
本文介绍如何使用Jaeger客户端对接日志服务。
背景信息
容器、Serverless编程方式提升了软件交付与部署的效率。在架构的演化过程中,可以看到以下变化。
应用架构从单体系统逐步转变为微服务,其中业务逻辑变为微服务之间的调用与请求。
资源角度来看,传统服务器这个物理单位逐渐淡化,变为了虚拟资源模式。
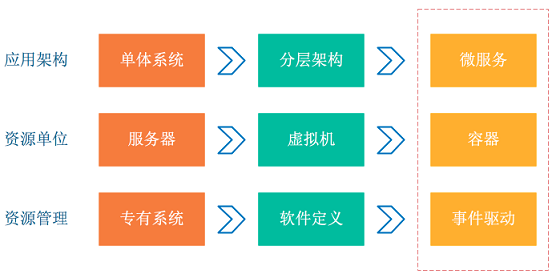
从以上两个变化可以看到这种弹性、标准化的架构背后,原本运维与诊断的需求也变得复杂。为应对这种变化趋势,诞生了一系列面向DevOps的诊断与分析系统,包括集中式日志系统(Logging)、集中式度量系统(Metrics)和分布式追踪系统(Tracing)。
除Jaeger外,阿里云还提供支持OpenTracing链路追踪产品XTrace。更多信息,请参见XTrace。
Logging,Metrics和Tracing的特点
Logging用于记录离散的事件
例如,应用程序的调试信息或错误信息,Logging是我们诊断问题的依据。
Metrics用于记录可聚合的数据
例如,队列的当前深度可被定义为一个度量值,在元素入队或出队时被更新;HTTP请求个数可被定义为一个计数器,新请求到来时进行累加。
Tracing用于记录请求范围内的信息
例如,一次远程方法调用的执行过程和耗时。Tracing是我们排查系统性能问题的利器。
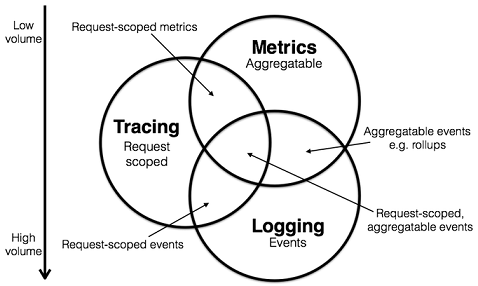
该图片来自于Peter Bourgon网站。
通过以上信息,可以对已有系统进行分类。例如,Zipkin专注于Tracing领域;Prometheus开始专注于Metrics,随着时间推移可能会集成更多的Tracing功能,但不太可能深入Logging领域;ELK、阿里云日志服务专注于Logging领域,但同时也不断地集成其他领域的特性到系统中来,正向上图中的圆心靠近。
更多三者关系详细信息请参见Peter Bourgon。下面为您重点介绍Tracing。
Tracing
流行的Tracing软件有:
Dapper(Google):各Tracer的基础
StackDriver Trace(Google)
Zipkin(Twitter)
Appdash(golang)
鹰眼(Taobao)
谛听(盘古,阿里云云产品使用的Trace系统)
云图(蚂蚁Trace系统)
sTrace(神马)
X-ray(AWS)
分布式追踪系统发展快,种类多,核心步骤一般有三个:
代码埋点
数据存储
查询展示
下图是一个分布式调用的例子,客户端发起请求,请求首先到达负载均衡器,接着经过认证服务,计费服务,然后请求资源,最后返回结果。 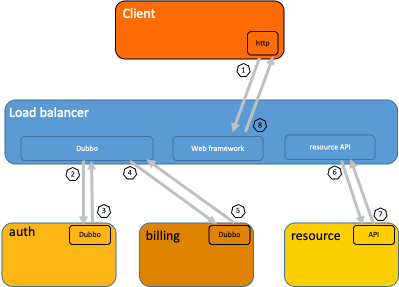 数据被采集存储后,分布式追踪系统一般会选择使用包含时间轴的时序图来呈现这个调用链。但在数据采集过程中,由于采集日志业务逻辑和用户代码深度融合,并且不同系统的API并不兼容,导致如果切换追踪系统,会有较大改动。
数据被采集存储后,分布式追踪系统一般会选择使用包含时间轴的时序图来呈现这个调用链。但在数据采集过程中,由于采集日志业务逻辑和用户代码深度融合,并且不同系统的API并不兼容,导致如果切换追踪系统,会有较大改动。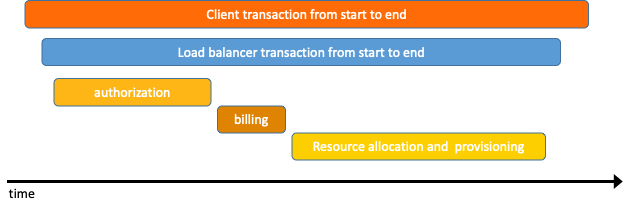
OpenTracing
为了解决不同的分布式追踪系统API不兼容的问题,诞生了OpenTracing规范。OpenTracing是一个轻量级的标准化层,它位于应用程序/类库和追踪或日志分析程序之间。更多信息,请参见OpenTracing。
OpenTracing优势:
OpenTracing已进入CNCF,为全球的分布式追踪,提供统一的概念和数据标准。
OpenTracing通过提供平台无关、厂商无关的API,使开发人员能够方便的添加或更换追踪系统。
OpenTracing数据模型:
OpenTracing中的Trace通过归属于此调用链的Span来隐性的定义。特别说明,一条Trace可以被认为是一个由多个Span组成的有向无环图(DAG图),Span与Span的关系被命名为References。如下示例,调用链就是由8个Span组成的。
