
表格存储按小时对实例的数据存储量计费,计费依据为该小时内的平均数据量。
实例的数据总量等于所有表的数据量之和;表的数据量等于所有行的数据量之和;每行的数据量等于主键列与属性列的数据量之和。
关于最新的单价信息,请参见表格存储价格详情页。
下面分别介绍行数据量和表数据量的计算方式。
计算行数据量
每行数据的存储空间由主键列和属性列共同决定:
单行数据量=主键列的数据量+所有属性列的数据量
主键列的数据量=主键列的名字长度之和+主键列的值的数据量之和
属性列的数据量取决于 MaxVersions 和 TTL(Time to Live)设置,详见下方示例。
各数据类型的字节数
|
数据类型 |
字节数 |
|
String |
UTF-8 字符串占用的字节数。空字符串的数据大小为 0。 |
|
Integer |
8 |
|
Double |
8 |
|
Boolean |
1 |
|
Binary |
二进制数据占用的字节数 |
提示:属性列名越短,存储费用越低。例如,列名Name(4 字节)比CustomerName(12 字节)每行节省 8 字节的存储开销。
示例:行数据量计算
以下示例中,数据表主键列为 ID(Integer 类型),其他均为属性列。
|
ID |
Name |
Length |
Comments |
|
1 |
timestamp=1466676354000,value='zhangsan' |
timestamp=1466676354000,value=20 |
timestamp=1466676354000,value=String(100 Bytes) timestamp=1466679954000,value=String(150 Bytes) |
Comments 列存有两个版本的数据,计算方式因 MaxVersions 和 TTL 设置而不同。
-
场景一:MaxVersions=2,TTL=2592000
开启多版本(MaxVersions>1)或设置 TTL(TTL>-1)时,每个版本号以时间戳形式存储,占用 8 字节。
单个属性列的数据量=
(属性列名字长度+8)× 有效版本数+该属性列所有有效版本的值数据量之和说明在使用多版本(即Max versions>1)或者使用了TTL(即TTL > -1)的场景下,每个版本号需要占用8字节(以下提到的timestamp等同于版本号)。
该行数据量=10+20+22+282=334 Bytes,详情如下:
主键列(ID):
len('ID')+len(1)=10 Bytes属性列 Name:
(len('Name')+8)×1+len('zhangsan')=20 Bytes属性列 Length:
(len('Length')+8)×1+len(20)=22 Bytes属性列 Comments(2 个版本):
(len('Comments')+8)*2+100+150=282 Bytes
-
场景二:MaxVersions=1,TTL=-1
MaxVersions=1 且 TTL=-1(不启用 TTL)时,版本号不占用字节。
单个属性列的数据量=
属性列名字长度+属性列的值的数据量之和说明不使用多版本(即Max versions=1)且不使用TTL(即TTL=-1)时,版本号不占用字节。
虽然 Comments 列存有两个版本,但 MaxVersions=1,只计算最新版本。
该行数据量=10+12+14+158=194 Bytes,详情如下:
主键列(ID):
len('ID')+len(1)=10 Bytes属性列 Name:
len('Name')+len('zhangsan')=12 Bytes属性列 Length:
len('Length')+len(20)=14 Bytes属性列 Comments(仅最新版本):
len('Comments')+150=158 Bytes
计算表数据量
表的数据量等于所有行的数据量之和。以下示例中,ID 为主键列,其他均为属性列,MaxVersions=2,TTL=-1。
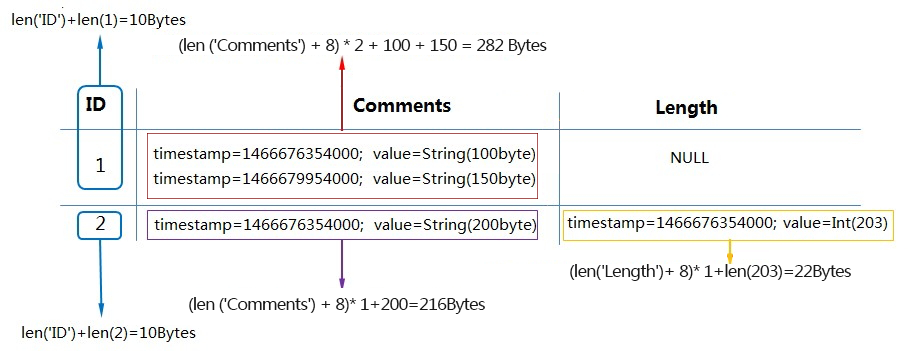
ID=1 的行:292 Bytes — 主键列 10 Bytes + Comments 属性列两个版本 282 Bytes。
ID=2 的行:248 Bytes — 主键列 10 Bytes + Comments 属性列一个版本 216 Bytes + Length 属性列一个版本 22 Bytes。
该表的数据总量为 292+248=540 Bytes。若一小时内数据量未发生变化,将按 540 Bytes 计费。
表格存储对单表数据存储量没有限制,按实际用量计费。
表格存储会异步清理各分区中已过期的数据及超过 MaxVersions 的版本数据,清理完成后重新统计该分区的数据量。清理时长与总数据量相关,一般在 24 小时内完成。清理操作完成后新写入的数据,将在下一次清理操作后计入该分区数据量。
存储量统计周期
存储量计量存在一定延迟,一般在 24 小时内完成统计。
延迟原因
表格存储基于 LSM(Log-Structured Merge-tree)架构实现,数据以追加写入方式先存入内存,达到一定条件后转存为磁盘上的小文件。对同一行数据的多次更新和删除操作可能分散在多个文件中,直接汇总所有文件大小会导致重复计量。
为保证计量准确,表格存储在 Compaction(合并操作)完成后才重新计算数据量。Compaction 会定期合并小文件并清除冗余数据。
因此,数据写入、更新或删除后,短期内表的存储量可能不会立即变化。存储量统计周期与系统执行 Compaction 的周期一致。