
性能洞察是一项专注于用户数据库实例性能调优、负载监控和关联分析的重要工具。它能帮助用户直观地评估数据库负载、识别资源等待的源头及相关SQL查询语句,从而实现精准的性能优化。
功能简介
性能洞察能够帮助您快速、方便且直接地识别数据库实例的负载,以及导致性能问题的SQL语句。主要包含以下功能:
关键性能指标趋势图:内存/CPU使用率、会话连接、TPS和IOPS的变化趋势图。
平均活跃会话(AAS,Average Active Sessions):实时追踪实例负载,清晰展示负载来源。
多维负载信息:从SQL、用户(User)、数据库(Databases)、等待事件(Waits)、客户端主机(Hosts)、应用(Applications)和会话类别(Session Type)等维度展示实例负载信息。
适用范围
适用于满足以下条件的RDS PostgreSQL实例:
数据库大版本:RDS PostgreSQL13及以上。
产品系列:高可用系列、集群系列。
内核小版本:20240530及以上。
开启性能洞察
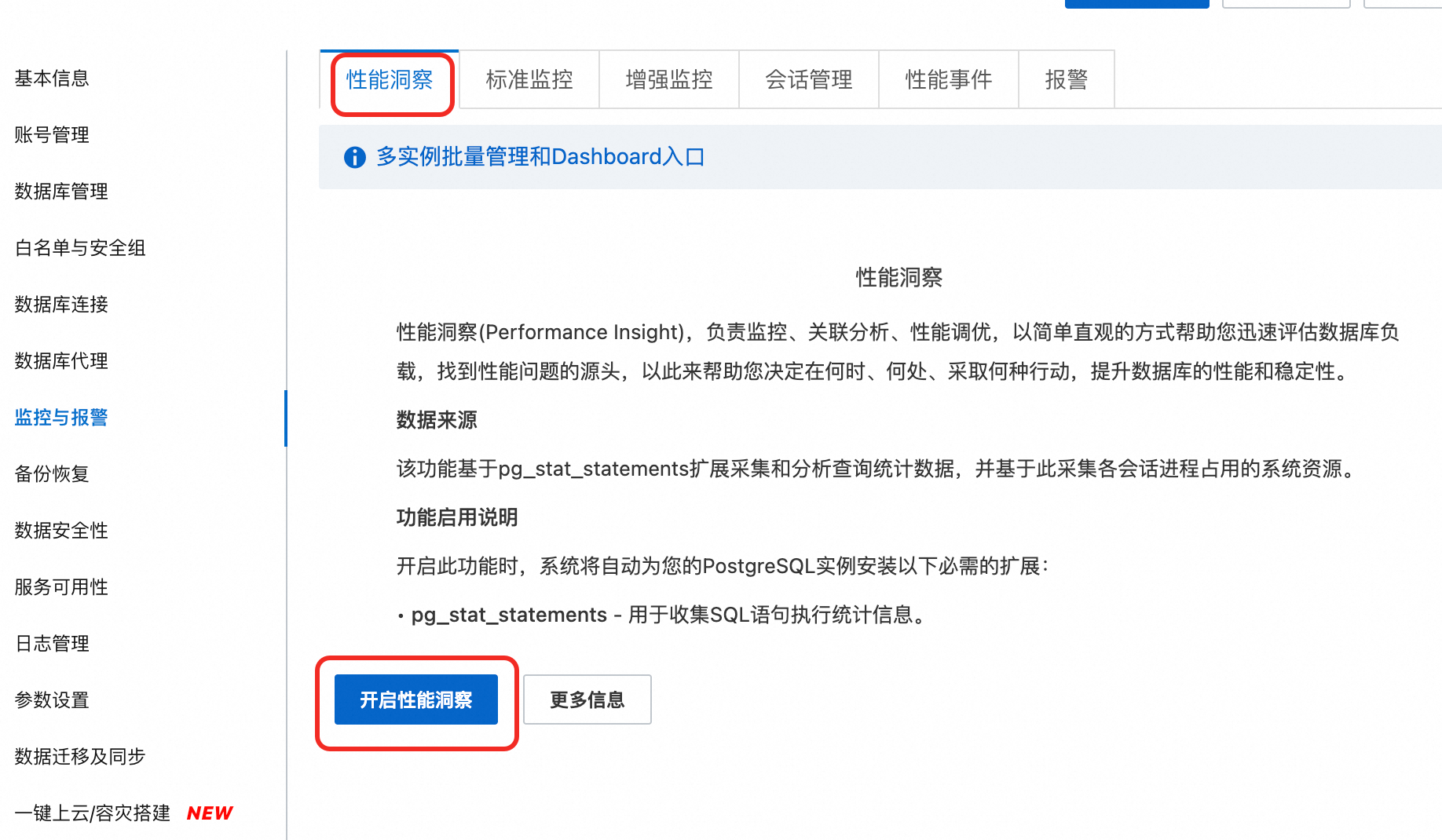
访问RDS实例列表,在上方选择地域,然后单击目标实例ID。
在左侧导航栏中,选择监控与报警。在性能洞察页签。
单击开启性能洞察按钮,在弹出的对话框中单击确定开启功能。
 说明
说明如果您不再使用性能洞察功能,可以单击性能洞察页面的关闭性能洞察,关闭此功能。
开启后,等待片刻,性能洞察页面将开始展示数据。
使用性能洞察进行分析
功能开启后,可遵循以下步骤对数据库实例性能进行分析。
步骤一:定位异常时间段
目前性能洞察处于免费公测期,数据保留7天。正式版支持按需延长数据保留时长,收费将提前通知。
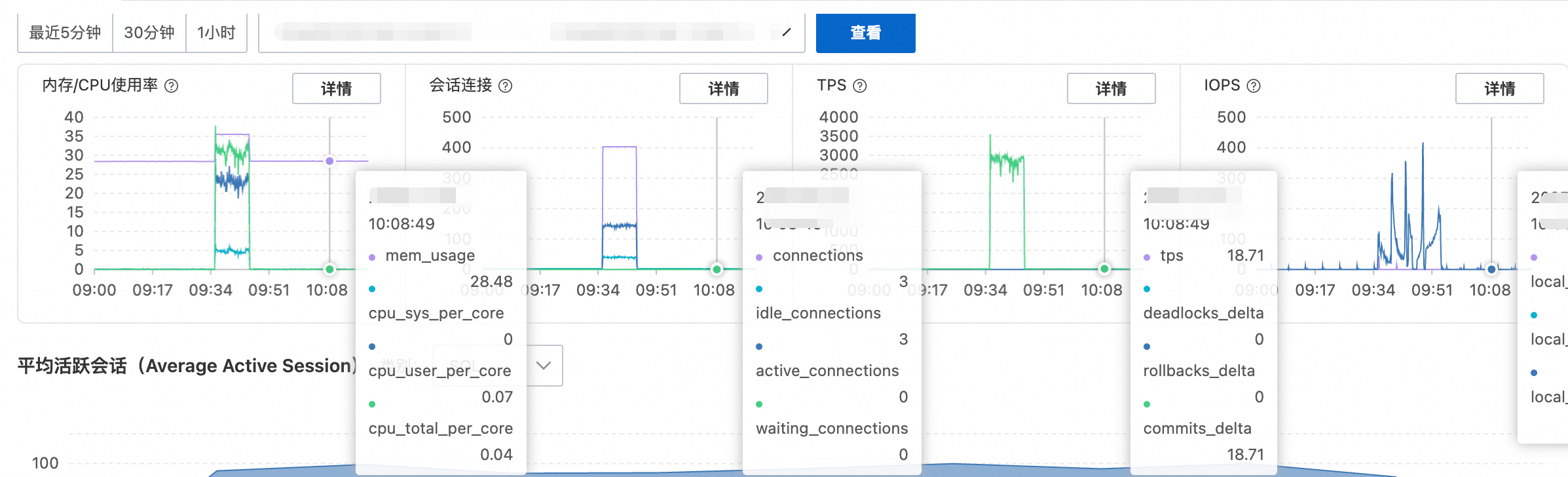
