
您可以在日志服务控制台实时查询所采集到的日志,并将日志投递到MaxCompute,进行进一步的BI分析及数据挖掘。本文介绍通过日志服务投递日志到MaxCompute的操作步骤。
投递日志到MaxCompute(旧版)功能已下线,投递日志到MaxCompute请参考投递日志到MaxCompute(新版)。
前提条件
已开通MaxCompute,并创建表。更多信息,请参见创建表。
使用限制
只有阿里云账号能够创建投递任务,不支持RAM用户操作。
不同Logstore中的数据请勿投递到同一张MaxCompute表中,有小概率导致MaxCompute表中的分区数据被覆盖。
投递不支持日志时间(对应保留字段__time__)距离当前时间14天以前的数据,在投递过程中自动丢弃超过14天的数据。
通过日志服务投递日志到MaxCompute,暂不支持DECIMAL、DATETIME、DATE、TIMESTAMP数据类型。更多信息,请参见2.0数据类型版本。
支持的地域如下所示,其他地域请使用DataWorks进行数据同步。更多信息,请参见日志服务通过数据集成投递数据。
日志服务Project所在地域
MaxCompute所在地域
华北1(青岛)
华东2(上海)
华北2(北京)
华北2(北京)、华东2(上海)
华北3(张家口)
华东2(上海)
华北5(呼和浩特)
华东2(上海)
华东1(杭州)
华东2(上海)
华东2(上海)
华东2(上海)
华南1(深圳)
华南1(深圳)、华东2(上海)
中国(香港)
华东2(上海)
步骤一:创建投递任务
登录日志服务控制台。
在Project列表区域,单击目标Project。

在页签中,单击目标Logstore左侧的>,选择。
单击开启投递。
在投递提示对话框中,单击直接投递。
在MaxCompute投递功能页面,配置投递规则,然后单击确定。
重要参数配置如下所示。
参数
说明
选择要投递的区域
日志服务Project所在地域不同,所支持的MaxCompute地域不同。更多信息,请参见使用限制。
投递名称
投递任务的名称。
项目名
MaxCompute项目名称。
MaxCompute表名
MaxCompute表名称。
MaxCompute普通列
左边输入框中填写与MaxCompute表列相映射的日志字段名称,右边为MaxCompute表的列名称。更多信息,请参见数据模型映射。
重要日志服务投递日志到MaxCompute按照日志字段与MaxCompute表列的顺序进行映射,修改MaxCompute表列名不影响数据投递。如果更改MaxCompute表schema,请重新配置日志字段与MaxCompute表列映射关系。
左边输入框的日志字段,不支持双引号(“”)、单引号('')和含有空格的字符串。
如果您的日志中存在同名字段(例如都为request_time),则日志服务会将其中一个字段名显示为request_time_0,底层存储的字段名仍为request_time。因此您在投递时,只能使用原始字段名request_time。
存在同名字段时,系统只随机投递其中一个字段的值。请尽量避免日志中使用同名字段。
MaxCompute分区列
左边输入框中填写与MaxCompute表分区列相映射的日志字段名称,右边为MaxCompute表分区列名称。更多信息,请参见数据模型映射。
说明最大配置3个分区列,请谨慎选择自定义字段作为分区列,保证一次投递任务中生成的分区数目小于512个,否则会导致投递任务写数据到MaxCompute表失败,整批数据无法投递。
时间分区格式
时间分区格式,配置示例和参数详细请参见参考示例和Java SimpleDateFormat。
说明仅当分区字段配置为__partition_time__时,时间分区格式才生效。
请勿使用精确到秒的日期格式,易导致单表的分区数目超过限制(60000个)。
单次投递任务的数据分区数目必须在512以内。
导入时间间隔
投递任务的时长,默认值为1800,单位为秒。
当投递任务的时长达到此处设置的大小时,会自动创建一个新的投递任务。
开启投递后,一般情况下日志数据会在写入Logstore后的1个小时导入到MaxCompute,导入成功后即可在MaxCompute内查看到相关日志数据。更多信息,请参见日志投递MaxCompute后,如何检查数据完整性。
步骤二:查看MaxCompute数据
投递到MaxCompute成功后,您可以查看MaxCompute数据,数据样例如下所示。您可以使用已经与MaxCompute绑定的大数据开发工具Data IDE来消费数据,进行可视化的BI分析及数据挖掘。
| log_source | log_time | log_topic | time | ip | thread | log_extract_others | log_partition_time | status |
+------------+------------+-----------+-----------+-----------+-----------+------------------+--------------------+-----------+
