
语音识别检测,可以直观的看到指定语音模型语音转文字的识别准确率,通过人工校验得到正确的文本标注结果,用来训练您的自定义模型;通过对比可以看到每次优化后的准确率提升情况,从而让您十分高效的提升语音转文字的识别准确率。提升识别准确率是一件非常重要的事情,因为识别准确率与质检规则命中率息息相关,识别准确率越高,您的规则的命中率就会越高。
识别准确率:指使用指定的语言模型进行语音转文字识别出的”文本内容”,经过人工校验后,正确的文本内容所占的比例即为识别准确率,即:正确文本内容/全部文本内容 * 100%,所以准确率通常指的是一个语言模型在某次语音转文字任务中的准确率,因为准确率并不是稳定不变的,相同的录音文件使用不同的语言模型进行转写,准确率也会有所差异。
新建任务
点击语音识别检测页面列表上方的 新建任务 按钮,按照页面提示填写任务名称,选择数据集,然后点击左下角的 转写并进行人工校验 按钮来提交任务。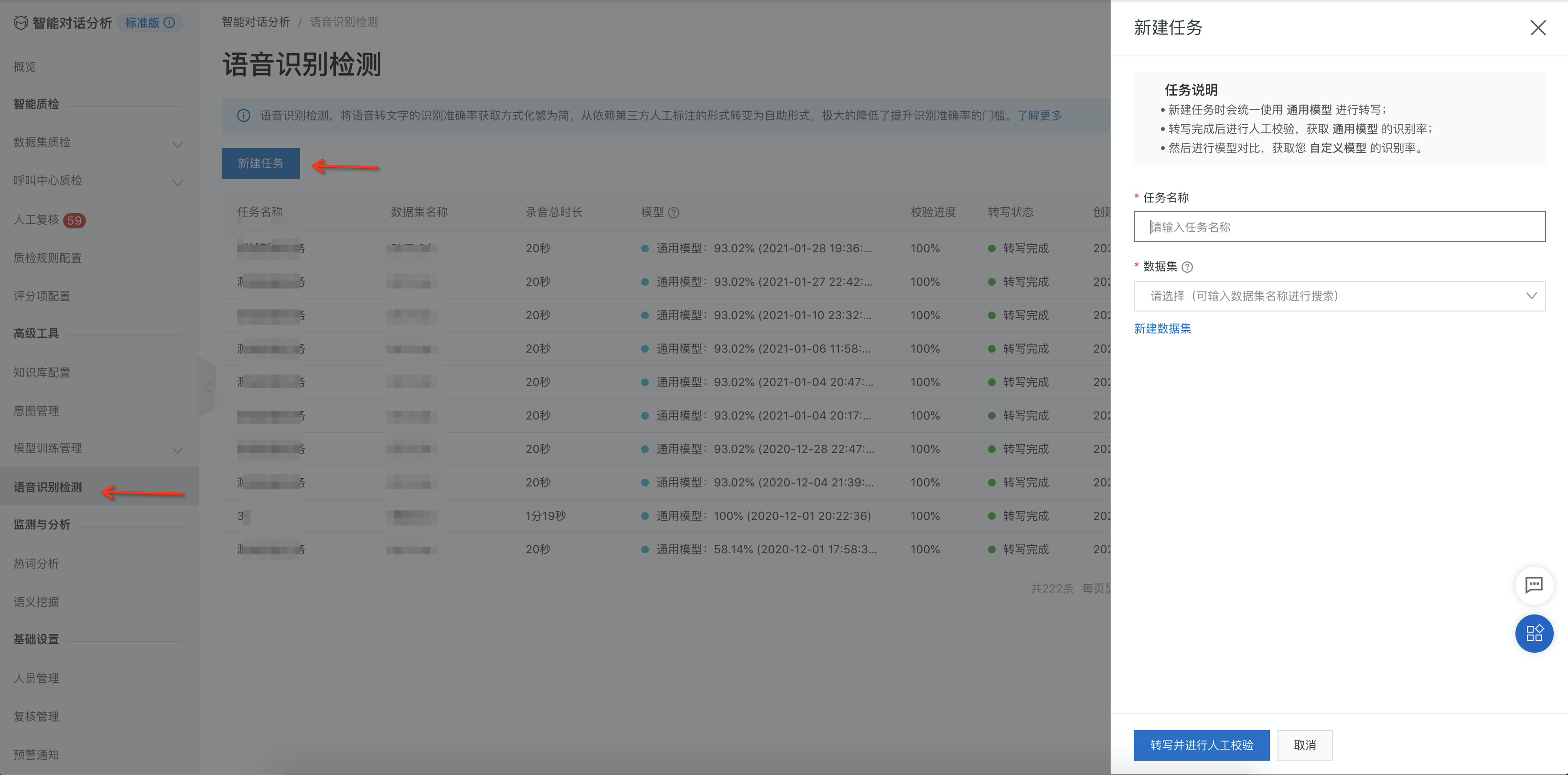
人工校验
任务执行完成后,进行人工校验,此时通用模型的准确率为100%,通过对每句话进行人工校验,也就是人工听取录音确认每句话转写的文本是否正确,校验时如果转写有误需要您填写正确的文本,这样一来,系统就可以根据转写正确的文字数量来计算通用模型在您提供的录音文件中真实的准确率。
1. 打开人工校验的文件
点击列表最右侧的 人工校验 按钮,新弹出的人工校验页面,与文件复核页面功能比较类似,如下图: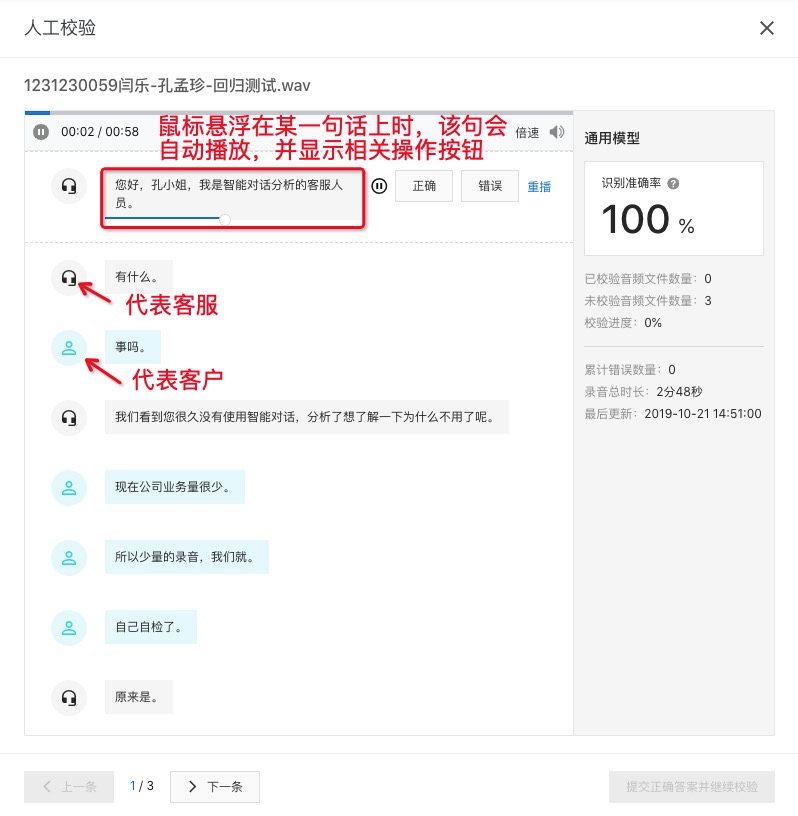
