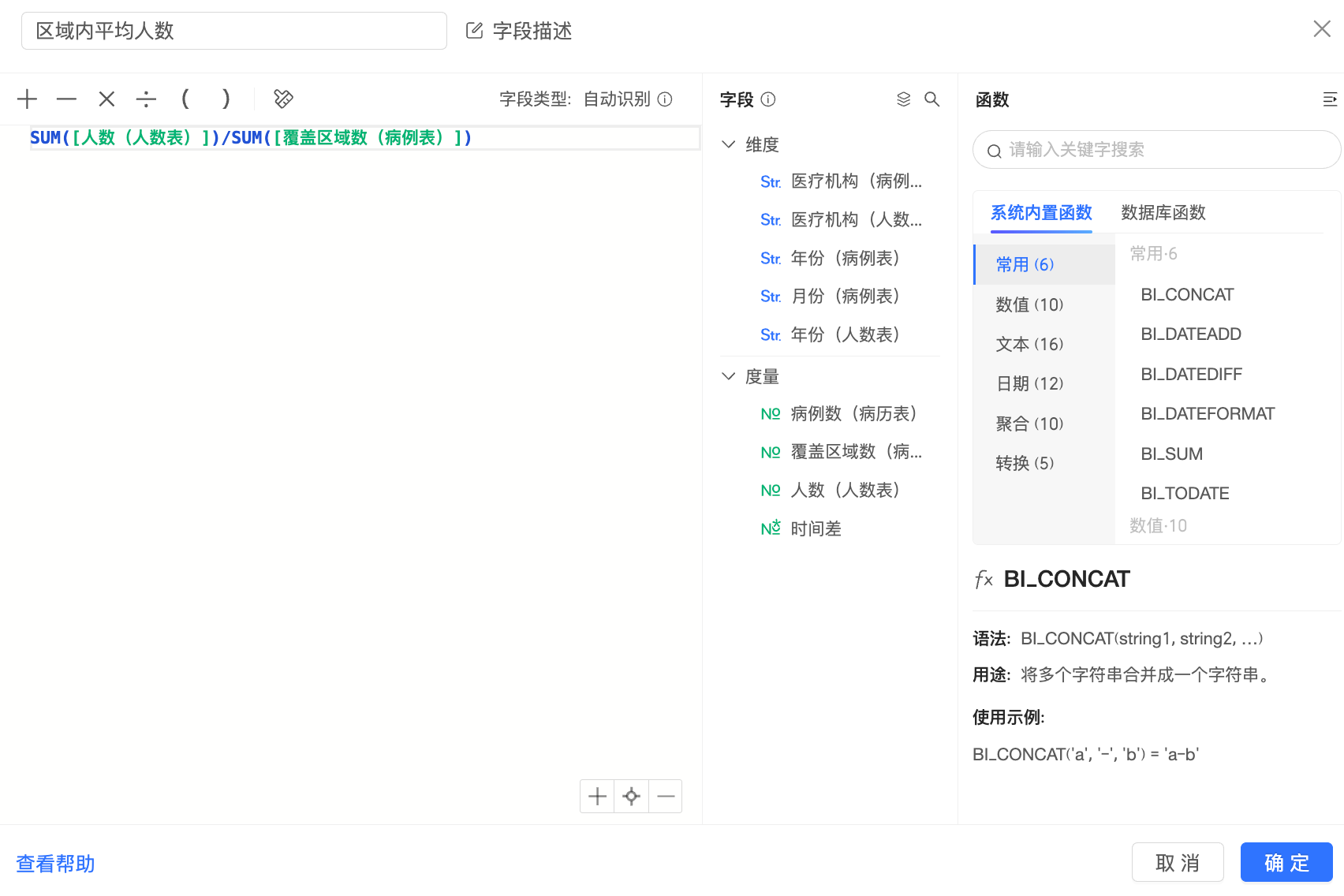
该字段在计算时,Quick BI将分别在人数表中计算出SUM([人数(人数表)]),在病例表中计算出SUM([覆盖区域数(病例表)]),得到2份中间表如下:
医疗机构(病例表) | SUM(人数(人数表)) |
A | 210 |
B | 155 |
C | 160 |
- | 120 |
医疗机构(病例表) | SUM(覆盖区域数(病例表)) |
