
本方案介绍如何利用阿里云日志服务的数据加工能力,在日志数据持久化之前自动进行脱敏处理。通过此方案,可以有效保护LLM应用交互日志中的敏感信息,确保数据在后续运维、分析和审计环节的安全,满足数据安全与合规要求。
业务场景说明
在基于LLM构建的智能客服、订单处理等应用中,系统与用户的交互日志会记录大量敏感数据,例如手机号、收货地址、银行卡号、内部接口凭证等。若将这些原始日志直接存储,会在后续的查询、共享或分析环节引发数据泄露风险,不符合《个人信息保护法》等法规对“数据最小化”的处理原则。本方案旨在完整保留日志结构和分析价值的前提下,实现敏感字段的自动化、实时脱敏,确保所有人员访问的都是脱敏后的安全数据,从源头构建数据安全防线。
方案架构
本文将以一个电商 Copilot Demo 为例,展示如何借助阿里云日志服务的脱敏函数,在不改变业务逻辑的前提下,确保系统中的敏感数据隐私安全。通过在应用服务器上部署LoongCollector,将日志统一发送至阿里云日志服务。在日志数据写入Logstore之前,利用SLS的数据加工功能执行预设的SPL脱敏脚本,对指定字段进行脱敏。处理完成后的安全日志最终被持久化存储,供后续分析使用。

Dify 平台:作为 Copilot 的中枢,负责用户意图识别、服务调用编排与 LLM 回复生成。
业务服务层:提供退款、订单、物流等核心 API。
日志链路:通过 LoongCollector 统一采集各服务日志,并推送至 SLS。
SLS 脱敏处理:在日志写入 LogStore 前,自动对敏感字段执行脱敏。
使用层:脱敏后的日志可供运维、运营、安全团队安全使用。
准备工作
在采集日志前,需规划并创建用于管理与存储日志的Project和Logstore。若已有可用资源,可跳过此步骤,直接进入步骤一:配置机器组(安装LoongCollector)。
单击Project名称,进入目标Project。
在左侧导航栏,选择
 ,单击+。
,单击+。在创建Logstore页面,完成以下核心配置:
Logstore名称:设置一个在Project内唯一的名称,该名称创建后不可修改。
Logstore类型:根据规格对比选择标准型或查询型。
计费模式:
按使用功能计费:按存储、索引、读写次数等各项资源独立计费。适合小规模或功能使用不确定的场景。
按写入数据量计费:仅按原始写入数据量计费,提供30天免费存储,以及免费的数据加工、投递等功能。适合存储周期接近30天或数据处理链路复杂的业务场景。
数据保存时间:设置日志的保留天数(1~3650天,3650为永久保存),默认为30天。
其他配置保持默认,单击确定。如需了解其他配置信息,请参考管理Logstore。
实施步骤
以下步骤将引导您完成从日志采集到配置脱敏规则的全过程。
步骤一:配置机器组(安装LoongCollector)
在完成准备工作后,为不同类型的服务器安装LoongCollector并将其加入机器组。
