
表格存储知识库(RAG)的系统架构、数据模型、Embedding 和检索策略、Subspace 多租户设计,以及配额限制和适用性评估,帮助技术决策者判断产品是否适合自身业务场景。
系统架构
表格存储知识库服务采用全托管的 Serverless 架构,用户通过 API 与服务交互,底层资源由平台自动管理。
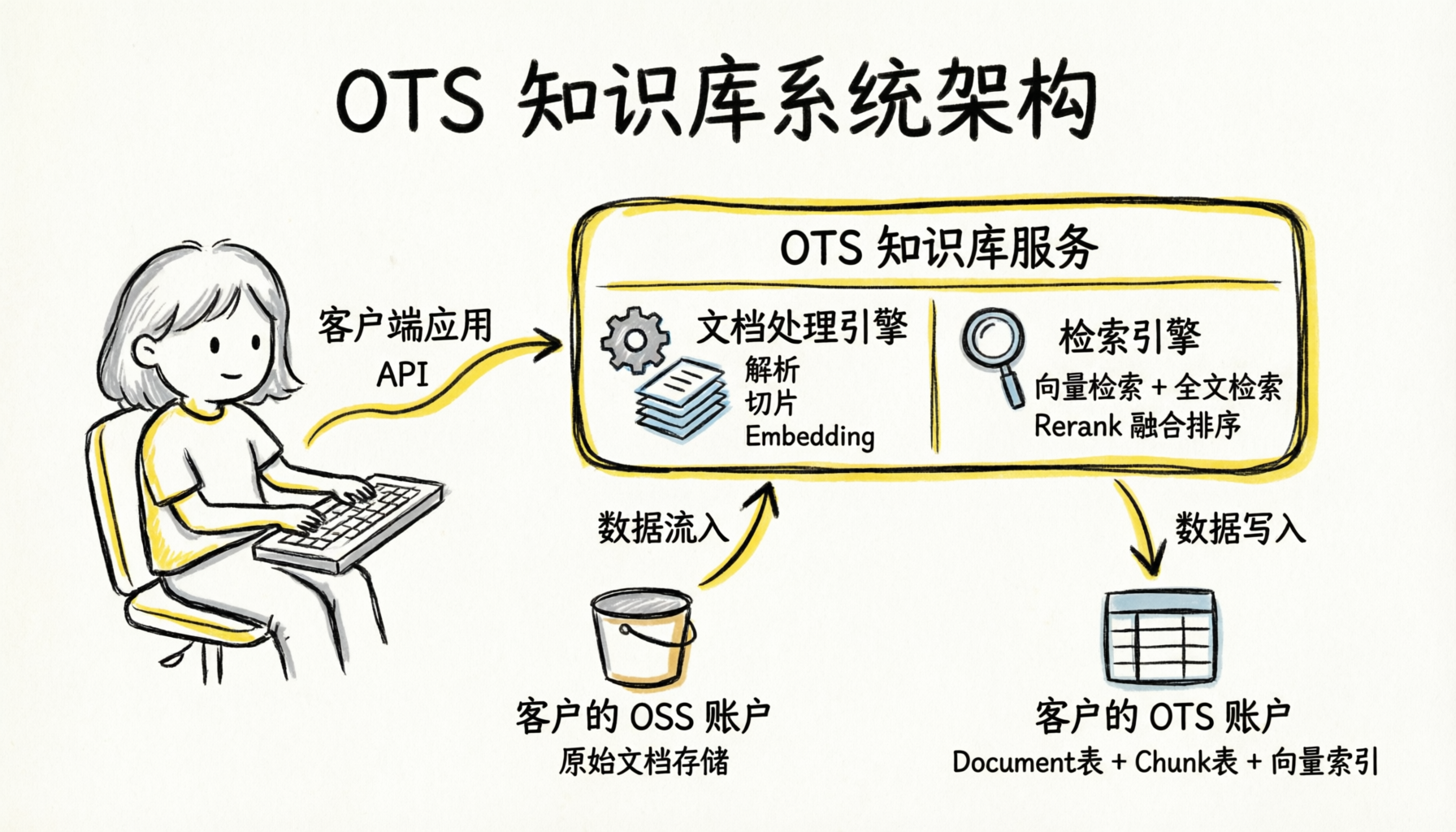
数据流转过程:
调用
AddDocuments接口,指定 OSS 文件路径(或通过 SDK 上传本地文件)。系统从 OSS 读取文件,自动完成文档解析和智能切片。
对每个切片调用 Embedding 模型生成向量,写入 Tablestore 的 Chunk 表。
自动构建向量索引和全文索引。
调用 Retrieve 接口时,系统执行混合检索并返回相关Chunk结果。
所有数据(原始文档、解析结果、向量数据)均存储在用户账号的 OSS 和 Tablestore 内。服务本身不持有任何客户数据。存储与计算分离,独立计费。
数据模型
知识库的数据按五层实体组织:
实体 | 说明 |
Project | 顶层项目,对应一个表格存储实例。一个 Project 下最多创建 256 个知识库。 |
KnowledgeBase | 知识库,每个知识库对应一张 Document 表、一张 Chunk 表和一张索引表。单个知识库最大支持 1 亿级文档。 |
Document | 文档记录,关联 OSS 文件,记录文档状态和元数据。 |
Chunk | 文档切片,存储向量数据和原文内容,是检索的最小单元。 |
Index | 索引表,存储向量数据,检索增强内容,是检索的最小单元。 |
系统自动在 Tablestore 中创建对应的数据表:
Document 表:使用
{知识库名}_{知识库 id}Chunk 表:使用
{知识库名}_{知识库 id}_chunkIndex 表:使用
{知识库名}_{知识库 id}_index
数据源
知识库的数据源为阿里云对象存储(OSS)。不论通过哪种方式上传,文档的原始数据都存储在自己的 OSS Bucket 内。