A | 3 |
B | 2 |
C | 4 |
D | 1 |
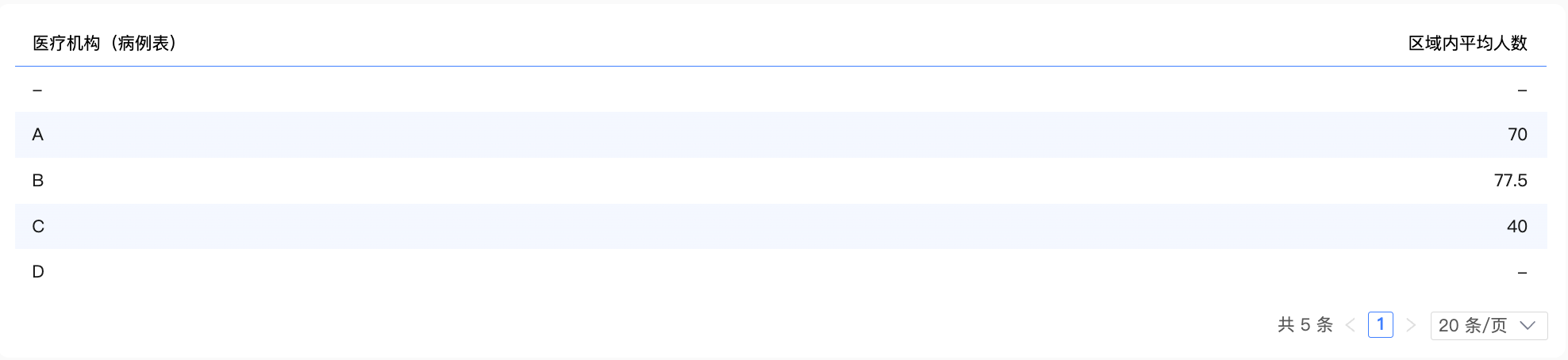
之后,将2份中间表进行关联,并进行除法计算求出最终结果。
明细跨表
当单表的字段直接在明细层进行跨表的加减乘除计算时,该计算字段为明细的跨表计算字段。
例如:
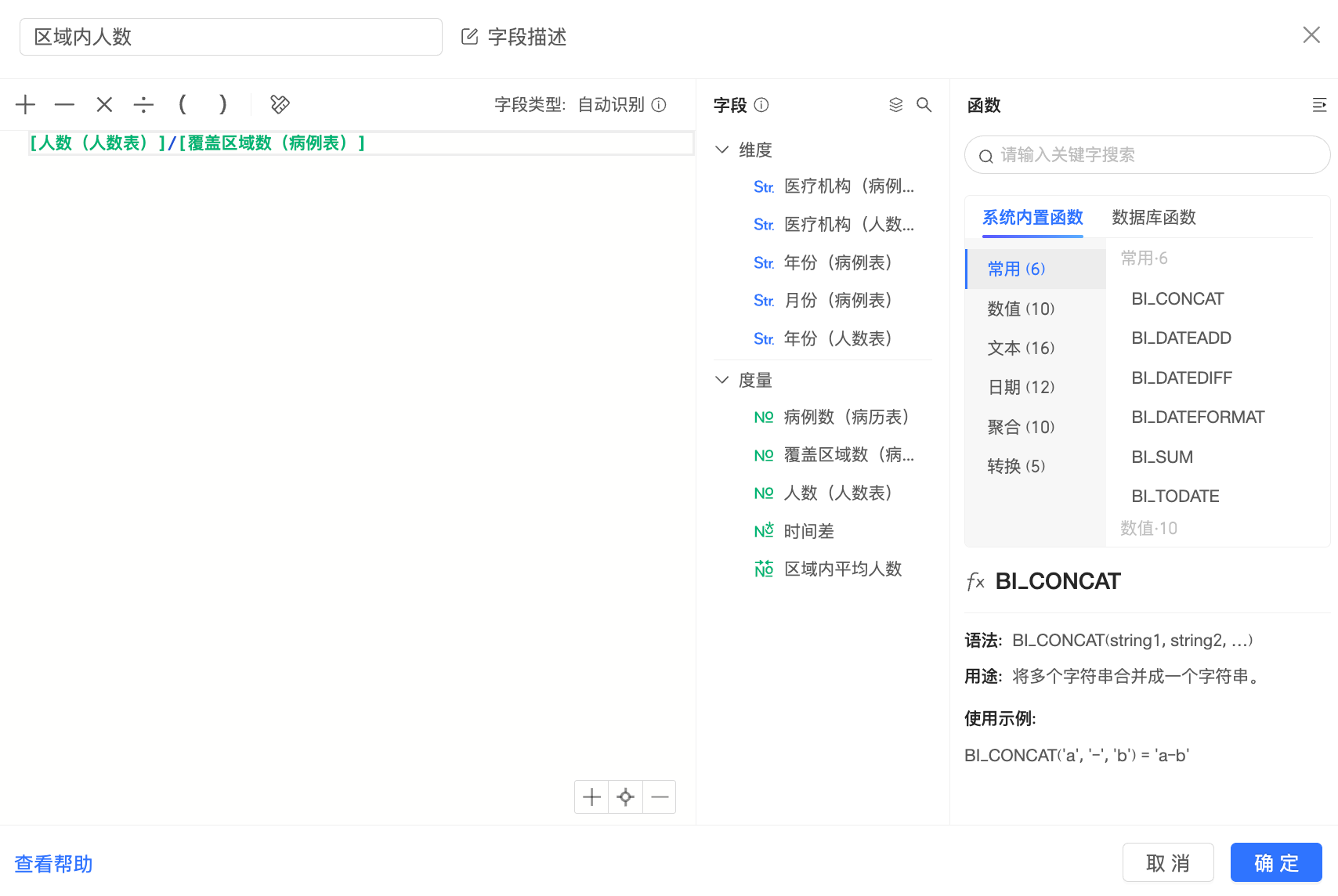
