通过RPA编辑器获取到页面数据之后,除了可将数据保存到本地表格之外,也可直接将数据处理后传输到数据库中,本文档主要介绍使用RPA获取页面数据场景中、将获取到的数据传输到数据库的实践方法。
本文档仅针对获取数据并传输到数据库的数据新增场景,涉及到数据库已有数据调整、特别是业务数据调整的,不适合使用RPA来进行操作,请谨慎考虑具体实践。
前置准备
获取第三方包pymysql、peewee并导入编辑器
可在下列两种方法中进行二选一:
1.可以前往cmd黑窗口中将第三方包进行打包操作
导入包操作可参考如何使用自定义组件
# 安装PyMySQL 0.10.1版本
pip install PyMySQL==0.10.1
# 安装peewee 3.14.4版本
pip install peewee==3.14.4
# 安装rpapack工具
pip install rpapack
# 执行打包操作
python -m rpapack PyMySQL
python -m rpapack peewee
2.获取预先准备好的常用第三方包
示例RPA工程文件中已导入第三方包,下载示例工程文件即可参考
常用第三方库可参考:如何引用第三方库(旧)
快捷生成表对象类-ORM
常见场景中,往往是需要操作数据库中已有的表,需要用到对象关系映射模型(ORM),即将数据库表转化为python类、表字段转化为类属性,然后对属性字段进行操作。
安装好pymysql及peewee之后,在命令行界面执行peewee自带的pwiz.py模组,将对应数据库中的表按需生成python类对应的文本,以供后续数据操作,参考指令及说明如下:
# 生成本地数据库(localhost)对象类
python -m pwiz -e mysql -u root -P test
# 生成非本地数据库对象类
python -m pwiz -e mysql -H 4x.xxx.xxx.xx -p 3306 -u root -P -t users test注意:执行上述指令后,会在控制台输出对应的python文本,要将其保存为文件,可使用重定向符号,例如:
# 将生成的对象类重定向到test.py文件中
python -m pwiz -e mysql -u root -P test > test.py
指令各部分说明如下:
指令文本 | 含义说明 | 说明 |
python -m pwiz | 通过命令行形式运行pwiz.py文件 | 必填 |
-e mysql | 指定数据库引擎(操作MySQL需要先安装PyMySQL库) | 必填 |
-H 4x.xxx.xxx.xx | 指定数据库服务host地址(IP或域名) | 连接非本地数据库时必填 |
-p 3306 | 指定数据库 | 非必填,默认使用3306端口 |
-u root | 指定数据库用户 | 必填 |
-P | 指定使用密码登录数据库 | 必填,执行指令后会提示输入数据库用户对应的密码,密码正确才能连接数据库并生成对应文本。 |
-t users | 指定表名 | 非必填 |
test | 指定数据库名 | 必填 |
以上内容参考python第三方包peewee官方操作文档。
基本CURD操作
peewee对数据库的所有操作均基于表对应的模型类,请参考快捷生成表对象类-ORM
生成的类对象文件中,将配置对应数据库连接。
(一)Create数据新增
1.单行数据插入
# 实例化表对象,每一个实例对应一个数据行,使用save方法即可将数据行实例写入到数据库对应表中
user1 = User()
user1.username = "Howie"
user1.save()
# 使用create方法,则会创建一个表数据行实例,并将其插入到对应表中,并返回主键ID
User.create(username="Alier")
# 使用insert方法,则不会创建对象实例,直接将数据写入表中
User.insert(username="Wayen").execute()
2.多行数据插入
# 对于键值对型的数据,可以使用insert_many进行批量插入
data = [
{"username":"Ali","age":22},
{"username":"Ant","age":7},
{"username":"Howie","age":25}
]
# 对于非键值对型的元组数据,要插入多行,可以在使用insert_many方法的基础上,按顺序指定对应字段名,以正确插入相关数据。
data = [
