
分词器可以将长文档解析、拆分为多个词,存入索引中。在多数场景下,您可以直接使用TairSearch提供的多种内置分词器,同时您也可以按需自定义分词器。本文介绍TairSearch分词器的使用方法。
导航
内置分词器 | Character Filter | Tokenizer | Token Filter |
分词器的工作流程
TairSearch分词器由Character Filter、Tokenizer和Token Filter三部分组成,其工作流程依次为Character Filter、Tokenizer和Token Filter,其中Character Filter和Token Filter可以为空。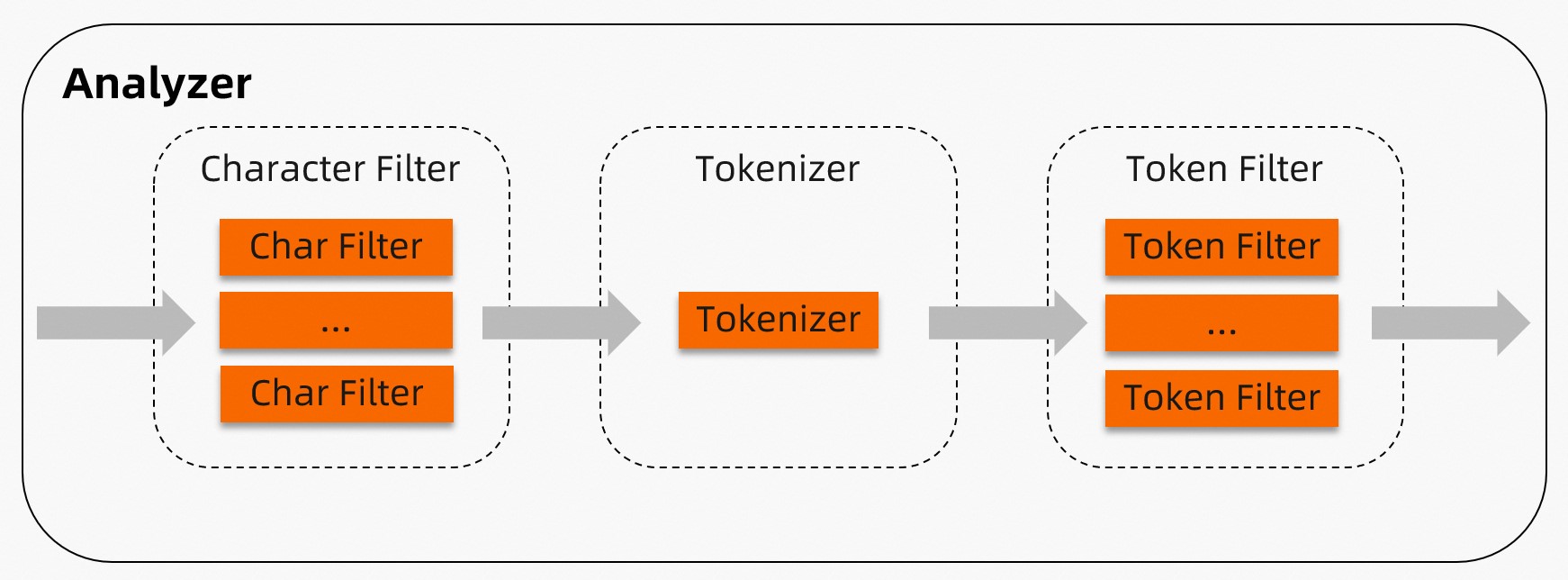 其具体作用如下:
其具体作用如下:
Character Filter:负责将文档进行预处理,每个分词器可以配置零个或者多个Character Filter,多个Character Filter会按照指定顺序执行。例如将
"(:"字符替换成"happy"字符。Tokenizer:负责将输入的文档拆分成多个Token(词元),每个分词器仅能配置一个Tokenizer。例如通过Whitespace Tokenizer将
"I am very happy"拆分成["I", "am", "very", "happy"]。Token Filter:负责对Tokenizer产生的Token进行处理,每个分词器可以配置零个或者多个Token Filter,多个Token Filter会按照指定顺序执行。例如通过Stop Token Filter过滤停用词(Stopwords)。
内置分词器
Standard
基于Unicode文本切割算法拆分文档,并将Token(词元,Tokenizer的结果)转为小写、过滤停用词,适用于多数语言。
组成部分:
Tokenizer(分词器):Standard Tokenizer。
Token Filter(词元过滤器):LowerCase Token Filter和Stop Token Filter。
未展示Character Filter(字符过滤器)表示无Character Filter。
可选参数:
stopwords:停用词,分词器会过滤这些词。数组类型,单个停用词必须是字符串。配置后,会覆盖默认停用词。默认停用词如下:
["a", "an", "and", "are", "as", "at", "be", "but", "by", "for", "if", "in", "into", "is", "it", "no", "not", "of", "on", "or", "such", "that", "the", "their", "then", "there", "these", "they", "this", "to", "was", "will", "with"]max_token_length:每个Token的长度上限,默认为255。若Token超过该长度,会根据指定的长度上限对Token进行拆分。
配置示例:
# 默认配置:
{
"mappings":{
"properties":{
"f0":{
"type":"text",
"analyzer":"standard"
}
}
}
}
# 自定义停用词配置:
{
"mappings":{
"properties":{
"f0":{
"type":"text",
"analyzer":"my_analyzer"
}
}
},
"settings":{
"analysis":{
"analyzer":{
"my_analyzer":{
"type":"standard",
"max_token_length":10,
"stopwords":[
"memory",
"disk",
"is",
"a"
]
}
}
}
}
}Stop
根据非字母(non-letter)的符号拆分文档,并将Token转为小写,同时过滤停用词。
组成部分:
Tokenizer:LowerCase Tokenizer。
Token Filter:Stop Token Filter。
可选参数:
stopwords:停用词,分词器会过滤这些词。数组类型,单个停用词必须是字符串。配置后,会覆盖默认停用词。默认停用词如下:
["a", "an", "and", "are", "as", "at", "be", "but", "by", "for", "if", "in", "into", "is", "it", "no", "not", "of", "on", "or", "such", "that", "the", "their", "then", "there", "these", "they", "this", "to", "was", "will", "with"]
配置示例:
# 默认配置:
{
"mappings":{
"properties":{
"f0":{
"type":"text",
"analyzer":"stop"
}
}
}
}
# 自定义停用词配置:
{
"mappings":{
"properties":{
"f0":{
"type":"text",
"analyzer":"my_analyzer"
}
}
},
"settings":{
"analysis":{
"analyzer":{
"my_analyzer":{
"type":"stop",
"stopwords":[
"memory",
"disk",
"is",
"a"
]
}
}
}
}
}Jieba
推荐的中文分词器,可以按照预先训练好的词典或者指定的词典拆分文档,采用Jieba搜索引擎模式,同时将英文Token转为小写,并过滤停用词。
组成部分:
Tokenizer:Jieba Tokenizer。
Token Filter:LowerCase Token Filter和Stop Token Filter。
可选参数:
userwords:自定义词典,数组类型,单个词必须是字符串。配置后会追加至默认词典中,默认词典请参见Jieba默认词典。
重要为了更好的分词效果,Jieba内置了一个较大的词典,约占用20 MB内存,该词典在内存中仅会保留一份。在首次使用Jieba时才会加载词典,这可能会导致首次使用Jieba分词器时延时出现微小的抖动。
自定义词典的单词中不能出现空格与特殊字符:
\t、\n、,和。。
use_hmm:对于字典中不存在的词,是否使用隐式马尔科夫链模型判断成词,取值为true(默认,表示开启)或false(不开启)。
stopwords:停用词,分词器会过滤这些词。数组类型,单个停用词必须是字符串。配置后,会覆盖默认停用词。默认停用词请参见Jieba默认停用词。
配置示例:
# 默认配置:
{
"mappings":{
"properties":{
"f0":{
"type":"text",
"analyzer":"jieba"
}
}
}
}
# 自定义停用词配置:
{
"mappings":{
"properties":{
"f0":{
"type":"text",
"analyzer":"my_analyzer"
}
}
},
"settings":{
"analysis":{
"analyzer":{
"my_analyzer":{
"type":"jieba",
"stopwords":[
"memory",
"disk",
"is",
"a"
],"userwords":[
"Redis",
"开源免费",
"灵活"
],
"use_hmm":true
}
}
}
}
}IK
中文分词器,兼容ES的IK分词器插件。分为ik_max_word和ik_smart模式,ik_max_word模式会拆分出文档中所有可能存在的Token,ik_smart模式会在ik_max_word的基础上,对Token进行二次识别,选择出最有可能的Token。
以“Redis是完全开源免费的,遵守BSD协议,是一个灵活的高性能key-value数据结构存储,可以用来作为数据库、缓存和消息队列。Redis比其他key-value缓存产品有以下三个特点:Redis支持数据的持久化,可以将内存中的数据保存在磁盘中,重启的时候可以再次加载到内存使用。”文档为例,ik_max_word和ik_smart的Token如下:
ik_max_word:redis 是 完全 全开 开源 免费 的 遵守 bsd 协议 是 一个 一 个 灵活 的 高性能 性能 key-value key value 数据结构 数据 结构 存储 可以用 可以 用来 来作 作为 数据库 数据 库 缓存 和 消息 队列 redis 比 其他 key-value key value 缓存 产品 有 以下 三个 三 个 特点 redis 支持 数据 的 持久 化 可以 将 内存 中 的 数据 保存 存在 磁盘 中 重启 的 时候 可以 再次 加载 载到 内存 使用ik_smart:redis 是 完全 开源 免费 的 遵守 bsd 协议 是 一个 灵活 的 高性能 key-value 数据结构 存储 可以 用来 作为 数据库 缓存 和 消息 队列 redis 比 其他 key-value 缓存 产品 有 以下 三个 特点 redis 支持 数据 的 持久 化 可以 将 内存 中 的 数据 保 存在 磁盘 中 重启 的 时候 可以 再次 加 载到 内存 使用
组成部分:
Tokenizer:IK Tokenizer。
可选参数:
stopwords:停用词,分词器会过滤这些词。数组类型,单个停用词必须是字符串。配置后,会覆盖默认停用词。默认停用词如下:
["a", "an", "and", "are", "as", "at", "be", "but", "by", "for", "if", "in", "into", "is", "it", "no", "not", "of", "on", "or", "such", "that", "the", "their", "then", "there", "these", "they", "this", "to", "was", "will", "with"]userwords:自定义词典,数组类型,单个词必须是字符串,配置后会追加至默认词典中。默认词典请参见IK默认词典。
quantifiers:自定义量词词典,数组类型,单个词必须是字符串,配置后会追加至默认量词词典中。默认量词词典请参见IK默认量词词典。
enable_lowercase:是否将大写字母转换为小写,取值为true(默认,表示开启)或false(不开启)。
重要由于本参数所控制的操作(将大写字母转换为小写)会发生在分词之前,若自定义词典中存在大写字母,请将本参数设置为false。
配置示例:
# 默认配置:
{
"mappings":{
"properties":{
"f0":{
"type":"text",
"analyzer":"ik_smart"
},
"f1":{
"type":"text",
"analyzer":"ik_max_word"
}
}
}
}
# 自定义停用词配置:
{
"mappings":{
"properties":{
"f0":{
"type":"text",
"analyzer":"my_ik_smart_analyzer"
},
"f1":{
"type":"text",
"analyzer":"my_ik_max_word_analyzer"
}
}
},
"settings":{
"analysis":{
"analyzer":{
"my_ik_smart_analyzer":{
"type":"ik_smart",
"stopwords":[
"memory",
"disk",
"is",
"a"
],"userwords":[
"Redis",
"开源免费",
"灵活"
],
"quantifiers":[
"纳秒"
],
"enable_lowercase":false
},
"my_ik_max_word_analyzer":{
"type":"ik_max_word",
"stopwords":[
"memory",
"disk",
"is",
"a"
],"userwords":[
"Redis",
"开源免费",
"灵活"
],
"quantifiers":[
"纳秒"
],
"enable_lowercase":false
}
}
}
}
}Pattern
根据指定的正则表达式拆分文档,正则表达式匹配的词将作为分隔符。例如指定的正则表达式是"aaa",对"bbbaaaccc"文档进行分词,会得到"bbb"和"ccc",同时根据lowercase参数决定是否将英文Token转为小写,并过滤停用词。
组成部分:
Tokenizer:Pattern Tokenizer。
Token Filter:LowerCase Token Filter和Stop Token Filter。
可选参数:
pattern:正则表达式,正则表达式匹配的词将作为分隔符,默认为
\W+,更多语法信息请参见Re2。stopwords:停用词,分词器会过滤这些词。配置时,停用词词典必须是一个数组,每个停用词必须是字符串,配置停用词后会覆盖默认停用词。默认停用词如下:
["a", "an", "and", "are", "as", "at", "be", "but", "by", "for", "if", "in", "into", "is", "it", "no", "not", "of", "on", "or", "such", "that", "the", "their", "then", "there", "these", "they", "this", "to", "was", "will", "with"]lowercase:是否将Token转换为小写,取值为true(默认,表示开启)或false(不开启)。
flags:正则表达式是否大小写敏感,默认为空(表示大小写敏感),取值为CASE_INSENSITIVE(表示大小写不敏感)。
配置示例:
# 默认配置:
{
"mappings":{
"properties":{
"f0":{
"type":"text",
"analyzer":"pattern"
}
}
}
}
# 自定义停用词配置:
{
"mappings":{
"properties":{
"f0":{
"type":"text",
"analyzer":"my_analyzer"
}
}
},
"settings":{
"analysis":{
"analyzer":{
"my_analyzer":{
"type":"pattern",
"pattern":"\\'([^\\']+)\\'",
"stopwords":[
"aaa",
"@"
],
"lowercase":false,
"flags":"CASE_INSENSITIVE"
}
}
}
}
}Whitespace
根据空格拆分文档。
组成部分:
Tokenizer:Whitespace Tokenizer。
可选参数:无
配置示例:
# 默认配置:
{
"mappings":{
"properties":{
"f0":{
"type":"text",
"analyzer":"whitespace"
}
}
}
}Simple
根据非字母(non-letter)的符号拆分文档,将Token转为小写。
组成部分:
Tokenizer:LowerCase Tokenizer。
可选参数:无
配置示例:
# 默认配置:
{
"mappings":{
"properties":{
"f0":{
"type":"text",
"analyzer":"simple"
}
}
}
}Keyword
不拆分文档,将文档作为一个Token输出。
组成部分:
Tokenizer:Keyword Tokenizer。
可选参数:无
配置示例:
# 默认配置:
{
"mappings":{
"properties":{
"f0":{
"type":"text",
"analyzer":"keyword"
}
}
}
}Language
支持多国语言分词器,包括:chinese、arabic、cjk、brazilian、czech、german、greek、persian、french、dutch和russian。
可选参数:
stopwords:停用词,分词器会过滤这些词。配置时,停用词词典必须是一个数组,每个停用词必须是字符串,配置停用词后会覆盖默认停用词。各语言的默认停用词请参见附录4:内置分词器Language各语言的默认停用词(Stopwords)。
说明暂不支持修改chinese分词器的停用词。
stem_exclusion:指定不需要进行词干化处理的词(Term),例如
"apples"进行词干化处理后为"apple"。本参数默认为空,配置时,stem_exclusion必须是一个数组,每个词必须是字符串。说明仅brazilian、german、french和dutch分词器支持本参数。
配置示例:
# 默认配置:
{
"mappings":{
"properties":{
"f0":{
"type":"text",
"analyzer":"arabic"
}
}
}
}
# 自定义停用词配置:
{
"mappings":{
"properties":{
"f0":{
