TairVector是基于Tair的向量存储引擎,集存储、检索于一体,提供高性能、实时的向量数据库服务。本文介绍了TairVector的性能测试方法和测试结果。
TairVector支持高性能的向量近似最近邻(ANN)检索,可用于非结构化数据的语义检索、个性化推荐等场景,更多信息请参见Vector。
测试说明
数据库测试环境
测试环境信息 | 说明 |
地域和可用区 | 华北3(张家口)地域,可用区A。 |
存储介质 | 内存型(兼容Redis 6.0)。 |
实例版本 | 6.2.8.2 |
实例架构 | 标准版(双副本)架构,不启用集群,详情请参见标准架构。 |
实例规格 | 由于测试结果受规格影响较小,本次测试以16 GB(tair.rdb.16g)规格为例,规格详情请参见内存型实例规格。 |
客户端测试环境
与Tair实例为同专有网络(VPC)的ECS实例,且与Tair通过专有网络连接。
Linux操作系统。
已安装Python 3.7及以上版本。
测试数据
本文使用Sift-128-euclidean、Gist-960-euclidean、Glove-200-angular和Deep-image-96-angular数据集测试HNSW索引,使用Random-s-100-euclidean和Mnist-784-euclidean数据集测试FLAT索引。
数据集名称 | 数据集介绍 | 向量维度 | 向量总数 | 查询数量 | 数据总量 | 距离类型 |