以下安装步骤仅适用于日志源为阿里云ECS实例,且该实例与日志服务Project属于同一阿里云账号和相同地域的场景。
如果您的ECS实例与Project不在同一账号或地域,或者日志源为自建服务器,请参考LoongCollector 安装与配置进行操作。
配置步骤:
在
 日志库页面,单击目标Logstore名称前的
日志库页面,单击目标Logstore名称前的 展开。
展开。单击数据接入后的
 ,在快速数据接入弹框中,选择单行-文本日志,单击立即接入。
,在快速数据接入弹框中,选择单行-文本日志,单击立即接入。在机器组配置页面,配置如下参数:
使用场景:主机场景
安装环境:ECS
配置机器组:根据目标服务器的LoongCollector安装情况与机器组配置状态,选择对应操作:
已安装LoongCollector且已加入某个机器组,直接在源机器组列表中勾选,将其添加至应用机器组列表,无需重复创建。
未安装LoongCollector,单击创建机器组:
以下步骤将引导您完成LoongCollector的一键自动安装并创建机器组。
系统会自动列出与 Project 同地域的 ECS 实例,勾选需要采集日志的一台或多台实例。
单击安装并创建为机器组,系统将自动在所选ECS实例上安装LoongCollector。
配置机器组名称并单击确定。
说明如果安装失败或一直处于等待中,请检查ECS地域是否与Project相同。
检查心跳状态:单击下一步,页面出现机器组心跳情况。查看心跳状态,若为OK表示机器组连接正常,单击下一步,进入Logtail配置页面。
若为FAIL,可能是初次建立心跳需要花费一些时间,请等待两分钟左右,再刷新心跳状态。若刷新后仍为FAIL,请参考心跳异常问题汇总排查。
步骤二:配置日志采集
完成LoongCollector安装和机器组配置后,进入Logtail配置页面,定义日志采集和处理规则。
全局配置:
配置名称:自定义采集配置名称,例如
llm-app-log-collection。
输入配置:
类型:文本日志采集。
文件路径:指定应用日志文件的存储路径和文件名。例如,
/logs/app/*.log表示采集/logs/app/目录下所有以.log结尾的文件。最大目录监控深度:文件路径中通配符
**匹配的最大目录深度。默认为0,表示只监控本层目录。
完成全局配置与输入配置后,单击下一步,进入查询分析配置页面:
配置完成后,单击下一步,完成整个采集流程的设置。
步骤三:配置写入侧脱敏规则
针对本文电商Copilot日志,在对应的Project中新建数据处理器,即可智能识别并对IP地址、邮箱等敏感内容进行脱敏。其中手机号、身份证号、信用卡号、姓名以及地址信息,定制化地保留前后缀。详细配置介绍可参见无需复杂正则:SLS 新脱敏函数让隐私保护更简单高效。
SLS提供的mask(脱敏)函数,支持内置和关键字匹配两种模式,能高效、精准地识别并脱敏日志中的敏感信息:
内置匹配(