2. 人工校验过程说明
逐句进行人工校验,通过听取录音,判断转写是否存在错误:
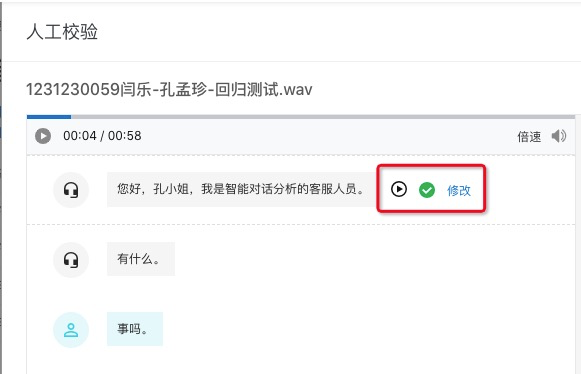
如果正确就点击 正确 按钮来确认,点击后该句校验完成,如下图:
如果错误,在点击 错误 按钮后,需要填写正确的文本以及正确的角色,如下图:
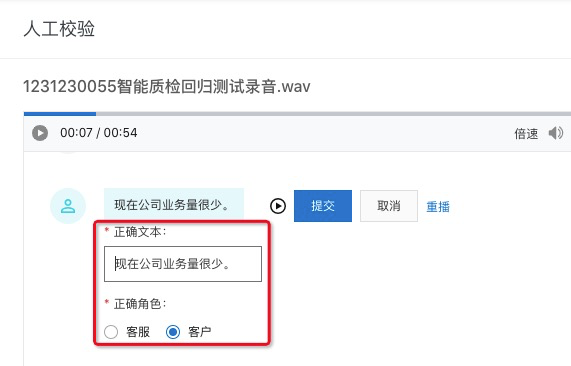
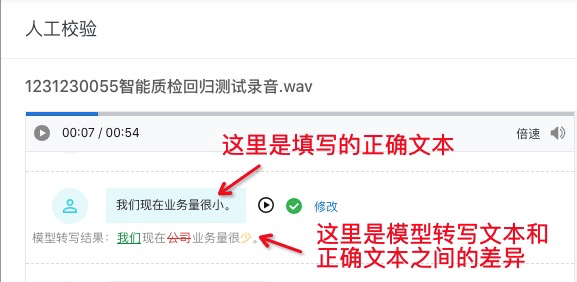
当文本错误时,填写正确的文本,提交后,效果如下图,其中模型转写文本与正确文本差异有以下三种情况:
绿色带下划线:少字,指模型转写时缺少的字,也就是您在正确文本中补充的字;
红色带删除线:多字,指模型转写时多出的字,也就是您在正确文本中将其删掉的字;
黄色:错字,指转写错误的字,也就是您再正确文本中进行修改的字;
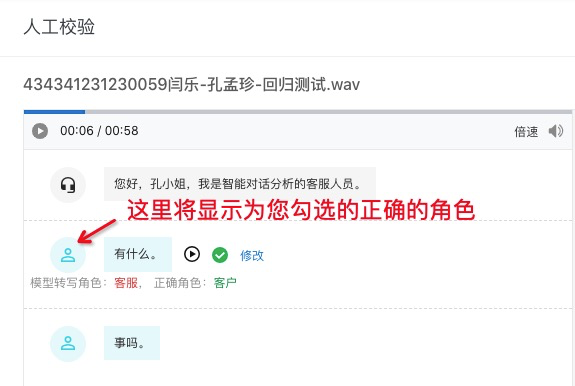
当角色错误时,选择正确的角色,提交后,效果如下图:

3. 校验进度提示
当存在未校验的句子时, 右下角的 提交 按钮是不可点击的,鼠标悬浮在提交按钮上时,会提示您当前校验进度,点击 跳转到未校验的句子 按钮,会自动跳转到当前未校验的句子,方便您查漏补缺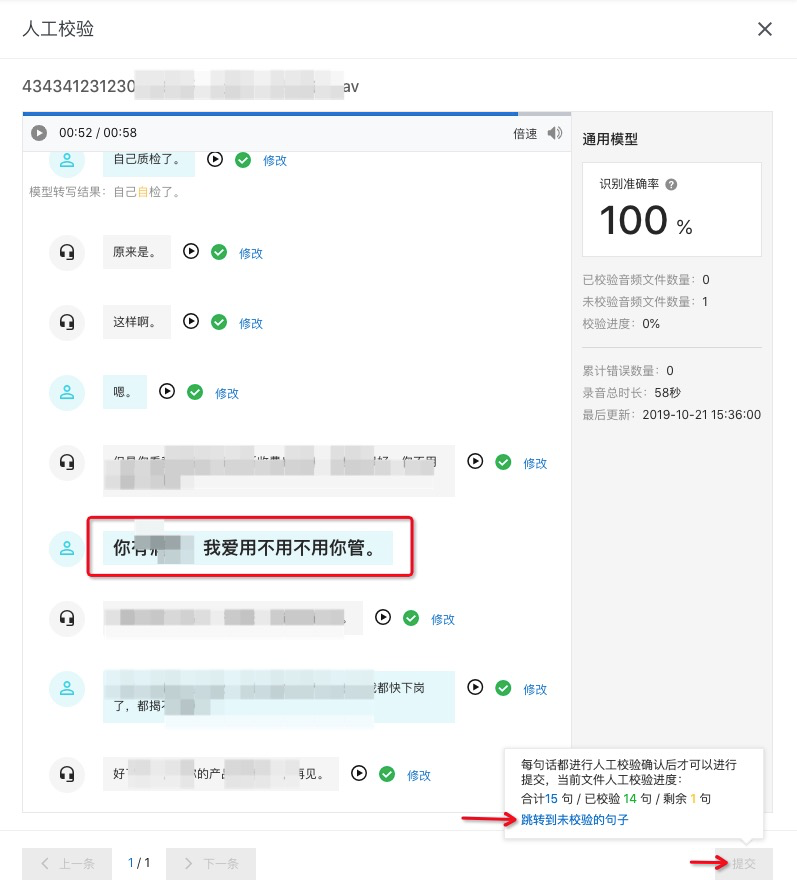
4. 提交