| 10.10.*.* | 1453899013 | | 27/Jan/2016:20:50:13 +0800 | 10.10.*.* | 414579208 | {"url":"POST /PutData?Category=YunOsAccountOpLog&AccessKeyId=****************&Date=Fri%2C%2028%20Jun%202013%2006%3A53%3A30%20GMT&Topic=raw&Signature=******************************** HTTP/1.1","user-agent":"aliyun-sdk-java"} | 2016_01_27_20_50 | 200 |
+------------+------------+-----------+-----------+-----------+-----------+------------------+--------------------+-----------+授予日志服务账号投递权限
在数加平台删除表后再重建,会导致默认授权失效,您需手动为日志服务投递数据操作重新授权。
登录DataWorks控制台。
在页面左上角,选择地域。
在左侧导航栏中,单击工作空间列表。
在工作空间列表页面,将鼠标悬停至目标工作空间对应的快速进入,然后单击数据开发。
新建业务流程。
在数据开发页面,选择。
在新建业务流程对话框中,配置业务名称,然后单击新建。
新建节点。
在数据开发页面,选择。
在新建节点对话框中,配置名称和路径,然后单击提交。
其中,路径需配置为您在步骤5中所创建的业务流程。
在已创建的节点编辑框中,执行如下命令,完成授权。
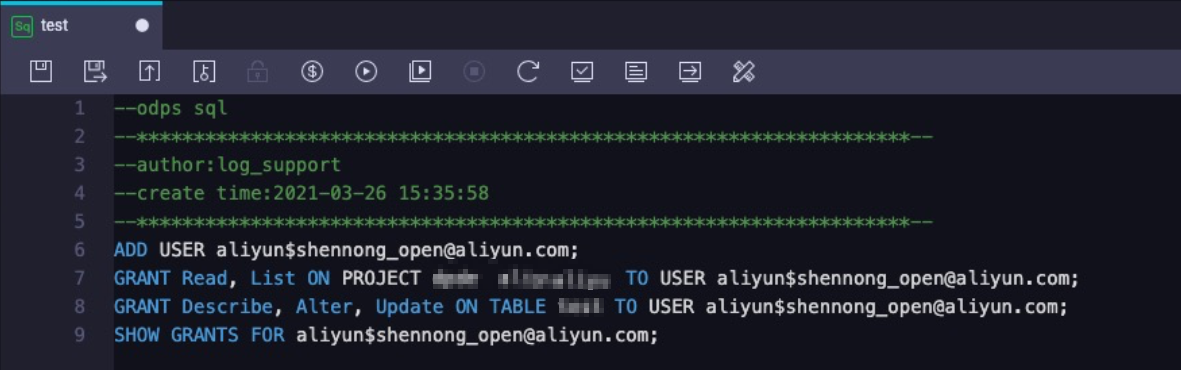
命令
含义
ADD USER aliyun$shennong_open@aliyun.com;在MaxCompute项目空间中添加用户。
其中shennong_open@aliyun.com为日志服务账号(固定值,请勿修改)。
GRANT Read, List ON PROJECT {ODPS_PROJECT_NAME} TO USER aliyun$shennong_open@aliyun.com;授予用户读和查询MaxCompute项目空间的权限。
其中{ODPS_PROJECT_NAME}为MaxCompute项目空间名称,请使用实际值替换。
GRANT Describe, Alter, Update ON TABLE {ODPS_TABLE_NAME} TO USER aliyun$shennong_open@aliyun.com;授予用户Describe、Alter和Update权限。
其中{ODPS_TABLE_NAME}为MaxCompute表名称,请使用实际值替换。
SHOW GRANTS FOR aliyun$shennong_open@aliyun.com;确认授权是否成功。
如果返回如下信息表示授权成功。
A projects/{ODPS_PROJECT_NAME}: List | Read A projects/{{ODPS_PROJECT_NAME}/tables/{ODPS_TABLE_NAME}: Describe | Alter | Update
相关操作
创建投递任务后,您可以在MaxCompute(原ODPS)投递管理页面,执行修改投递配置、关闭投递任务、查看投递任务状态及错误信息、重试投递任务等操作。
修改投递配置
单击投递配置,修改投递配置,参数详情请参见本文中的步骤一:创建投递任务。其中如果想新增列,可以在大数据计算服务MaxCompute修改投递的数据表列信息。
关闭投递任务
单击关闭投递,即可关闭投递任务。
查看投递任务状态及错误信息
日志服务支持查看过去两天内的所有日志投递任务及其投递状态。
任务状态
状态
说明
成功
投递任务正常运行。
进行中
投递任务进行中,请稍后查看是否投递成功。
失败
因外部原因而无法重试的错误导致投递任务失败,请根据错误信息进行排查并重试。例如MaxCompute表结构不符合日志服务规范、无权限等。
日志服务支持重试最近2天内所有失败的任务。
错误信息
如果投递任务出现错误,控制台上会显示相应的错误信息。
错误信息
建议方案
MaxCompute项目空间不存在
在MaxCompute控制台中确认您配置的MaxCompute项目是否存在,如果不存在则需要创建。日志服务不会主动重试该错误,请在解决问题后手动重试。
MaxCompute表不存在
在MaxCompute控制台中确认您配置的MaxCompute表是否存在,如果不存在则需要创建。日志服务不会主动重试该错误,请在解决问题后手动重试。
MaxCompute项目空间或表没有向日志服务授权
在MaxCompute控制台中确认授权给日志服务账号的权限是否存在,如果不存在则需要重新授权。更多信息,请参见授予日志服务账号投递权限。日志服务不会主动重试该错误,请在解决问题后手动重试。
MaxCompute错误
显示投递任务收到MaxCompute错误,请参见MaxCompute相关文档或联系MaxCompute团队解决。日志服务自动重试最近两天内的失败任务。
日志服务导入字段配置无法匹配MaxCompute表的列
重新配置MaxCompute表的列与日志服务中日志字段的映射。日志服务不会主动重试该错误,请在解决问题后手动重试。
重试任务
针对内部错误,日志服务支持按照策略自动重试。其他情况下,请您手动重试。自动重试的最小间隔是30分钟。当任务失败后,等待30分钟再做重试。日志服务支持重试最近2天内所有失败的任务。
如果您需要立即重试失败任务,请单击重试全部失败任务或通过API、SDK指定任务进行重试。
参考信息
__partition_time__
将日志时间作为分区字段,通过时间筛选数据是MaxCompute常见的过滤数据的方法。
格式
__partition_time__是根据日志服务中__time__字段的值计算得到的,结合分区时间格式,向下取整。为避免触发MaxCompute单表分区数目的限制,日期分区列的值会根据投递间隔对齐。
例如:日志服务的日志时间为27/Jan/2016 20:50:13 +0800,日志服务据此计算出保留字段__time__为1453899013(Unix时间戳),不同配置下的时间分区列取值如下所示。
导入MaxCompute间隔
分区时间格式
__partition_time__
1800
yyyy_MM_dd_HH_mm_00
2016_01_27_20_30_00
1800
yyyy-MM-dd HH:mm
2016-01-27 20:30
1800
yyyyMMdd
20160127
3600
yyyyMMddHHmm
201601272000
3600
yyyy_MM_dd_HH
2016_01_27_20
使用方法
使用__partition_time__ 筛选数据,可以避免全表扫描。例如查询2016年1月26日一天内日志数据,查询语句如下所示。
select * from {ODPS_TABLE_NAME} where log_partition_time >= "2015_01_26" and log_partition_time < "2016_01_27";
__extract_others__
__extract_others__是一个JSON字符串。例如要获取该字段的user-agent内容,查询语句如下所示。
select get_json_object(sls_extract_others, "$.user-agent") from {ODPS_TABLE_NAME} limit 10;说明get_json_object是MaxCompute提供的标准UDF,请联系MaxCompute团队开通使用该标准UDF的权限。更多信息,请参见MaxCompute提供的标准UDF。
示例供参考,请以MaxCompute产品的建议为最终标准。
数据模型映射
将日志服务中的日志投递到MaxCompute时,涉及两个服务之间的数据模型映射问题,相关注意事项与示例如下所示。
MaxCompute表至少包含一个数据列和一个分区列。
日志服务保留字段建议使用__partition_time__、__source__、__topic__。
一个MaxCompute表的分区数最大值为60000个,当分区数超出最大值后无法再写入数据。
投递任务是批量执行的,请谨慎设置分区列及其类型,保证一个投递任务内处理的数据分区数小于512个,否则该批数据都无法写入MaxCompute。
系统保留字段__extract_others__有曾用名_extract_others_,可兼容使用。
MaxCompute分区列的值不支持配置为MaxCompute的保留字和关键字。更多信息,请参见保留字与关键字。
MaxCompute分区列取值不支持配置为空,所以映射到分区列的字段必须为保留字段或日志字段,且可以通过cast运算符将string类型字段值转换为对应分区列类型,空分区列的日志会在投递中被丢弃。
日志服务中一个日志字段只能映射到一个MaxCompute表的列(数据列或分区列),不支持字段冗余,同一个字段名第二次使用时其投递的值为null,如果null出现在分区列会导致数据无法被投递。
MaxCompute数据列、分区列与日志服务字段的映射关系示例如下所示,其中日志服务保留字段详情请参见保留字段。
MaxCompute 列类型
列名(MaxCompute)
数据类型(MaxCompute)
日志字段名称(日志服务)
字段类型(日志服务)
字段说明
数据列
log_source
string
__source__
保留字段
日志来源。
log_time
bigint
__time__
保留字段
日志的Unix时间戳(从1970年1月1日开始所经过的秒数),对应数据模型中的Time域。
log_topic
string
__topic__
保留字段
日志主题。
time
string
time
日志内容字段
解析自日志,对应数据模型中的key-value。在很多时候Logtail采集的数据的__time__与time取值相同。
ip
string
ip
日志内容字段
解析自日志。
thread
string
thread
日志内容字段
解析自日志。
log_extract_others
string
__extract_others__
保留字段
未在配置中进行映射的其他日志字段会通过key-value序列化到JSON中,该JSON是一层结构,不支持字段内部JSON嵌套。
分区列
log_partition_time
string
__partition_time__
保留字段
由日志的 __time__ 字段对齐计算而得,分区粒度可配置。
status
string
status
日志内容字段
解析自日志,该字段取值支持枚举,保证分区数目不超过上限。