buildin):mask函数开箱即用,内置了对常见6种敏感信息(如手机号、身份证、邮箱、IP地址、座机电话、银行卡号)的识别能力。关键字匹配(
keyword):智能识别任意文本中符合"key":"value"、'key':'value'或key=value 等常见 KV 对格式的敏感信息。
在左侧导航栏,选择
 。
。在写入处理器页签下,单击创建,进行如下配置:
处理器名称:自定义处理器名称,例如脱敏处理。
处理失败:保留原始数据。
SPL:
* | extend content = mask (content,' [ {"mode":"buildin","types":["IP_ADDRESS","EMAIL", "LANDLINE_PHONE"]}, {"mode":"buildin","types":["PHONE","IDCARD","CREDIT_CARD"],"maskChar":"*","keepPrefix":3,"keepSuffix":4}, {"mode":"keyword","keys":["address"],"maskChar":"*","keepPrefix":3,"keepSuffix" :1}, {"mode":"keyword","keys":["name"],"maskChar":"*","keepPrefix":1}]')
调试SPL脱敏脚本,脚本无误后,单击保存。
步骤四:关联写入处理器并查看日志
在左侧导航栏,选择
,单击目标Logstore名称前的展开。单击
 ,在Logstore属性页面,单击写入处理器。
,在Logstore属性页面,单击写入处理器。单击修改,选择新建的写入处理器,并保存。
单击右上角的查询分析,查看处理后的日志。脱敏前后日志对比:
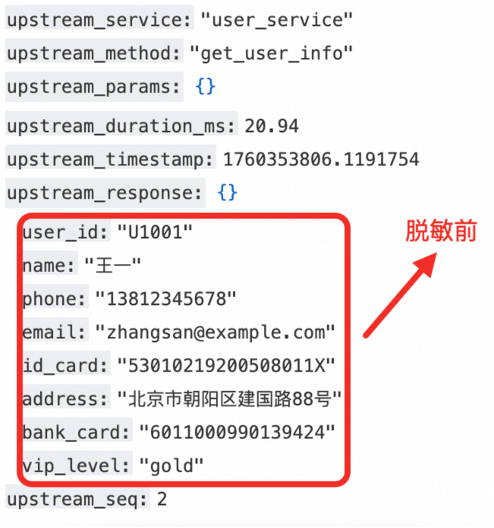
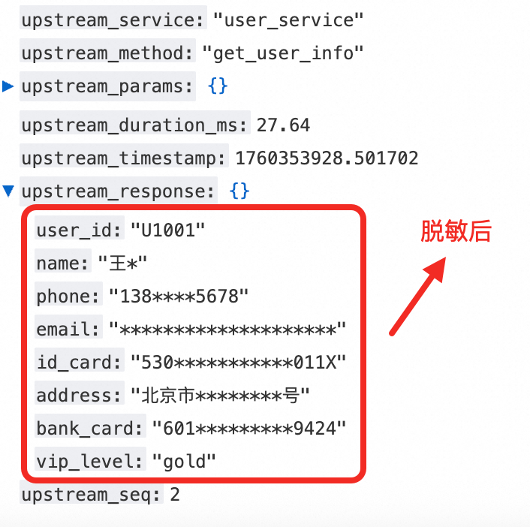
对比脱敏前的数据可以看到:
按需保留,安全与可用性兼顾: 针对不同敏感字段,可定制化保留前后缀字符。手机号保留前三后四位,既保护了用户隐私,又方便运维人员进行问题排查和用户身份核验,在保障安全的同时兼顾了数据可用性。
配置极简,无需正则:关键字匹配模式下,即使数据嵌套多层 JSON 结构,也只需配置最内层的 Key 即可精准匹配 Value 进行脱敏,同时无需编写复杂的正则表达式来兼容各种 key:value 对格式,大大降低了配置难度。中文精准脱敏: 姓名与地址精确按照配置的规则进行打码,避免因编码问题导致脱敏失效。
此外,mask函数相较于使用正则表达式进行脱敏,在性能上具有显著优势,可有效降低日志处理延迟,提升整体性能。尤其是在复杂或者数据量巨大的场景下,性能优势更为明显。
日志分析
数据脱敏让同一份日志呈现出三种“视角”:
运维:看到调用链与性能瓶颈,却看不到隐私;
运营:看到趋势、效率与体验,却看不到个体;
安全:看到策略执行与留痕证据,却无需担心遗漏。
在这套体系中,数据不再是一座孤岛,而是一套有边界的智能资产,数据合规、分析、排障三者可以并行。
运维工程师:定位
对于运维团队来说,以往排障往往依赖包含用户手机号、地址、账户号的明文日志,这在合规上存在高风险。 现在,脱敏后的日志让这一过程从源头安全化,在问题定位场景中通过trace_id 检索即可复原整个调用链:
从 Copilot 的意图识别开始;
到订单服务 → 退款服务 → 第三方支付网关;
再到返回结果与耗时。
需要核对用户身份时,日志里只保留了脱敏后的银行卡号、手机号等信息,足以和业务侧“同一用户”比对,而不会暴露原值。即便是跨团队协查,也能直接在脱敏日志上定位问题,避免泄露风险。
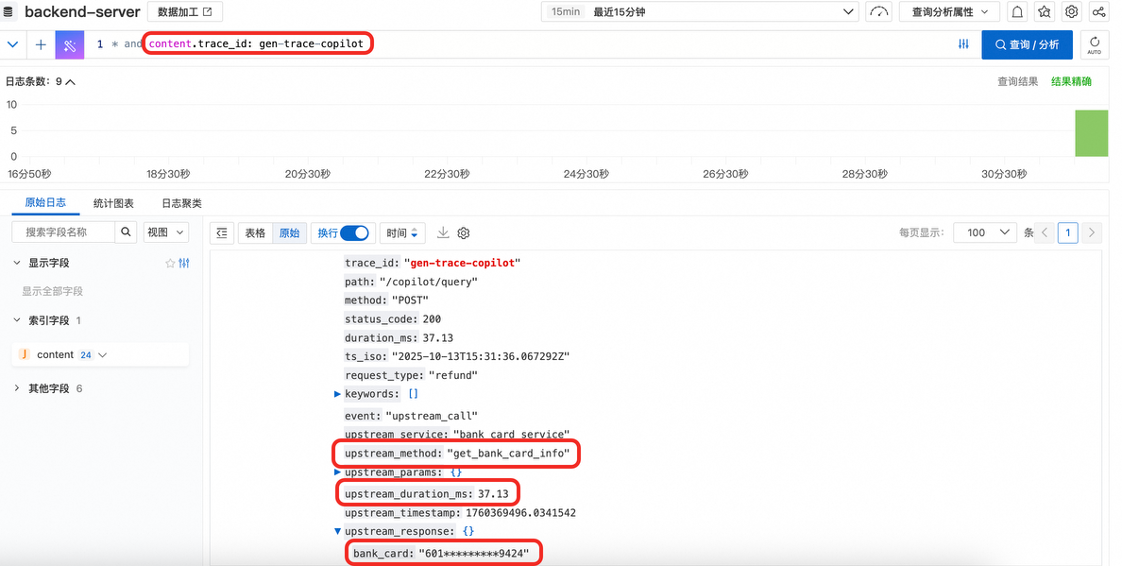
运营团队:分析
报表的价值在于发现整体趋势,而非窥探个人信息。在脱敏运营报表中,用户信息已匿名化处理,仅保留关键业务指标,助力团队从数据中挖掘洞察。
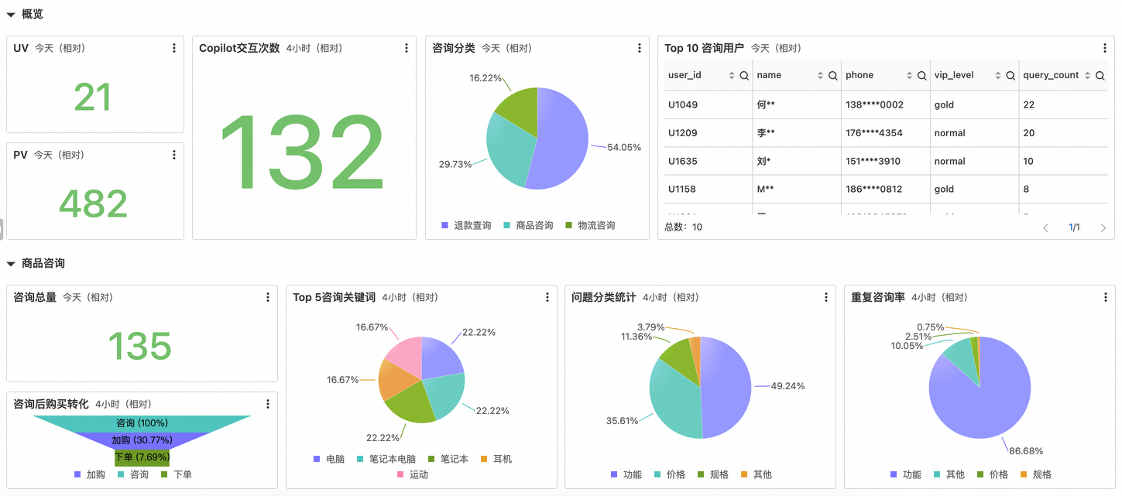
从报表中,运营团队可以快速了解:
整体概况: UV、PV 等关键指标,Copilot 交互次数,以及咨询总量,快速掌握运营概况。
咨询分类:退款、商品、物流咨询占比,清晰了解用户关注点。
问题分类:掌握用户提问的侧重点,如功能、价格、规格等。
重复咨询率:衡量服务质量,快速定位需要优化的环节。
用户行为:咨询后购买转化漏斗,以及热门咨询关键词,助力优化产品和营销策略。
重点用户: Top 10 咨询用户,虽然用户信息脱敏,但可通过 VIP 等级和咨询次数,制定差异化服务策略。
此外,报表中所有用户信息都经过脱敏处理,电话号码、姓名等个人信息均被掩码,确保无法反推到具体用户,充分保障用户隐私。
安全与合规团队:审计
对安全与合规团队而言,日志的最大风险在于“存量明文”。 本文中的脱敏方案将脱敏前置:数据在写入前已被处理,这从根本上消除了敏感数据脱敏覆盖不全与导出明文数据的可能。此外,SLS还提供完善的合规支撑能力:
数据存储:支持自定义日志存储时间,对网络审计相关日志设置>180天的存储天数,满足安全审计要求。
数据操作审计:日志使用过程中会存在用户级操作行为,这些不管是管控层面的控制台操作、OpenAPI 调用,或者数据面的业务日志使用,任何人查看、分析、导出日志,都只在授权范围内看到应当看到的内容。同时CloudLens for SLS还提供Project、Logstore的资产使用监控。
总结
当LoongCollector的日志采集与 Logstore 的数据脱敏连成闭环,日志在落库同时完成安全转化。运维能定位,运营能分析,安全能审计。 这不仅是一次性的加固,而是一条可复用的路径:写入侧脱敏 + 默认脱敏落库 + 角色化访问。 以此为基线,企业能放心扩展 Copilot 的业务覆盖,让“效率红利”与“合规确定性”并行存在。