该数据集是基于Texmex的数据集整理,使用SIFT算法得到的图片特征向量。 | 128 | 1,000,000 | 10,000 | 488 MB | L2 | |
该数据集是基于Texmex的数据集整理,使用GIST算法得到的图片特征向量。 | 960 | 1,000,000 | 1,000 | 3.57 GB | L2 | |
该数据集是互联网文本数据使用GloVe算法得到的单词向量。 | 200 | 1,183,514 | 10,000 | 902 MB | COSINE | |
该数据集是ImageNet图片经过GoogLeNet模型训练,从最后一层神经网络提取的向量。 | 96 | 9,990,000 | 10,000 | 3.57 GB | COSINE | |
Random-s-100-euclidean | 该数据集为测试工具随机生成,不提供下载链接。 | 100 | 90,000 | 10,000 | 34 MB | L2 |
该数据集来自于MNIST手写失败数据集。 | 784 | 60,000 | 10,000 | 179 MB | L2 |
测试工具与测试方法
在测试服务器上,安装
tair-py和hiredis。安装方式:
pip install tair hiredis下载、安装Ann-benchmarks并解压。
解压命令如下:
tar -zxvf ann-benchmarks.tar.gz将Tair实例的连接地址、端口号和账号密码配置到
algos.yaml文件中。打开
algos.yaml文件,搜索tairvector找到对应配置项,修改base-args参数项,参数说明如下:url:Tair实例的连接地址及账号密码,格式为
redis://user:password@host:port。
parallelism:多线程的并发数,默认为4,建议使用默认值。
示例如下:
{"url": "redis://testaccount:Rp829dlwa@r-bp18uownec8it5****.redis.rds.aliyuncs.com:6379", "parallelism": 4}执行
run.py,启动完整的测试流程。重要run.py脚本会执行整个测试流程,包括建索引、写入数据、查询以及记录结果等操作,请勿对单个数据集重复执行。示例如下:
# 多线程测试Sift数据集(HNSW索引)。 python run.py --local --runs 3 --algorithm tairvector-hnsw --dataset sift-128-euclidean --batch # 多线程测试Mnist数据集(FLAT索引)。 python run.py --local --runs 3 --algorithm tairvector-flat --dataset mnist-784-euclidean --batch您也可以通过自带的Web前端执行测试,示例如下:
# 需提前安装Streamlit依赖。 