在页面顶部选择时间范围,通过观察关键性能指标趋势图的异常波动,快速锁定问题发生的时间点。
重点关注:内存/CPU 使用率、会话连接数、TPS和IOPS的突发尖峰或急剧下跌。关于关键指标的详细解读,请参考附录:关键性能指标解读。
推荐操作:将鼠标悬停在任意趋势图上某一时间点,可放大该时间点进行更细粒度的分析。
步骤二:识别性能瓶颈
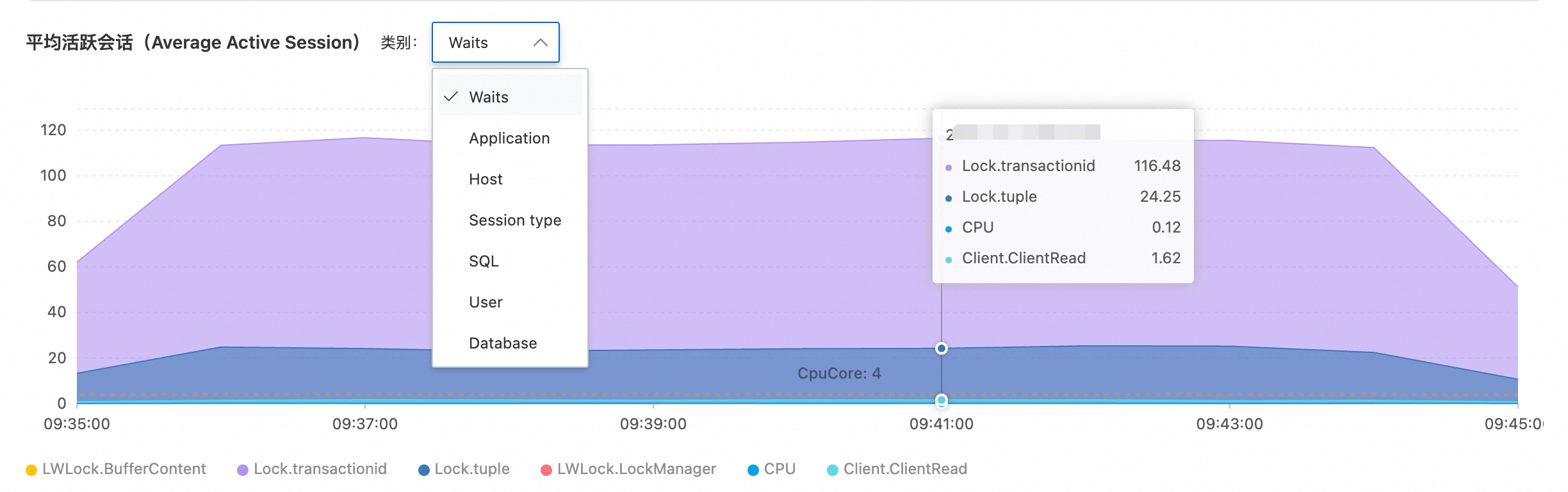
锁定异常时间段后,核心是分析平均活跃会话(AAS)图表。它将数据库负载按不同维度(如等待事件、SQL、来源主机等)进行可视化拆分,帮助您精确识别性能瓶颈的类型。关于AAS图表及各分析维度的详细解读,请参见附录:理解AAS(平均活跃会话)图表和附录:多维分析列表说明。
推荐诊断流程:
在AAS图表右侧的类别下拉框中,首先选择 Waits(等待事件)维度。
观察图表中颜色占比最高的区域,判断核心瓶颈类型:
Lock.tuple:行级锁争用,通常由并发更新/删除同一行数据引起。
LWLock.LockManager:轻量级锁争用,通常与高并发下的内部数据结构访问有关。
Client.ClientRead:客户端读取缓慢,可能是网络延迟或客户端处理慢。
CPU:CPU消耗过高,瓶颈在于计算资源。
LWLockBuffContent:内存页面锁争用,通常由热点数据页的高并发访问引起。
步骤三:追溯问题源头
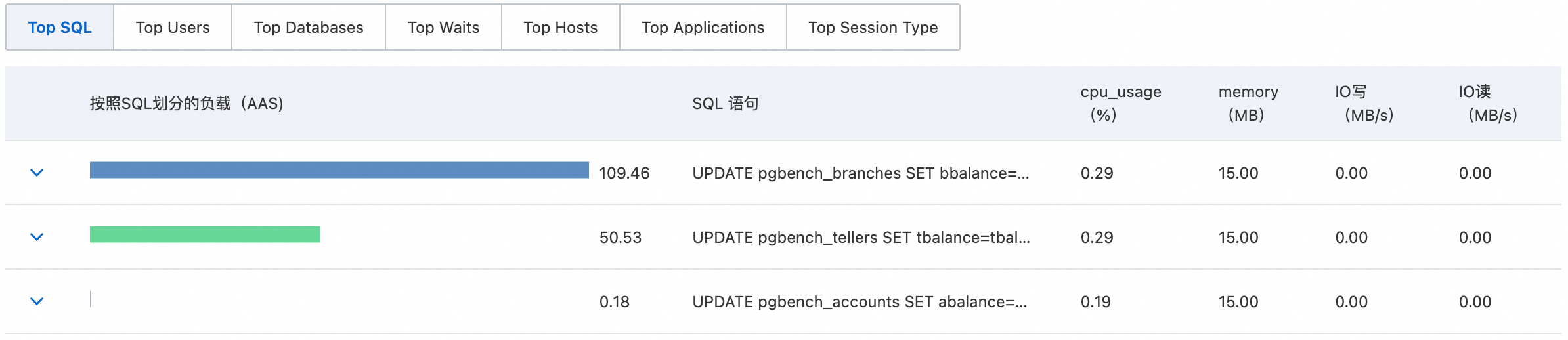
确定瓶颈类型后,利用页面下方的Top N列表,精确定位导致问题的具体来源。
推荐追溯流程:
切换至Top SQL列表,找到“按照SQL划分的负载(AAS)”最高的SQL语句。
切换至Top Users和Top Hosts列表,确认执行该SQL的数据库用户和客户端IP。
