
本文介绍如何利用阿里云日志服务(SLS)接入中心,一键完成 OpenClaw AI Agent 的日志接入,配合内置审计大盘与观测大盘,实现开箱即用的安全审计与运维观测闭环。
背景信息
OpenClaw 安全风险:为何受控运行至关重要
OpenClaw 是 2026 年最受关注的开源 AI Agent 平台之一。它允许大语言模型直接操作文件系统、执行 Shell 命令、浏览网页、收发消息——将 LLM 的推理能力转化为真实的系统操作。这种"自主执行"能力是其核心价值,也是其核心风险。
行业安全事件:风险不是假设,而是事实
2026 年初,多家安全厂商集中披露了一批 OpenClaw 相关漏洞和事件,数据如下:
来源
发现
安全研究统计
公网可访问的 OpenClaw 实例达 4 万余个,覆盖多国;其中 约 1.5 万个 未打补丁或采用默认配置,存在远程控制风险;约 93% 的暴露实例 存在严重认证绕过类漏洞。
GitHub 安全公告
(GHSA-g8p2-7wf7-98mq)
Control UI 信任 URL 参数中的 gatewayUrl 且自动连接,用户点击恶意链接即可导致网关 Token 被窃取并发送至攻击者服务器,进而 一键实现 RCE(CVSS 8.8),即使网关仅监听本机亦然;v2026.1.29 已修复。
Skills 供应链
OpenClaw Skills 注册表中发现 800+ 恶意 Skills(约占已发布包的两成),包括窃取凭证、植入后门等;安装未审核技能等同于放大 Agent 权限。
Unit 42 等研究
间接提示注入(IDPI) 已在真实场景中被观测:攻击者将隐藏指令嵌入网页内容,Agent 抓取后误执行,导致数据外泄或越权操作。
监管与预警
多国监管机构关注 AI 智能体风险;工信部发布《关于防范 OpenClaw 开源 AI 智能体安全风险的预警提示》,建议及时更新并进行安全加固。
代码审计数据:OpenClaw 自身的安全修复频率
行业报告说明了外部威胁态势。而对 OpenClaw 自身代码仓库的审计则揭示了另一个维度——项目本身在高频修复安全问题。通过基于 Git 历史与 commit message 的安全语义分析,可以量化一段时间内与安全相关的代码变更规模与分布,从而判断攻击面集中在哪些层次。
对 OpenClaw近期 commits 进行筛选与分类,发现风险高度集中在入口与执行层:
模块
安全修复数
占比
主要风险
src/tools/52
35%
命令注入、路径遍历
src/gateway/38
26%
权限控制、认证授权
src/auth/18
12%
认证绕过、CSRF
src/sandbox/15
10%
路径遍历、SSRF
src/hooks/12
8%
Prompt 注入、信息泄露
而工具执行层(
tools/)与入口网关层(gateway/)正是“自主操作”与“多入口接入”的代价所在;静态代码审计只能覆盖已提交的变更,无法穷尽运行时的行为变异、配置组合与外部输入驱动的攻击路径。为什么仅靠运行时防护不够
OpenClaw 的架构在正常配置下能有效缩小攻击面,但从安全工程角度看,属于同一信任域内的执行时校验,存在以下几类固有局限:
防护层
机制与能力
固有局限
工具策略(Tool Policy Pipeline)
在工具调用前按策略(如按发送方、按通道、按工具名)决定允许/拒绝或需人工审批;支持 ACP 审批流。
策略误配、规则遗漏或策略绕过(如通过合法工具链间接达成高危效果)可导致越权执行;策略变更后缺乏独立审计,难以事后归因。
循环检测(Stuck/Loop Detection)
检测会话在若干轮内无实质性进展(如无新 user/assistant 消息、仅重复工具调用),触发告警或终止。
