
本文汇总了集群管理的常见问题。
扩容时报错“The specified parameter AddNumber is not valid”,该如何处理?
服务类常见问题
EMR Doctor常见问题
EMR集群是否支持升级版本?
EMR集群不支持升级,也不能进行服务的升级。如果有升级需求,请释放集群并重新创建集群。
EMR集群都支持哪些服务?
不同版本、不同集群支持的服务有所不同,详情请参见发行版本。
EMR支持在控制台新增Zeppelin组件吗?
EMR不支持通过控制台以新增服务的方式安装Zeppelin组件。如需新增Zeppelin,您可以在任一Master节点的ECS服务器上进行安装。其他无法在控制台中新增的组件,您也可以在底层ECS服务器上自行安装和维护。有关更多集群场景及其支持新增的服务,请参见新增服务。
EMR支持Oozie服务吗?如果不支持是否有替代方案?
EMR DataLake集群(EMR-5.8.0和EMR-3.42.0及以上版本)不再包含Oozie组件。如果您需要使用工作流调度服务,可以通过EMR Workflow来实现,详情请参见什么是EMR Workflow。
高可用集群为什么部署3个Master节点?
新版EMR高可用集群采用3 Master节点,比2 Master更具可靠性。现在已不支持2 Master节点。
对于高可用集群,EMR会把Master节点分布在不同的底层硬件上以降低故障风险。
EMR支持哪些地域?
当前EMR支持的地域有:华东1(杭州)、华东2(上海)、华北1(青岛)、华北2(北京)、华北3(张家口)、华北5(呼和浩特)、华北6(乌兰察布)、华南1(深圳)、西南1(成都)、中国香港、日本(东京)、新加坡、马来西亚(吉隆坡)、印度尼西亚(雅加达)、德国(法兰克福)、英国(伦敦)、美国(硅谷)、美国(弗吉尼亚)、阿联酋(迪拜)。
如何开启磁盘加密?开启后有什么影响?
您可以在创建集群页面基础配置阶段的高级配置区域,选择是否开启数据盘加密,详情请参见开启数据盘加密。
仅支持在创建集群时开启数据盘加密,集群创建后无法开启该功能。
加密数据盘后,数据盘上的动态数据传输以及静态数据都会被加密。如果您的业务存在安全合规要求,则可以使用该功能。数据盘加密后在ECS的OS层面对应用是透明的,因此不会影响作业运行。
如何清理创建失败的集群?
集群创建失败,通常是由于RDS配置错误导致集群部署失败,或者是由于部分ECS没有库存导致的。
如果在创建过程中,集群已经创建出来部分ECS实例,且集群状态为启动失败,这时需要您前往ECS控制台释放该部分ECS实例,在您的ECS实例全部被释放后,EMR集群将会自动释放。
如果在创建过程中,EMR部署失败,且集群状态为异常终止,此时集群不存在任何资源,也不存在任何收费,您可以单击目标集群操作列的删除,清除该集群。
创建集群后,还支持新增服务吗?
EMR支持在集群创建成功后新增部分未安装的服务,详情请参见新增服务。
新增服务后,因为部分服务需要手动修改配置并进行重启,所以请在业务低峰期进行新增服务操作。
因为各版本的服务有差异,所以具体待添加的服务请以控制台界面显示为准。
修改服务配置后,是否需要重启服务?
EMR集群的Spark、Hive、HDFS等服务端类型配置修改后,需要重启服务才能生效。EMR集群的客户端类型配置修改后,只需要单击部署客户端配置就能生效,不用重启服务。修改或添加配置项的具体操作请参见管理配置项。
如何查询EMR集群有哪些节点?
您可以通过ListNodes接口查询EMR集群节点列表,详情请参见ListNodes - 查询节点。
EMR的滚动重启是什么意思?
滚动重启机制是指在一个ECS实例重启完成且该实例上的大数据服务全部恢复后,再启动下一个ECS实例。每个节点重启耗时约5分钟。
集群创建后如何绑定公网IP?
您可以单独申请EIP地址,并绑定到未分配公网IP地址的专有网络VPC类型的实例上,使ECS实例可以通过公网访问,详情请参见绑定EIP。
什么场景下开启部署集?
部署集是阿里云ECS(Elastic Compute Service)提供的能力,用于控制ECS实例分布的策略。建议为使用本地盘机型的Core节点组开启部署集功能来提升数据安全性。开启部署集可防止多个ECS实例部署在同一个物理机上,避免当某个物理机发生故障时影响多个ECS实例,导致EMR本地HDFS数据丢失。
受ECS部署集本身的限制,目前最多支持20台ECS实例加入部署集。具体操作请参见开启部署集。
扩容集群如何指定部署集?
默认本地盘机型会开启部署集,其他机型关闭部署集,您可以根据需要自行调整。开启部署集的具体操作,请参见开启部署集。
扩容集群如何指定磁盘大小?
扩容时新节点的磁盘大小跟随节点组设定,无法修改。如有需要,您可以调整节点组的磁盘大小。磁盘扩容的具体操作,请参见扩容磁盘。
是否支持磁盘的扩缩容?
仅支持数据盘扩容,不支持数据盘缩容,不支持系统盘扩容或缩容。
您可以在目标集群的节点管理页签,单击目标节点组的磁盘扩容,对数据盘进行扩容。具体操作,请参见扩容磁盘。
是否支持集群的扩缩容?
支持,但不同节点类型的扩缩容规则有所不同:
如何更换节点组中ECS实例的配置?
在更换节点组中ECS实例的配置时,您可以根据实际需求选择提升或降低ECS实例规格。
节点组的机器规格是否支持多选?
节点组的机器规格选择规则如下:
包年包月:仅支持选择单一规格,不可多选。
按量付费或抢占式实例:
如果节点组类型为Task,则最多可选择10个同规格(相同vCPU和内存)的实例作为备选。其他节点组类型(非Task)不可多选。
扩容时报错“The specified parameter AddNumber is not valid”,该如何处理?
问题现象:在集群扩容中遇到报错信息
The specified parameter AddNumber is not valid. add instances number :xxx larger than deploymentSet availableAmount: xxx deploymentSetId: ds-uf6gwfou0a13kekupt14xxxx。问题原因:该错误表示您集群已开启部署集功能,且节点组的节点数已到达部署集上限,部署集详情请参见开启部署集。
解决方法:请联系ECS服务为您当前账号提升部署集上限。
如何停止采集服务日志?
如果您不想EMR收集您的数据,则可以关闭采集服务日志。
关闭日志采集后,EMR的健康检查和技术支持将受到限制,但其他功能仍可正常使用。因此请谨慎选择。
解决方法:
关闭采集服务日志
创建集群时:在创建集群的软件配置阶段,单击允许采集服务运行日志。
创建集群后:在目标集群的基础信息页面的软件信息区域,单击服务运行日志收集状态。
验证关闭情况。
查看/usr/local/ilogtail/user_log_config.json中是否存在
namenode-log信息,不存在则说明服务日志采集已关闭。说明关闭服务日志采集后,大约需要2-3分钟来同步该配置,请耐心等待。
服务运行日志收集哪些信息?
服务运行日志收集仅包括集群服务组件运行的日志。您可以选择一键开启或关闭所有服务日志的采集。需要注意的是,关闭日志采集后,集群的健康检测功能以及售后的技术支持都将受限。
创建集群时默认开启服务运行日志收集,您可以根据需要选择是否关闭该功能。具体操作,请参见如何停止采集服务日志?。
哪些集群类型支持EMR Doctor功能?
仅DataLake和Hadoop集群类型支持健康检查功能。集群创建后,您可以在EMR控制台目标集群的页签使用该功能。
如果您的Hadoop集群没有此功能,则需要开通EMR Doctor,详情请参见开通EMR Doctor(Hadoop集群类型)。
EMR Doctor在安装和升级过程中,是否会对集群组件和集群任务产生影响?
EMR Doctor在安装和升级过程中不会重启任何服务,本身过程也不会对您现有任务产生任何影响,并且在安装结束后,EMR Doctor会将必要参数配置到现有集群中,不需要您再手动进行配置。
EMR Doctor在安装和升级过程中会对YARN、Spark、Tez和Hive服务进行配置整体下发,如果您现有的部分配置只进行了修改保存,并没有下发,则需要您确保下发过程不会对服务造成影响。
EMR Doctor都会采集哪些数据?
EMR Doctor不会采集您的实际数据,也不会扫描您的实际文件和文件内容。
EMR Doctor仅采集必要的事件数据,例如任务启动时间、终止时间、Metrics数据和Counters数据等。
EMR Doctor收费吗?
当前是不收取任何费用的。
采集操作会对任务的运行会产生什么影响?
EMR Doctor存储元数据采集会根据用户资源动态调整采集的资源,不会占用过多用户资源。
EMR Doctor的任务采集使用Java探针技术,不会单独启动Java进程监控。采集使用异步方式,不会阻塞任务主进程,当采集造成的压力过大时,会自动丢弃采集数据,并且您可以根据参数调整采集频率等。
TPC-DS部分测试的数据如下表所示。
SQL及使用引擎 | 使用EMR Doctor采集时间(10次平均) | 不使用EMR Doctor采集时间(10次平均) |
query7(Spark) | 21.0s | 21.2s |
query71(Tez) | 50.8s | 49.8s |
query19(MapReduce) | 68.6s | 68.2s |
本文的TPC-DS的实现基于TPC-DS的基准测试,并不能与已发布的TPC-DS基准测试结果相比较,本文中的测试并不符合TPC-DS的基准测试的所有要求。
什么时候可以看到采集报告?
EMR Doctor自安装和升级之后,日报功能会根据用户运行的任务以及是否采集存储元数据来进行分析,所以集群需要存在负载任务。
对于计算任务:当集群的计算任务被收集后,第二天即可看到最新的报告,报告内容是根据前一天的集群任务运行状态对集群整体进行分析后给出的集群评估建议。
对于存储分析:EMR Doctor默认不启用存储采集分析,您可以手动开启存储采集。开启采集后,通常是上午10点左右进行采集,等待所有采集结束后第二天凌晨才会进行分析并生成报告。如果是当天下午才开启采集,则需要到第三天才能看到结果。
可以给出配置的具体参数值吗?
EMR Doctor给出的建议,采用的是指向性方式。例如,建议减少内存配置和修改GC参数等,并没有给出具体的参数值。因为EMR Doctor采用打点抽样进行采集,尽量避免对您的程序造成影响,即使推荐配置也需要您进行调整,并验证其可行性。
扩容时报错“ECS库存不足”,该如何处理?
问题现象:扩容集群时失败,失败原因显示“ECS库存不足_OutofStock”或“ECS库存不足_OperationDenied.NoStock”。
问题原因:该错误表示您需要扩容的节点组的ECS机型库存不足,无法满足您的扩容需求。
解决方法:您可以等待需要扩容的ECS机型库存充足后再扩容,或者通过新增节点组的方式选择其他ECS机型对集群进行扩容,详情请参见新增节点组。
创建集群时报错“ECS库存不足”,该如何处理?
问题现象:新建集群或新增节点组时失败,失败原因显示“ECS库存不足_OutofStock”或“ECS库存不足_OperationDenied.NoStock”。
问题原因:该错误表示您创建集群或新增节点组时选择的ECS机型库存不足,无法满足需求。
解决方法:在创建集群时选择其他库存充足且满足您业务需求的ECS机型。
如何删除不需要的服务?
目前不支持删除集群已有的服务。一旦服务被启动,您将无法通过控制台或API删除已有的服务。
如何登录集群的节点?
E-MapReduce集群创建后,Master节点可以使用创建集群时设置的密码登录,其余节点的登录方式,请查看登录集群其他节点。
如何查看实例所属交换机?
在阿里云EMR on ECS中,交换机信息与节点组紧密相关,不可在基础信息页面直接查看。您可以在节点管理页面,单击实例所属的节点组名称,查看该实例关联的交换机信息。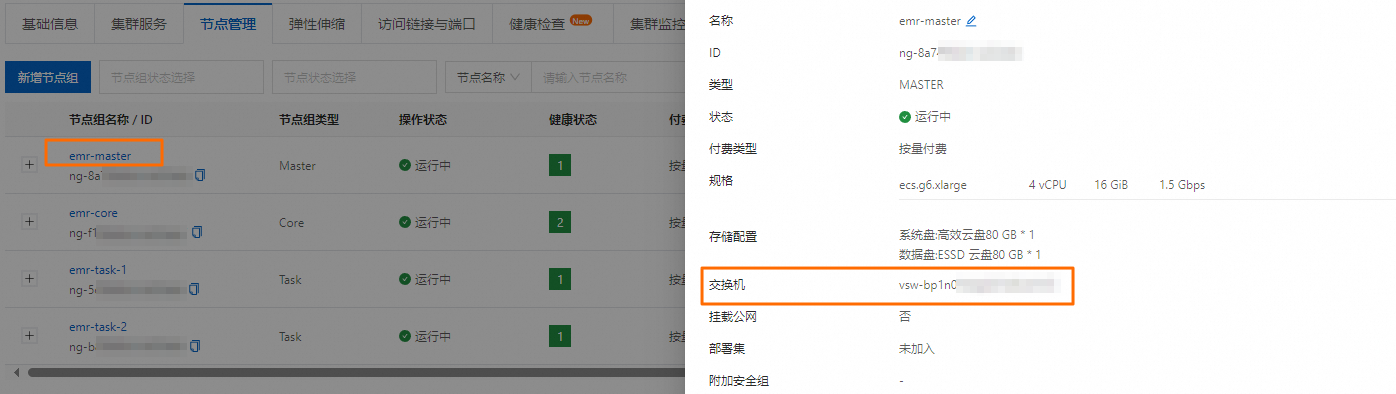
大规模集群网络丢包如何解决?
问题现象:集群中频繁出现网络丢包现象,系统日志中可能会显示错误信息,例如
neighbour: arp_cache: neighbor table overflow!。这表明ARP(Address Resolution Protocol)缓存表达到其容量上限,无法有效管理IP与MAC地址映射,从而导致网络性能问题。问题原因:在大规模分布式系统中,尤其是当单个集群规模超过1000台服务器,并且使用的是EMR-5.18.0之前或EMR-3.52.0之前(不包括这两个版本)时,可能会遭遇网络不稳定及数据丢包的问题。为此,可以通过调整系统参数来优化ARP Cache的管理。
ARP Cache存储IP地址与MAC地址的映射关系,其参数配置如下:
net.ipv4.neigh.default.gc_thresh1:当ARP表小于该值时,不进行垃圾回收。默认值为128。net.ipv4.neigh.default.gc_thresh2:当ARP表超出该值时,5秒内进行垃圾回收。默认值为512。net.ipv4.neigh.default.gc_thresh3:ARP表的最大容量。默认值为1024。
说明由于默认配置较小,导致集群规模超过1000台后,出现网络丢包和不稳定现象,因此需要调整相关配置。
解决方法:
编辑
/etc/sysctl.conf文件,增加以下内容以扩大ARP缓存的容量限制及优化连接跟踪最大值。net.ipv4.neigh.default.gc_thresh1 = 512 net.ipv4.neigh.default.gc_thresh2 = 2048 net.ipv4.neigh.default.gc_thresh3 = 10240 net.nf_conntrack_max = 524288执行命令
sudo sysctl -p,以使新的设置生效。说明如果在执行
sysctl -p命令时遇到错误信息sysctl: cannot stat /proc/sys/net/nf_conntrack_max: No such file or directory,请首先运行命令sudo modprobe nf_conntrack以加载相应模块,然后再尝试使用sysctl -p更新配置。
收到ECS系统事件SystemMaintenance.Redeploy后,应该如何处理?
如果您收到因系统维护实例重新部署(SystemMaintenance.Redeploy)类型的本地盘实例系统事件,表明阿里云检测到集群节点的ECS实例的底层宿主机存在潜在的软硬件故障风险,该风险会导致ECS实例重新部署,但请勿直接在ECS控制台单击重新部署,以避免数据丢失。
解决方法:
EMR集群下的ECS实例相关云盘如何默认添加EMR集群ID标签?
若您希望为EMR集群下的ECS实例相关云盘默认添加EMR集群ID标签,您可以在资源管理中启用ECS实例的关联资源标签设置。此时,当云盘与ECS实例绑定时,将自动继承ECS实例的标签,并随ECS实例标签的变更而更新。
操作步骤:
登录标签控制台。
在左侧导航栏,选择。
阅读启用说明,选中创建服务关联角色。
启用关联资源标签设置功能时,系统会自动创建一个名为AliyunServiceRoleForTag的服务关联角色,用于执行关联资源标签相关操作。更多信息,请参见标签服务关联角色。
单击启用并设置规则。
设置关联资源标签规则。
针对支持关联资源标签设置功能的资源,指定需要继承的标签键,可以选择全部标签键或部分标签键。
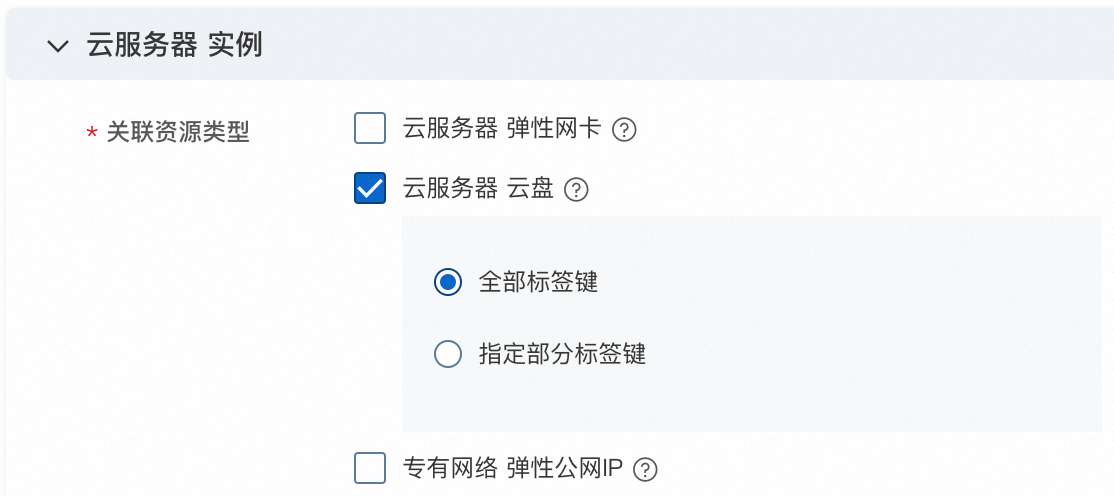
单击确定。
有关标签的更多设置,请参见关联标签继承。
报错:IdempotentParameterMismatch
问题现象:在进行释放集群、升级配置等操作时,您可能会遇到以下错误信息。
问题原因:该错误信息表明多次请求使用了相同的client token。
The request uses the same client token as a previous, but non-identical request. Do not reuse a client token with different requests, unless the requests are identical.解决方法:请确认您的操作是否已经在进行中。如果是,则无需重复提交。否则,您可以尝试刷新控制台页面,EMR控制台界面会自动生成新的 client token。
报错:QuotaExceeded.PrivateIpAddress
问题现象:在创建集群或者执行扩容操作时,您可能遇到以下错误信息。
[QuotaExceeded.PrivateIpAddress] The specified VSwitch "vsw-xxxx" does not have enough IP addresses.问题原因:该错误表明所选的交换机(VSwitch)可用的IP地址数量不足,无法满足集群创建或扩容需求。
解决方法:通过创建新的节点组并选择具备足够IP地址的交换机,您可以顺利完成集群创建或扩容操作。
报错:LostProxy
问题现象:在创建集群、扩容或服务配置更新时,出现错误提示:“taihao-proxy disconnect”。
问题原因:该错误信息表示集群节点上的EMR管控代理(Proxy)已失去连接。
解决方法:
检查集群状态并修复节点问题。
如果批量节点失联:检查CPU和内存指标。
如果CPU或内存使用率较高,说明集群负载过大。可以通过升配或扩容来缓解压力。
如果CPU或内存使用率较低,检查网络安全组配置,确保网络通信正常。
如果只有个别节点失联:请检查该节点的负载情况,确认是否CPU或内存使用率达到100%。若负载过高,排查是否存在异常进程占用资源。如果发现异常进程,终止相关进程并观察节点状态是否恢复。如果无异常进程,考虑以下解决方案:
Master节点:排查消耗CPU高的进程,可以通过升配来提升Master节点的规格,或者通过增加MASTER-EXTEND节点来分担压力。
非Master节点:如果单个ECS实例负载过高或处于无响应状态,可以下线问题节点或者扩容新节点。
通过登录该节点执行以下命令重启服务。
service taihao-proxy restart
完成以上检查和操作后,重新进行创建集群、扩容或服务配置更新。
创建、扩容、升配集群时报错“账户余额不足”,该如何处理?
问题现象:在创建集群、扩容集群或升配时,遇到以下错误信息。
nvalidAccountStatus.NotEnoughBalance Message: Your account does not have enough balance to order postpaid product.问题原因:您的账号当前余额不足。
解决方法:检查账户余额,保证账号余额大于所需资源的费用。如需进行充值操作,请参见充值操作指引。在确保余额充足后,再次进行相关操作。
扩容集群、扩容磁盘时报错:QuotaExceed.DiskCapacity
问题现象:在进行扩容集群、扩容磁盘时,您可能遇到以下错误信息。
[QuotaExceed.DiskCapacity] The used capacity of disk type has exceeded the quota in the zone, quota check fail.问题原因:该错误表明实例磁盘配额已达上限。
解决方法:由于指定磁盘类型的已用容量超出可用区配额限制,您可以前往配额中心查询并申请提升磁盘容量配额。
创建集群、扩容时报错:QuotaExceed.DiskCapacity
问题现象:在进行创建集群、扩容时,您可能遇到以下错误信息。
QuotaExceed.ElasticQuota Message: The number of the specified ECS instances has exceeded the quota of the specified instance type.问题原因:ECS实例配额已达上限。
解决方法:您可以选择其他实例规格或减少实例数量后重新购买,也可以前往ECS管理控制台或配额中心申请提高限额。
引导脚本执行失败,该如何处理?
通过操作历史详情查看执行出错的引导脚本的执行日志:
如果日志中有明确报错信息,请根据报错内容修改引导脚本,并重新执行操作。
如果日志中包含关键词
exitCode但无明确报错,请在引导脚本中添加更多的执行日志,以便更好地调试,然后重新执行操作。如果显示任务超时或日志中没有任何输出,请排查以下内容:
确保用户具有引导脚本所在OSS Bucket的读权限。
检查ECS的网络配置,确保能够访问OSS内网域名,然后重新执行操作。
EMR Gateway提交Spark作业报错:Error initializing SparkContext
问题描述
使用EMR-CLI自定义部署Gateway环境,在Gateway节点Client模式下向集群提交任务时出现错误:ERROR [main] SparkContext: Error initializing SparkContext。
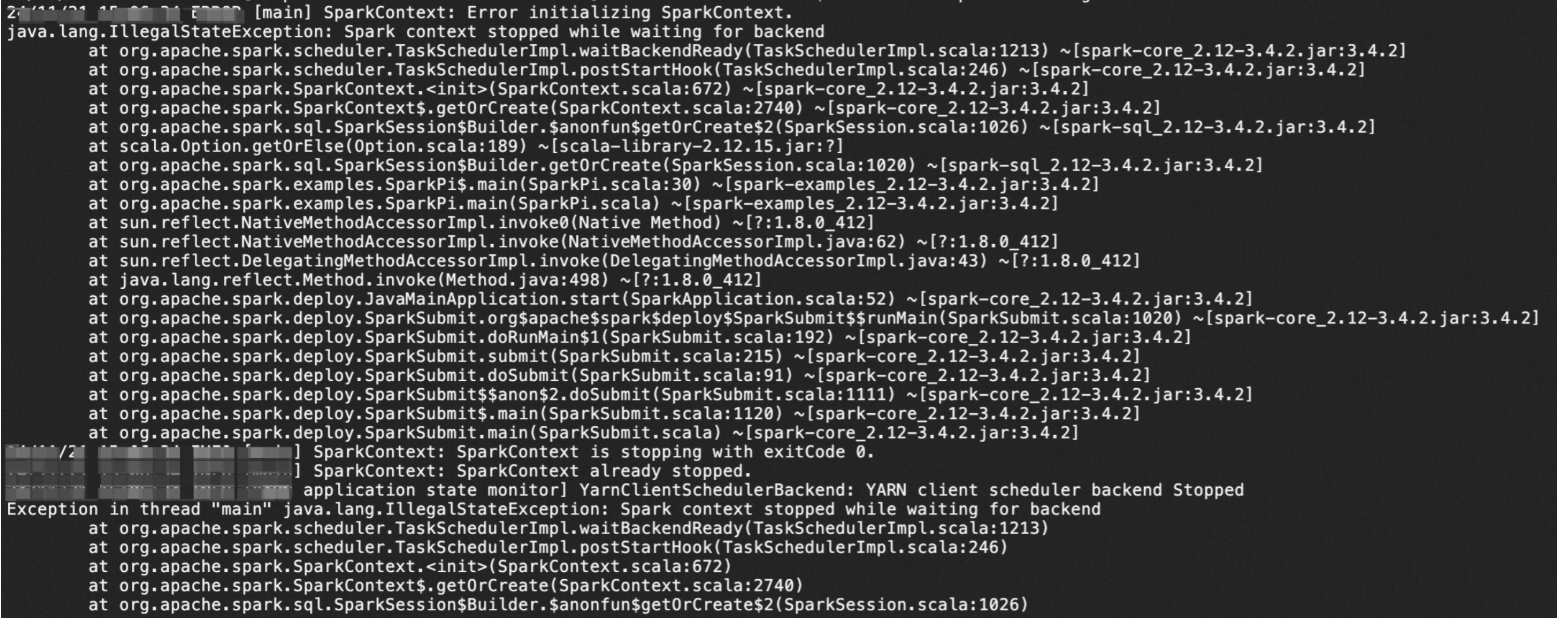
问题原因
在Spark Client模式下,Driver运行于提交作业的客户端(例如Gateway机器),而EMR集群内部则通过Hostname进行通信。由于Gateway的Hostname未在集群的DNS或Hosts中注册,Executor无法解析其地址,这导致Driver与集群之间的通信中断,从而触发SparkContext初始化失败。
解决方案
方案一:使用Cluster模式(推荐)
提交任务时指定
--deploy-mode cluster。在Spark Cluster模式下,Driver运行于YARN管理的ApplicationMaster进程中(位于集群内部),与客户端完全解耦。任务提交后,客户端可立即断开,由YARN全程托管任务资源调度及执行状态监控,避免因客户端网络或Hostname问题导致任务中断,更适合生产环境的高可靠需求。方案二:修改Hosts文件
在Client模式下,需要在EMR集群所有NodeManager节点的/etc/hosts文件中添加Gateway机器的IP映射。

为什么创建的包年包月集群一直处于启动中?
问题现象:在创建包年包月类型的集群后,集群状态长时间显示为启动中,且提示订单未支付。
问题原因:该问题通常是由于订单未完成支付导致的。创建包年包月集群时,系统会生成一个待支付的订单,如果订单未支付或支付流程未完成,集群将无法继续初始化,因此状态会一直停留在启动中。
解决方法:在EMR on ECS页面,单击付费类型列中的待支付,然后单击前往支付以进行支付,或选择取消订单以终止当前操作。
如何解决自定义集群脚本阻塞集群服务启动?
问题现象:在创建集群时,如果通过引导操作配置了自定义脚本,可能会因为脚本执行失败或阻塞,导致进度卡住或任务失败。
The cluster has been terminated with errors: [{"errorCode":"BootstrapScriptFailed","errorMessage":"ScriptFailed: RUN_BOOTSTRAP_CLUSTER_SCRIPT_as_cs-29b7c428b6f344bc849ff7****"}].问题原因:脚本逻辑错误或语法问题。
解决方法:
在集群的操作历史中,定位到脚本执行的相关部分,分析报错信息。
根据报错内容修改脚本逻辑,基于新的引导操作脚本创建集群。
如何解决创建集群时部分机型在所选可用区不支持的报错?
问题现象:创建集群时失败,您可能遇到以下错误信息。
The cluster has been terminated with errors: [{"errorCode":"COMMODITY.INVALID_COMPONENT","errosMessage":"????"}]问题原因:集群配置了在所选可用区EMR不支持的机型,该机型可能未发布或已下架。
解决方法:若出现类似错误,请更换机型进行尝试,或提交工单以便后端进行进一步的判断与处理。