知识库需要对 OSS Bucket 进行读写操作:读取原始文档进行解析和切片,将解析过程的中间结果写回 OSS。
支持以下三种方式将文档导入知识库:
上传本地文件:指定本地文件或目录,SDK 自动上传到 OSS 后添加到知识库。如果是目录,会递归遍历所有文件。
添加 OSS 文件:文件已在 OSS 上时,直接指定 OSS 路径添加到知识库,省去上传步骤。
OSS 目录批量导入:指定 OSS 目录路径,系统自动递归扫描目录下所有文件。支持通过
inclusionFilters和exclusionFilters按文件名模式过滤。
每种方式的详细用法参见文档管理。
Embedding 配置
Embedding 配置决定了文档切片如何被向量化,在创建知识库时指定。
配置项 | 说明 |
| 模型提供方。 |
| 模型名称。百炼支持 |
| 向量维度。例如 |
| 仅 |
| 仅 |
不传 embeddingConfiguration 时,系统默认使用百炼 text-embedding-v4 模型(1024 维),适用于大多数场景。
Embedding 配置创建后不可修改。如需更换模型或维度,必须删除并重建知识库。创建前应充分评估模型选型。
选型建议:
通用中英文场景:推荐
text-embedding-v4(1024 维),在语义理解和性能之间取得较好平衡。已有自研或第三方 Embedding 服务:使用
custom模式接入,保持技术栈统一。维度越高语义表达越丰富,但存储和计算成本也越高。1024 维是大多数场景的推荐选择。
检索策略概述
调用 Retrieve 接口时,检索配置(retrievalConfiguration)按以下优先级确定:
优先级 | 来源 | 说明 |
1(最高) | Retrieve 接口参数 | 本次请求中传入的配置,仅对当次生效 |
2 | 知识库级别配置 | 创建知识库时设定,可通过 UpdateKnowledgeBase 修改 |
3(最低) | 系统默认值 | 向量 + 全文混合检索,WEIGHT 加权融合(向量 0.7 : 全文 0.3) |
检索类型
类型 | 说明 | 适用场景 |
| 向量检索,基于语义相似度 | 用自然语言描述需求,需要理解语义 |