(可选)切换至Top Waits列表,交叉验证步骤二识别的瓶颈类型是否吻合。
通过以上三步,即可完成一次从全局到局部的系统性性能诊断,为优化提供精确指引。
故障诊断案例:慢SQL突增导致的锁争用问题
故障现象
监控显示从某时刻开始,慢SQL数量急剧上升,应用响应时间显著恶化。
数据库实例配置
数据库类型:PostgreSQL17.0。
实例规格:独享规格。
规格代码:pg.x2.2xlarge.2c。
CPU:16 核。
内存:32G。
诊断分析
步骤1:性能指标趋势分析
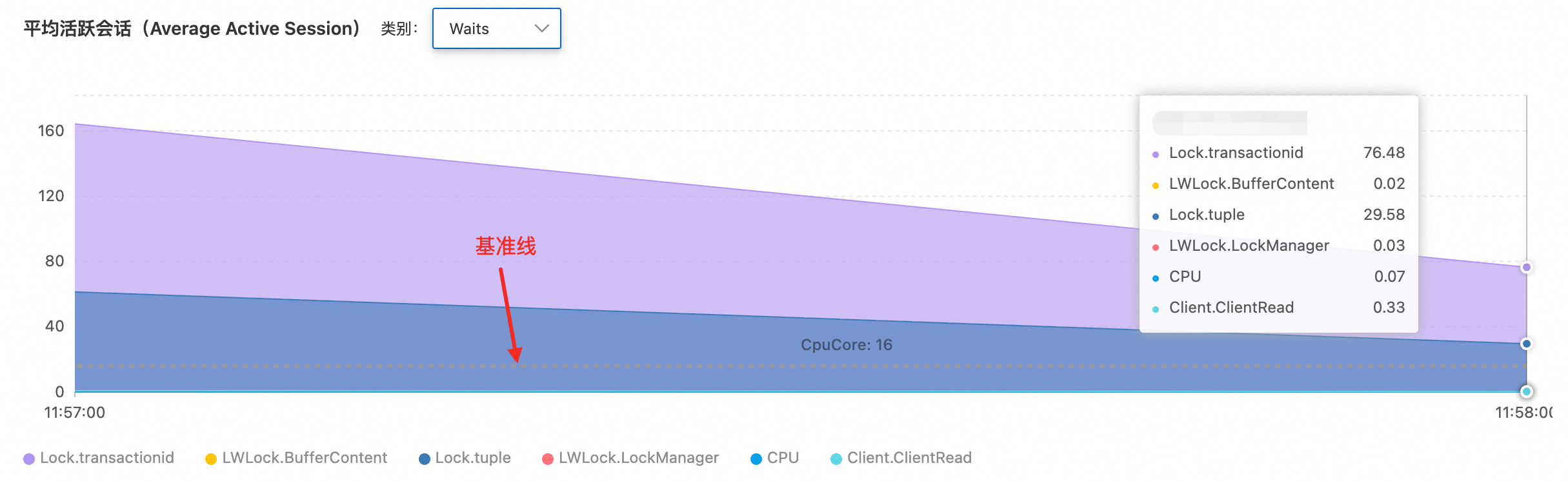
检查关键性能指标趋势图,发现00:34时刻活跃会话数从正常的十几个大幅上升至1100+,超过PostgreSQL实例的合理并发处理能力。
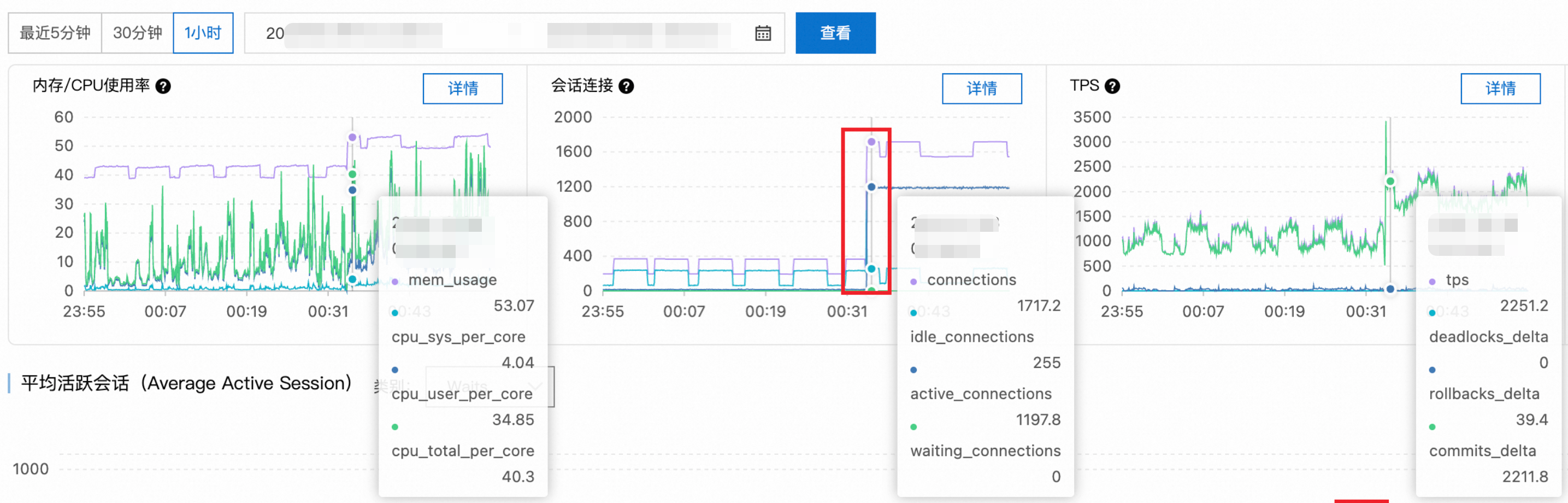
步骤2:等待事件分析
通过平均活跃会话(AAS)图表的等待事件分布,识别出主要瓶颈集中在:
Lock/transactionid:事务ID锁等待,通常由长事务或死锁引起。Lock/tuple:行级锁等待,表明存在严重的并发写入冲突。
活跃会话数远超16核CPU处理的基准线数值,确认系统处于严重的锁争用状态。
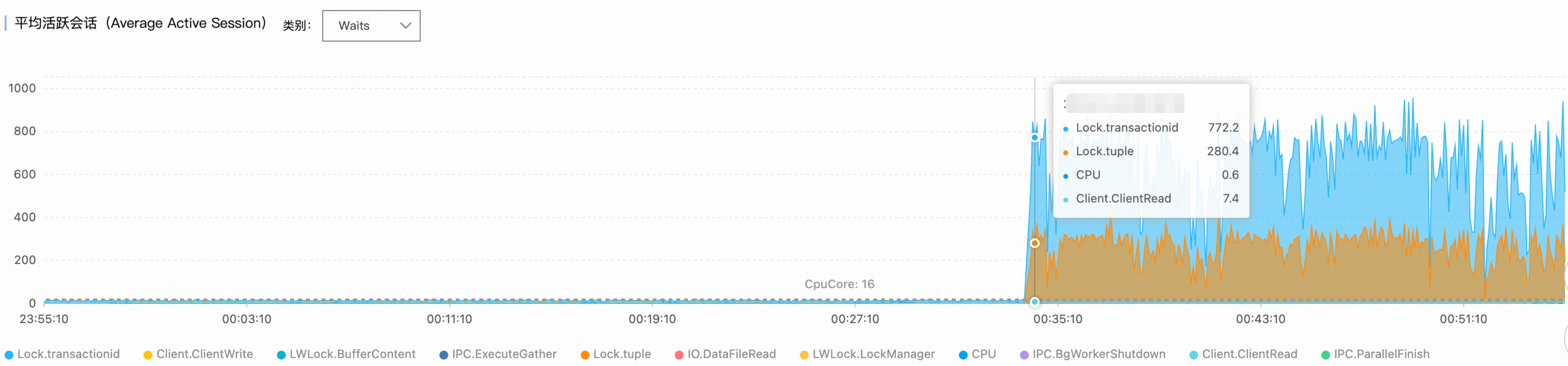
步骤3:SQL语句分析
Top SQL排行显示,前两个查询分别有220和119个会话在等待锁资源释放,这些SQL成为整个锁等待链的关键节点。
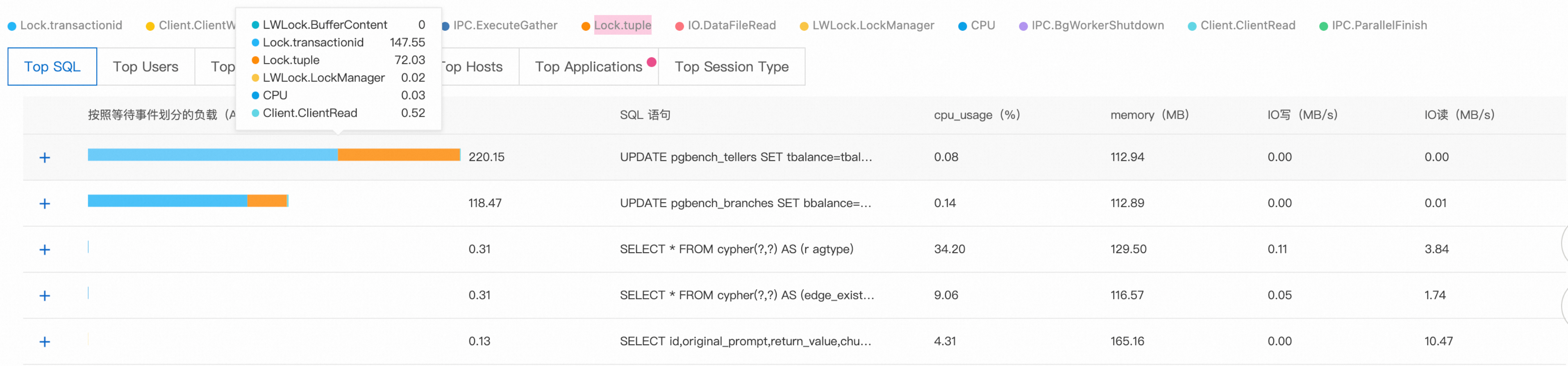
步骤4:来源追溯
结合Top Hosts和Top Databases数据,锁定问题源头:
异常客户端:
140.205.XXX.XXX目标数据库:
perf_test
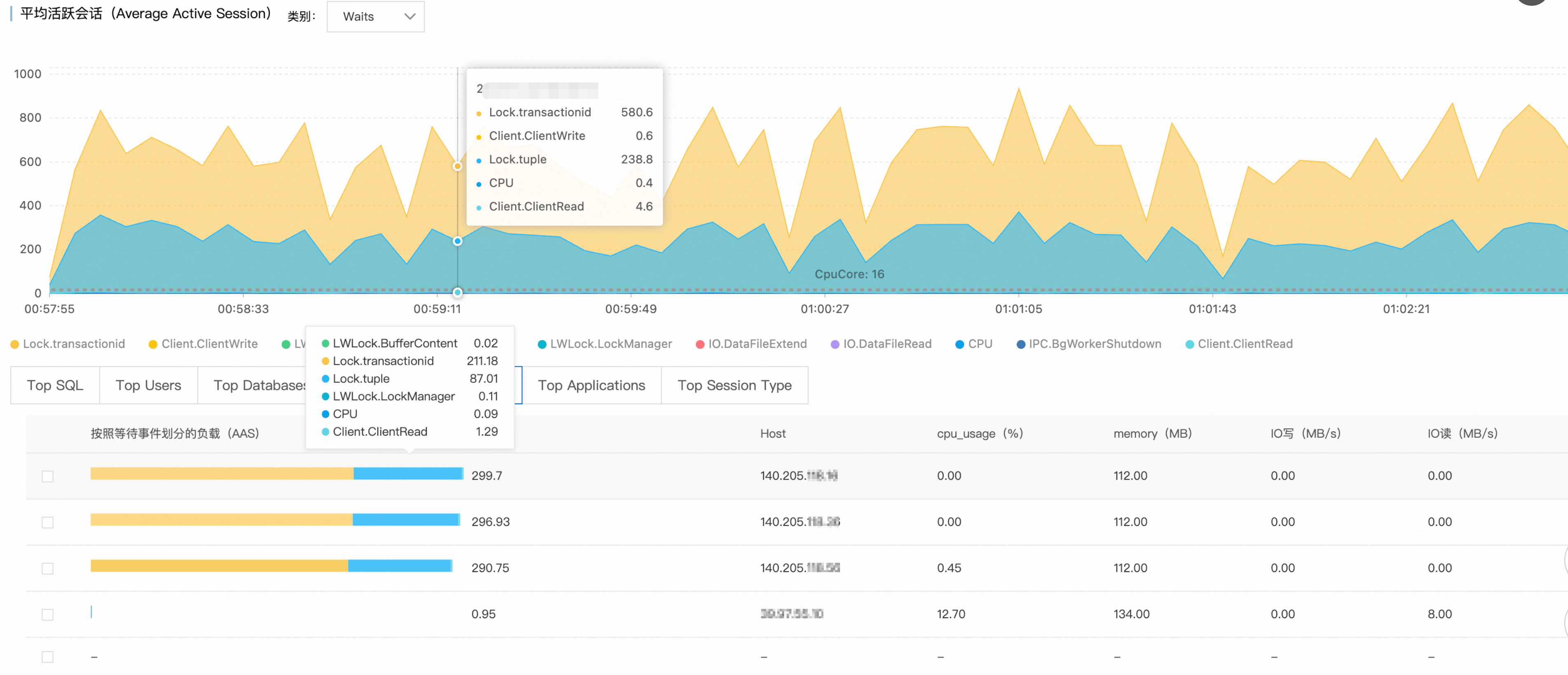
根因分析
故障类型:锁争用雪崩
技术原理:
触发原因:客户端对
perf_test数据库发起高并发DML操作,可能涉及热点行更新或大事务处理。失控机制:PostgreSQL的锁管理机制中,当多个事务竞争相同资源时,后续事务将进入等待队列。由于缺乏连接数限制和锁等待超时控制,新连接持续涌入,形成锁等待的恶性循环。
解决方案
即时措施
限制异常客户端IP的连接数
ALTER ROLE target_user CONNECTION LIMIT 10; -- target_user:数据库用户名终止长时间等待的会话
-- 先查看要终止的会话详情 SELECT pid, -- 进程ID(会话标识) usename, -- 数据库用户名 state, -- 会话状态(active/idle等) wait_event, -- 等待事件具体类型 now() - query_start AS query_duration, -- 当前查询已执行时长 left(query, 50) AS query_preview -- SQL语句预览(前50字符) FROM pg_stat_activity WHERE datname = 'perf_test' -- 限定数据库名称 AND client_addr = '140.205.XXX.XXX' -- 限定客户端IP地址 AND state = 'active' -- 仅查询活跃状态的会话 AND wait_event_type = 'Lock' -- 仅查询正在等待锁的会话 AND pid <> pg_backend_pid() -- 排除当前执行此查询的会话(避免自杀) AND now() - query_start > interval '5 minutes'; -- 查询执行时长超过5分钟 -- pg_terminate_backend会立即终止目标会话,可能导致事务回滚。 -- 在生产环境中执行前,请务必确认目标会话可以被安全终止。 SELECT pg_terminate_backend(pid) FROM pg_stat_activity WHERE datname = 'perf_test' AND client_addr = '140.205.XXX.XXX' AND state = 'active' AND wait_event_type = 'Lock' AND pid <> pg_backend_pid() AND now() - query_start > interval '5 minutes'; -- 确认目标会话是否已清理 SELECT pid, usename, state, query FROM pg_stat_activity WHERE datname = 'perf_test' AND client_addr = '140.205.XXX.XXX';
长期优化
连接池配置:部署PgBouncer等连接池,控制最大并发连接数。
超时参数调优
-- 设置锁等待超时 ALTER DATABASE perf_test SET lock_timeout = '30s'; -- 设置语句执行超时 ALTER DATABASE perf_test SET statement_timeout = '60s';应用层优化:
减小事务粒度,避免长事务。
使用乐观锁或分布式锁机制处理热点数据。
实施读写分离,将只读查询分流至从库。
监控告警:配置活跃连接数和锁等待时间的监控阈值,实现故障预警。
通过这种系统性的诊断方法,可以快速定位PostgreSQL性能问题的根本原因,并制定针对性的解决方案。
附录:核心概念解析
1. 关键性能指标解读
内存/CPU 使用率
指标含义:反映数据库实例物理资源的消耗情况,是判断负载压力和资源瓶颈最直接的依据。
诊断关注点:
持续高位:如果指标长时间(如数分钟或数小时)处于80%以上的高水平,可能情况:
资源瓶颈:实例规格已无法满足当前业务负载,可能需要升级。
低效SQL:存在大量进行全表扫描、复杂计算或未使用索引的查询,持续消耗CPU和内存资源。需要结合Top SQL列表进行分析。
突然尖峰:指标在短时间内急剧上升,可能情况:
“坏”SQL上线:新发布的应用版本中包含了资源消耗极大的SQL。
缓存雪崩:应用层缓存(如Redis)失效,导致海量请求直接穿透到数据库。
后台任务:数据库正在执行计划外的批量处理、数据迁移或复杂的报表生成任务。
会话连接数
指标含义:显示当前与数据库建立的连接总数,包括活跃(active)、空闲(idle)和等待(waiting)状态的连接。
诊断关注点:
持续高位:连接数居高不下,接近或达到实例规格上限,表明连接管理可能存在问题:
连接池配置不当:应用端的连接池最大连接数设置过高或未设置,或最小空闲连接数不合理。
连接泄漏:应用程序在完成数据库操作后,未能正确关闭和释放连接。
长事务阻塞:存在大量处于idle in transaction状态的会话,这些会话占用了连接却不执行任何操作,通常由应用逻辑缺陷导致。
突然飙升:通常与TPS下跌和CPU/IOPS上升同时发生,可能情况:
数据库响应缓慢:由于锁等待或资源耗尽,SQL执行时间变长,导致新的连接请求大量积压。
应用瞬间重启:应用集群重启后,所有实例同时尝试建立新的数据库连接,造成连接风暴。