('Ali', 22),
('Ant', 7),
('Howie', 25)
]
User.insert_many(data, fields=[User.name, User.age]).execute()3.分批插入
# 人工对数据进行切片操作
for index in range(0,len(data),100):
User.insert_many(data[index:index+100]).execute()
# 使用chunked方法可以快速将数据分批
for batch in chunked(data, 100):
User.insert_many(batch).execute()(二)Update数据更新
# 通过先按条件检索出相关数据行,直接对对应的行对象实例进行save操作,如本例中取出主键ID为3的行,将其name字段改为"TEST"
user = User.get(3)
user.user_name = "TEST"
user.save()
# 使用update方法进行更新
query = Bill.update(amount=0).where(Bill.amount<1000)
query.execute()
(三)Retrieve数据检索
1.基础查询
# 通过select方法会返回对应表中的所有行,作为ModelSelect对象进行操作
query = User.select()
# 通过dicts方法,能将每一行转换为字典结构;
row_data_dicts = query.dicts()
for row_dict in row_data_dicts:
print(row_dict)
# {"name":"Ali","age":12}
# 关联查询,多表关联查询需要用到join方法进行表关联,where方法限定查询条件,方法中已做了谓词下推等基本优化。
# 最终将返回ModelSelect对象
query = (Bill
.select(Bill,User)
.join(User, on = Bill.user==User.id)
.where(Bill.user==1)
.order_by(Bill.bill_id.desc())
)2.查询新增联合操作
# 使用get_or_create操作,会先检索数据库中是否存在对应行数据,不存在的情况下,进行新增操作
# 使用类属性参数来指定查询条件,查询无记录的情况下,将对应属性作为新记录执行插入
# 使用defaults参数来指定当行记录不存在时,要新增的字段值
# get_or_create会返回形如(Model,Bool)的结果,其中Model是对应的数据行模型,Bool指是否为新建记录。
bill,created = Bill.get_or_create(
user=2,
defaults={'amount':666}
)(四)Delete删除数据
# 使用delete_instance方法删除单个数据行实例
user = User.get(User.id == 1)
user.delete_instance()
# 使用delete方法根据条件删除多行数据
query = Bill.delete().where(Bill.amount<1000)
query.execute()
事务型操作
# 使用with db.atomic声明事务操作,保证批量数据插入的完整性,其中db为通过peewee的MySQLDatabase方法创建的数据库连接实例
data = [
{"username":"Ali","age":"22"},
{"username":"Ant","age":"7"},
# ...
]
# 需要将数据作整体一次性插入时
with db.atomic():
User.insert_many(data).excute()
# 遇到数据量特别大的情况,可以考虑使用chunk方法进行数据分批操作
with db.atomic():
for batch in chunked(data, 100):
User.insert_many(batch).execute()
实例-获取GDP数据并存入数据库
工程文件可前往以下地址进行下载:RPA 4最佳实践工程文件
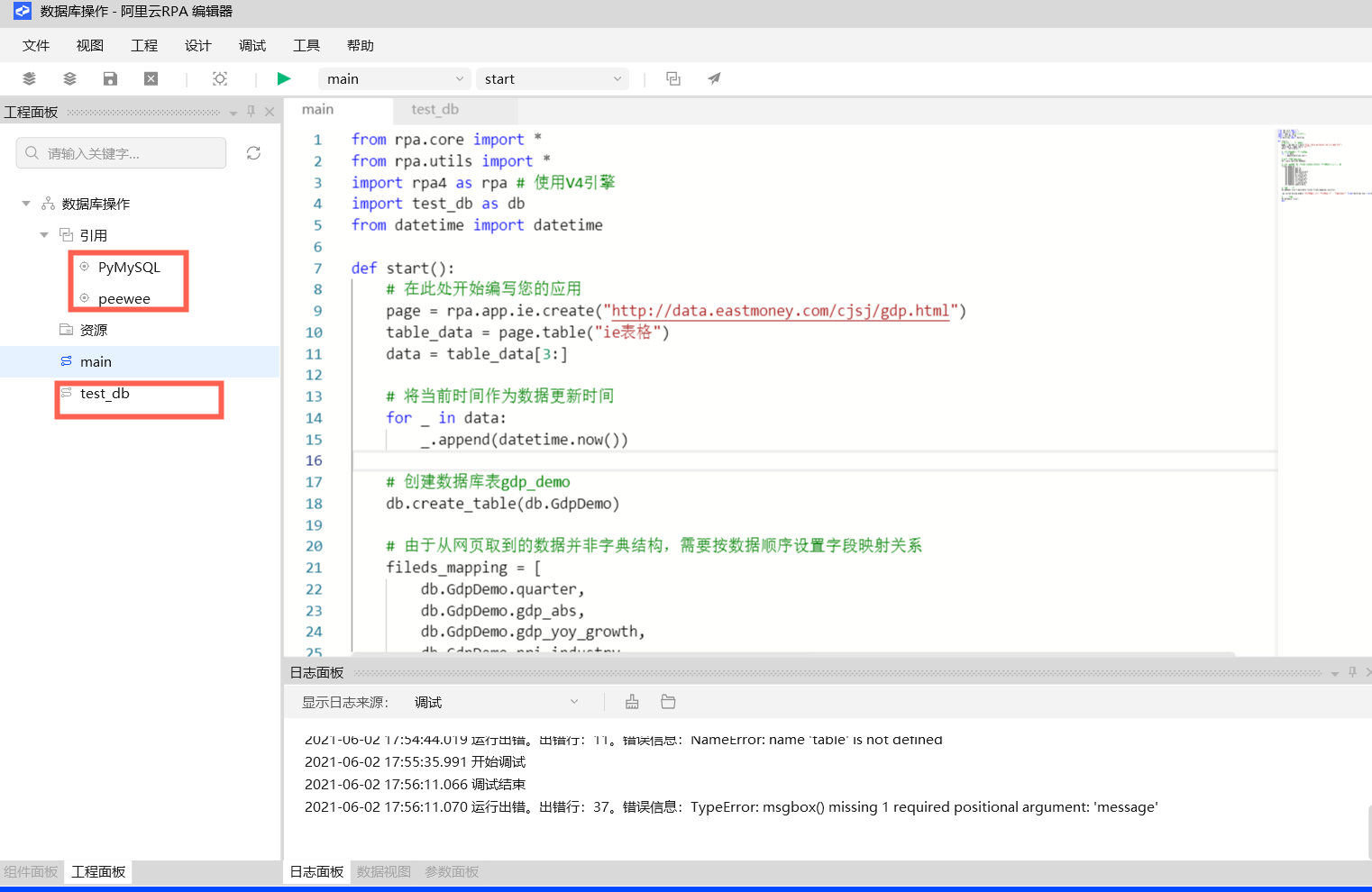 本案例主要登录特定网址,获取GDP数据,最终将其存放到本地MySQL数据库中的rpa_demo库中,详情请参见工程源文件或者关键代码说明。
