
ARMS告警管理提供了可靠的告警收敛、通知、自动升级等功能,帮助您快速检测和修复业务告警。本文介绍告警管理的实现原理和优势。
背景信息
SAE集成了ARMS告警管理功能。ARMS新版告警管理功能仅对2021年04月30日0点之后开通SAE的阿里云账户开放。
功能架构
告警管理包含集成管理、告警事件管理、通知策略管理、告警协同处理和告警处理分析五个功能模块。

集成管理
集成管理分为默认告警集成和三方产品集成两部分。
默认告警集成
默认告警集成默认集成了ARMS各子产品的告警,如应用监控告警、前端监控告警、Prometheus告警、云拨测告警等。ARMS默认告警通常通过周期性的触发任务来检查监控数据是否存在异常,检测到异常后会通过默认的通道将告警事件上报到事件管理中心。
三方产品集成
三方产品集成支持通过简单配置接入任意告警源产生的告警,从而在ARMS上一站式处理分布在各个云上云下IDC系统产生的告警,实现统一处理告警的目的。任意告警源产生的告警上报到ARMS告警管理后统称为告警事件,告警事件有如下约束:
告警事件的数据结构
ARMS告警事件的数据结构参考开源AlertManager的数据结构,数据结构包括:
Labels(标签):告警元数据,一组标签唯一标识一个事件,标签相同的事件为同一个事件,重复上报会进行合并,例如:
“alertname: 告警名称 ”。Annotations(注释):注释是告警事件的附加描述,注释不属于元数据。例如:
“message: 告警内容”。StartsAt(告警开始时间):告警事件开始时间。
EndsAt(告警结束时间):告警事件结束时间。
GeneratorUrl(事件URL地址):告警事件URL地址。
标签(Labels)和注释(Annotations)的区别
一组标签共同决定了一个告警事件,当其中的一个标签发生变化时,将产生新的告警事件。
示例:
{ "hostname":"线上生产主机", "alertname":"CPU使用率过高","ip":"192.168.0.3"}这一组标签代表一个告警(主机192.168.0.3的CPU使用率过高)。当标签IP发生变化后,如{ "hostname":"线上生产主机", "alertname":"CPU使用率过高","ip":"192.168.0.4"},就会生成一个新的告警(主机192.168.0.4的CPU使用率过高)。注释的变化不会改变告警事件,一组标签相同注释不同的多条事件会被认为是一条事件多次上报。
示例:
注释
{"value":"85","message":"主机192.168.0.3 CPU使用率85%,超过阈值80%"}改变其中的内容不会产生新的告警,例如改变CPU使用率后{"value":"86","message":"主机192.168.0.3 CPU使用率86%,超过阈值80%"},两次事件上报的告警为同一条告警。
集成中可以配置去重字段,配置去重字段后这个集成上报的告警都会按照配置的去重字段作为标签来唯一确定一个告警事件。如果不配置去重字段默认会按照所有的标签来唯一确定一个告警事件。
告警事件管理
告警事件管理支持通过以下两种方式对告警源再加工:
通过事件处理流编排简单的处理流程,对任意告警源上报的告警事件进行再加工,以满足差异化的事件数据处理需求。
事件管理支持对任意告警源上报的告警事件去重、压缩、降噪、静默,从而收敛告警,减少告警风暴的产生。
事件压缩原理
告警事件管理默认会对事件进行2个层面的压缩,基于标签压缩和基于时间压缩,下面分别阐述压缩实现的原理。
基于标签压缩
满足条件的告警事件在通知时会按照通知策略中设置的分组策略进行压缩。根据分组策略中设置的标签,当满足条件的多条事件包含相同的标签时,将会自动压缩成一条告警进行通知。下图展示3个不同的事件,根据两种不同的压缩标签进行压缩的效果:

基于时间压缩
每个告警事件都包含告警开始时间和告警结束时间,标签相同的告警如果开始时间和结束时间有交集,则会合并为一个告警事件,且合并后的告警事件的开始时间和结束时间取这两个告警事件的并集。

通知策略管理
通知策略本质上是一种订阅规则,通过配置匹配规则,当满足条件的告警事件产生时会根据通知策略的配置进行通知。
事件处理流、事件管理和通知策略的关系如下图所示。

告警协同处理
告警协同处理模块支持多种协作策略的配置,您可以在阿里云控制台、钉钉、企业微信、飞书等工具中直接对告警进行处理。同时也支持群消息同步、排班管理、升级策略等功能,满足团队协同处理告警的需求。告警处理流程如下所示,具体操作,请参见在告警通知群中处理告警。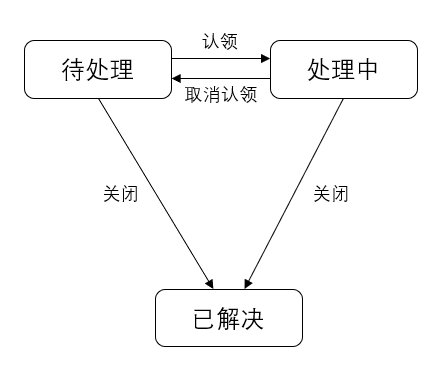
告警处理分析
告警处理分析模块通过记录和分析告警处理的过程,可以对单个告警进行复盘或者对过去一段时间内的告警进行处理分析,找出告警处理过程中的薄弱点,优化告警处理流程,提高处理效率。 与Grafana、Loki、Prometheus结合可以通过Grafana大盘实时查看已处理和未处理的告警,实现通过一个大盘全盘掌握系统告警处理状态。
默认支持丰富的SLO指标统计,通过告警接手率、平均接手时长、平均处理时长等指标来管理团队。通过丰富的标签能力多维度分析(如团队、应用、服务、环境)告警处理情况,满足大规模团队使用。更多信息,请参见通过ARMS告警大盘提高告警处理效率。
告警管理优势
当业务部署到阿里云并使用ARMS产品监控业务后,如果使用告警管理功能处理业务告警,ARMS告警管理能从以下几点来提升您的运维效率。
全球化。
告警规则模板全球化,一站式为全球事件配置告警。
联系人、通知策略全球化,一次配置全球生效。
集成事件后管理更高效。
告警管理默认支持一键化集成阿里云常见的监控工具,并支持更多的监控工具手动接入,方便统一维护。
事件接入模块稳定,能提供7×24小时的无间断事件处理服务。
处理海量事件数据时可以保证低延时。
及时准确地将告警通知给联系人。
配置通知规则,对事件合并后再发送告警通知,减少运维人员出现通知疲劳的情况。
根据告警的紧急程度选择邮件、短信、电话、钉钉等不同的通知方式,来提醒联系人处理告警。
通过升级通知对长时间没有处理的告警进行多次提醒,保证告警及时解决。
帮助您快速便捷地管理告警。
联系人能通过钉钉随时处理告警。
使用通用告警格式,联系人能更好地分析告警。
多个联系人通过钉钉协同处理。
统计告警数据,实时分析处理情况,改进告警处理效率。