pip3 install streamlit # 启动Web前端,启动后可以在浏览器中打开"http://localhost:8501"。 streamlit run webrunner.py执行
data_export.py,导出结果。示例如下:
# 多线程 python data_export.py --output out.csv --batch
测试结果
重点关注写入性能、KNN查询性能和内存效率方面的测试结果:
写入性能:关注吞吐率,吞吐率越高,性能越好。
KNN查询性能:关注QPS和召回率,QPS反映系统性能,召回率反映结果的准确性。通常召回率越高,相应的QPS也越低。在相同召回率下比较QPS才有参考意义,因此测试结果以“QPS-召回率”曲线的形式展示。对于FLAT索引,由于召回率始终为1,因此只展示QPS。
内存效率:关注向量索引占用内存的情况,内存占用越低越好。
写入和KNN查询测试均为4线程并发。
本次分别测试了FLOAT32(默认数据类型)和FLOAT16数据类型的性能。对于HNSW索引,还测试了开启AUTO_GC功能下的性能表现。
HNSW索引
写入性能
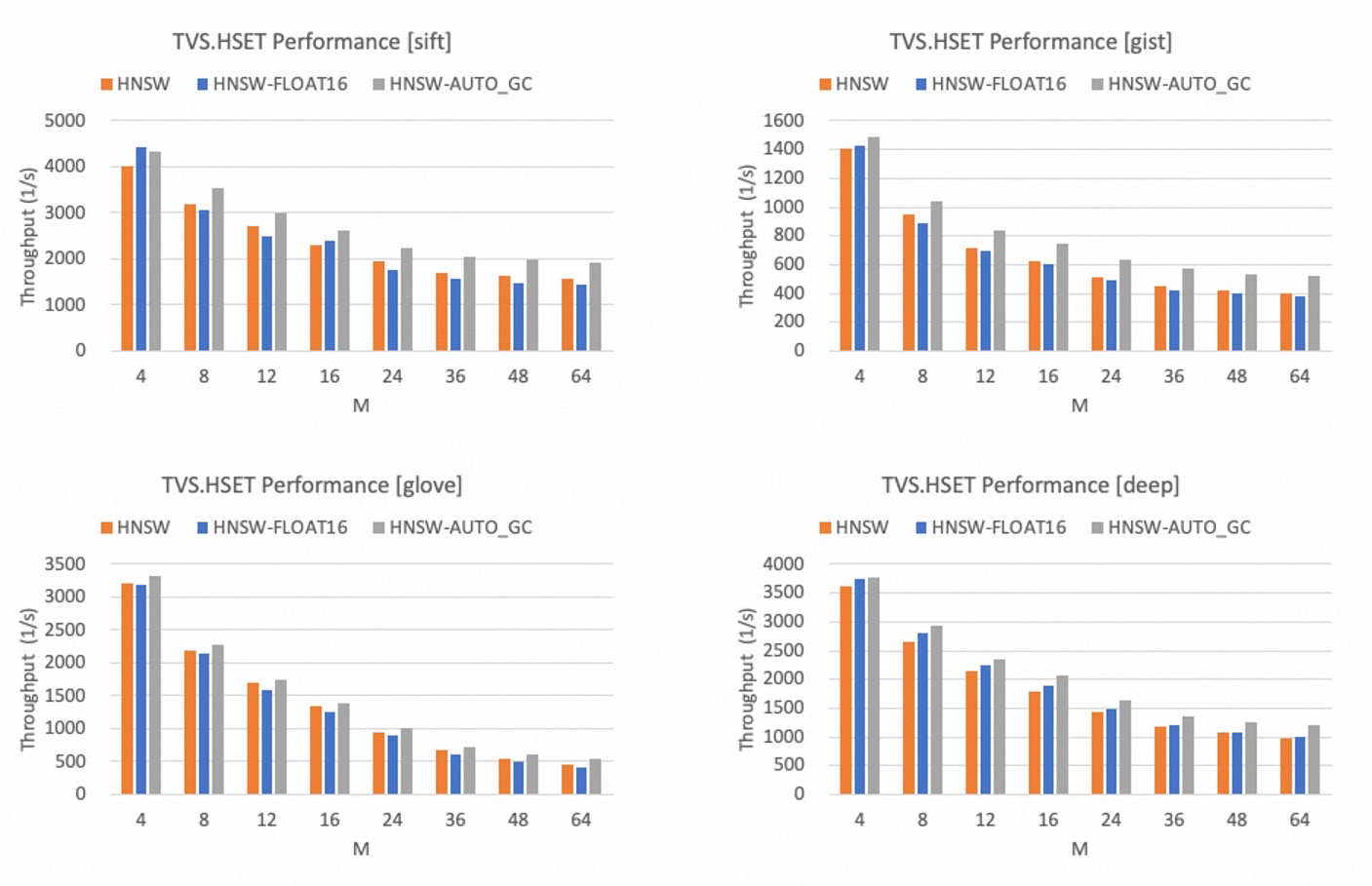
以下为ef_construct = 500时,不同M参数取值下的写入性能,可以得出:
M值越大,HNSW索引的写入性能越差。
相比较FLOAT32,FLOAT16数据类型的写入性能在多数情况下会有所下降,但是下降幅度不大,二者表现非常接近。
开启AUTO_GC功能后,写入性能会存在一定幅度提升,提升幅度最大可达30%。
KNN查询性能
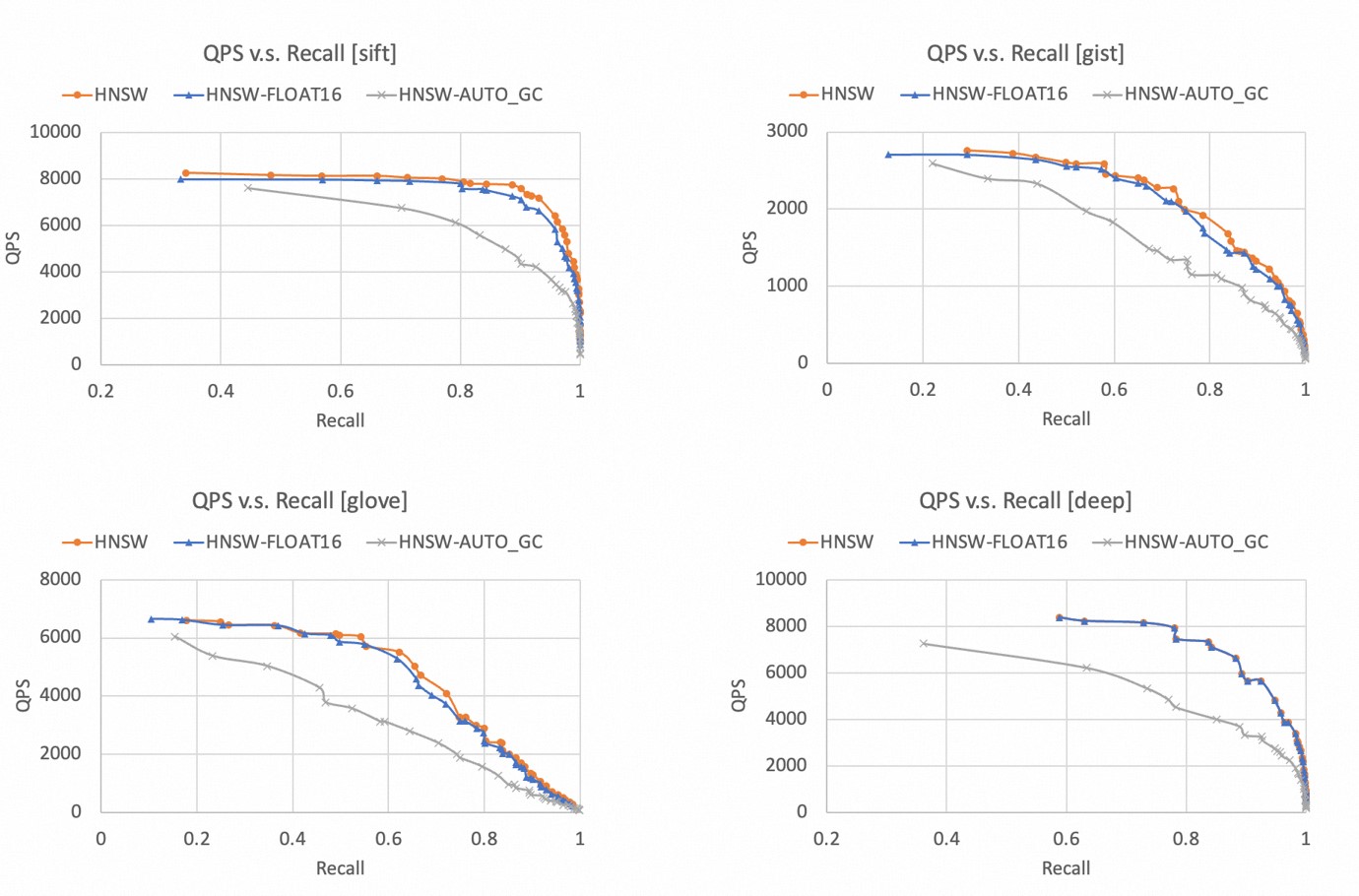
召回率和QPS都是越高越好,因此曲线越靠近右上角,代表算法表现越好。
以下为不同数据集下,TairVector HNSW索引的“QPS-召回率”曲线,可以得出:
在4个数据集下,HNSW索引都可以达到99%以上的召回率。
相比较FLOAT32,FLOAT16数据类型的性能略有下降,但是幅度不大,二者表现非常接近。
开启AUTO_GC功能后,查询性能会明显下降,因此建议您仅在需要删除大量数据的场景下开启AUTO_GC功能。
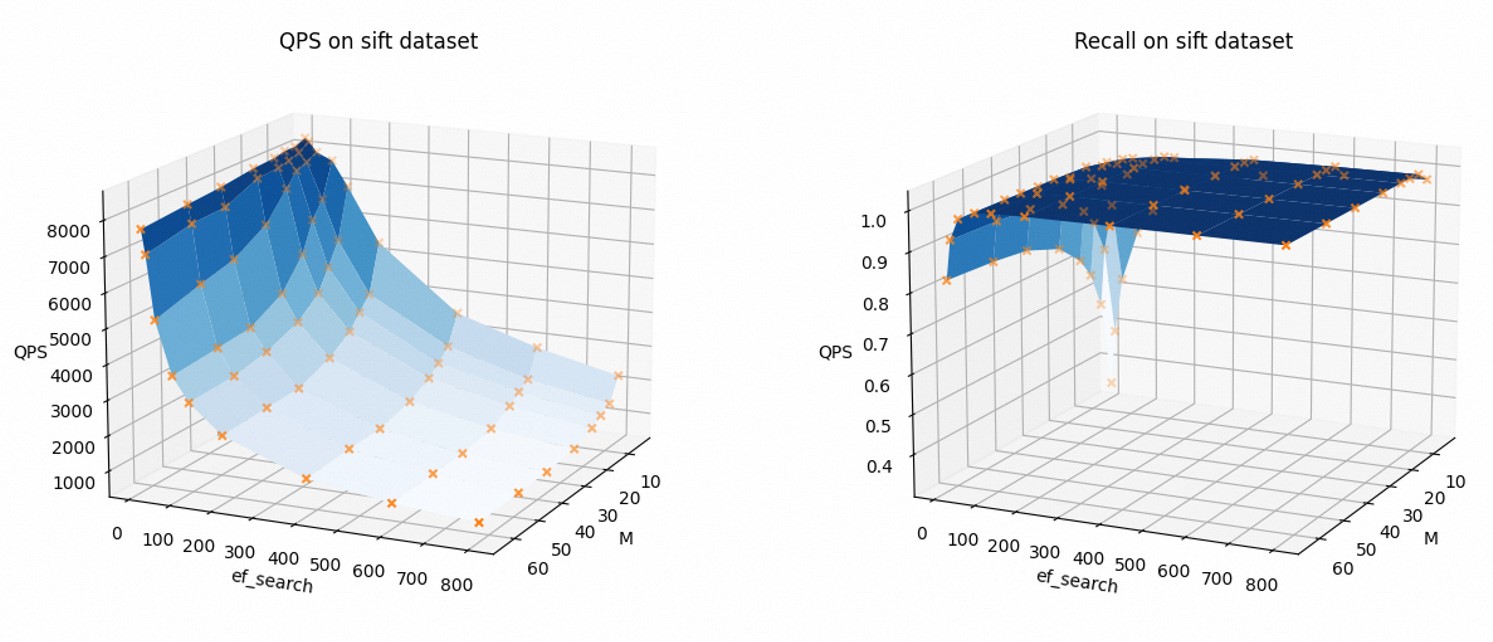
为了直观地展示索引参数如何影响查询性能,以下为以Sift数据集为例(FLOAT32,不开启AUTO_GC),QPS和召回率随着参数M和ef_search的变化趋势。
可以看到,随着M和ef_search的增加,QPS下降,召回率上升。
您在使用过程中可以根据需求调整索引参数,平衡查询性能与召回率。
内存效率
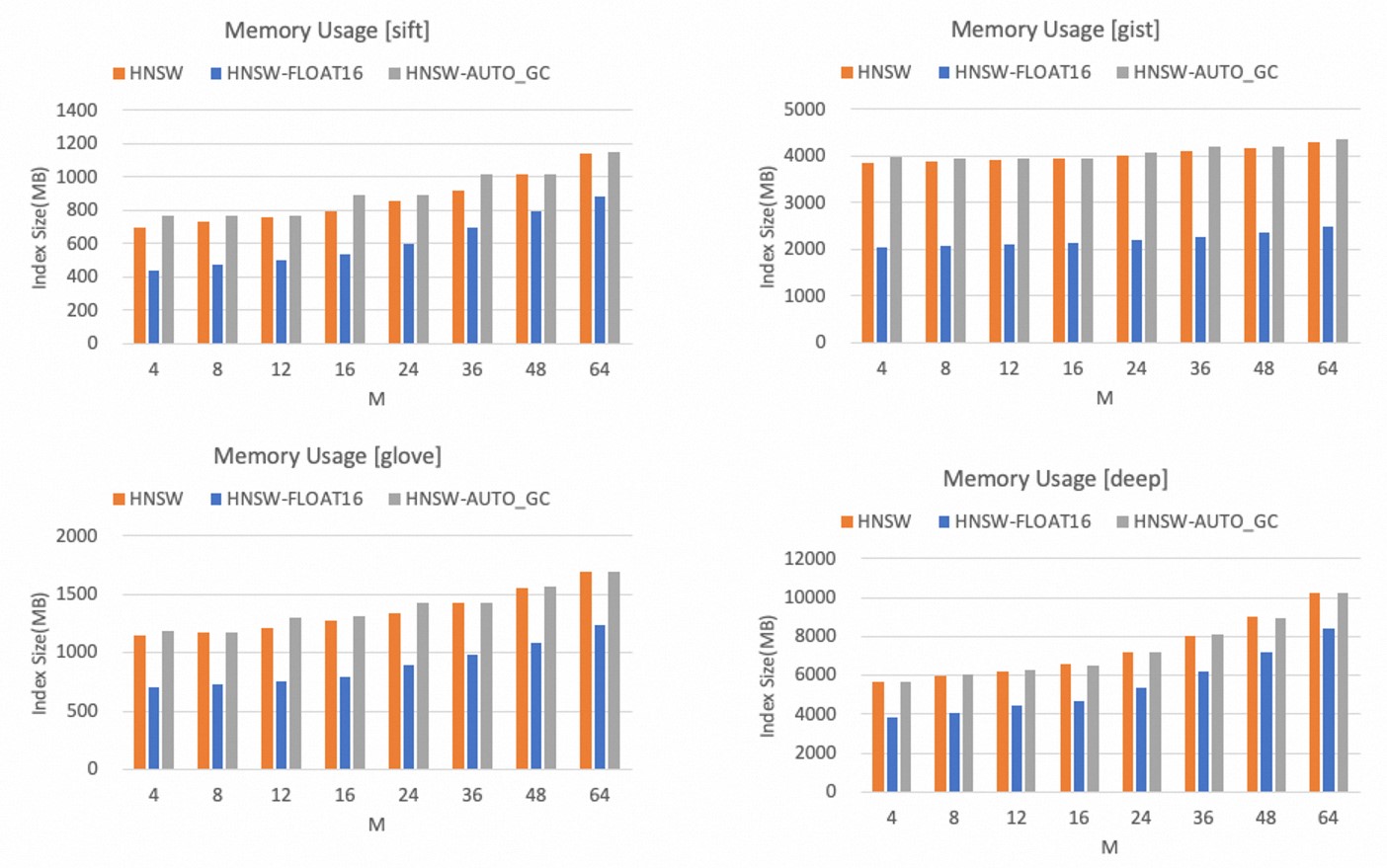