| 全文检索,基于关键词匹配 | 输入精确关键词、专有名词、编号 |
建议同时开启两种检索类型,通过 Rerank 机制融合结果。
Rerank 排序策略
类型 | 说明 | 适用场景 |
RRF | 按排名倒数加权融合,无需额外模型调用 | 通用场景,延迟低 |
WEIGHT | 按比例加权向量与全文检索得分 | 需要精细控制两路检索的贡献比例 |
MODEL | 调用 Rerank 模型对候选结果重排序 | 对排序质量要求高,可接受额外延迟 |
检索策略的详细配置和调优方法参见检索和排序。
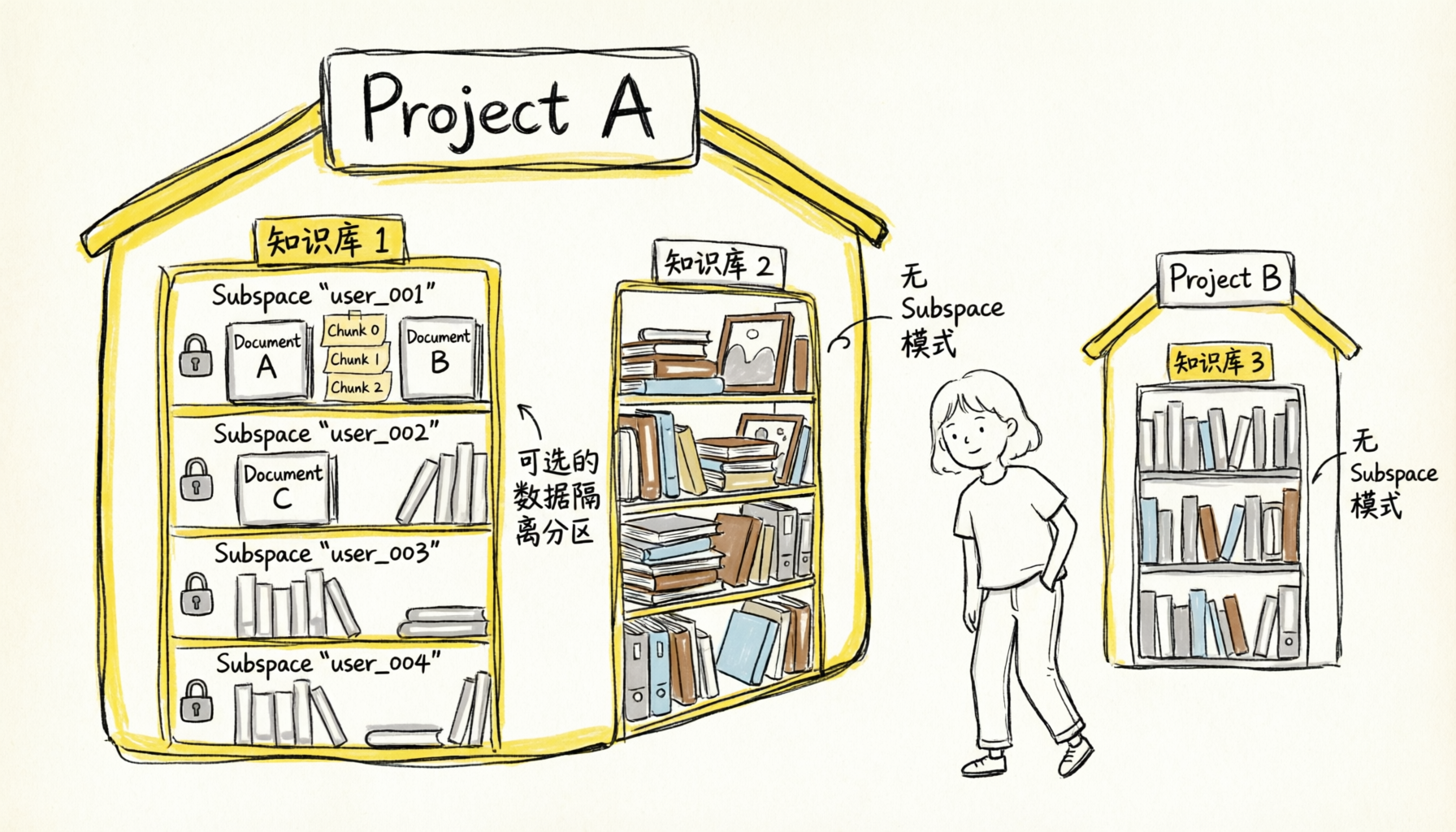
Subspace 多租户
Subspace 是知识库内的数据隔离分区,适用于在同一知识库内按用户、部门或租户隔离数据的场景。创建知识库时设置 "subspace": true 开启。
核心规则:
开启 Subspace 后,所有文档操作(添加/查询/删除/列出)和检索都必须指定
subspace字段,否则报错。Retrieve 支持同时查询多个 Subspace(传入列表),最多 32 个。
Subspace 名称最大长度 128 字符。
Subspace 开关创建后不可修改。
在企业环境中,同一部门的每位员工有各自的文档。部门管理员创建一个知识库并开启 Subspace,为每位员工分配一个独立的 Subspace(如 employee_zhangsan、employee_lisi)。每位员工的文档互不可见,管理员统一管控知识库配置。当需要跨员工检索时,在 Retrieve 时传入多个 Subspace 即可联合检索。
Subspace 与多知识库的选择
维度 | Subspace | 多知识库 |
隔离粒度 | 同一知识库内的逻辑分区 | 完全独立的知识库 |
Embedding 配置 | 共享同一配置 | 每个知识库独立配置 |
检索范围 | 可跨 Subspace 联合检索 | 只能在单个知识库内检索 |
管理成本 | 低(一个知识库管理所有租户) | 高(需管理多个知识库) |
适用场景 | 同质化数据的多租户隔离 | 不同业务域、不同 Embedding 需求 |
配额与限制
知识库
限制项 | 限制值 |
单 Project 知识库数量 | 最大 256 |
单知识库文档数 | 最大 1 亿 |
知识库名称长度 | 1–64 字符,字母开头,仅允许字母/数字/下划线 |
知识库描述长度 | 最大 4KB |
Tags 总长度 | 最大 4KB |
Metadata 字段数 | 最多 200 个 |
Metadata 字段名长度 | 最大 128 字符 |
文档
限制项 | 限制值 |
单文件大小 | 最大 50MB |
单请求文档数(AddDocuments) | 最多 10 个 |
Metadata 总大小(key + value) | 最大 4KB |
Subspace 名称长度 | 最大 128 字符 |
ListDocuments 的 Subspace 列表 | 最多 10 个 |
检索
限制项 | 限制值 |
检索文本长度 | 最长 128 字符或汉字 |
Retrieve 的 Subspace 列表 | 最多 32 个 |
向量检索返回数量 | 最大 100 |
全文检索返回数量 | 最大 100 |
切片更新
限制项 | 限制值 |
单请求切片更新数 | 最多 10 个 |
分页
接口 | maxResults 默认值 | maxResults 最大值 |
ListKnowledgeBase | 10 | 100 |
ListDocuments | 10 | 1000 |
ListChunks | 10 | 1000 |
支持文档格式
格式 | 扩展名 |
| |
Word |
|
Excel |
|
PowerPoint |
|
纯文本 |
|
Markdown |
|
适用性评估
推荐使用的场景:
为 LLM 应用构建 RAG 检索能力
需要向量检索 + 全文检索的混合检索
需要多租户数据隔离
文档规模从几百到百亿级
对数据安全有严格要求(数据不出自己的账户)
希望按量付费、零运维
需要评估的场景:
对文档索引实时性要求极高(文档上传到可检索是异步过程,存在处理延迟)
需要自定义切片策略(当前为系统自动切片)
不推荐的场景:
纯结构化数据查询(建议使用表格存储宽表模型或关系型数据库)
需要实时流式数据索引(建议直接使用Tablestore多元索引)