
本文介绍了对接Structured Streaming微批模式的过程以及表格存储对接Spark Structured Streaming的详细接入流程。
背景信息
在对接Spark Structured Streaming的微批模式时,此处以Spark DataSource v1接口为例说明过程。
调用GetOffset方法获取当前批次可以读取到的最大Offset(EndOffset)。
调用GetBatch方法获取当前批次的StartOffset(上一个批次的EndOffset)到EndOffset间的数据并进行转换。
执行自定义的Spark计算逻辑。
在此种微批模式对接中,上游数据库的流式接口需要提供灵活且准确的Seek功能,能够实时获取到每个分区的起始游标或结束游标等,从而进行Spark微批模式中Offset的预估。
在分布式NoSQL数据库中,对于基于数据捕获变更(CDC)技术的流式接口,该接口是一种持续流的模式,通常不具备灵活的Seek接口,对接Structured Streaming的微批接口有较大的难度。如果在GetOffset阶段进行提前的数据拉取,可以获取到预期的EndOffset,但是需要提前进行一次额外的RDD的计算并将其进行持久化缓存,大大降低了Source的性能。
接入流程
下图为表格存储对接Structured Streaming方案的UML时序图。
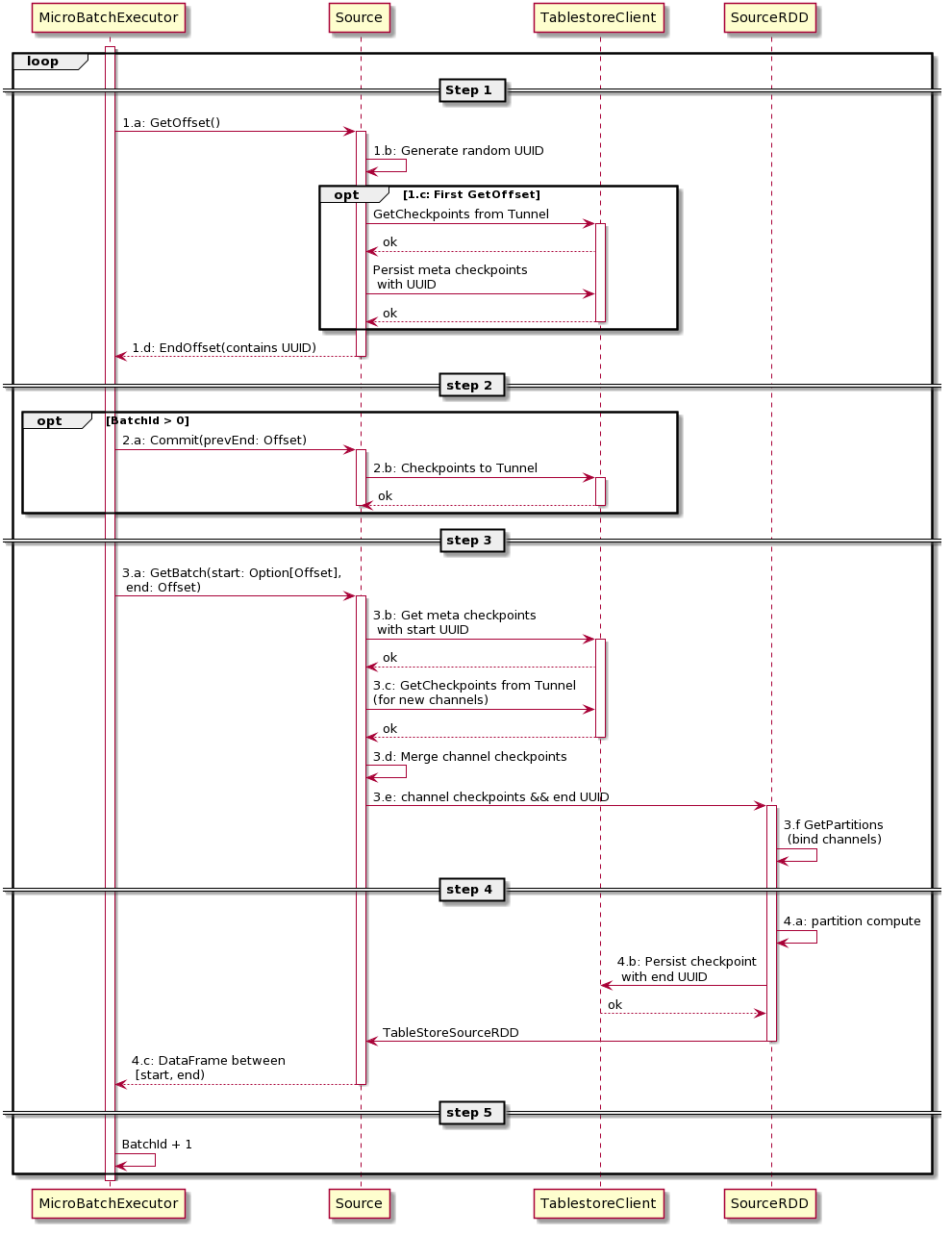
图中MicroBatchExecutor为Spark的微批处理框架,Source为Structured Streaming抽象的接口类,SourceRDD为Spark的RDD抽象类,TablestoreClient为表格存储的客户端。实线表示详细操作,虚线表示请求成功返回。
从整体上看,时序流程是GetOffset、 Commit和GetBatch三个步骤的循环执行,分别对应于Spark Streaming的一个Batch执行。
详细接入流程步骤说明如下:
调用GetOffset方法获取当前批次可以读取到的最大Offset(EndOffset)。
MicroBatchExecutor调用Source中GetOffset方法,获取当前批次的最大可达Offset,即EndOffset。
Source中生成一个随机的UUID字符串,UUID会与Offset一一对应。
(可选)获取表格存储的通道信息。
说明只有首次调用Source中GetOffset方法时,才执行此步骤;否则系统会跳过此步骤。
从表格存储的Tunnel服务端获取当前所有Channel(分区)的消费位点(Checkpoint)。
将获取到所有Channel的消费位点持久化到Meta表中,建立UUID和checkpoints的映射关系。
将UUID包装成Offset(Offset与UUID可以互相转换),并返回给MicroBatchExecutor作为当前批次的EndOffset。
(可选)将checkpoints持久化到Tunnel服务端。
说明只有当前批次的BatchId大于0时,才执行此步骤;否则系统会跳过此步骤
MicroBatchExecutor调用Source的Commit逻辑。
将上一个批次的EndOffset(当前批次的StartOffset)对应的checkpoints持久化到Tunnel服务端。
说明正常情况下Commit逻辑无需处理额外内容,此操作的目的如下:
持久化到Tunnel服务端后,可以实时显示消费进度。
Tunnel为了实现数据保序有父子分区关系,需要由客户端将父分区已消费结束checkpoint返回服务端,子分区才能加载。
调用GetBatch方法获取当前批次的StartOffset(上一个批次的EndOffset)到EndOffset间的数据并进行转换。
MicroBatchExecutor根据当前批次的StartOffset和GetOffset返回的EndOffset调用Source中的GetBatch操作,以期获得当前批次的数据,供计算逻辑使用。
根据StartOffset对应的UUID从Meta表中获取Tunnel对应的Channel列表的实时消费位点。
从Tunnel服务端定时获取Channel的消费位点。
由于表的分区变化可能会存在新的分区(例如子分区),所以需要定时获取Channel的消费位点。
合并从Meta表中获取的实时消费位点和从Tunnel服务端定时获取消费位点checkpoints,得到当前所有Channel的消费位点。
根据最新的checkpoints和EndOffset对应的UUID等信息来构建SourceRDD。
RDD是Spark中最基本的数据抽象,它代表一个不可变、可分区、元素可并行计算的集合。
在SourceRDD中将通道的channel和RDD的partition进行绑定,因此每个Channel都会在Spark的执行节点上分布式地进行数据并行转换和处理。
执行自定义的Spark计算逻辑。
执行每个RDD partition上的计算逻辑,此处会进行channel上的数据读取,并更新内存中的每个channel的消费位点。
每个RDD partition在本批次执行完成后(例如读到指定条数或无新数据),将channel对应的最新消费位点持久化到Meta表对应UUID的行中,即填充EndOffset对应UUID的checkpoints,每个批次结束后,新的批次的StartOffset对应的checkpoints都能够在Meta表中查询到。
待所有RDD partition的计算逻辑完成后,返回当前批次对应Offset范围内的数据给MicroBatchExecutor。
当前批次的所有逻辑计算完成后,递增BatchId,从步骤1重新开始,循环执行。