所有句子都校验完成后,点击提交按钮,会对当前文件进行提交,并且重新计算当前任务的识别准确率,可以查看任务列表中通用模型的识别率已经发生了变化: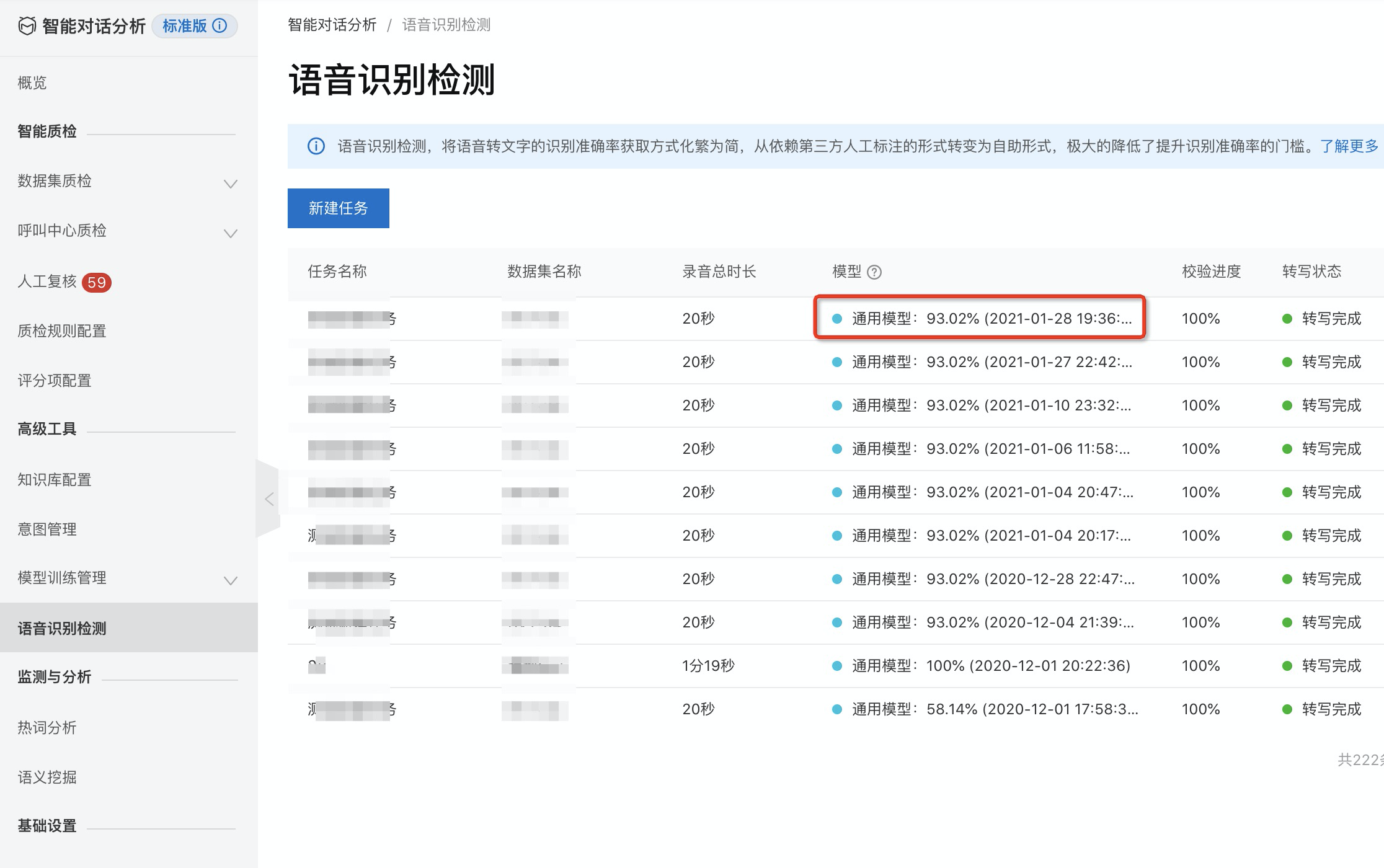
模型对比
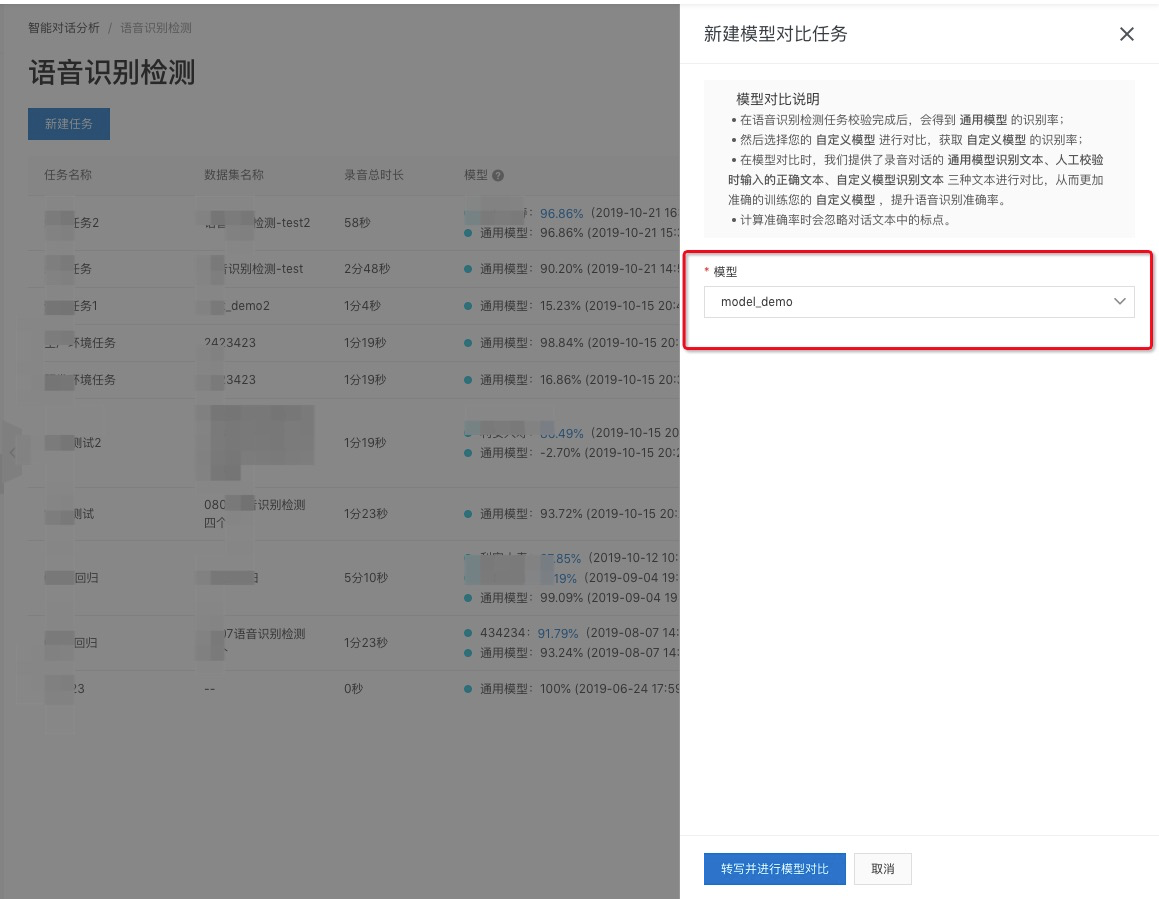
人工校验完毕,我们已经获得了通用模型真实的识别准确率,如果准确率较低,您可以训练自己的自定义语言模型,具体如何训练,请查看 语言模型,如果已经有了自定义语言模型,可以进行模型对比,查看自定义模型的识别准确率。
点击任务列表最右侧的 模型对比,选择您的自定义语言模型,然后提交任务
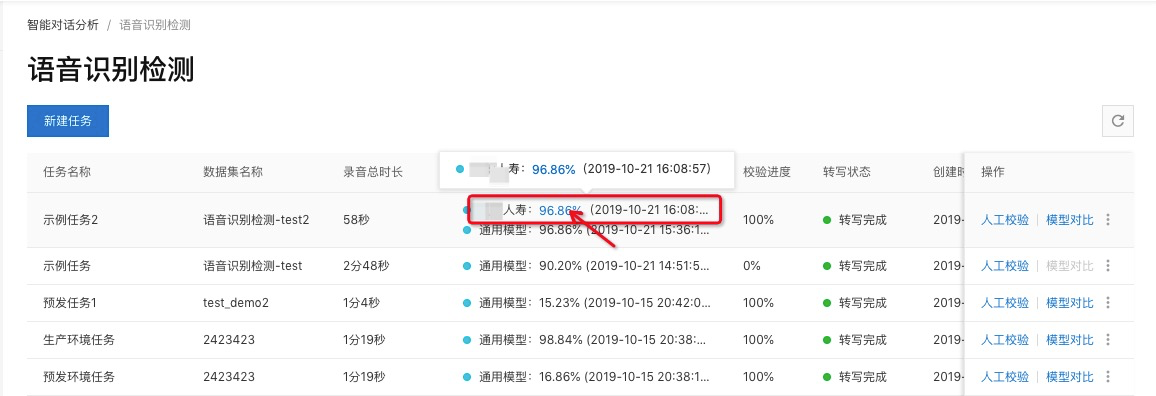
