本文中含有需要您注意的重要提示信息,忽略该信息可能对您的业务造成影响,请务必仔细阅读。
大数据计算服务(MaxCompute,原名ODPS)是一种快速、完全托管的EB级数据仓库解决方案。通过数据传输服务DTS(Data Transmission Service),您可以将RDS MySQL或RDS MySQL Serverless的数据同步至MaxCompute,帮助您快速搭建数据实时分析系统。
前提条件
您已完成以下操作:
注意事项
DTS在执行全量数据初始化时将占用源库和目标库一定的读写资源,可能会导致数据库的负载上升,在数据库性能较差、规格较低或业务量较大的情况下(例如源库有大量慢SQL、存在无主键表或目标库存在死锁等),可能会加重数据库压力,甚至导致数据库服务不可用。因此您需要在执行数据同步前评估源库和目标库的性能,同时建议您在业务低峰期执行数据同步(例如源库和目标库的CPU负载在30%以下)。
仅支持表级别的数据同步。
数据同步期间,请勿对源库的同步对象使用gh-ost或pt-online-schema-change等类似工具执行在线DDL变更,否则会导致同步失败。
由于MaxCompute不支持主键约束,当DTS在同步数据时因网络等原因触发重传,可能会导致MaxCompute中出现重复记录。
费用说明
| 同步类型 | 链路配置费用 |
| 库表结构同步和全量数据同步 | 不收费。 |
| 增量数据同步 | 收费,详情请参见计费概述。 |
源库支持的实例类型
执行数据同步操作的MySQL数据库支持以下实例类型:
ECS上的自建数据库
通过专线、VPN网关或智能网关接入的自建数据库
通过数据库网关接入的自建数据库
同一或不同阿里云账号下的RDS MySQL实例
本文以RDS实例为例介绍配置流程,当源库为其他实例类型时,配置流程与该案例类似。
如果源库为自建MySQL数据库,您还需要执行相应的准备工作,详情请参见准备工作概览。
支持同步的SQL操作
DDL操作:ALTER TABLE ADD COLUMN
DML操作:INSERT、UPDATE、DELETE
同步过程介绍
结构初始化。
DTS将源库中待同步表的结构定义信息同步至MaxCompute中,初始化时DTS会为表名增加_base后缀。例如源表为customer,那么MaxCompute中的表即为customer_base。
全量数据初始化。
DTS将源库中待同步表的存量数据,全部同步至MaxCompute中的目标表名_base表中(例如从源库的customer表同步至MaxCompute的customer_base表),作为后续增量同步数据的基线数据。
说明该表也被称为全量基线表。
增量数据同步。
DTS在MaxCompute中创建一个增量日志表,表名为同步的目标表名_log,例如customer_log,然后将源库产生的增量数据实时同步到该表中。
说明关于增量日志表结构的详细信息,请参见增量日志表结构定义说明。
操作步骤
为保障DTS同步账号能够授权成功,请使用主账号完成下述操作步骤。
购买数据同步作业,详情请参见购买流程。
说明购买时,选择源实例为MySQL,目标实例为MaxCompute,并选择同步拓扑为单向同步。
登录数据传输控制台。
说明若数据传输控制台自动跳转至数据管理DMS控制台,您可以在右下角的
 中单击
中单击 ,返回至旧版数据传输控制台。
,返回至旧版数据传输控制台。在左侧导航栏,单击数据同步。
在同步作业列表页面顶部,选择同步的目标实例所属地域。
定位至已购买的数据同步实例,单击配置同步链路。
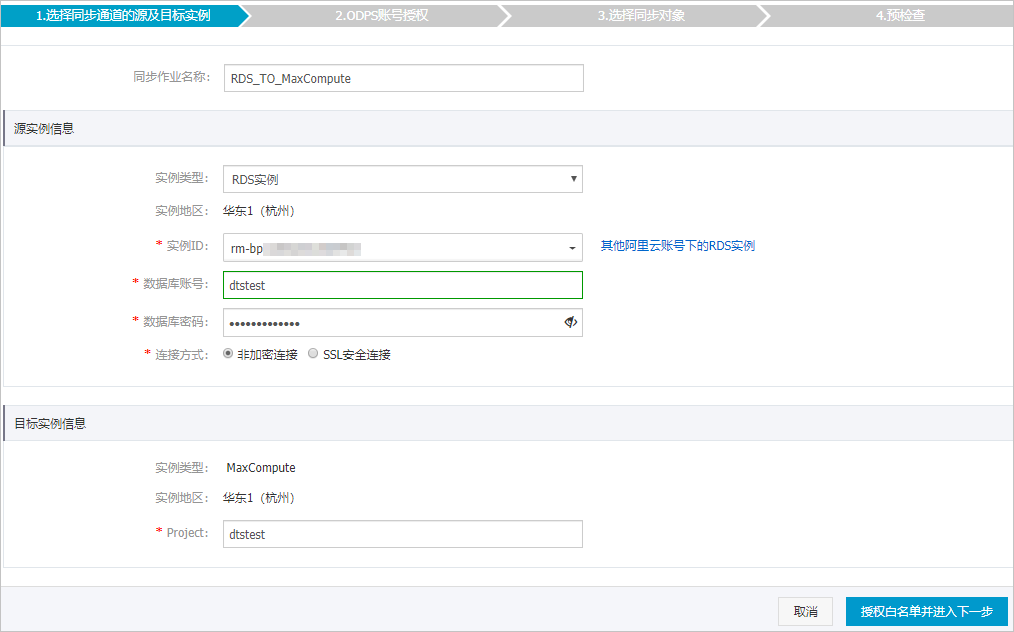
配置同步通道的源实例及目标实例信息。
类别
配置
说明
无
同步作业名称
DTS会自动生成一个同步作业名称,建议配置具有业务意义的名称(无唯一性要求),便于后续识别。
源实例信息
实例类型
选择RDS实例。
实例地区
购买数据同步实例时选择的源实例地域信息,不可变更。
实例ID
选择作为数据同步源的RDS实例ID。
数据库账号
填入源RDS的数据库账号。
说明当源RDS实例的数据库类型为MySQL 5.5或MySQL 5.6时,无需配置数据库账号和数据库密码。
数据库密码
填入数据库账号对应的密码。
连接方式
根据需求选择非加密连接或SSL安全连接。如果设置为SSL安全连接,您需要提前开启RDS实例的SSL加密功能,详情请参见设置SSL加密。
目标实例信息
实例类型
固定为MaxCompute,不可变更。
实例地区
购买数据同步实例时选择的目标实例地域信息,不可变更。
Project
填入MaxCompute实例的Project,您可以在MaxCompute工作空间列表页面中查询。

单击页面右下角的授权白名单并进入下一步。
如果源或目标数据库是阿里云数据库实例(例如RDS MySQL、云数据库MongoDB版等),DTS会自动将对应地区DTS服务的IP地址添加到阿里云数据库实例的白名单中;如果源或目标数据库是ECS上的自建数据库,DTS会自动将对应地区DTS服务的IP地址添到ECS的安全规则中,您还需确保自建数据库没有限制ECS的访问(若数据库是集群部署在多个ECS实例,您需要手动将DTS服务对应地区的IP地址添到其余每个ECS的安全规则中);如果源或目标数据库是IDC自建数据库或其他云数据库,则需要您手动添加对应地区DTS服务的IP地址,以允许来自DTS服务器的访问。DTS服务的IP地址,请参见DTS服务器的IP地址段。
警告DTS自动添加或您手动添加DTS服务的公网IP地址段可能会存在安全风险,一旦使用本产品代表您已理解和确认其中可能存在的安全风险,并且需要您做好基本的安全防护,包括但不限于加强账号密码强度防范、限制各网段开放的端口号、内部各API使用鉴权方式通信、定期检查并限制不需要的网段,或者使用通过内网(专线/VPN网关/智能网关)的方式接入。
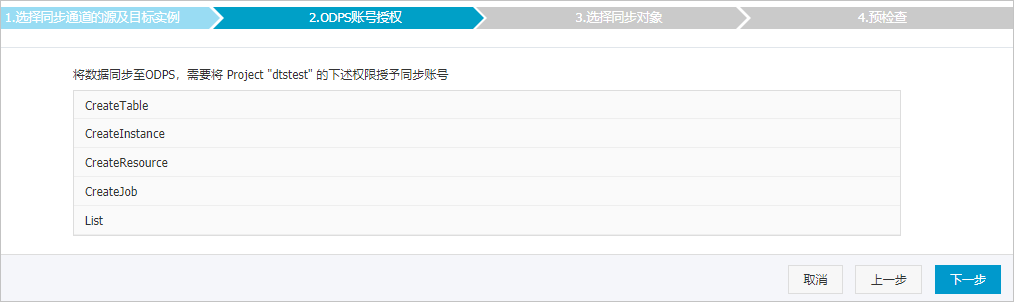
单击页面右下角的下一步,允许将MaxCompute中项目的下述权限授予给DTS同步账号,详情如下图所示。
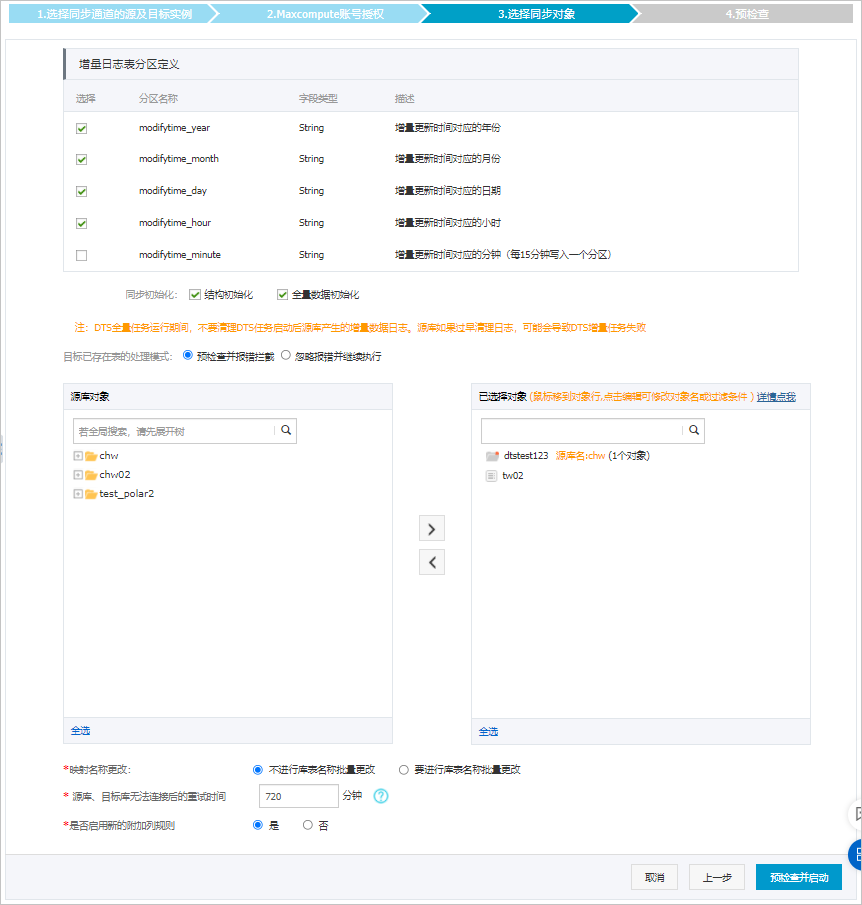
配置同步策略和同步对象。
配置
说明
增量日志表分区定义
根据业务需求,选择分区名称。关于分区的相关介绍请参见分区。
同步初始化
同步初始化类型细分为:结构初始化、全量数据初始化。
此处同时勾选结构初始化和全量数据初始化,DTS会在增量数据同步之前,将源数据库中待同步对象的结构和存量数据同步到目标数据库。
目标已存在表的处理模式
预检查并报错拦截:检查目标数据库中是否有同名的表。如果目标数据库中没有同名的表,则通过该检查项目;如果目标数据库中有同名的表,则在预检查阶段提示错误,数据同步作业不会被启动。
说明如果目标库中同名的表不方便删除或重命名,您可以设置同步对象在目标实例中的名称来避免表名冲突。
忽略报错并继续执行:跳过目标数据库中是否有同名表的检查项。
警告选择为忽略报错并继续执行,可能导致数据不一致,给业务带来风险,例如:
表结构一致的情况下,如果在目标库遇到与源库主键的值相同的记录,在初始化阶段会保留目标库中的该条记录;在增量同步阶段则会覆盖目标库的该条记录。
表结构不一致的情况下,可能会导致无法初始化数据、只能同步部分列的数据或同步失败。
选择同步对象
在源库对象框中单击待同步的表,然后单击
 将其移动至已选择对象框。说明
将其移动至已选择对象框。说明同步对象支持选择的粒度仅为表,您可以从多个库中选择表作为同步对象。
默认情况下,同步对象的名称保持不变。如果您需要在目标实例上名称不同,那么需要使用DTS提供的对象名映射功能,详情请参见设置同步对象在目标实例中的名称。
选择附加列规则
DTS在将数据同步到MaxCompute时,会在同步的目标表中添加一些附加列。如果附加列和目标表中已有的列出现名称冲突将会导致数据同步失败。您需要根据业务需求选择是否启用新的附加列规则为是或否。
警告在选择附加列规则前,您需要评估附加列和目标表中已有的列是否会出现名称冲突,否则可能会导致任务失败或数据丢失。关于附加列的规则和定义说明,请参见附加列名称和定义说明。
映射名称更改
如需更改同步对象在目标实例中的名称,请使用对象名映射功能,详情请参见库表列映射。
源表DMS_ONLINE_DDL过程中是否复制临时表到目标库
如源库使用数据管理DMS(Data Management)执行Online DDL变更,您可以选择是否同步Online DDL变更产生的临时表数据。
是:同步Online DDL变更产生的临时表数据。
说明Online DDL变更产生的临时表数据过大,可能会导致同步任务延迟。
否:不同步Online DDL变更产生的临时表数据,只同步源库的原始DDL数据。
说明该方案会导致目标库锁表。
源、目标库无法连接重试时间
当源、目标库无法连接时,DTS默认重试720分钟(即12小时),您也可以自定义重试时间。如果DTS在设置的时间内重新连接上源、目标库,同步任务将自动恢复。否则,同步任务将失败。
说明由于连接重试期间,DTS将收取任务运行费用,建议您根据业务需要自定义重试时间,或者在源和目标库实例释放后尽快释放DTS实例。
上述配置完成后,单击页面右下角的预检查并启动。
说明在同步作业正式启动之前,会先进行预检查。只有预检查通过后,才能成功启动同步作业。
如果预检查失败,单击具体检查项后的
 ,查看失败详情。
,查看失败详情。您可以根据提示修复后重新进行预检查。
如无需修复告警检测项,您也可以选择确认屏蔽、忽略告警项并重新进行预检查,跳过告警检测项重新进行预检查。
在预检查对话框中显示预检查通过后,关闭预检查对话框,同步作业将正式开始。
等待同步作业的链路初始化完成,直至处于同步中状态。
您可以在数据同步页面,查看数据同步作业的状态。

增量日志表结构定义说明
你需要在MaxCompute中执行set odps.sql.allow.fullscan=true;,设置项目空间属性,允许进行全表扫描。
DTS在将MySQL产生的增量数据同步至MaxCompute的增量日志表时,除了存储增量数据,还会存储一些元信息,示例如下。

示例中的modifytime_year、modifytime_month、modifytime_day、modifytime_hour、modifytime_minute为分区字段,是在配置同步策略和同步对象步骤中指定的。
结构定义说明
字段 | 说明 |
record_id | 增量日志的记录ID,为该日志唯一标识。 说明
|
operation_flag | 操作类型,取值:
|
utc_timestamp | 操作时间戳,即binlog的时间戳(UTC 时间)。 |
before_flag | 所有列的值是否为更新前的值,取值:Y或N。 |
after_flag | 所有列的值是否为更新后的值,取值:Y或N。 |
关于before_flag和after_flag的补充说明
对于不同的操作类型,增量日志中的before_flag和after_flag定义如下:
INSERT
当操作类型为INSERT时,所有列的值为新插入的记录值,即为更新后的值,所以before_flag取值为N,after_flag取值为Y,示例如下。

UPDATE
当操作类型为UPDATE时,DTS会将UPDATE操作拆为两条增量日志。这两条增量日志的record_id、operation_flag及utc_timestamp对应的值相同。
第一条增量日志记录了更新前的值,所以before_flag取值为Y,after_flag取值为N。第二条增量日志记录了更新后的值,所以before_flag取值为N,after_flag取值为Y,示例如下。

DELETE
当操作类型为DELETE时,增量日志中所有的列值为被删除的值,即列值不变,所以before_flag取值为Y,after_flag取值为N,示例如下。

全量数据合并示例
执行数据同步的操作后,DTS会在MaxCompute中分别创建该表的全量基线表和增量日志表。您可以通过MaxCompute的SQL命令,对这两个表执行合并操作,得到某个时间点的全量数据。
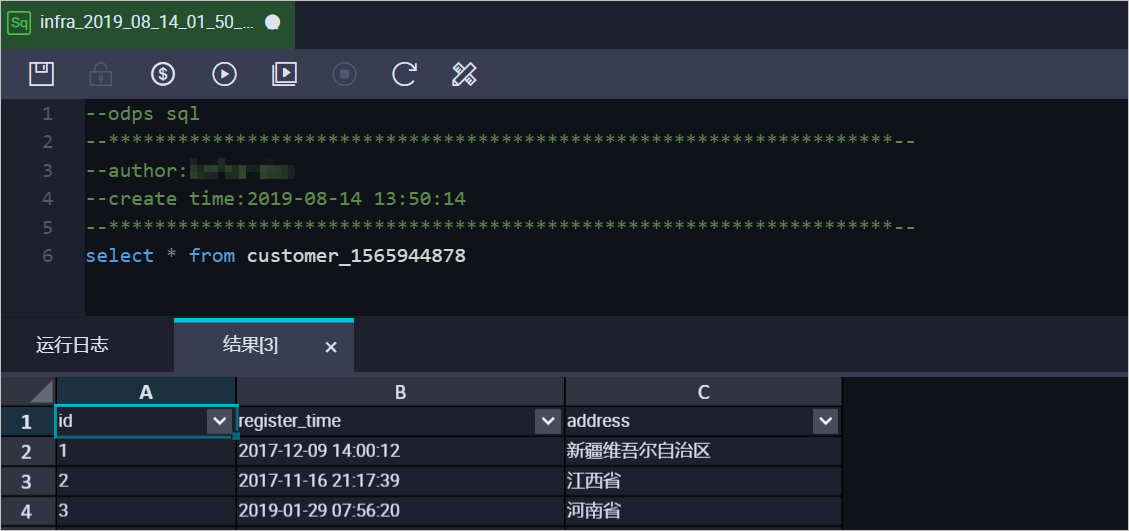
本案例以customer表为例(表结构如下),介绍操作流程。

根据源库中待同步表的结构,在MaxCompute中创建用于存储合并结果的表。
例如,需要获取customer表在
1565944878时间点的全量数据。为方便业务识别,创建如下数据表:CREATE TABLE `customer_1565944878` ( `id` bigint NULL, `register_time` datetime NULL, `address` string);说明您可以在MaxCompute的临时查询中,运行SQL命令。
关于MaxCompute支持的数据类型与相关说明,请参见数据类型。
在MaxCompute中执行如下SQL命令,合并全量基线表和增量日志表,获取该表在某一时间点的全量数据。
set odps.sql.allow.fullscan=true; insert overwrite table <result_storage_table> select <col1>, <col2>, <colN> from( select row_number() over(partition by t.<primary_key_column> order by record_id desc, after_flag desc) as row_number, record_id, operation_flag, after_flag, <col1>, <col2>, <colN> from( select incr.record_id, incr.operation_flag, incr.after_flag, incr.<col1>, incr.<col2>,incr.<colN> from <table_log> incr where utc_timestamp< <timestamp> union all select 0 as record_id, 'I' as operation_flag, 'Y' as after_flag, base.<col1>, base.<col2>,base.<colN> from <table_base> base) t) gt where row_number=1 and after_flag='Y'说明<result_storage_table>:存储全量merge结果集的表名。
<col1>/<col2>/<colN>:同步表中的列名。
<primary_key_column>:同步表中的主键列名。
<table_log>:增量日志表名。
<table_base>:全量基线表名。
<timestamp>:需要获取全量数据的时间点。
合并数据表,获取customer表在
1565944878时间点的全量数据,示例如下:set odps.sql.allow.fullscan=true; insert overwrite table customer_1565944878 select id, register_time, address from( select row_number() over(partition by t.id order by record_id desc, after_flag desc) as row_number, record_id, operation_flag, after_flag, id, register_time, address from( select incr.record_id, incr.operation_flag, incr.after_flag, incr.id, incr.register_time, incr.address from customer_log incr where utc_timestamp< 1565944878 union all select 0 as record_id, 'I' as operation_flag, 'Y' as after_flag, base.id, base.register_time, base.address from customer_base base) t) gt where gt.row_number= 1 and gt.after_flag= 'Y';上述命令执行完成后,可在customer_1565944878表中查询合并后的数据。