"type":"text",
"analyzer":"my_analyzer"
}
}
},
"settings":{
"analysis":{
"analyzer":{
"my_analyzer":{
"type":"german",
"stopwords":[
"ein"
],
"stem_exclusion":[
"speicher"
]
}
}
}
}
}自定义分词器
TairSearch分词器的工作流程依次为Character Filter、Tokenizer和Token Filter,您可以按需配置Character Filter、Tokenizer和Token Filter参数。
配置方法:在properties中配置analyzer为自定义分词器,例如my_custom_analyzer,在settings中,指定自定义分词器(my_custom_analyzer)的相关配置。
参数说明:
参数 | 说明 |
type(必选) | 固定为custom,表示自定义分词器。 |
char_filter(可选) | 字符过滤器,在开始Tokenizer流程前,对文档进行预处理,默认为空,表示不进行预处理,当前仅支持Mapping。 参数说明:
|
tokenizer(必选) | 分词器,必选且只能选择一个,取值为:whitespace、lowercase、standard、classic、letter、keyword、jieba、pattern、ik_max_word和ik_smart,更多信息请参见附录2:支持的Tokenizer。 |
filter(可选) | 词元过滤器,对Token(Tokenizer的结果)进行处理,例如删除停用词、将词元转换为小写等,支持多选,默认为空,表示不进行处理。 取值为:classic、elision、lowercase、snowball、stop、asciifolding、length、arabic_normalization和persian_normalization,更多信息请参见附录3:支持的Token Filter。 |
配置示例:
# 自定义分词器配置:
# 本示例配置了名为emoticons和conjunctions的Character Filter,同时配置了Whitespace Tokenizer以及Lowercase Token Filter和Stop Token Filter。
{
"mappings":{
"properties":{
"f0":{
"type":"text",
"analyzer":"my_custom_analyzer"
}
}
},
"settings":{
"analysis":{
"analyzer":{
"my_custom_analyzer":{
"type":"custom",
"tokenizer":"whitespace",
"filter":[
"lowercase",
"stop"
],
"char_filter": [
"emoticons",
"conjunctions"
]
}
},
"char_filter":{
"emoticons":{
"type":"mapping",
"mappings":[
":) => _happy_",
":( => _sad_"
]
},
"conjunctions":{
"type":"mapping",
"mappings":[
"&=>and"
]
}
}
}
}
}附录1:支持的Character Filter
Mapping Character Filter
可通过mappings参数配置Key-Value映射关系,当匹配到Key字符,则用对应Value进行替换,例如":) =>_happy_",表示":)"会被"_happy_"替换。支持配置多个过滤器。
参数说明:
mappings(必填):数组类型,每个元素必须包含
=>,例如"&=>and"。
配置示例:
{
"mappings":{
"properties":{
"f0":{
"type":"text",
"analyzer":"my_custom_analyzer"
}
}
},
"settings":{
"analysis":{
"analyzer":{
"my_custom_analyzer":{
"type":"custom",
"tokenizer":"standard",
"char_filter": [
"emoticons"
]
}
},
"char_filter":{
"emoticons":{
"type":"mapping",
"mappings":[
":) => _happy_",
":( => _sad_"
]
}
}
}
}
}附录2:支持的Tokenizer
whitespace
根据空格拆分文档。
可选参数:
max_token_length:每个Token的长度上限,默认为255。若Token超过该长度,会根据指定的长度上限对Token进行拆分。
配置示例:
# 默认配置:
{
"mappings":{
"properties":{
"f0":{
"type":"text",
"analyzer":"my_custom_analyzer"
}
}
},
"settings":{
"analysis":{
"analyzer":{
"my_custom_analyzer":{
"type":"custom",
"tokenizer":"whitespace"
}
}
}
}
}
# 自定义配置:
{
"mappings":{
"properties":{
"f0":{
"type":"text",
"analyzer":"my_custom_analyzer"
}
}
},
"settings":{
"analysis":{
"analyzer":{
"my_custom_analyzer":{
"type":"custom",
"tokenizer":"token1"
}
},
"tokenizer":{
"token1":{
"type":"whitespace",
"max_token_length":2
}
}
}
}
}standard
基于Unicode文本切割算法拆分文档,适用于多数语言。
可选参数:
max_token_length:每个Token的长度上限,默认为255。若Token超过该长度,会根据指定的长度上限对Token进行拆分。
配置示例:
# 默认配置:
{
"mappings":{
"properties":{
"f0":{
"type":"text",
"analyzer":"my_custom_analyzer"
}
}
},
"settings":{
"analysis":{
"analyzer":{
"my_custom_analyzer":{
"type":"custom",
"tokenizer":"standard"
}
}
}
}
}
# 自定义配置:
{
"mappings":{
"properties":{
"f0":{
"type":"text",
"analyzer":"my_custom_analyzer"
}
}
},
"settings":{
"analysis":{
"analyzer":{
"my_custom_analyzer":{
"type":"custom",
"tokenizer":"token1"
}
},
"tokenizer":{
"token1":{
"type":"standard",
"max_token_length":2
}
}
}
}
}classic
根据英文语法拆分文档,并且会对缩写词、公司名称、电子邮件地址和互联网IP地址进行特殊处理,详细说明如下。
按标点符号拆分单词,并删除标点符号,但没有空格的英文句号会被认为是Token的一部分,例如
red.apple不会被拆分,red.[space] apple会被拆分为red和apple。按连字符拆分单词,若Token中含有数字,则整个Token会被解释为产品编号而不会被拆分。
将电子邮件地址和因特网主机名识别为一个Token。
可选参数:
max_token_length:每个Token的长度上限,默认为255。若Token超过该长度,会被跳过。
配置示例:
# 默认配置:
{
"mappings":{
"properties":{
"f0":{
"type":"text",
"analyzer":"my_custom_analyzer"
}
}
},
"settings":{
"analysis":{
"analyzer":{
"my_custom_analyzer":{
"type":"custom",
"tokenizer":"classic"
}
}
}