可以在任务列表中查看模型对比任务执行状态,执行完毕后会显示自定义模型的准确率,点击准确率,可以查看模型对比详情:
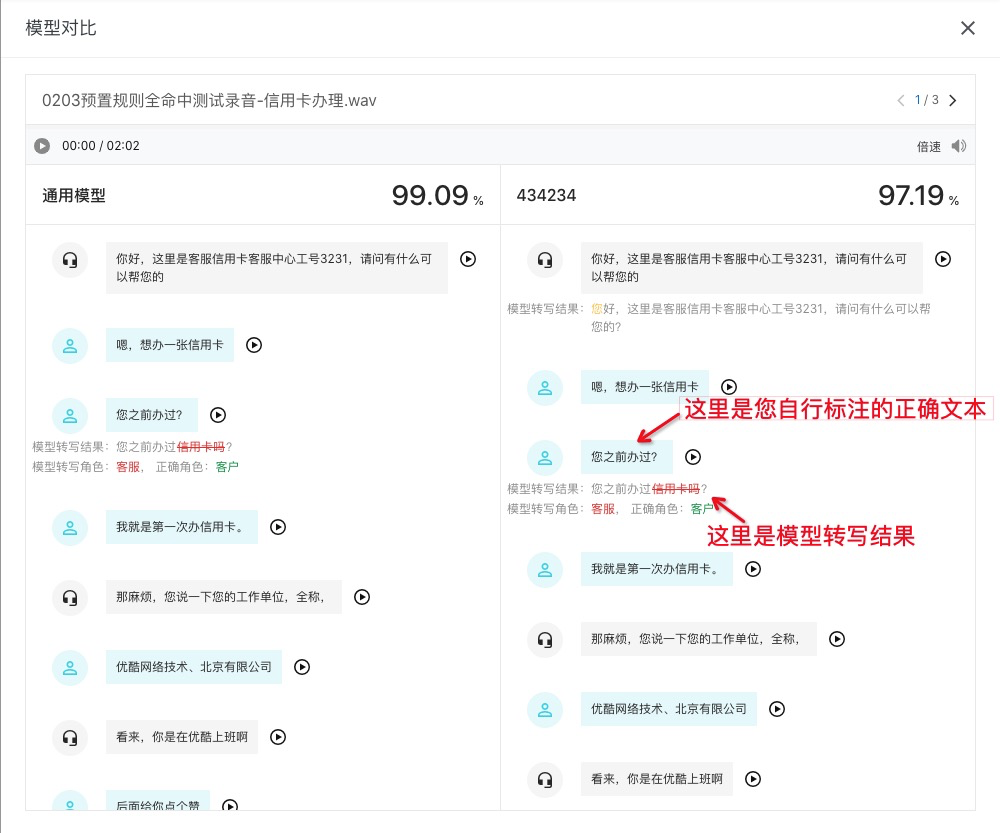
如下图,左右两侧分别为通用模型、自定义模型转写结果,查看自定义模型转写存在差异的地方,然后有针对性的增加更多的语料来训练对应的模型,进一步提升自定义模型的识别准确率。
提升模型准确率
每一个语音识别检测任务,在您进行人工校验后,可以下载您的标注结果,也就是正确的文本,这些文本是非常好的语言模型训练语料,您可以下载标注结果,然后手动训练指定的自定义模型,后期我们会上线自动训练功能。
模型训练完毕后,再次使用自定义模型执行模型对比,查看识别准确率提升情况。