仅能识别“无进展”的循环,无法识别“逻辑自洽但结果灾难”的多步操作链(如逐步诱导删除、外泄);误报/漏报依赖阈值调参。
命令 allowlist/denylist
对
exec、shell等工具的可执行命令做白名单或黑名单过滤,减少任意命令执行。混淆或编码后的命令(如 base64 解码执行、别名/换行拼接)历史上曾绕过过滤,已有相应 CVE 与修复;名单维护滞后于新攻击手法。
上下文与安全指令
通过 System Prompt 等注入“禁止做 X”“需审批再做 Y”等约束,依赖模型遵守。
长对话下上下文窗口压缩、摘要或截断可能导致关键安全指令被稀释或“遗忘”;对抗性输入可尝试覆盖或弱化约束(Prompt Injection)。
因此,运行时防护相当于“城墙”——能挡住绝大多数已知攻击路径,但无法保证配置永不出错、也无法覆盖未知绕过与逻辑性误用。 在安全架构上,需要与之互补的“哨兵”对 Agent 的调用方、消耗、工具调用序列与结果做持续可观测与审计。
方案介绍
可观测性正是处于“哨兵”的位置:用日志、指标与链路数据对 Agent 行为持续观测,支撑审计追溯与使用合规,并借助异常检测回答“谁在调、花了多少、具体做了什么”,在策略失效或遭遇新型攻击时及早发现并在影响扩大前响应。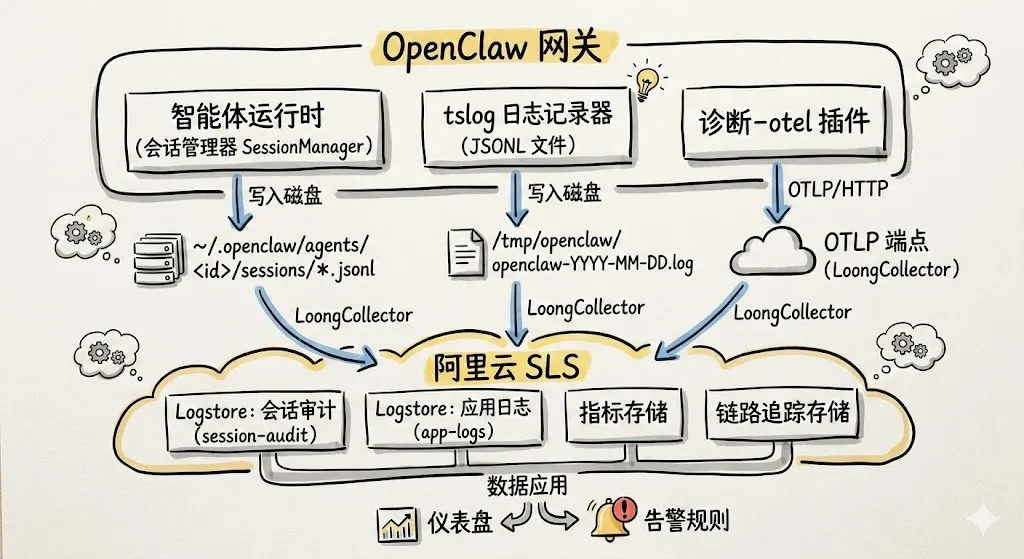
可观测三支柱在 AI Agent 下的映射
可观测性建立在 Logs + Metrics + Traces 三支柱之上,在 OpenClaw 场景下,三者与数据源的对应关系及各自要回答的核心问题如下:
支柱 | OpenClaw 数据源 | 回答的核心问题 |
Logs(Session 审计日志) |
| Agent 做了什么?调用了哪些工具?消耗了多少 Token、多少成本? |
Logs(应用运行日志) |
| 系统哪里出了问题?Webhook 失败、认证被拒、网关异常? |
Metrics |
| 当前成本与延迟是否正常?有无会话卡死、异常重试? |
Traces |
| 单条消息从接收到完整响应经历了哪些步骤?调用链如何串起? |
三支柱缺一不可:仅有 Metrics 无法回答“谁、因何”导致成本飙升;仅有 Session 日志无法从全局感知系统健康与异常拐点;仅有应用运行日志则看不到 Agent 的业务行为与工具调用序列。三者协同才能同时支撑安全审计、成本管控与运维排障。
阿里云 SLS 能力与优势
SLS 作为可观测领域的基础底座,在 OpenClaw 场景具有以下天然优势:
强大的数据接入能力,与 OpenClaw 技术栈原生对齐
LoongCollector 具备强大的 OneAgent 采集能力,对日志与 OTLP 协议均有原生支持。Agent Session 日志因承载模型交互上下文而往往较长,LoongCollector 提供针对长文本日志的高性能采集能力;与 OpenClaw 内置的
diagnostics-otel插件零改造对接,Metrics 与 Traces 经 OTLP 直接写入 SLS。查询分析与处理算子丰富
Session 日志为 JSON 嵌套格式(如
message.content、message.usage.cost、message.toolName),SLS 提供 SQL + SPL 计算引擎及丰富的解析、过滤、聚合算子,可对嵌套字段做索引与实时分析,无需额外 ETL 处理。安全与合规能力
RAM 权限管控、敏感数据脱敏与加密存储,满足审计留痕与合规要求;SLS 持有网络安全专用产品安全检测/认证证书(原安全专用产品销售许可证),便于在等保与行业合规场景下作为可观测与审计底座使用。告警通道支持钉钉、短信、邮件等,便于安全事件与成本/异常告警的及时触达与响应。
全托管、按量计费与弹性伸缩