}
}
# 自定义配置:
{
"mappings":{
"properties":{
"f0":{
"type":"text",
"analyzer":"my_custom_analyzer"
}
}
},
"settings":{
"analysis":{
"analyzer":{
"my_custom_analyzer":{
"type":"custom",
"tokenizer":"token1"
}
},
"tokenizer":{
"token1":{
"type":"classic",
"max_token_length":2
}
}
}
}
}letter
根据非字母(non-letter)的符号拆分文档,适用于欧洲语言,不适用于亚洲语言。
配置示例:
# 默认配置:
{
"mappings":{
"properties":{
"f0":{
"type":"text",
"analyzer":"my_custom_analyzer"
}
}
},
"settings":{
"analysis":{
"analyzer":{
"my_custom_analyzer":{
"type":"custom",
"tokenizer":"letter"
}
}
}
}
}lowercase
根据非字母(non-letter)的符号拆分文档,并将所有Token转为小写。Lowercase Tokenizer的分词效果与Letter Tokenizer组合LowerCase Filter的效果相同,但Lowercase Tokenizer可减少一次遍历。
配置示例:
# 默认配置:
{
"mappings":{
"properties":{
"f0":{
"type":"text",
"analyzer":"my_custom_analyzer"
}
}
},
"settings":{
"analysis":{
"analyzer":{
"my_custom_analyzer":{
"type":"custom",
"tokenizer":"lowercase"
}
}
}
}
}keyword
不拆分文档,将文档作为一个Token输出。通常与Token Filter配合使用,例如Keyword Tokenizer组合Lowercase Token Filter,可实现将输入的文档转为小写。
配置示例:
# 默认配置:
{
"mappings":{
"properties":{
"f0":{
"type":"text",
"analyzer":"my_custom_analyzer"
}
}
},
"settings":{
"analysis":{
"analyzer":{
"my_custom_analyzer":{
"type":"custom",
"tokenizer":"keyword"
}
}
}
}
}jieba
推荐的中文分词器,可以按照预先训练好的词典或者指定的词典拆分文档。
可选参数:
userwords:自定义词典,数组类型,单个词必须是字符串。配置后会追加至默认词典中,默认词典请参见Jieba默认词典。
重要自定义词典的单词中不能出现空格与特殊字符:
\t、\n、,和。。use_hmm:对于字典中不存在的词,是否使用隐式马尔科夫链模型判断成词,取值为true(默认,表示开启)或false(不开启)。
配置示例:
# 默认配置:
{
"mappings":{
"properties":{
"f0":{
"type":"text",
"analyzer":"my_custom_analyzer"
}
}
},
"settings":{
"analysis":{
"analyzer":{
"my_custom_analyzer":{
"type":"custom",
"tokenizer":"jieba"
}
}
}
}
}
# 自定义配置:
{
"mappings":{
"properties":{
"f1":{
"type":"text",
"analyzer":"my_custom_analyzer"
}
}
},
"settings":{
"analysis":{
"analyzer":{
"my_custom_analyzer":{
"type":"custom",
"tokenizer":"token1"
}
},
"tokenizer":{
"token1":{
"type":"jieba",
"userwords":[
"Redis",
"开源免费",
"灵活"
],
"use_hmm":true
}
}
}
}
}pattern
根据指定的正则表达式拆分文档,正则表达式匹配的词可以作为分隔符或者目标Token。
可选参数:
pattern:正则表达式,默认为
\W+,更多语法信息请参见Re2。group:指定正则表达式作为分隔符或目标Token,取值如下:
-1(默认):指定正则表达式匹配的词作为分隔符,例如指定的正则表达式是
"aaa",对"bbbaaaccc"文档进行分词,会得到"bbb"和"ccc"。0或大于0的整数:指定正则表达式匹配的词作为目标Token,0表示以整个正则表达式进行匹配,1或1以上的整数表示以正则表达式中的第几个捕获组进行匹配。例如指定的正则表达式是
"a(b+)c",对"abbbcdefabc"文档进行分词:当group为0时,会得到"abbbc"和"abc";当group为1时,将以"a(b+)c"中的第一个捕获组b+进行匹配,会得到"bbb"和"b"。
flags:正则表达式是否大小写敏感,默认为空(表示大小写敏感),取值为CASE_INSENSITIVE(表示大小写不敏感)。
配置示例:
# 默认配置:
{
"mappings":{
"properties":{
"f0":{
"type":"text",
"analyzer":"my_custom_analyzer"
}
}
},
"settings":{
"analysis":{
"analyzer":{
"my_custom_analyzer":{
"type":"custom",
"tokenizer":"pattern"
}
}
}
}
}
# 自定义配置:
{
"mappings":{
"properties":{
"f1":{
"type":"text",
"analyzer":"my_custom_analyzer"
}
}
},
"settings":{
"analysis":{
"analyzer":{
"my_custom_analyzer":{
"type":"custom",
"tokenizer":"pattern_tokenizer"
}
},
"tokenizer":{
"pattern_tokenizer":{
"type":"pattern",
"pattern":"AB(A(\\w+)C)",
"flags":"CASE_INSENSITIVE",
"group":2
}
}
}
}
}IK
中文分词器,取值为ik_max_word或ik_smart。ik_max_word会拆分出文档中所有可能存在的Token;ik_smart会在ik_max_word的基础上,对Token进行二次识别,选择出最有可能的Token。
可选参数:
stopwords:停用词,分词器会过滤这些词。数组类型,单个停用词必须是字符串。配置后,会覆盖默认停用词。默认停用词如下:
["a", "an", "and", "are", "as", "at", "be", "but", "by", "for", "if", "in", "into", "is", "it", "no", "not", "of", "on", "or", "such", "that", "the", "their", "then", "there", "these", "they", "this", "to", "was", "will", "with"]userwords:自定义词典,数组类型,单个词必须是字符串,配置后会追加至默认词典中。默认词典请参见IK默认词典。
quantifiers:自定义量词词典,数组类型,单个词必须是字符串,配置后会追加至默认量词词典中。默认量词词典请参见IK默认量词词典。
enable_lowercase:是否将大写字母转换为小写,取值为true(默认,表示开启)或false(不开启)。
重要由于本参数所控制的操作(将大写字母转换为小写)会发生在分词之前,若自定义词典中存在大写字母,请将本参数设置为false。
配置示例:
# 默认配置:
{
"mappings":{
"properties":{
"f0":{
"type":"text",
"analyzer":"my_custom_ik_smart_analyzer"