本案例主要登录特定网址,获取GDP数据,最终将其存放到本地MySQL数据库中的rpa_demo库中,详情请参见工程源文件或者关键代码说明。
关键代码
1.数据库操作
from peewee import *
# 根据实际情况设置数据库用户名密码,以及要连接的库名
db_user_name = 'root'
db_password = 'xxxxx'
db_name = 'rpa_demo'
# 构建数据库连接类
database = MySQLDatabase(db_name, **{'password': db_password, 'sql_mode': 'PIPES_AS_CONCAT', 'charset': 'utf8', 'user': db_user_name, 'use_unicode': True})
class BaseModel(Model):
class Meta:
database = database
# 构建数据表对象类,用于存放GDP数据
class GdpDemo(BaseModel):
# 行ID
row_id = AutoField()
# 季度名
quarter = CharField()
# 国内生产总值
# 绝对值
gdp_abs = CharField()
# 同比增长
gdp_yoy_growth = CharField()
# 第一产业
# 绝对值
pri_industry = CharField()
# 同比增长
pi_yoy_growth = CharField()
# 第二产业
# 绝对值
sec_industry = CharField()
# 同比增长
si_yoy_growth = CharField()
# 第三产业
# 绝对值
thi_industry = CharField()
# 同比增长
ti_yoy_growth = CharField()
# 数据更新日期
update_date = DateField()
class Meta:
table_name = 'gdp_demo'
# 新建表
def create_table(table):
if not table.table_exists():
table.create_table()2.主程序
from rpa.core import *
from rpa.utils import *
import rpa4 as rpa # 使用V4引擎
import test_db as db
from datetime import datetime
def start():
# 在此处开始编写您的应用
page = rpa.app.ie.create("http://data.eastmoney.com/cjsj/gdp.html")
table_data = page.table("ie表格")
data = table_data[3:]
# 将当前时间作为数据更新时间
for _ in data:
_.append(datetime.now())
# 创建数据库表gdp_demo,如果表已存在则跳过
db.create_table(db.GdpDemo)
# 由于从网页取到的数据并非字典结构,需要按数据顺序设置字段映射关系
fileds_mapping = [
db.GdpDemo.quarter,
db.GdpDemo.gdp_abs,
db.GdpDemo.gdp_yoy_growth,
db.GdpDemo.pri_industry,
db.GdpDemo.pi_yoy_growth,
db.GdpDemo.sec_industry,
db.GdpDemo.si_yoy_growth,
db.GdpDemo.thi_industry,
db.GdpDemo.ti_yoy_growth,
db.GdpDemo.update_date]
# 批量插入数据
db.GdpDemo.insert_many(data,fields=fileds_mapping).execute()
rpa.system.dialog.msgbox("数据成功入库","当前时间{}:{}行数据已经成功写入到表gdp_demo中".format(datetime.now(),len(data)))
# 关闭数据库
db.database.close()
pass