如何设计时间线结构提升查询效率
本文介绍通过设计时间线结构提升查询效率。
时间线概念
在TSDB里,我们将一个指标+一组标签组合称为一条时间线。在一条时间线下面,连续时间点的采样数据则为时序数据。比如:{“metric”:“cpu”,“tags”:{“site”:“et2”,“ip”:“1.1.1.1”,“app”: “TSDB”} }这个metric+tags的组合为一条时间线,在同一条时间线下面产生连续的(timestamp,value)。例如,下图有3条时间线: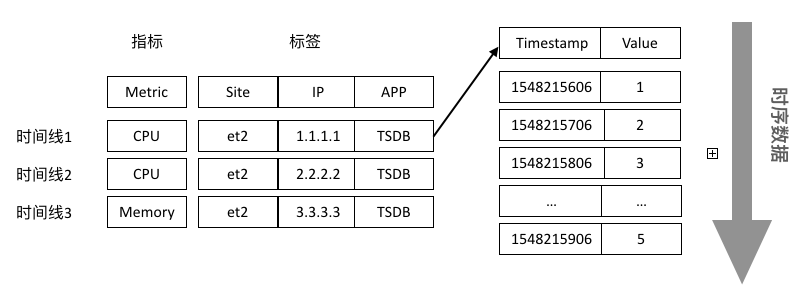
时间线倒排索引概念
为了加速查询,TSDB会给每一条时间线都生成倒排索引。具体来说,TSDB会给时间线上的每个tag、metric生成索引,索引到该tag、metric对应到的时间线上。例如,在时间线概念里出现的3条时间线,会生成如下所示的倒排索引:
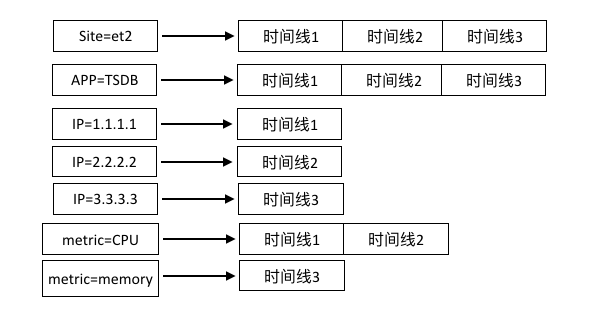
最佳实践
减少时间线数量
在TSDB中,唯一决定时间线的有如下因素:
metric相同。
tags数量相同。
每一个tag的TagKey和TagValue都相同。
说明在设计时间线的tag的TagValue时,不建议将进程ID或时间戳设置为TagValue,需要让同一tag的Value值变化尽可能少。TagValue如果设计得有误,即便metric,TagKey都没有显著变化时,时间线数量也有可能飞速膨胀。
字段名 (仅在使用多值模型时)。
线数量的上限等于metric和tag的集合的笛卡尔积(若是多值模型时,还需要加上field的集合)。因此,建议用户在设计时间线时,尽量减少metric或者tag的变化,以免时间线不断膨胀,超过规格限制。
减少单个Tag 标签索引时间线量
避免在每一条时间线上都设置一个相同的标签,以免该标签索引的时间线数量过多,影响查询时的性能。
减少查询时间线覆盖
如果标签1索引的时间线的集合是标签2的子集,那么查询时可以只使用标签1,以提升查询性能。例如,在上面的例子中,若我们想查询时间线1的数据,有如下两种查询方式:
方式一:
{“metric”:“cpu”,”tags”:{“site”:“et2”,“ip”:“1.1.1.1”,“app”:“TSDB”} }方式二:
{“metric”:“cpu”,”tags”:{“ip”:“1.1.1.1”} }查询方式二只使用了1个标签,因为
ip=1.1.1.1这个标签只索引了1条时间线。因此,相比查询方式一,查询方式二的性能反而是更好的。
- 本页导读 (1)