},
"f1":{
"type":"text",
"analyzer":"my_custom_ik_max_word_analyzer"
}
}
},
"settings":{
"analysis":{
"analyzer":{
"my_custom_ik_smart_analyzer":{
"type":"custom",
"tokenizer":"ik_smart"
},
"my_custom_ik_max_word_analyzer":{
"type":"custom",
"tokenizer":"ik_max_word"
}
}
}
}
}
# 自定义配置:
{
"mappings":{
"properties":{
"f0":{
"type":"text",
"analyzer":"my_custom_ik_smart_analyzer"
},
"f1":{
"type":"text",
"analyzer":"my_custom_ik_max_word_analyzer"
}
}
},
"settings":{
"analysis":{
"analyzer":{
"my_custom_ik_smart_analyzer":{
"type":"custom",
"tokenizer":"my_ik_smart_tokenizer"
},
"my_custom_ik_max_word_analyzer":{
"type":"custom",
"tokenizer":"my_ik_max_word_tokenizer"
}
},
"tokenizer":{
"my_ik_smart_tokenizer":{
"type":"ik_smart",
"userwords":[
"中文分词器",
"自定义stopwords"
],
"stopwords":[
"关于",
"测试"
],
"quantifiers":[
"纳秒"
],
"enable_lowercase":false
},
"my_ik_max_word_tokenizer":{
"type":"ik_max_word",
"userwords":[
"中文分词器",
"自定义stopwords"
],
"stopwords":[
"关于",
"测试"
],
"quantifiers":[
"纳秒"
],
"enable_lowercase":false
}
}
}
}
}附录3:支持的Token Filter
classic
过滤Token中尾部的's和缩略词中的.,例如会将Fig.转换为Fig。
配置示例:
# 默认配置:
{
"mappings":{
"properties":{
"f0":{
"type":"text",
"analyzer":"my_custom_analyzer"
}
}
},
"settings":{
"analysis":{
"analyzer":{
"my_custom_analyzer":{
"type":"custom",
"tokenizer":"classic",
"filter":["classic"]
}
}
}
}
}elision
过滤指定的元音,常用于法语中。
可选参数:
articles(自定义时必填):指定的元音,数组类型,单个字母必须是字符串,默认为
["l", "m", "t", "qu", "n", "s", "j"],配置后会覆盖默认词典。articles_case(可选):指定的元音是否大小写敏感,取值为true(表示大小写不敏感)或false(默认,大小写敏感)。
配置示例:
# 默认配置:
{
"mappings":{
"properties":{
"f0":{
"type":"text",
"analyzer":"my_custom_analyzer"
}
}
},
"settings":{
"analysis":{
"analyzer":{
"my_custom_analyzer":{
"type":"custom",
"tokenizer":"whitespace",
"filter":["elision"]
}
}
}
}
}
# 自定义配置:
{
"mappings":{
"properties":{
"f0":{
"type":"text",
"analyzer":"my_custom_analyzer"
}
}
},
"settings":{
"analysis":{
"analyzer":{
"my_custom_analyzer":{
"type":"custom",
"tokenizer":"whitespace",
"filter":["elision_filter"]
}
},
"filter":{
"elision_filter":{
"type":"elision",
"articles":["l", "m", "t", "qu", "n", "s", "j"],
"articles_case":true
}
}
}
}
}lowercase
将所有Token转换为小写。
可选参数:
language:词元过滤器的语言,只能设置为greek或russian。若不设置该参数,则默认为英语。
配置示例:
# 默认配置:
{
"mappings":{
"properties":{
"f0":{
"type":"text",
"analyzer":"my_custom_analyzer"
}
}
},
"settings":{
"analysis":{
"analyzer":{
"my_custom_analyzer":{
"type":"custom",
"tokenizer":"whitespace",
"filter":["lowercase"]
}
}
}
}
}
# 自定义配置:
{
"mappings":{
"properties":{
"f0":{
"type":"text",
"analyzer":"my_custom_greek_analyzer"
},
"f1":{
"type":"text",
"analyzer":"my_custom_russian_analyzer"
}
}
},
"settings":{
"analysis":{
"analyzer":{
"my_custom_greek_analyzer":{
"type":"custom",
"tokenizer":"whitespace",
"filter":["greek_lowercase"]
},
"my_custom_russian_analyzer":{
"type":"custom",
"tokenizer":"whitespace",
"filter":["russian_lowercase"]
}
},
"filter":{
"greek_lowercase":{
"type":"lowercase",
"language":"greek"
},
"russian_lowercase":{
"type":"lowercase",
"language":"russian"
}
}
}
}
}snowball
将所有Token转换为词干,例如将cats转换为cat。
可选参数:
language:词元过滤器的语言,取值为english(默认)、german、french和dutch。
配置示例:
# 默认配置:
{
"mappings":{
"properties":{
"f0":{
"type":"text",
"analyzer":"my_custom_analyzer"
}
}
},
"settings":{
"analysis":{
"analyzer":{
"my_custom_analyzer":{
"type":"custom",
"tokenizer":"whitespace",
"filter":["snowball"]
}
}
}
}
}
# 自定义配置:
{
"mappings":{
"properties":{
"f0":{
"type":"text",
"analyzer":"my_custom_analyzer"
}
}
},
"settings":{
"analysis":{
"analyzer":{
"my_custom_analyzer":{
"type":"custom",
"tokenizer":"standard",
"filter":["my_filter"]
}
},
"filter":{
"my_filter":{
"type":"snowball",
"language":"english"
}
}
}
}
}stop
根据指定的停用词数组,过滤Token中出现的停用词。
可选参数:
stopwords:停用词数组,单个停用词必须是字符串。配置后,会覆盖默认停用词。默认停用词如下:
["a", "an", "and", "are", "as", "at", "be", "but", "by", "for", "if", "in", "into", "is", "it", "no", "not", "of", "on", "or", "such", "that", "the", "their", "then", "there", "these", "they", "this", "to", "was", "will", "with"]ignoreCase:匹配停用词时是否大小写敏感,取值为true(表示大小写不敏感)或false(默认,大小写敏感)。
配置示例:
# 默认配置:
{
"mappings":{
"properties":{
"f0":{
"type":"text",
"analyzer":"my_custom_analyzer"
}
}
},
"settings":{
"analysis":{
"analyzer":{
"my_custom_analyzer":{
"type":"custom",
"tokenizer":"whitespace",
"filter":["stop"]
}
}
}
}
}
# 自定义配置:
{
"mappings":{
"properties":{
"f0":{
"type":"text",
"analyzer":"my_custom_analyzer"
}
}
},
"settings":{
"analysis":{
"analyzer":{
"my_custom_analyzer":{
"type":"custom",
"tokenizer":"standard",
"filter":["stop_filter"]
}
},
"filter":{
"stop_filter":{
"type":"stop",
"stopwords":[
"the"
],
"ignore_case":true
}
}
}
}
}asciifolding
将不在基本拉丁文Unicode块(前127个ASCII字符)中的字母、数字和符号转换为等价的ASCII字符(如果存在),例如将é转换为e。
配置示例:
# 默认配置:
{
"mappings":{
"properties":{
"f0":{
"type":"text",
"analyzer":"my_custom_analyzer"
}
}
},
"settings":{
"analysis":{
"analyzer":{
"my_custom_analyzer":{
"type":"custom",
"tokenizer":"standard",
"filter":["asciifolding"]
}
}
}
}
}length
过滤指定长度范围以外的Token。
可选参数:
min:Token的最小长度,整数,默认为0。
max:Token的最大长度,整数,默认为(2^31 - 1)。
配置示例:
# 默认配置:
{
"mappings":{
"properties":{
"f0":{
"type":"text",
"analyzer":"my_custom_analyzer"
}
}
},
"settings":{
"analysis":{
"analyzer":{
"my_custom_analyzer":{
"type":"custom",
"tokenizer":"whitespace",
"filter":["length"]
}
}
}
}
}
# 自定义配置:
{
"mappings":{
"properties":{
"f0":{
"type":"text",
"analyzer":"my_custom_analyzer"
}
}
},
"settings":{
"analysis":{
"analyzer":{
"my_custom_analyzer":{
"type":"custom",
"tokenizer":"whitespace",
"filter":["length_filter"]
}
},
"filter":{
"length_filter":{
"type":"length",
"max":5,
"min":2
}
}
}
}
}Normalization
规范某种语言的特定字符,取值为arabic_normalization或persian_normalization,推荐搭配Standard tokenizer使用。
配置示例:
# 默认配置:
{
"mappings":{
"properties":{
"f0":{
"type":"text",
"analyzer":"my_arabic_analyzer"
},
"f1":{
"type":"text",
"analyzer":"my_persian_analyzer"
}
}
},
"settings":{
"analysis":{
"analyzer":{
"my_arabic_analyzer":{
"type":"custom",
"tokenizer":"arabic",
"filter":["arabic_normalization"]
},
"my_persian_analyzer":{
"type":"custom",
"tokenizer":"arabic",
"filter":["persian_normalization"]
}
}
}
}
}附录4:内置分词器Language各语言的默认停用词(Stopwords)
arabic
["من","ومن","منها","منه","في","وفي","فيها","فيه","و","ف","ثم","او","أو","ب","بها","به","ا","أ","اى","اي","أي","أى","لا","ولا","الا","ألا","إلا","لكن","ما","وما","كما","فما","عن","مع","اذا","إذا","ان","أن","إن","انها","أنها","إنها","انه","أنه","إنه","بان","بأن","فان","فأن","وان","وأن","وإن","التى","التي","الذى","الذي","الذين","الى","الي","إلى","إلي","على","عليها","عليه","اما","أما","إما","ايضا","أيضا","كل","وكل","لم","ولم","لن","ولن","هى","هي","هو","وهى","وهي","وهو","فهى","فهي","فهو","انت","أنت","لك","لها","له","هذه","هذا","تلك","ذلك","هناك","كانت","كان","يكون","تكون","وكانت","وكان","غير","بعض","قد","نحو","بين","بينما","منذ","ضمن","حيث","الان","الآن","خلال","بعد","قبل","حتى","عند","عندما","لدى","جميع"]cjk
["with","will","to","this","there","then","the","t","that","such","s","on","not","no","it","www","was","is","","into","their","or","in","if","for","by","but","they","be","these","at","are","as","and","of","a"]brazilian