单个 Trace 中,span 间的因果关系 [Span A] ←←←(the root span) | +------+------+ | | [Span B] [Span C] ←←←(Span C是Span A的孩子节点, ChildOf) | | [Span D] +---+-------+ | | [Span E] [Span F] >>> [Span G] >>> [Span H] ↑ ↑ ↑ (Span G在Span F后被调用, FollowsFrom)另外,基于时间轴的时序图可以更好的展现Trace,可以使用以下示例如下:
单个Trace中,span间的时间关系 ––|–––––––|–––––––|–––––––|–––––––|–––––––|–––––––|–––––––|–> time [Span A···················································] [Span B··············································] [Span D··········································] [Span C········································] [Span E·······] [Span F··] [Span G··] [Span H··]每个Span包含以下对象:
An operation name:操作名称。
A start timestamp:起始时间。
A finish timestamp:结束时间。
Span Tag:一组键值对构成的Span标签集合。键值对中,键必须为string,值可以是字符串、布尔、或者数字类型。
Span Log:一组span的日志集合。每次log操作包含一个键值对,以及一个时间戳。键值对中,键类型必须为string,值可以是任意类型。不是所有的支持OpenTracing的Tracer,都需要支持所有的值类型。
SpanContext:Span上下文对象。每个SpanContext包含以下状态:
任何一个OpenTracing的实现,都需要将当前调用链的状态(例如:Trace和Span的ID),依赖一个独特的Span去跨进程边界传输。
Baggage Items是Trace的随行数据,是一个键值对集合,存在于Trace中,也需要跨进程边界传输。
References(Span间关系):相关的零个或者多个Span(Span间通过SpanContext建立这种关系)。
更多关于OpenTracing数据模型的知识,请参见OpenTracing数据模型。
关于所有的OpenTracing实现,请参见OpenTracing。在这些实现中,比较流行的为Jaeger和Zipkin。更多信息,请参见Jaeger和Zipkin。
Jaeger
Jaeger是Uber推出的一款开源分布式追踪系统,兼容OpenTracing API。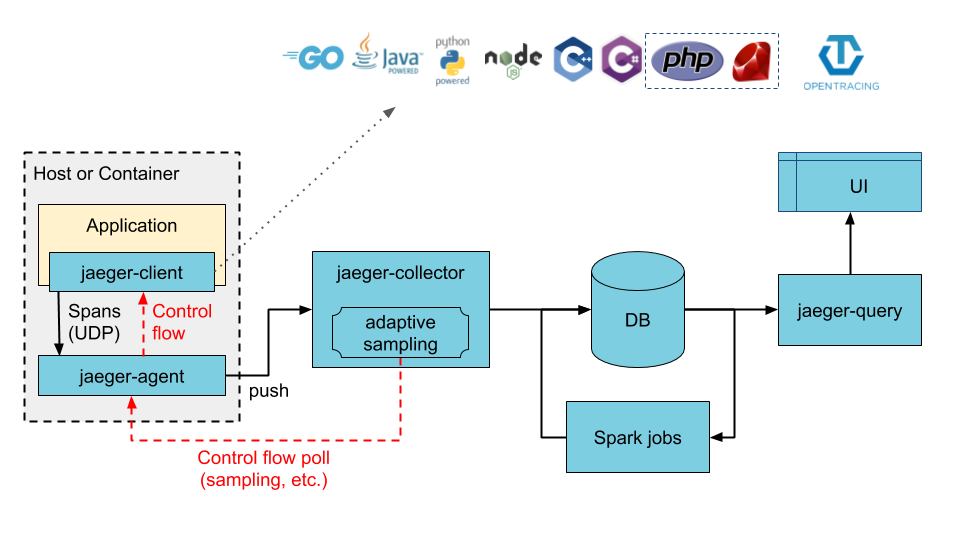
该图片来自于JAEGER网站。
如上图所示,Jaeger主要由以下几部分组成。
Jaeger Client:为不同语言实现了符合OpenTracing标准的SDK。应用程序通过API写入数据,client library把Trace信息按照应用程序指定的采样策略传递给jaeger-agent。
Agent:它是一个监听在UDP端口上接收span数据的网络守护进程,它会将数据批量发送给collector。它被设计成一个基础组件,部署到所有的宿主机上。Agent将client library和collector解耦,为client library屏蔽了路由和发现collector的细节。
Collector:接收jaeger-agent发送来的数据,然后将数据写入后端存储。Collector被设计成无状态的组件,因此您可以同时运行任意数量的jaeger-collector。
Data Store:后端存储被设计成一个可插拔的组件,支持将数据写入cassandra、elastic search。
Query:接收查询请求,然后从后端存储系统中检索Trace并通过UI进行展示。Query是无状态的,您可以启动多个实例,把它们部署在Nginx负载均衡器后面。
Jaeger on Alibaba Cloud Log Service
Jaeger on Alibaba Cloud Log Service是基于Jaeger开发的分布式追踪系统,支持将采集到的追踪数据持久化到日志服务中,并通过Jaeger的原生接口进行查询和展示。 更多信息,请参见Jaeger on Alibaba Cloud Log Service。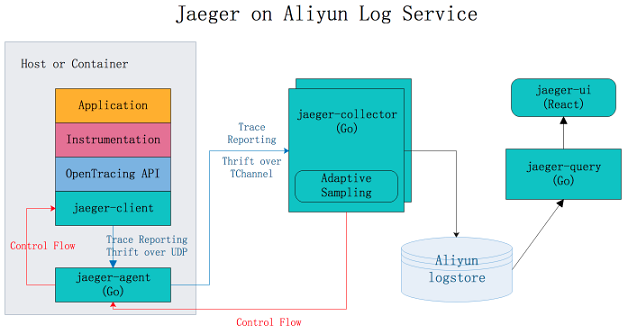
Jaeger的优势:
原生Jaeger仅支持将数据持久化到cassandra和Elasticsearch中,您需要自行维护后端存储系统的稳定性,调节存储容量。Jaeger on Alibaba Cloud Log Service借助阿里云日志服务的海量数据处理能力,让您享受Jaeger在分布式追踪领域给您带来便捷的同时无需过多关注后端存储系统的问题。
Jaeger UI部分仅提供查询、展示Trace的功能,对分析问题、排查问题支持不足。使用Jaeger on Alibaba Cloud Log Service,您可以借助日志服务强大的查询分析能力,助您更快分析出系统中存在的问题。
Jaeger on Alibaba Cloud Log Service配置步骤请参见GitHub。
Jaeger配置示例
HotROD是由多个微服务组成的应用程序,它使用了OpenTracing API记录Trace信息。
下面通过一段视频向您展示如何使用Jaeger on Alibaba Cloud Log Service诊断HotROD出现的问题。视频包含以下内容:
配置日志服务
通过docker-compose运行Jaeger。
运行HotROD。
通过Jaeger UI检索特定的Trace。
通过Jaeger UI查看Trace的详细信息。
通过Jaeger UI定位应用的性能瓶颈。
通过日志服务管理控制台,定位应用的性能瓶颈。
应用程序调用OpenTracing API。
示例中使用的query语句及其含义如下:
以分钟为单位统计frontend服务的HTTP GET/dispatch操作的平均延迟以及请求个数。
process.serviceName: "frontend" and operationName: "HTTP GET /dispatch" | select from_unixtime( __time__ - __time__ % 60) as time, truncate(avg(duration)/1000/1000) as avg_duration_ms, count(1) as count group by __time__ - __time__ % 60 order by time desc limit 60比较两条Trace各个操作的耗时。
TraceID: "Trace1" or TraceID: "Trace2" | select operationName, (max(duration)-min(duration))/1000/1000 as duration_diff_ms group by operationName order by duration_diff_ms desc统计延迟大于1.5 s的Trace的IP情况。
process.serviceName: "frontend" and operationName: "HTTP GET /dispatch" and duration > 1500000000 | select "process.tags.ip" as IP, truncate(avg(duration)/1000/1000) as avg_duration_ms, count(1) as count group by "process.tags.ip"