本文为您介绍如何通过阿里云账号登录E-MapReduce(简称EMR)控制台,快速创建一个DataLake集群并执行作业。
前提条件
注意事项
代码的运行环境由所属用户负责管理和配置。
操作流程
在EMR控制台,快速创建一个DataLake集群。
集群创建成功后,您可以创建并执行Spark类型的作业。
提交作业后,您可以通过YARN UI方式查看作业运行记录。
如果不再使用该集群,可以释放集群以节约成本。
步骤一:创建集群
进入创建集群页面。
在顶部菜单栏处,根据实际情况选择地域和资源组。
地域:创建的集群会在对应的地域内,一旦创建不能修改。
资源组:默认显示账号全部资源。
单击上方的创建集群。
在创建集群页面,完成集群相关配置。
配置区域
配置项
示例
描述
软件配置
地域
华东1(杭州)
集群节点ECS实例所在的物理位置。
重要集群创建后,无法更改地域,请谨慎选择。
业务场景
数据湖
选择适合的业务场景,创建集群时阿里云EMR会自动为您配置默认的组件、服务和资源,以简化集群配置,并提供符合特定业务场景需求的集群环境。
产品版本
EMR-5.14.0
当前最新的软件版本。
服务高可用
不开启
默认不开启。打开服务高可用开关后,EMR会把Master节点分布在不同的底层硬件上以降低故障风险。
可选服务
HADOOP-COMMON、 OSS-HDFS、YARN、Hive、Spark3、Tez、Knox和OpenLDAP。
根据您的实际需求选择组件,被选中的组件会默认启动相关的服务进程。
说明除过集群默认的服务,还需选择Knox和OpenLDAP服务。
允许采集服务运行日志
开启
支持一键开启或关闭所有服务的日志采集。默认开启,将收集您的服务运行日志,这些日志仅供集群诊断使用。
集群创建后,您可以在基础信息页面,修改服务运行日志收集状态。
重要关闭日志采集后,EMR的健康检查和技术支持将受到限制,但其他功能仍可正常使用。如何关闭及影响详情,请参见如何停止采集服务日志?。
元数据
DLF统一元数据
表示元数据存储在数据湖构建DLF中。
系统会为您选择默认的DLF数据目录,如果您不同集群期望使用不同的数据目录,可以单击创建数据目录。
说明选择该方式时,需要开通阿里云数据湖构建服务。
集群存储根路径
1366993922******
当您在可选服务区域选择了OSS-HDFS服务时,需要配置该参数,如果选择的是HDFS服务,则无需配置该参数。
说明在选择使用OSS-HDFS服务之前,请确保您选择的地域支持该服务。否则,您可以尝试更换地域或使用HDFS服务替代OSS-HDFS服务。OSS-HDFS服务目前支持的地域信息,请参见开通并授权访问OSS-HDFS服务。
EMR-5.12.1及后续版本,EMR-3.46.1及后续版本的DataLake、DataFlow、DataServing和Custom集群,支持选择OSS-HDFS服务。
硬件配置
付费类型
按量付费
在测试场景下,建议使用按量付费,测试正常后可以释放该集群,再新建一个包年包月的生产集群正式使用。
可用区
可用区 I
集群创建后,无法直接更改可用区,请谨慎选择。
专有网络
vpc_Hangzhou/vpc-bp1f4epmkvncimpgs****
选择对应区域下的专有网络。如果没有,单击创建VPC前往新建。创建专有网络完成后,单击刷新,可以选择刚创建好的VPC。
交换机
vsw_i/vsw-bp1e2f5fhaplp0g6p****
选择在对应专有网络下可用区的交换机,如果在这个可用区没有可用的交换机,则需要新创建一个。
默认安全组
sg_seurity/sg-bp1ddw7sm2risw****
重要禁止使用ECS上创建的企业安全组。
如果已有在使用的安全组,则可以直接选择使用。您也可以新建一个安全组。
节点组
打开Master节点组下的挂载公网开关,其余使用默认值即可。
您可以根据业务诉求,配置Master节点组、Core节点组或Task节点组信息。详情请参见选型配置说明。
基础配置
集群名称
Emr-DataLake
集群的名字,长度限制为1~64个字符,仅可使用中文、字母、数字、短划线(-)和下划线(_)。
身份凭证
密码。
用于远程登录集群的Master节点。
登录密码和确认密码
自定义密码。
请记录该配置,登录集群时您需要输入该密码。
选中服务协议,单击确认订单。
在EMR on ECS页面,当集群状态显示为运行中时,表示集群创建成功。更多集群参数信息,请参见创建集群。
步骤二:创建并执行作业
集群创建成功后,您可以在该集群创建并执行作业。
通过SSH方式连接集群,详情请参见登录集群。
在命令行执行以下命令,提交并运行作业。
本文以Spark 3.1.1版本为例,输入的命令示例如下。
spark-submit --class org.apache.spark.examples.SparkPi --master yarn --deploy-mode client --driver-memory 512m --num-executors 1 --executor-memory 1g --executor-cores 2 /opt/apps/SPARK3/spark-current/examples/jars/spark-examples_2.12-3.1.1.jar 10说明spark-examples_2.12-3.1.1.jar为您集群中对应的JAR包名称,您可以登录集群,在/opt/apps/SPARK3/spark-current/examples/jars路径下查看。
步骤三:查看作业运行记录
提交作业后,您可以通过YARN UI方式查看作业运行记录。
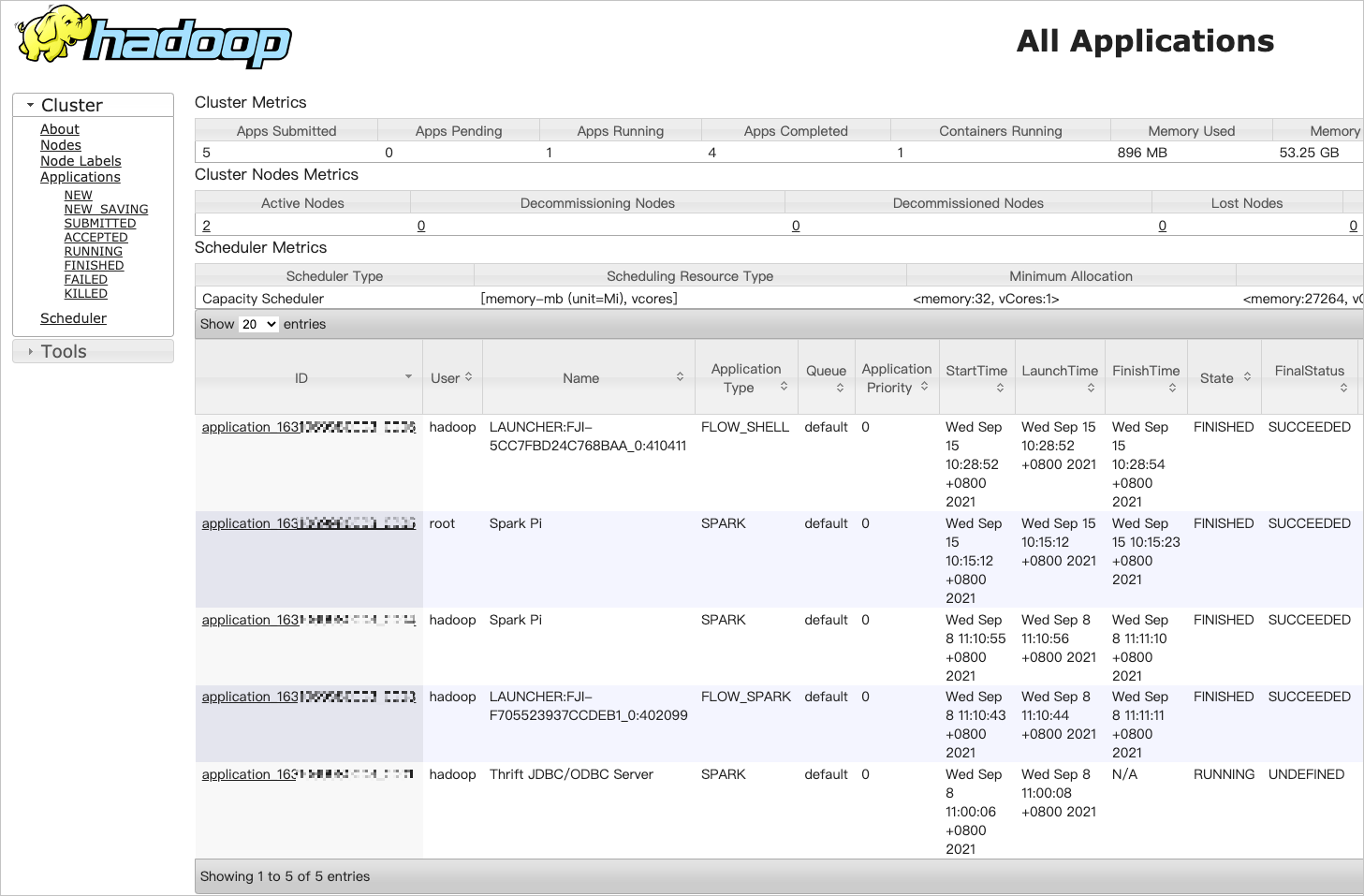
(可选)步骤四:释放集群
如果您创建的集群不再使用时,可以释放集群节约成本。确认集群释放后,系统会对集群进行如下处理:
强制终止集群上的所有作业。
终止并释放所有的ECS实例。
这个过程所需时间取决于集群的大小,集群越小释放越快。通常在几秒内可以完成释放,至多不会超过5分钟。
按量付费的集群可以随时释放,包年包月的集群到期后才能释放。
释放集群前,请确保集群状态是初始化中、运行中或空闲。
在EMR on ECS页面,选择目标集群所在行的
 > 释放。
> 释放。您还可以单击目标集群的集群名称,然后在基础信息页面,选择右上角的。
在弹出的对话框中,单击确定。
相关文档
常见问题
了解使用阿里云E-MapReduce的常见问题:常见问题。