HNSW索引的内存使用量只受参数M的影响,M值越大,HNSW索引的内存占用越大。
以下为不同数据集下,TairVector HNSW索引的内存占用量,可以得出:
相比较FLOAT32,FLOAT16数据类型可以显著减少内存占用量,最大可以减少40%以上。
开启AUTO_GC功能后,内存占用量有小幅上升,但是幅度不大。
说明您在使用过程中可以根据向量数据维度和内存容量预算选择合适的M值。同时如果可以接受一定的精度损失,建议使用FLOAT16类型以节省内存空间。
FLAT索引
写入性能
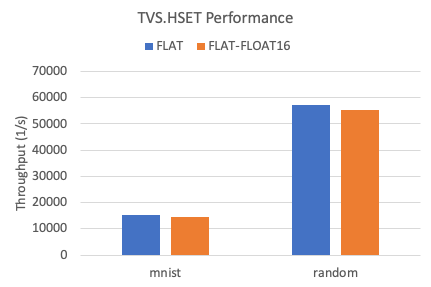
以下是在两个数据集下,TairVector FLAT索引的写入吞吐率。
相比较FLOAT32,FLOAT16数据类型的写入性能略有下降,下降幅度为5%左右。
KNN查询性能
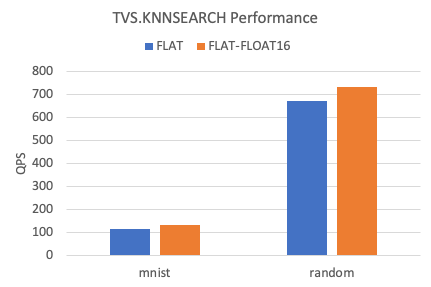
以下是在两个数据集下,TairVector FLAT索引KNN查询的QPS。
相比较FLOAT32,FLOAT16数据类型的KNN查询性能提升约10%左右。
内存效率
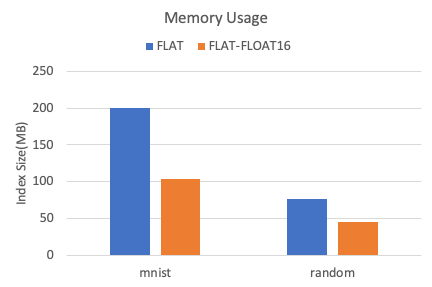
以下是在两个数据集下,TairVector FLAT索引的内存占用情况。
相比较FLOAT32,FLOAT16数据类型可减少40%以上的内存占用。
- 本页导读