TPS (每秒事务数)
指标含义:衡量数据库吞吐量的核心指标,反映了数据库每秒成功提交和回滚的事务总数。
诊断关注点:
突然暴跌:TPS曲线断崖式下跌,而业务请求量未变,可能情况:
系统性阻塞:数据库内部出现严重的锁等待、死锁,或单个大事务阻塞了大量其他事务。
资源耗尽:CPU或IOPS达到100%饱和,数据库无法处理更多请求。
异常飙升:TPS远超正常业务峰值,可能情况:
无效事务增多:可能存在大量快速失败并回滚的短事务,需检查应用日志确认业务是否正常。
流量攻击:系统可能正在遭受DDoS攻击或恶意的API调用。
IOPS (每秒磁盘读写次数)
指标含义:衡量磁盘子系统繁忙程度的指标。高IOPS意味着数据库正在频繁地从磁盘读取或向磁盘写入数据。
诊断关注点:
持续高位:IOPS长时间接近或达到磁盘性能上限,表明数据访问效率低下:
索引缺失或失效:最常见的原因。查询无法利用索引,被迫进行大规模的全表扫描,导致物理读急剧增加。
内存不足:分配给数据库的内存(特别是缓冲池)过小,导致数据页无法在内存中缓存,需要频繁从磁盘读取。
大字段写入:频繁更新或写入包含TEXT、BLOB等大字段的表。
突然飙升:通常与特定的数据密集型操作相关:
批量数据操作:执行大规模的数据导入、导出或归档。
大表变更:对大表进行TRUNCATE、REINDEX,或执行DDL(如添加列并设置默认值)。
内部机制触发:数据库的自动清理、检查点等后台进程集中运行。
2. 理解AAS(平均活跃会话)图表
平均活跃会话(Average Active Session, AAS) 是性能洞察的核心分析图表,它以堆叠面积图的形式展示了数据库负载的构成。
横轴:时间线(精确到秒级,如13:32:05至13:50:05)。
纵轴:活跃会话数(数值越高,负载越大)。