["uns","umas","uma","teu","tambem","tal","suas","sobre","sob","seu","sendo","seja","sem","se","quem","tua","que","qualquer","porque","por","perante","pelos","pelo","outros","outro","outras","outra","os","o","nesse","nas","na","mesmos","mesmas","mesma","um","neste","menos","quais","mediante","proprio","logo","isto","isso","ha","estes","este","propios","estas","esta","todas","esses","essas","toda","entre","nos","entao","em","eles","qual","elas","tuas","ela","tudo","do","mesmo","diversas","todos","diversa","seus","dispoem","ou","dispoe","teus","deste","quer","desta","diversos","desde","quanto","depois","demais","quando","essa","deles","todo","pois","dele","dela","dos","de","da","nem","cujos","das","cujo","durante","cujas","portanto","cuja","contudo","ele","contra","como","com","pelas","assim","as","aqueles","mais","esse","aquele","mas","apos","aos","aonde","sua","e","ao","antes","nao","ambos","ambas","alem","ainda","a"]czech
["a","s","k","o","i","u","v","z","dnes","cz","tímto","budeš","budem","byli","jseš","muj","svým","ta","tomto","tohle","tuto","tyto","jej","zda","proc","máte","tato","kam","tohoto","kdo","kterí","mi","nám","tom","tomuto","mít","nic","proto","kterou","byla","toho","protože","asi","ho","naši","napište","re","což","tím","takže","svých","její","svými","jste","aj","tu","tedy","teto","bylo","kde","ke","pravé","ji","nad","nejsou","ci","pod","téma","mezi","pres","ty","pak","vám","ani","když","však","neg","jsem","tento","clánku","clánky","aby","jsme","pred","pta","jejich","byl","ješte","až","bez","také","pouze","první","vaše","která","nás","nový","tipy","pokud","muže","strana","jeho","své","jiné","zprávy","nové","není","vás","jen","podle","zde","už","být","více","bude","již","než","který","by","které","co","nebo","ten","tak","má","pri","od","po","jsou","jak","další","ale","si","se","ve","to","jako","za","zpet","ze","do","pro","je","na","atd","atp","jakmile","pricemž","já","on","ona","ono","oni","ony","my","vy","jí","ji","me","mne","jemu","tomu","tem","temu","nemu","nemuž","jehož","jíž","jelikož","jež","jakož","nacež"]german
["wegen","mir","mich","dich","dir","ihre","wird","sein","auf","durch","ihres","ist","aus","von","im","war","mit","ohne","oder","kein","wie","was","es","sie","mein","er","du","daß","dass","die","als","ihr","wir","der","für","das","einen","wer","einem","am","und","eines","eine","in","einer"]greek
["ο","η","το","οι","τα","του","τησ","των","τον","την","και","κι","κ","ειμαι","εισαι","ειναι","ειμαστε","ειστε","στο","στον","στη","στην","μα","αλλα","απο","για","προσ","με","σε","ωσ","παρα","αντι","κατα","μετα","θα","να","δε","δεν","μη","μην","επι","ενω","εαν","αν","τοτε","που","πωσ","ποιοσ","ποια","ποιο","ποιοι","ποιεσ","ποιων","ποιουσ","αυτοσ","αυτη","αυτο","αυτοι","αυτων","αυτουσ","αυτεσ","αυτα","εκεινοσ","εκεινη","εκεινο","εκεινοι","εκεινεσ","εκεινα","εκεινων","εκεινουσ","οπωσ","ομωσ","ισωσ","οσο","οτι"]persian
["انان","نداشته","سراسر","خياه","ايشان","وي","تاكنون","بيشتري","دوم","پس","ناشي","وگو","يا","داشتند","سپس","هنگام","هرگز","پنج","نشان","امسال","ديگر","گروهي","شدند","چطور","ده","و","دو","نخستين","ولي","چرا","چه","وسط","ه","كدام","قابل","يك","رفت","هفت","همچنين","در","هزار","بله","بلي","شايد","اما","شناسي","گرفته","دهد","داشته","دانست","داشتن","خواهيم","ميليارد","وقتيكه","امد","خواهد","جز","اورده","شده","بلكه","خدمات","شدن","برخي","نبود","بسياري","جلوگيري","حق","كردند","نوعي","بعري","نكرده","نظير","نبايد","بوده","بودن","داد","اورد","هست","جايي","شود","دنبال","داده","بايد","سابق","هيچ","همان","انجا","كمتر","كجاست","گردد","كسي","تر","مردم","تان","دادن","بودند","سري","جدا","ندارند","مگر","يكديگر","دارد","دهند","بنابراين","هنگامي","سمت","جا","انچه","خود","دادند","زياد","دارند","اثر","بدون","بهترين","بيشتر","البته","به","براساس","بيرون","كرد","بعضي","گرفت","توي","اي","ميليون","او","جريان","تول","بر","مانند","برابر","باشيم","مدتي","گويند","اكنون","تا","تنها","جديد","چند","بي","نشده","كردن","كردم","گويد","كرده","كنيم","نمي","نزد","روي","قصد","فقط","بالاي","ديگران","اين","ديروز","توسط","سوم","ايم","دانند","سوي","استفاده","شما","كنار","داريم","ساخته","طور","امده","رفته","نخست","بيست","نزديك","طي","كنيد","از","انها","تمامي","داشت","يكي","طريق","اش","چيست","روب","نمايد","