日志分析一站式:“采集 → 存储 → 索引 → 查询 → 仪表盘 → 告警”,依靠LogStore / MetricStore 全托管。小规模 Agent 日志量不大、按量计费成本低;流量增加也能自动弹性,无需预留容量与手动扩容,无需自建 Elasticsearch、Prometheus 等。
因此 SLS 在对接 OpenClaw 可观测数据,支撑审计 + 成本 + 异常检测 + 安全合规 + 运维等多场景下,适合作为 OpenClaw 受控运行的可观测与审计底座。
当前 SLS 推出 OpenClaw 一站式接入方案:
通过接入中心向导式配置采集路径与解析方式,自动生成并下发生效,实现 Session 日志、应用日志与 OTLP 遥测的统一入口、统一 Project。一站式接入,显著降低多数据源割裂带来的复杂度与运维成本。
一份 Session 数据既可做安全审计,也可做成本与行为分析,满足多场景复用。
预置的审计大盘、成本大盘与运行指标大盘实现开箱即用的受控运行观测闭环。
操作步骤
步骤一:日志接入(以 Session 日志为例)
Session 日志是安全审计的核心数据源,记录了每一轮对话、每一次工具调用、每一笔 Token 消耗。
前置准备
已创建Project(如
openclaw-observability)且已创建LogStore。确保 OpenClaw 所在 ECS / 自建服务器已安装LoongCollector。
接入流程
登录日志服务控制台,选择右侧的快速接入数据并选择接入卡片,选择OpenClaw-会话日志,选择目标Project与LogStore。
在机器组配置下的源机器组列表中选择安装LoongCollector时创建的机器组添加到应用机器组列表中。
若机器组心跳异常请参考心跳异常问题汇总排查。
在Logtail配置页,日志服务已自动填充内置的采集配置,若无需修改可直接单击下一步。
配置名称已默认配置。可按需修改。
其他全局配置下的日志主题类型已默认配置。
关于日志主题类型:LoongCollector支持从文件路径中自动提取topic和session_id,如文件路径经过自定义与预填不匹配需要自行调整。
文件路径已默认自动填充。
关于文本文件路径:预填的文件路径是假设用户在Linux主机使用非root用户默认安装的路径,如与实际情况不符,请注意修改。
处理模式中默认配置了处理插件组合。
关于时间解析:OpenClaw默认输出日志中的时区为0时区,如进行过自定义,请同步修改时间解析插件中的时区,避免时间错配。
在查询分析配置页,日志服务会自动生成内置索引与报表。后续可在查询分析与仪表盘中查看。
内置索引如下:

仪表盘如下:
OpenClaw 行为分析大盘
OpenClaw 审计大盘
OpenClaw 指标大盘
OpenClaw Token 分析大盘
步骤二:审计与观测
SLS 为 OpenClaw 提供了预置的仪表盘,覆盖安全审计、成本分析、行为分析、运行指标四个维度。
登录日志服务控制台,在Project列表中选择目标Project。
在日志存储中目标LogStore中通过查询 / 分析进行接入验证与日志格式校验。
在仪表盘中查看预置仪表盘。
安全审计大盘
Agent 的行为透明度直接关联系统安全与合规风险,且异常行为往往在造成实际损害之前已有迹可循。安全审计大盘是 OpenClaw 受控运行的核心看板,聚焦于回答"Agent 在做什么、有没有高危动作、谁在执行越界操作"这一核心问题,从行为总览、高危命令、提示词注入、数据外泄等维度展开,提供实时行为监控、威胁识别与事后溯源的完整能力。
安全审计统计概览页:
以指定时间窗口内的多维高危操作计数为核心,将 OpenClaw 的安全态势压缩为一屏可读的风险快照。高危命令执行、网页请求外发、命令行外发、通信工具外发、敏感文件访问、提示词注入等七项指标并列呈现,配合环比数据,帮助安全团队在无需深入明细的情况下快速判断当前风险水位是否异常。
尤为值得关注的是提示词注入事件后的高危操作计数。普通高危操作可能源于任务本身的合理需求,而注入后触发的高危行为则是强烈的威胁信号,这意味着注入的恶意指令已驱动 Agent 付诸执行。即便存在误判,此类信号也应触发最高级别的人工复核,而非等待进一步确认。因此,"注入后工具调用的会话数"是整个总览中威胁置信度最高的信号,3 个此类会话的优先级往往高于数百次普通高危命令。
高风险会话表以 Session 为单位聚合各维度风险计数,通过综合风险评分自动排序,将最需要人工介入的会话置顶呈现。安全团队无需逐条筛查日志,直接从风险最高的 Session 开始溯源,大幅压缩从发现到响应的时间窗口。
Skills 使用分析
Skills 使用分析从攻击面视角审视 OpenClaw 的能力边界。Skills 是 OpenClaw 的原生能力扩展机制,也是恶意提示词注入的主要攻击入口,使用者往往在不经意间安装了存在安全漏洞或内嵌恶意指令的 Skill,为攻击者提供了可操控的能力入口。因此,Skills 的调用分布并非单纯的使用统计,更是攻击路径分析的重要依据。
使用分布饼图帮助安全团队快速建立 Skills 调用的基线认知:哪些 Skills 属于高频主流调用,哪些属于边缘低频。一旦某个非常见 Skills 的占比突然上升,或出现从未见过的新 Skills,往往意味着 Agent 正在被引导至非预期的能力路径,需要及时介入排查。
新增 Skills 表格中内容尤为关键。新引入的 Skills 尚未经过充分的安全评估,其权限边界与行为模式对安全团队而言仍是盲区。按首次调用时间逆序排列,可第一时间捕获环境中新出现的 Skills,在其被滥用之前完成审查。
高危命令调用监控
OpenClaw 的创新能力之一是自主执行系统命令,这也使其成为攻击者的理想跳板。一旦 Agent 遭受提示词注入或被恶意 Skill 操控,攻击者即可借助 Agent 的系统访问权限执行删除文件、提升权限、渗出数据等破坏性操作,且全程以 Agent 身份发起,极难与正常任务行为区分。
高危命令调用监控的核心价值在于在运行时防护之外建立独立的可观测层。OpenClaw 的工具权限体系已在运行时层面实施管控,但策略配置错误、权限边界界定模糊或未覆盖的边缘场景,都可能导致高危命令在运行时层面悄然通过。可观测层独立于防护机制运行,确保即便运行时出现疏漏,高危操作也不会彻底失察。
时间线视图的意义不只是计数,而是帮助安全团队识别行为模式。孤立的单次高危命令与短时间内的密集调用,风险含义截然不同。后者往往是 Agent 被操控后系统性执行恶意指令的典型特征,需要立即介入。明细表则提供完整的溯源上下文,支持安全团队从异常信号快速追溯到具体会话与原始命令。
提示词注入检测
提示词注入是驱动 AI 执行有害行为的核心攻击手段。无论攻击路径如何,用户直接输入、Skills 调用返回还是
web_fetch、read等工具读取的外部数据,恶意指令终究需要汇入提示词才能对 Agent 施加影响。提示词是所有攻击路径的最终汇聚点。注入来源的分布可以帮助判断实际风险的性质。用户直接输入的注入通常是有意为之,而通过
toolResult携带的注入,用户往往并不知情。对于 OpenClaw 这类个人助理型 Agent,间接注入才是主要威胁——用户安装的 Skills 或访问的外部内容均可能成为注入载体,且难以被用户主动识别和规避。注入分类的价值在于识别攻击意图,而不只是标记异常。同样是注入事件,
ROLE_HIJACK和JAILBREAK意味着攻击者在试图突破 Agent 的行为边界,HIDDEN_INSTRUCTION则代表更隐蔽的植入手法,这些类型的响应优先级和处置方式各不相同。持续观察分类分布的变化,也有助于发现针对特定攻击面的集中尝试。明细表记录每条注入事件的触发工具、会话上下文与原始内容,支持安全团队从分类统计快速下钻至具体事件,完成从模式识别到溯源响应的完整闭环。
敏感数据外泄检测
数据外泄在 Agent 场景下往往不是单一事件,而是一条由多个步骤构成的行为链:Agent 被引导读取敏感文件、内容进入模型上下文、再通过后续工具调用完成外传。单独观察任意一个环节都难以判断威胁,只有将文件访问与外发行为关联起来,才能还原攻击的完整意图。
敏感数据外泄检测采用漏斗式分析思路,逐层收窄噪声,精准定位真实威胁。第一层对敏感文件访问进行全量记录,按 SSH_KEY、ENV_FILE、CREDENTIALS、CONFIG_SECRET、HISTORY 五类资产分类,建立访问基线。第二层对外发行为按渠道(API_CALL、MESSAGE_SEND、WEB_ACCESS、EMAIL)独立追踪,识别潜在的数据出口。第三层将两者在时间维度上关联,若同一 Session 内敏感文件访问与外发操作在短时间窗口内相继出现,则标记为高优先级渗出事件。
这一机制的核心价值在于因果定位而非单点告警。Agent 读取 SSH_KEY 不一定是威胁,发起 API_CALL 也不一定是威胁,但两者在同一 Session 内以分钟级间隔先后发生,且外发参数中携带敏感文件内容,威胁置信度则大幅提升。行为链分析表直接呈现 access_time 与 outbound_time 的时间差及完整的调用参数,让安全团队无需手动关联日志即可完成溯源判断。
Token 分析大盘
Token 消耗直接关联运营成本,且其波动往往是系统异常(如 Prompt 注入导致上下文膨胀等)的早期信号。Token 分析大盘围绕“钱花在哪了、花得是否合理、有没有异常”这一核心问题,从整体概览、模型维度趋势、会话等维度展开,提供用量监控、成本分析与异常发现能力。
关于费用数据:大盘中的费用(
cost)字段来自 OpenClaw 的usage.cost,OpenClaw 原生不支持阶梯计费,且cacheRead + cacheWrite计算逻辑与供应商无法保持一致,仅按inputTokens × input + outputTokens × output + ...估算单次调用费用。因此大盘费用应视为成本估算的参考基线,而非精确账单。未配置cost的模型,费用列将显示为 0。以千问3.5-Plus模型为例,百炼API调用的费用见模型列表。
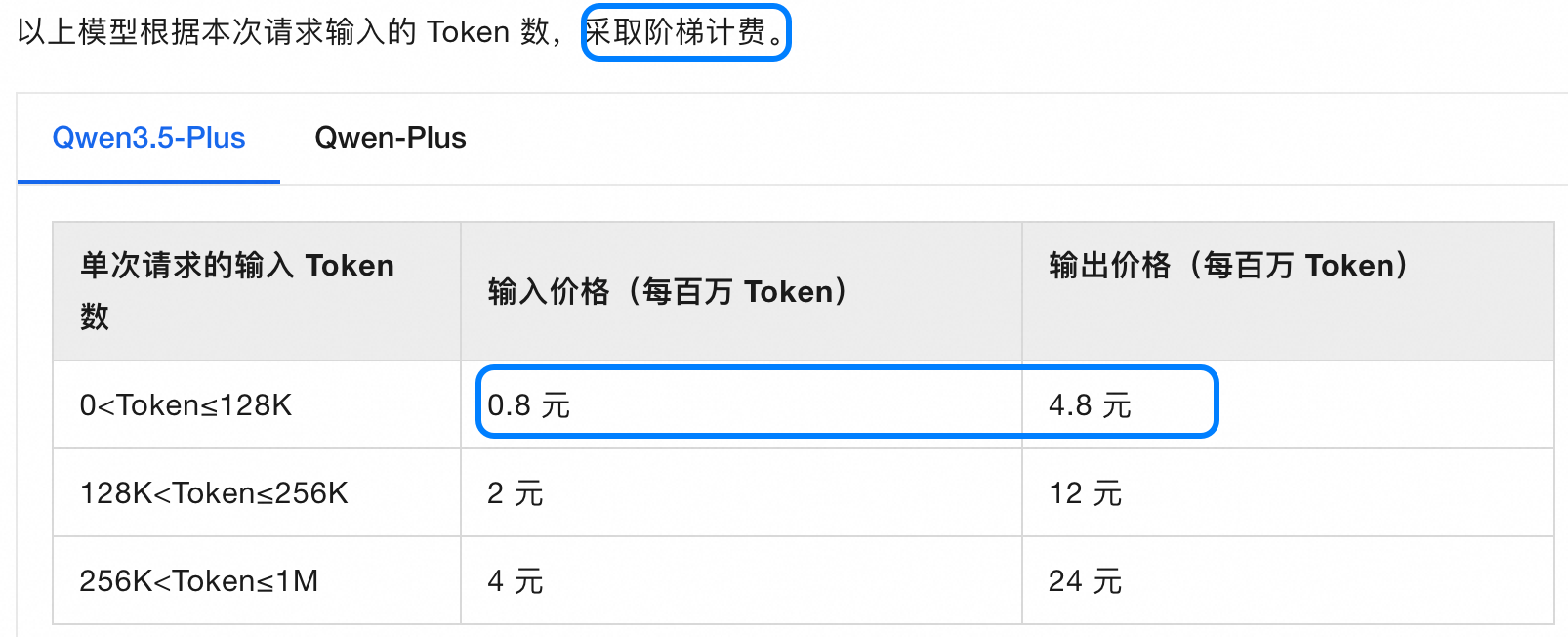
.openclaw中模型成本的配置为:
{ "id": "qwen3.5-plus", "name": "Qwen3.5 Plus", "cost": { "input": 0.8, // 取自最低阶梯输入价格 "output": 4.8, // 取自最低阶梯输出价格 "cacheRead": 0.4, // 取input一半进行估算 "cacheWrite": 0 }, }整体概览与模型分布
大盘顶部提供整体 Tokens与整体费用的 1 天对比:今日 vs 昨日用量(单位:万 tokens)、今日 vs 昨日费用(单位:元),以及环比比例,便于快速判断当日是否出现用量或费用突增。环比是成本异常的第一道信号——若日环比突破预设阈值(如 ±30%),通常意味着出现了 Prompt 膨胀、循环调用或异常会话,应立即下钻排查。
按 Provider / Model 的消耗趋势(时序)
模型 Tokens 趋势与模型费用趋势两条时序图(1 周相对)共享时间轴与图例,按模型分色展示各模型在时间维度上的 Token 消耗与费用变化。需要重点关注的是 Token 激增——这往往不只是成本问题,更可能是安全与稳定性的风险信号:Prompt 注入导致上下文被恶意填充、工具调用陷入死循环、或会话因未触发循环检测而持续膨胀,都会在趋势图上表现为某条曲线的陡峭上升。两张图按模型分色呈现,模型切换会直接反映为颜色构成的变化,无需额外推断即可确认切换时间点与涉及模型,便于判断是否为预期变更。
按会话与按主机/Pod 的 Top 消耗(柱状图)
柱状图构成 2×2 布局,从会话与主机(或 Pod,容器场景)维度回答"谁在花钱、哪台机器或容器在花钱",与具体的责任主体相关联:
Top Tokens By Session / Top Cost By Session:过去 1 周各会话的 Token 合计与费用按降序排列。实践中 Agent 的成本分布往往呈长尾特征——少数会话占据绝大部分消耗,识别这些"头部会话"是成本优化的第一步。
Top Tokens By Host / Top Cost By Host:按主机(实例)或 Pod 聚合的 Token 与费用,用于多实例部署下的成本分析与风险定位。在企业环境中,主机或 Pod 通常与特定团队、业务线或用户绑定,结合资产归属即可将消耗数据映射到具体责任方——既能支撑成本分摊,也能在某台实例消耗异常时快速锁定潜在的风险使用者或失控会话。
模型 Tokens 详情表(成本明细)
详情表(1 周相对)按模型列出:
totalTokens、inputTokens、outputTokens、cacheReadTokens、cacheWriteTokens,以及对应的totalCost、inputCost、outputCost、cacheReadCost、cacheWriteCost。支持排序与筛选,可直接回答"哪个模型花了最多钱、输入/输出各占多少"。其中inputTokens与outputTokens的比值反映 Agent 的交互模式:输入占比过高说明 Prompt 或上下文冗余,输出占比过高则可能是模型生成了大量无效内容;cacheReadTokens占比则直观体现缓存策略的收益——占比越高、实际计费越低,为 Prompt 工程与缓存调优提供量化依据。
行为分析大盘
行为分析大盘以会话为基本单位,对 OpenClaw 的运行行为进行全量记录与分类统计,回答"Agent 在当前时间窗口内做了什么"这一基础但关键的问题。
会话统计
顶部计数卡片将工具调用按行为类型拆解为命令执行、后台进程、网页请求、通信工具、文件读写等维度,提供整体行为构成的快速快照。其中调用异常单独列出,便于第一时间判断系统稳定性。
会话统计表以 Session 为粒度展开,记录每个会话在各行为维度上的调用量。截图中首行 Session 的工具调用总数达 1925 次,其中命令执行 1364 次、文件读写 561 次,与其他 Session 相比量级悬殊,此类异常活跃的 Session 往往值得优先审查。表格按最后活跃时间排序,结合各维度的调用分布,可快速识别行为模式异常的会话。
工具调用量统计和错误分析
工具调用是 Agent 与外部世界交互的唯一通道,其调用量与错误率的变化直接反映 Agent 的运行健康状态。工具调用时间线按工具类型分色展示各时间段的调用频次构成,异常尖峰是排查问题的第一入口,结合工具类型的构成变化,可快速判断是哪类操作驱动了调用激增。错误率趋势图与调用量时间线共享时间轴。错误率高峰不一定与调用量高峰重合,两者的时间差往往能揭示问题的真实来源:是某类工具在特定时段持续失败,还是某次任务引入了异常的调用模式。
全量工具调用日志则提供每次调用的协议错误、执行状态与返回内容,支持从趋势异常快速下钻至具体失败调用,定位根因。
外部交互
外部交互记录 Agent 在运行过程中发起的所有对外行为,包括 API 调用、网页访问、消息发送、邮件外发等,按会话、工具名与交互类型分类呈现。
对于 Agent 而言,外部交互既是完成任务的必要手段,也是潜在的风险出口。全量记录外部交互行为,一方面帮助团队掌握 Agent 的实际能力边界与使用习惯,另一方面在出现异常时提供完整的行为上下文,支持跨工具、跨会话的关联分析与溯源。
步骤三:自定义可观测数据探索
内置大盘提供的是通用维度的审计与观测视图。在实际安全运营中,大盘往往是“发现问题”的起点而非终点——当审计大盘标记出一个高风险会话、Token 趋势图出现异常尖峰、或运行指标告警触发时,往往需要进一步从统计概览下钻到具体事件,还原完整的行为链并确认根因。SLS 的查询分析引擎为这一过程提供了灵活的自定义探索能力。
日志数据模型:自定义分析的基础
自定义探索的前提是理解数据结构。SLS 接入方案已根据审计分析需求预建索引,用户无需额外配置即可直接查询。以下两类日志构成了自定义分析的核心数据源:
Session 日志 — 记录 Agent 的完整业务行为,是安全审计与成本分析的主要依据。即在步骤一:日志接入(以 Session 日志为例)中接入的日志。
字段路径
类型
审计分析用途
__tag__:__session_id__text
会话唯一标识,按会话隔离与聚合的关键字段
typetext
条目类型:
session(会话元数据)/message(对话消息)/compaction(上下文压缩摘要),过滤出可审计的对话记录message.roletext
消息角色:
user(用户输入)/assistant(模型响应)/toolResult(工具返回),定位行为主体message.contenttext
消息正文,涵盖用户输入、模型输出与工具参数/返回值,支撑注入检测、敏感数据匹配与全文检索
message.providermessage.modeltext
模型提供方与模型名称,用于成本分析与按模型维度的行为统计
message.usage.totalTokensmessage.usage.cost.totallong / double
Token 用量与估算成本,用于异常消耗检测与会话级成本排序
message.stopReasontext
响应终止原因:
stop(正常结束)、toolUse(触发工具调用,下一条通常为 toolResult)、error/aborted/timeout(异常终止),筛选异常会话的关键字段message.toolNamemessage.isErrortext / bool
工具调用名称与执行状态,配合
toolResult角色做工具级审计id、parentIdtext
条目 ID 与父 ID,用于构建对话树、还原消息顺序;
session类型条目的id即为 sessionIdtimestamptext
事件时间戳,用于时间窗口过滤、排序与告警范围界定
Runtime 日志 — 记录网关与各子系统的运行状态,是排障与系统健康分析的数据基础。
说明选择OpenClaw-运行时日志卡片并参考步骤一:日志接入(以 Session 日志为例)进行接入。
字段路径
类型
审计分析用途
_meta.logLevelNametext
日志级别(TRACE / DEBUG / INFO / WARN / ERROR / FATAL),聚焦 ERROR 与 FATAL 做异常排查
_meta.pathtext
源码文件路径与行号,精确关联代码位置,便于堆栈分析
数字键
"0"object(JSON)
结构化上下文,通常包含
subsystem字段(如gateway/channels/telegram/plugins)数字键
"1"及后续text
日志消息正文与堆栈内容,支持全文检索与关键字匹配
会话级下钻:从高风险会话到完整行为链
典型场景: 审计大盘的“高风险会话”列表标记了一个高危 Session,安全团队需要还原该会话的完整交互过程,确认威胁是否属实。
多实例部署环境下,各 OpenClaw 实例的日志集中写入同一 SLS Logstore。自定义探索的第一步是按 Session ID 隔离,将视野收敛到单个会话,明确“谁在何时触发了哪些请求、调用了哪些工具、模型如何响应”,为合规举证提供清晰边界。
登录日志服务控制台,在Project列表中选择目标Project。
在日志存储中目标LogStore中通过查询 / 分析进行数据探索,使用
* and __tag__:__session_id__:<Session_Id>进行过滤,替换<Session_Id>为真实Session ID。完成会话过滤后,在原始日志的原始页签下,找到目标日志,单击
 图标,可进行上下文预览,按原始顺序还原该会话内的完整行为链——用户输入、模型推理、工具调用请求、工具执行结果,先后关系一目了然。这一能力在审计场景中尤为关键:它不仅能帮助识别异常调用顺序(如敏感文件读取紧接外发操作),还为安全事件的复现与证据留存提供了完整的上下文视图。
图标,可进行上下文预览,按原始顺序还原该会话内的完整行为链——用户输入、模型推理、工具调用请求、工具执行结果,先后关系一目了然。这一能力在审计场景中尤为关键:它不仅能帮助识别异常调用顺序(如敏感文件读取紧接外发操作),还为安全事件的复现与证据留存提供了完整的上下文视图。
运行时排障:关键词检索与聚合分析
典型场景: 运行指标大盘告警提示错误率突增,需要从海量 Runtime 日志中快速定位故障模块与根因。
SLS 支持全文检索与结构化字段检索的组合,配合时间范围可逐层收敛排查范围。典型的排障路径分为两步——先缩小范围,再量化分布:
第一步:逐层过滤,锁定问题
按日志级别过滤:使用
_meta.logLevelName: ERROR or _meta.logLevelName: WARN or _meta.logLevelName: FATAL过滤所有错误与警告日志,将注意力集中到异常事件。按子系统下钻:在错误日志中叠加字段条件,例如
0.subsystem: plugins,则分析语句为(_meta.logLevelName: ERROR or _meta.logLevelName: WARN or _meta.logLevelName: FATAL) and 0.subsystem: plugins,将范围收敛到具体子系统,两步过滤即可快速定位到错误日志。
第二步:SQL 聚合,量化全局分布
关键词筛选定位的是单条事件,而 SQL 聚合分析则将单条日志上升为全局统计视图。例如,对 subsystem 字段做分组聚合,则分析语句为_meta.logLevelName: ERROR or _meta.logLevelName: WARN or _meta.logLevelName: FATAL | select "0.subsystem" as subsystem, count(1) as c group by subsystem,可直观呈现各子系统的错误分布,快速识别集中性异常,为进一步排查指明方向。
步骤四:多数据源联动,从异常发现到根因定位的排查闭环
前面我们基于可观测数据介绍了数据的接入、内置大盘与自定义探索,在实际运维与审计中,可观测数据之间并非孤立使用,而是遵循一个固定的协作模式,逐层收敛、互相印证:
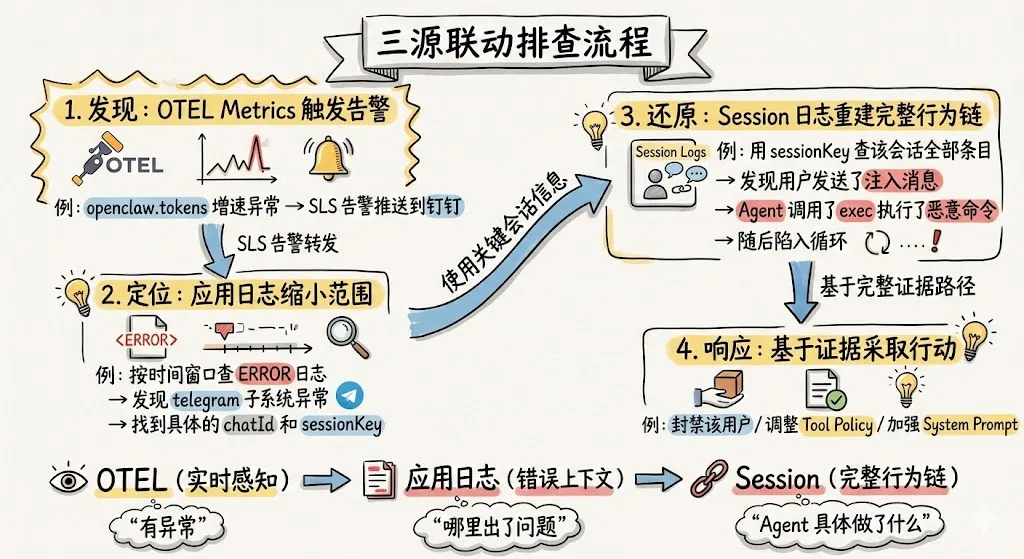
OTEL Metrics → 应用日志(错误上下文)→ Session 审计日志(完整行为链)。典型排查路径如下:OTEL 指标发现异常(如延迟飙升、Token 激增、错误率突增);随即在应用日志中定位对应时间窗口的错误详情(Webhook 超时、认证失败、网关异常);最后下钻到 Session 审计日志,还原该会话的完整工具调用序列、模型交互内容与成本消耗,确认根因并留存审计证据。