颜色分层:在不同的维度下,不同颜色代表不同的 item。比如在等待事件维度下,不同颜色表示不同的等待事件类型,在 Host维度下不同的颜色表示不同的客户端。
基准线:图表中标注的"CpuCore: N"表示实例的CPU核心数,当AAS超过此基准线时,表明数据库负载已超出CPU处理能力。

分析维度:不同分析维度及功能说明如下表所示。
分析维度
功能说明
SQL
按SQL语句分类负载(默认视图),识别哪些SQL占用了最多的会话资源。
Waits
按等待事件类型分类(如Lock、IO、LWLock等),是诊断瓶颈类型的关键维度。
Application
按应用程序分类,区分不同应用系统或服务模块对数据库的影响。
Host
按客户端主机IP分类,识别哪些服务器或客户端产生了最高的数据库负载。
Session type
按会话类型分类,判断负载来自业务请求还是数据库内部的维护操作。
User
按数据库用户分类,快速定位是哪个业务账号造成的压力。
3. 多维分析列表说明
位于页面下方的多维分析列表,用于从不同维度排序,展示Top N的负载贡献者。
页签名称 | 作用 |
Top SQL | 定位问题SQL的核心视图。关注“按照SQL划分的负载(AAS)”列,找到值最高的SQL。 |
Top Waits | 按等待事件类型排序负载,用于确认或详细查看各类等待事件的分布。 |
Top Users | 按数据库用户排序负载,定位是哪个应用账号或业务模块造成的压力。 |
Top Hosts | 按客户端IP排序负载,定位是哪台应用服务器或特定IP造成的压力。 |
Top Applications | 按应用名称排序负载,用于区分不同服务对数据库的影响。 |
Top Session Type | 按会话类型排序负载,判断负载来自业务请求还是后台维护任务。 |