用户在查询SQL Server表中的生僻字时,查询结果出现乱码。本文分析该问题出现的原因以及解决该问题的方法。
问题复现示例
执行如下代码,查询SQL Server表中的生僻字“䅇”(su)。
USE tempdb;
GO
IF OBJECT_ID('temp', 'U') IS NOT NULL
DROP TABLE temp;
GO
CREATE TABLE temp (
firstName VARCHAR(10)
);
INSERT INTO temp
SELECT '䅇'
UNION ALL
SELECT '库';
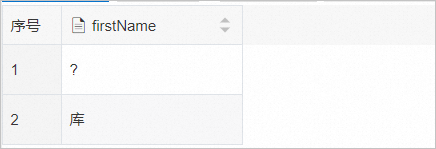
SELECT * FROM temp;显示结果如下,“䅇”(su)字并未正确显示,而是出现了问号“?”。
分析原因
SQL Server采用Unicode编码格式的数据类型(例如NCHAR、NVARCHAR)来支持包含亚洲语言(包括中文)的数据。因此,在查询代码时,必须使用Unicode编码的数据类型。本文问题复现示例中使用的VARCHAR是非Unicode编码数据类型,所以导致查询结果出现乱码。
解决方法
为了解决在SQL Server表中查询生僻字出现乱码的问题,您需要使用Unicode编码格式的数据类型,例如NVARCHAR,并在向该数据类型插入数据时,使用前置词N。N代表国家语言,必须大写。如果没有使用前置词N,则SQL Server会将字符串转换成当前数据库的非Unicode字符编码页,可能会导致乱码问题。
正确示例
将上述示例中的数据类型VARCHAR改为NVARCHAR,执行如下代码,查询SQL Server表中的生僻字“䅇”(su)。
-- 使用tempdb数据库
USE tempdb;
GO
-- 如果已经存在名为temp的表,则删除该表
IF OBJECT_ID('temp', 'U') IS NOT NULL
DROP TABLE temp;
GO
-- 创建名为temp的表,其中包含一个名为firstName的列,数据类型为NVARCHAR,长度为10
CREATE TABLE temp (
firstName NVARCHAR(10)
);
-- 向temp表中插入两条记录,分别包含“䅇”和“库”两个生僻字,需要使用前置词N避免乱码问题
INSERT INTO temp
SELECT N'䅇'
UNION ALL
SELECT N'库';
-- 查询temp表中的所有记录
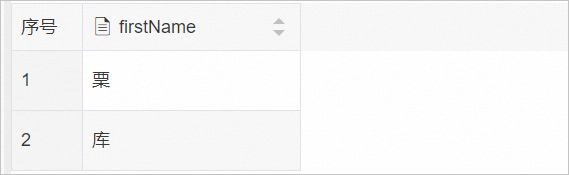
SELECT * FROM temp;显示结果如下,“䅇”(su)字被正确查询出。
该文章对您有帮助吗?