
消息(Timeline)模型是针对消息数据场景所设计的,能够满足消息数据场景对消息保序、海量消息存储、实时同步的业务需求,同时支持全文检索与多维度组合查询。适用于IM、Feed流等消息场景。
模型结构
消息模型以简单为设计目标,核心模块构成比较清晰明了。消息模型尽量提升使用的自由度,让您能够根据自身场景需求选择更为合适的实现。消息模型的架构主要包括:
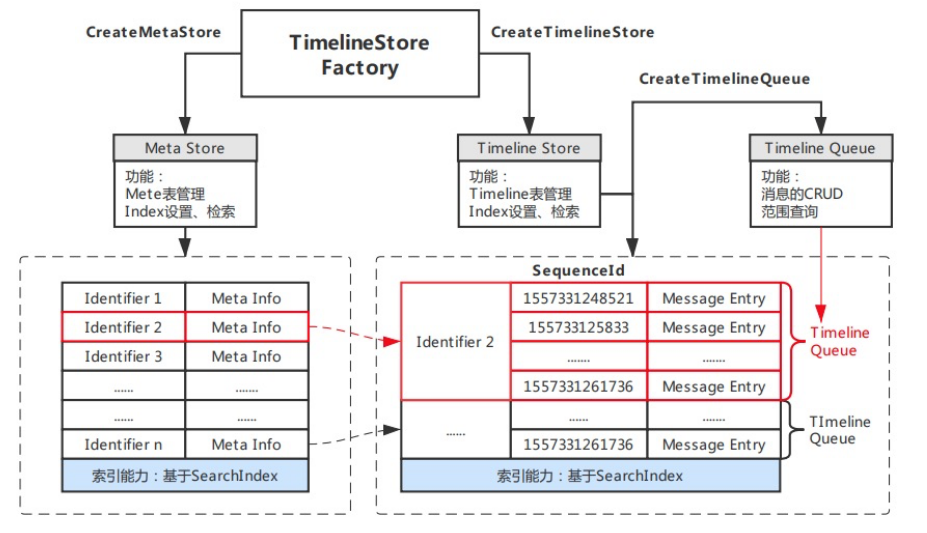
Store:Timeline存储库,类似数据库的表的概念。
Identifier:用于区分Timeline的唯一标识。
Meta:用于描述Timeline的元数据,元数据描述采用free-schema结构,可自由包含任意列。
Queue:一个Timeline内所有Message存储在Queue内。
SequenceId:Queue中消息体的序列号,需保证递增、唯一。模型支持自增列、自定义两种实现模式。
Message:Timeline内传递的消息体,是一个free-schema的结构,可自由包含任意列。
Index:包含Meta Index和Message Index,可对Meta或Message内的任意列自定义索引,提供灵活的多条件组合查询和搜索。
功能介绍
消息模型支持以下功能。
支持Meta、消息的基本管理(数据的CRUD)。
支持Meta、消息的多维组合查询、全文检索。
支持SequenceId的两种设置:自增列、手动设置。
支持多列的Timeline Identifier。
兼容Timeline 1.X模型,提供的TimelineMessageForV1样例可直接读写V1版本消息。
注意事项
当您在Maven项目中引用Tablestore Java SDK的依赖时,需根据版本号进行如下设置。
4.12.1(含)之后的SDK(已合入消息模型到SDK中),只需要引用Tablestore依赖。
<dependency> <groupId>com.aliyun.openservices</groupId> <artifactId>tablestore</artifactId> <version>4.12.1</version> </dependency>4.12.1之前的SDK,引用Tablestore依赖后,还需要单独引用Timeline依赖。
<dependency> <groupId>com.aliyun.openservices.tablestore</groupId> <artifactId>Timeline</artifactId> <version>2.0.0</version> </dependency>
解决方案
Feed流产品被广泛应用于各种主流应用中,例如微博、资讯推荐、短视频推荐等。使用消息模型打造一个千万级Feed流系统,请参见如何打造千万级Feed流系统。
基于消息模型构建的现代IM系统,例如钉钉,能够同时支持消息系统的多种特性,包括多端同步、消息漫游和在线检索,在性能和规模上能够实现全量消息云端存储和索引、百万TPS写入以及毫秒级延迟的消息同步和检索能力。更多信息,请参见基于表格存储的消息模型实现钉钉的IM功能。