گفت","چندين","چيزي","تواند","ام","ايا","با","ان","ايد","ترين","اينكه","ديگري","راه","هايي","بروز","همچنان","پاعين","كس","حدود","مختلف","مقابل","چيز","گيرد","ندارد","ضد","همچون","سازي","شان","مورد","باره","مرسي","خويش","برخوردار","چون","خارج","شش","هنوز","تحت","ضمن","هستيم","گفته","فكر","بسيار","پيش","براي","روزهاي","انكه","نخواهد","بالا","كل","وقتي","كي","چنين","كه","گيري","نيست","است","كجا","كند","نيز","يابد","بندي","حتي","توانند","عقب","خواست","كنند","بين","تمام","همه","ما","باشند","مثل","شد","اري","باشد","اره","طبق","بعد","اگر","صورت","غير","جاي","بيش","ريزي","اند","زيرا","چگونه","بار","لطفا","مي","درباره","من","ديده","همين","گذاري","برداري","علت","گذاشته","هم","فوق","نه","ها","شوند","اباد","همواره","هر","اول","خواهند","چهار","نام","امروز","مان","هاي","قبل","كنم","سعي","تازه","را","هستند","زير","جلوي","عنوان","بود"]french
["ô","être","vu","vous","votre","un","tu","toute","tout","tous","toi","tiens","tes","suivant","soit","soi","sinon","siennes","si","se","sauf","s","quoi","vers","qui","quels","ton","quelle","quoique","quand","près","pourquoi","plus","à","pendant","partant","outre","on","nous","notre","nos","tienne","ses","non","qu","ni","ne","mêmes","même","moyennant","mon","moins","va","sur","moi","miens","proche","miennes","mienne","tien","mien","n","malgré","quelles","plein","mais","là","revoilà","lui","leurs","","toutes","le","où","la","l","jusque","jusqu","ils","hélas","ou","hormis","laquelle","il","eu","nôtre","etc","est","environ","une","entre","en","son","elles","elle","dès","durant","duquel","été","du","voici","par","dont","donc","voilà","hors","doit","plusieurs","diverses","diverse","divers","devra","devers","tiennes","dessus","etre","dessous","desquels","desquelles","ès","et","désormais","des","te","pas","derrière","depuis","delà","hui","dehors","sans","dedans","debout","vôtre","de","dans","nôtres","mes","d","y","vos","je","concernant","comme","comment","combien","lorsque","ci","ta","nບnmoins","lequel","chez","contre","ceux","cette","j","cet","seront","que","ces","leur","certains","certaines","puisque","certaine","certain","passé","cependant","celui","lesquelles","celles","quel","celle","devant","cela","revoici","eux","ceci","sienne","merci","ce","c","siens","les","avoir","sous","avec","pour","parmi","avant","car","avait","sont","me","auxquels","sien","sa","excepté","auxquelles","aux","ma","autres","autre","aussi","auquel","aujourd","au","attendu","selon","après","ont","ainsi","ai","afin","vôtres","lesquels","a"]dutch
["andere","uw","niets","wil","na","tegen","ons","wordt","werd","hier","eens","onder","alles","zelf","hun","dus","kan","ben","meer","iets","me","veel","omdat","zal","nog","altijd","ja","want","u","zonder","deze","hebben","wie","zij","heeft","hoe","nu","heb","naar","worden","haar","daar","der","je","doch","moet","tot","uit","bij","geweest","kon","ge","zich","wezen","ze","al","zo","dit","waren","men","mijn","kunnen","wat","zou","dan","hem","om","maar","ook","er","had","voor","of","als","reeds","door","met","over","aan","mij","was","is","geen","zijn","niet","iemand","het","hij","een","toen","in","toch","die","dat","te","doen","ik","van","op","en","de"]russian
["а","без","более","бы","был","была","были","было","быть","в","вам","вас","весь","во","вот","все","всего","всех","вы","где","да","даже","для","до","его","ее","ей","ею","если","есть","еще","же","за","здесь","и","из","или","им","их","к","как","ко","когда","кто","ли","либо","мне","может","мы","на","надо","наш","не","него","нее","нет","ни","них","но","ну","о","об","однако","он","она","они","оно","от","очень","по","под","при","с","со","так","также","такой","там","те","тем","то","того","тоже","той","только","том","ты","у","уже","хотя","чего","чей","чем","что","чтобы","чье","чья","эта","эти","это","я"]