本文介绍E-MapReduce(简称EMR)的产品架构,以便您直观的了解EMR的产品组成。
EMR的产品架构如下图所示。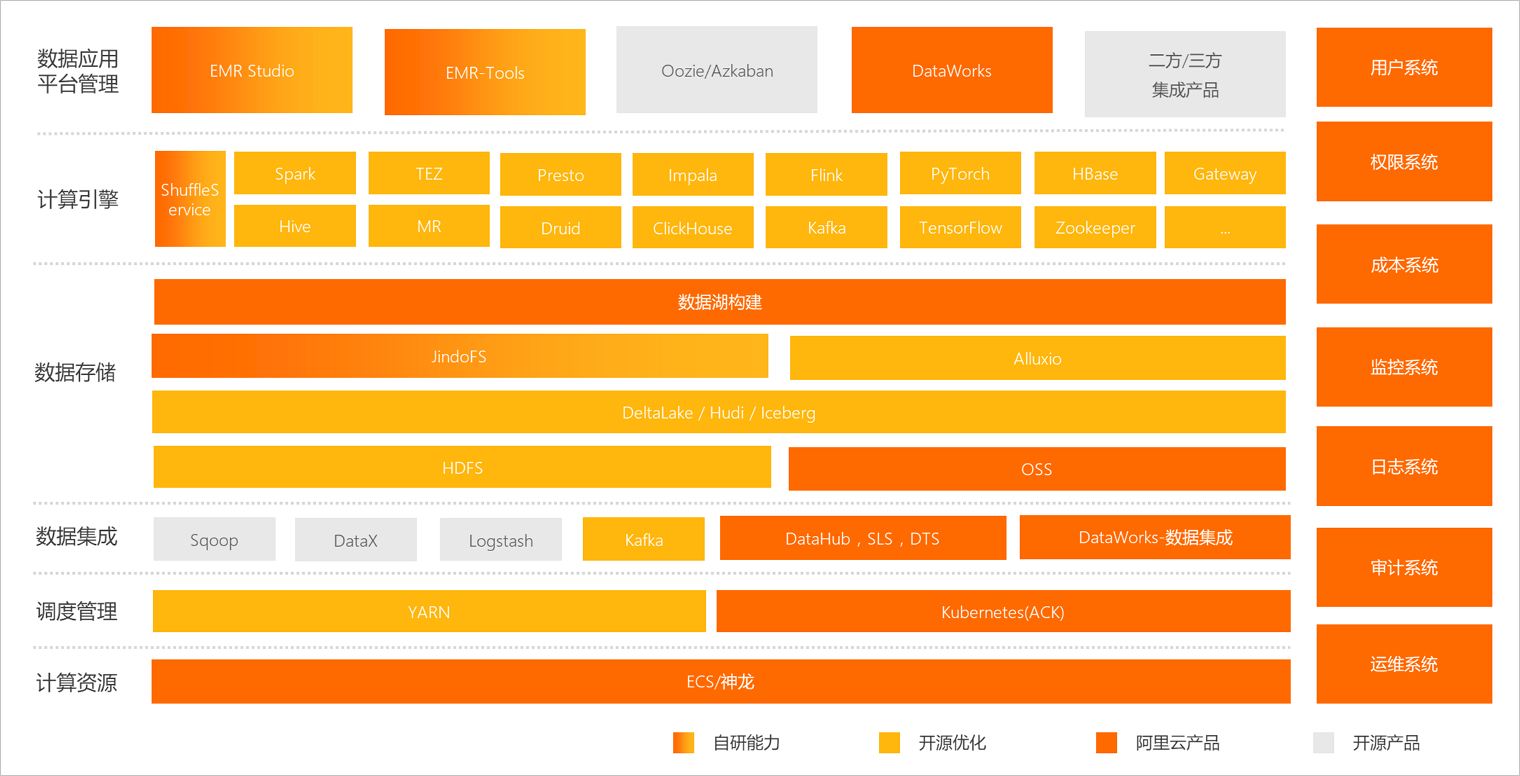
从上图可以看出EMR由四部分组成:
社区开源产品
集成Apache社区开源大数据组件,例如Hadoop、Hive和HBase,随着EMR版本更新,开源软件也会相应的升级,详情请参见版本概述下各版本的版本说明。
重要已经创建好的EMR集群不支持组件升级。
EMR开源优化
EMR基于开源社区版本的组件,增强了其性能和功能。例如,Delta Lake相较开源版本增加了ZOrder和Data Skipping能力,详情请参见Delta Lake概述。
EMR自研能力
为让开源大数据组件和服务更好的运行在阿里云技术设施上,EMR自研了如下组件:
数据应用平台,提供交互式开发、作业提交、作业调试和工作流一站式数据开发体验,详情请参见EMR Studio概述。
Shuffle Service是EMR在优化计算引擎的Shuffle操作上,推出的扩展组件,详情请参见ESS概述。
SmartData,为EMR各个计算引擎提供统一的存储优化、缓存优化、计算缓存加速优化和多个存储功能扩展,详情请参见SmartData。
阿里云产品
EMR衔接了开源大数据生态和阿里云生态。EMR可以部署在阿里云ECS(Elastic Compute Service)和Kubernetes(简称ACK)上;数据可以存储在阿里云OSS上;通过在EMR上创建Data Science集群可以使用及学习机器学习PAI;EMR集成在DataWorks,您可以在DataWorks上使用EMR作为作业计算和数据存储引擎。
文档内容是否对您有帮助?