该字段在计算时,Quick BI会先将“病例表”和“人数表”根据关联键进行关联,得到中间表:
医疗机构(病例表) | 覆盖区域数(病例表) | 医疗机构(人数表) | 人数(人数表) |
A | 1 | A | 110 |
A | 1 | A | 100 |
B | 1 | B | 75 |
B | 1 | B | 80 |
C | 2 | C | 90 |
C | 2 | C | 70 |
A | 1 | A | 110 |
A | 1 | A | 100 |
B | 1 | B | 75 |
B | 1 | B | 80 |
C | 2 | C | 90 |
C | 2 | C | 70 |
A | 1 | A | 110 |
A | 1 | A | 100 |
在该中间表的基础上,计算除法,之后根据图表中的维度进行聚合,得到最终结果:

常量的处理
在关系模型中,常量(纯文本、纯数字等)将被处理为跨表字段,但计算方式与跨表字段也有所不同。
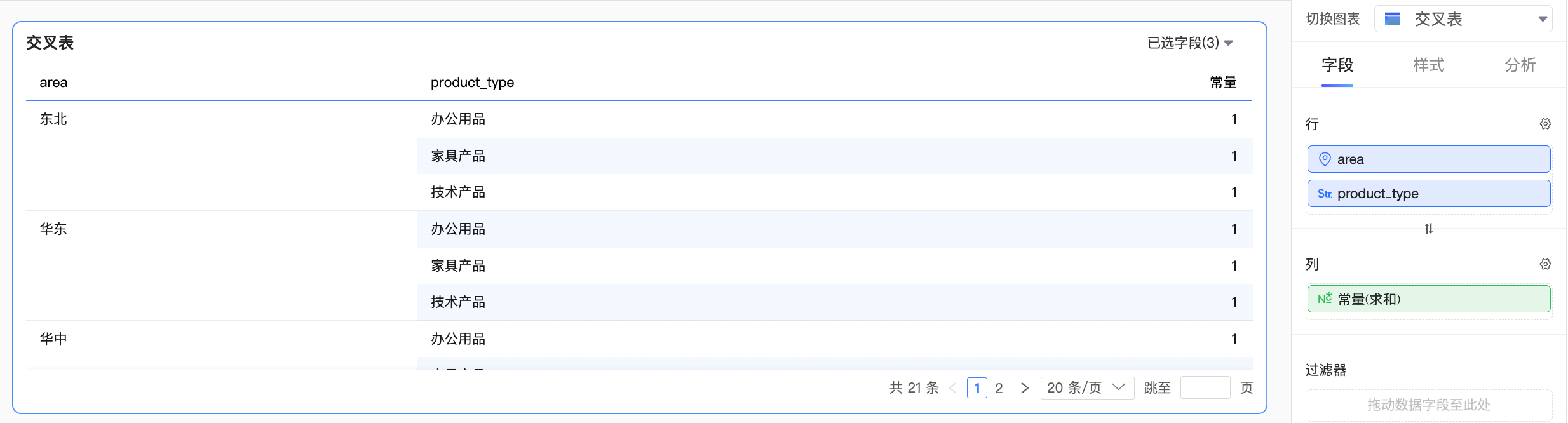
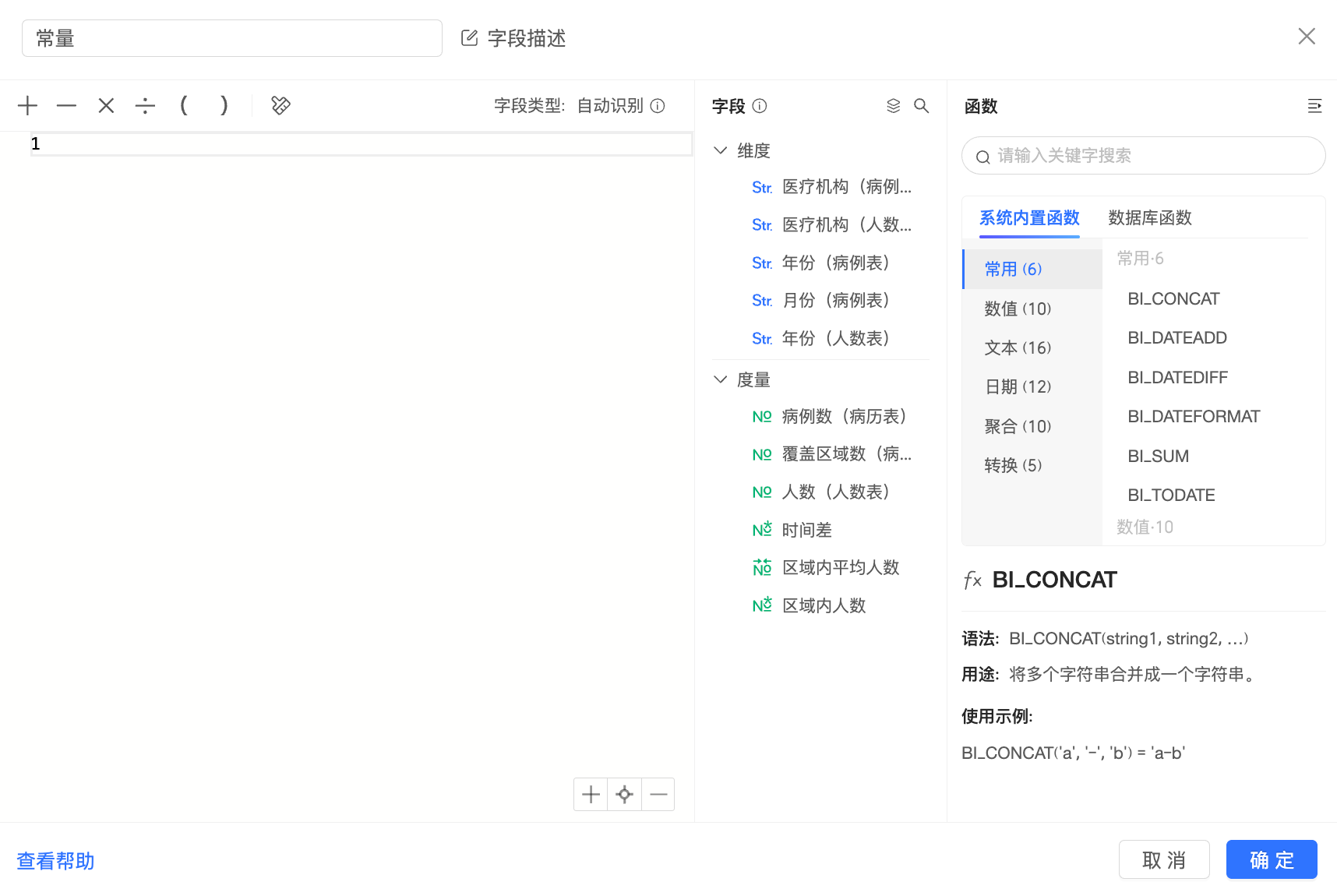
比如:在关系模型数据集中创建常量“1”,该字段将落入“跨表字段”中:
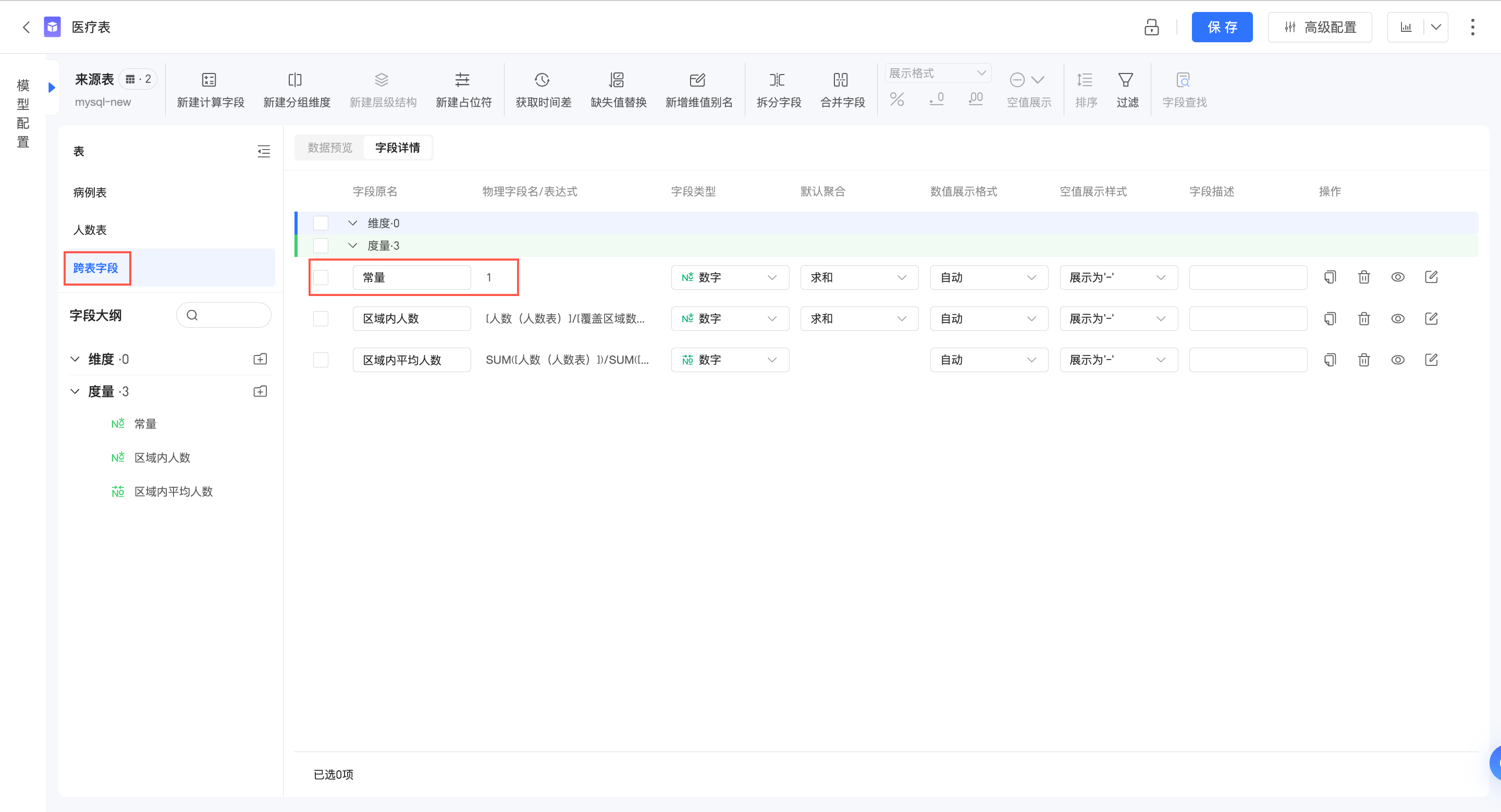
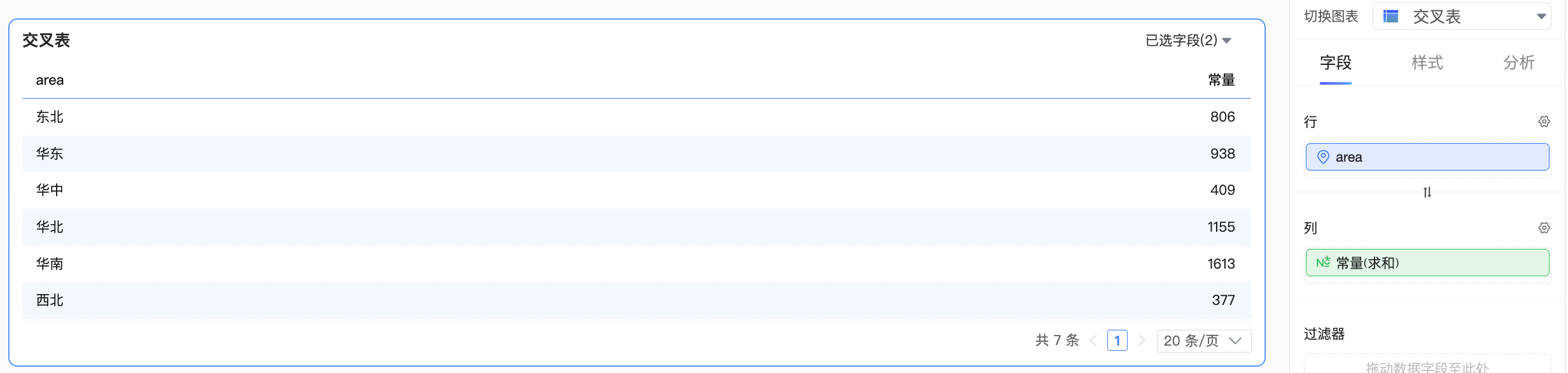
当常量与某一个逻辑表的字段组合计算
此时,Quick BI将把常量处理为单表内的字段,整体的计算按照单表查询进行处理,效果如下:
当常量与多个逻辑表的字段组合计算
此时,该如何对常量进行处理会变得不明确。若将常量作为其中某一个表内的字段去计算,那么该归属于哪张表呢?常量归属于不同表时,计算的结果也会有所不同,这不一定符合用户预期。
因此,在这种场景下,Quick BI将会把常量当作跨表字段去处理。而此时,常量与所有表中的维度都失去了关联性,因此不会参与到聚合计算中,效果如下: