数据传输服务DTS(Data Transmission Service)提供的数据同步功能简单易用,您只需在控制台上进行简单操作,即可完成整个数据同步任务的配置。
首次使用数据同步功能时,请阅读数据同步操作指导,帮助您快速掌握创建、监控、管理数据同步任务的操作。
注意事项
本文仅简单介绍数据同步任务的通用配置流程,不同的数据源在配置数据同步任务时略有不同。关于各类数据源的详细配置案例,请参见同步方案概览。
准备工作
数据同步的源数据库为PolarDB MySQL或自建MySQL时,须开启其binlog功能。详情请参见开启Binlog和为自建MySQL创建账号并设置binlog。
操作步骤
根据待同步的源实例、目标实例的数据库类型和地域信息购买数据同步任务,详情请参见购买流程。
登录数据传输控制台。
说明若数据传输控制台自动跳转至数据管理DMS控制台,您可以在右下角的
 中单击
中单击 ,返回至旧版数据传输控制台。
,返回至旧版数据传输控制台。在左侧导航栏,单击数据同步。
在同步作业列表页面顶部,选择数据同步实例所属地域。
定位至已购买的数据同步实例,单击该实例的配置同步链路。
配置同步通道的源实例及目标实例信息。
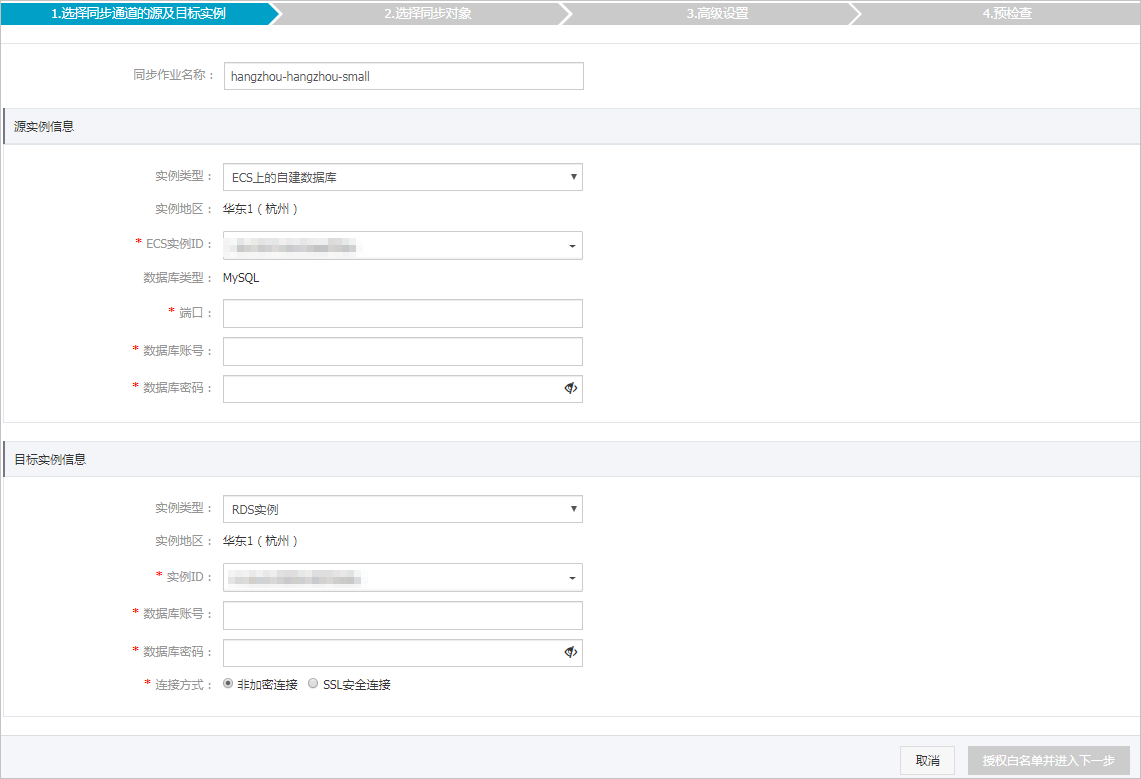
上述配置完成后,单击授权白名单并进入下一步。
说明当源实例或者目标实例为阿里云实例时,此步骤会将DTS服务器的IP地址自动添加到源实例或者目标实例的白名单中,用于保障DTS服务器能够正常连接实例。
配置同步策略及对象信息,配置完成后单击页面右下角的下一步。
配置项目
配置说明
选择同步对象
在源库对象框中单击待同步的对象,然后单击
 图标将其移动至已选择对象框。
图标将其移动至已选择对象框。同步对象的选择粒度为库、表。
说明如果选择整个库作为同步对象,该库中所有对象的结构变更操作都会同步至目标库。
默认情况下,同步对象在目标库中的名称与源库保持一致。如果您需要改变同步对象在目标库中的名称,需要使用对象名映射功能,详情请参见设置同步对象在目标实例中的名称。
映射名称更改
如需更改同步对象在目标实例中的名称,请使用对象名映射功能,详情请参见库表列映射。
源表DMS_ONLINE_DDL过程中是否复制临时表到目标库
如源库使用数据管理DMS(Data Management)执行Online DDL变更,您可以选择是否同步Online DDL变更产生的临时表数据。
是:同步Online DDL变更产生的临时表数据。
说明Online DDL变更产生的临时表数据过大,可能会导致同步任务延迟。
否:不同步Online DDL变更产生的临时表数据,只同步源库的原始DDL数据。
说明该方案会导致目标库锁表。
源、目标库无法连接重试时间
当源、目标库无法连接时,DTS默认重试720分钟(即12小时),您也可以自定义重试时间。如果DTS在设置的时间内重新连接上源、目标库,同步任务将自动恢复。否则,同步任务将失败。
说明由于连接重试期间,DTS将收取任务运行费用,建议您根据业务需要自定义重试时间,或者在源和目标库实例释放后尽快释放DTS实例。
配置同步初始化的高级配置信息。

上述配置完成后,单击页面右下角的预检查并启动。
说明在同步任务正式启动之前,会先进行预检查。只有预检查通过后,才能成功启动同步任务。
如果预检查失败,单击具体检查项后的
 ,查看失败详情。
,查看失败详情。您可以根据提示修复后重新进行预检查。
如无需修复告警检测项,您也可以选择确认屏蔽、忽略告警项并重新进行预检查,跳过告警检测项重新进行预检查。
在预检查对话框中显示预检查通过后,关闭预检查对话框,该同步任务正式开始。
等待该同步任务的链路初始化完成,直至状态处于同步中。
您可以在 数据同步页面,查看数据同步状态。
