
日志服务提供物化视图功能,对目标SQL自动提取出子视图(聚合、过滤、投影等)进行持久化,并在后续执行SQL分析时自动进行查询改写,从而显著加速超大规模数据的分析性能。
背景介绍
为什么要使用物化视图
日志服务支持通过SQL对数据进行即时分析,即每次SQL执行,都是对选择的时间范围内的全量数据进行计算分析。在大规模数据量下,普通执行模式可能会遇到结果不精确、执行超时、并发超限等问题。使用高性能完全精确查询与分析(SQL独享版)可以大幅提高计算能力,但支撑的数据规模仍然是有上限的,而且大规模数据下的执行时间也会比较长。因此对于超大规模数据,且对SQL执行时间有要求的情况下,比如Dashboard报表场景,我们可以通过创建物化视图的方式,对报表中SQL 的子语句进行增量预计算并持久化中间结果。在后续刷新报表的时候,就可以自动利用已经计算好的中间结果数据,从而大幅提升执行性能。
工作原理
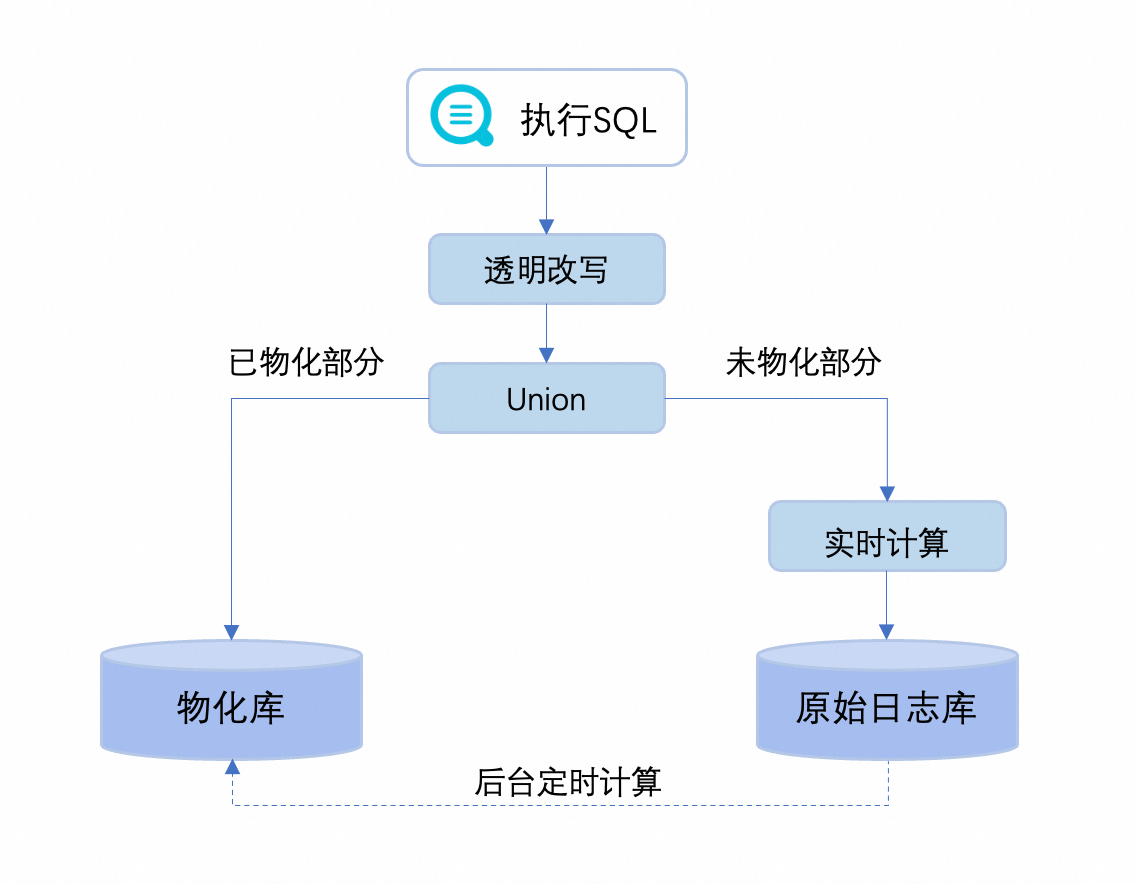
原始日志库:原始日志数据的Logstore(物化视图不会对原始日志库产生任何影响)。
物化库:创建物化视图后,会自动创建一个对应的物化库,用于存储物化视图的结果数据。
物化是按照写入数据流式处理的,即使原始数据在日志时间上存在乱序,定时物化的结果也不会存在重复或者遗漏。
后台定时计算:后台会针对输入的SQL,自动提取出需要物化的模式,并定时对原始Logstore的数据,计算物化的中间结果。
用户创建物化视图的时候,只需要提供想要加速的SQL,无需自己考虑物化细节。
透明改写:在执行一个任意的SQL查询时,日志服务的执行引擎会对SQL的结构进行智能分析,自动匹配相应的物化视图并进行透明改写。
使用SQL的时候,只需要直接查询原始Logstore。日志服务的计算引擎会自动匹配物化视图并进行智能改写,无需关心具体改写过程。
保证最新数据可见性:日志服务的计算引擎会智能地处理查询请求,对于已物化的数据范围,直接从物化视图中读取;对于尚未物化的最新数据,则从原始日志库中实时读取并计算,最终将两部分结果自动合并,返回完整的查询结果。由此,在充分发挥物化视图加速查询优势的同时,也确保了最新数据的实时可见性。
适用范围
仅支持日志库标准型Logstore,不支持查询型Logstore、时序库MetricStore、数据集StoreView等。
物化视图的管理,目前仅支持API的方式。暂不支持在控制台操作 。
使用物化视图
此处以Java语言为例。
若使用阿里云账号默认拥有所有权限,无需再额外授权。若使用RAM用户需设置如下权限:
导入如下版本的日志服务Java SDK。
<dependency> <groupId>com.aliyun.openservices</groupId> <artifactId>aliyun-log</artifactId> <version>0.6.138</version> </dependency>如下示例中,包含物化视图的创建、物化视图列表获取、物化视图信息获取、删除物化视图等操作,请按需修改执行。
代码中参数获取方式参考如下:
accessKey与accessId获取参考创建AccessKey。
host获取方式:
登录日志服务控制台,在Project列表中,单击目标Project。
单击Project名称右侧的
 进入项目概览页面,在访问域名中复制公网域名。
进入项目概览页面,在访问域名中复制公网域名。
import com.aliyun.openservices.log.Client; import com.aliyun.openservices.log.exception.LogException; import com.aliyun.openservices.log.request.CreateMaterializedViewRequest; import com.aliyun.openservices.log.request.ListMaterializedViewsRequest; import com.aliyun.openservices.log.response.ListMaterializedViewsResponse; import java.text.SimpleDateFormat; import java.util.concurrent.TimeUnit; public class MvDemo { static String accessId = System.getenv("ALIBABA_CLOUD_ACCESS_KEY_ID", ""); static String accessKey = System.getenv("ALIBABA_CLOUD_ACCESS_KEY_SECRET", ""); /** * 日志服务的服务接入点。此处以杭州为例,其它地域请根据实际情况填写。 */ static String host = "cn-hangzhou.log.aliyuncs.com"; /** * 创建日志服务Client。 */ static Client client = new Client(host, accessId, accessKey); /** * Project名称。 */ static String projectName = "xxx"; /** * Logstore名称。 */ static String logstoreName = "xxx"; public static void main(String[] args) throws Exception { String materializedViewName = "test_mv"; createMv(materializedViewName);//创建指定名称的物化视图 listMv();//获取当前project下的物化视图列表 getMv(materializedViewName);//获取当前物化视图信息 // deleteMv(materializedViewName); //删除物化视图 } static int dateStrToSecond(String dateStr) throws Exception { SimpleDateFormat simpleDateFormat = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss"); return (int)TimeUnit.MILLISECONDS.toSeconds(simpleDateFormat.parse(dateStr).getTime()); } static void createMv(String materializedViewName) throws Exception { String originalSql = "* | select count(l1) as cnt, l2 from stability group by l2"; // 请修改为需要通过物化加速的SQL int aggInternalMins = 60; // 定时执行物化的时间周期,单位是分钟。 int startTime = dateStrToSecond("2025-07-30 00:00:00"); // 开始物化的时间点:是原始数据的时间点(数据的写入时间)。限制只物化这个时间点之后的原始数据。 int ttl = 0; // 物化库的TTL,设为0表示和原始LogStore的TTL保持一致,物化库的TTL不能小于原始库的TTL。 //单个project下创建的物化视图数目不能超过 100个 CreateMaterializedViewRequest request = new CreateMaterializedViewRequest(projectName, materializedViewName, logstoreName, originalSql, aggInternalMins, startTime, ttl); client.createMaterializedView(request); System.out.println("create materialized view " + materializedViewName); } static void listMv() throws LogException { ListMaterializedViewsRequest request = new ListMaterializedViewsRequest(projectName, "", 0, 10);//0,10为分页查询参数。 ListMaterializedViewsResponse response = client.listMaterializedViews(request); System.out.println("total materialized view count: " + response.getTotal()); for (String materializedView : response.getMaterializedViews()) { System.out.println(materializedView); } } static void getMv(String materializedViewName) throws Exception { GetMaterializedViewResponse response = client.getMaterializedView(projectName, materializedViewName); System.out.println("get materialized view detail, name: " + materializedViewName); System.out.println("originalSql: " + response.getOriginalSql()); System.out.println("startTime: " + response.getStartTime()); System.out.println("ttl: " + response.getTtl()); } static void deleteMv(String materializedViewName ) throws LogException { client.deleteMaterializedView(projectName, materializedViewName); System.out.println("delete materialized view " + materializedViewName); } }
支持的语法
支持所有的标量函数和表达式。
支持WHERE条件、GROUP BY、LIMIT、TOP-N等语句。
支持常见的聚合函数,详细列表如下:
支持的聚合函数 | 语法 |
count(*) count(1) count(x) count_if(boolean expression) max(x) max(x, n) min(x) min(x, n) sum(x) arbitrary(x) | |
approx_distinct(x) approx_distinct(x, e) approx_percentile(x, percentage) |
计费说明
物化视图计费主要是针对写入物化库的数据量,取决于物化视图对应SQL定时计算的结果数据量。一般来说远小于原始Logstore的数据量,并按照标准型Logstore的按写入数据量计费。