兼容特征及功能函数项
兼有功能及特征函数的功能,可以同时在filter、sort及formula表达式中使用。
其中函数参数出现的文档字段需根据对应函数文档提示,创建为索引或属性.
tag_match : 用于对查询语句和文档做标签匹配,使用匹配结果对文档进行算分加权
1.场景概述:
涉及query和文档匹配的很多需求都可以使用或者转化为tag_match来满足,对实现搜索个性化需求尤其有用。例如优先出现用户点赞过的店铺,优先展现用户喜欢的体育和娱乐类新闻等。tag_match最基本的功能是在文档的某个ARRAY字段中存储一系列的key-value信息。然后在查询query中通过kvpairs子句传递对应的key-value信息,tag_match就会去文档中寻找查询query中的key, 然后为每个匹配的key计算得到一个分数,再合并所有匹配的key的分数得到一个最终分。这个结果就可以用来做算分加权或者过滤。
计算过程如下: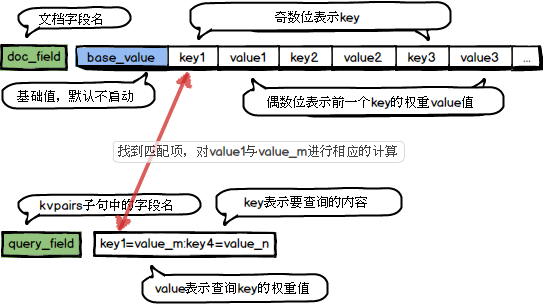
2.详细用法:
常见用法:
tag_match(query_key, doc_field, kv_op, merge_op)
高级用法:
tag_match(query_key, doc_field, kv_op, merge_op, has_default, doc_kv, max_kv_count)
3.参数:
query_key:指定查询语句中用于匹配的字段key-value值,该字段需要通过kvpairs子句传递,key与value通过英文等号‘=’分隔,多个key-value通过英文冒号‘:’分隔,如: kvpairs=query_tags:10=0.67:960=0.85:1=48//表示参数query_tags中包含3个元素:10、960、1,其对应的value分别是:0.67、0.85、48。其中query也可以只为key的列表,如:kvpairs=cats:10:960:1。
doc_field:指定文档中存储key-value的字段名,该字段只支持整型【int_array】或者浮点型【float_array,double_array】数组字段类型(如果是浮点型数组字段类型,则key的值匹配的时强转当int64来处理)。数组的奇数位置是key,下一个相邻的偶数位置为key的value。即 [key0 value0 key1 value1 …]
kv_op:当query_key中的值与doc_field中的key匹配时对二者的value所采取的操作,目前支持的操作符如下:max(最大值)、min(最小值)、sum(求和)、avg(平均数)、mul(乘积)、query_value(query_key中该key对应的value值)、doc_value(文档中该key对应的value值)、number(常数)。
merge_op:多个key匹配后会产生多个结果,merge_op指定了将这些结果进行如何操作,目前支持的操作类型如下:max(最大值)、min(最小值)、sum(求和)、avg(平均值)、first_match(取第一个kv_op的计算结果,忽略其他结果)。
has_default:默认是false,表示不启动初始分值;为true时说明doc_field的第一个值为默认值,[init_score k0 v0 k1 v1…]。(类似base分值的概念)
doc_kv:默认是true。表明doc_field字段中的值是以key-value对的形式存在;为false则表示doc_field中只包含key信息。
max_kv_count:因为查询中的key-value结构需要通过query传递,所有tag_match对query中能传递多少key-value有限制。默认为50,可以通过这个参数将这个限制调大,但是最大不能超过5120。
4.返回值:
double,返回具体的分值,如果has_default为false并且没有配额的内容则为0.如果需要返回int64的结果,需要使用int_tag_match,该函数功能与参数与int_tag_match完全一致,但int_tag_match不能在排序表达式中使用。
5.适用场景
场景1:一个大型的综合性论坛,帖子可以被打上各种各样的标签(搞笑,体育,新闻,音乐,科普..)。我们在推送给OpenSearch的文档中,可以为每个标签赋予一个标签id(例如搞笑-1, 体育-5, 新闻-3, 音乐-6..), 然后通过一个tag字段存储这些标签。 如果我们对帖子做过预处理,甚至能得到每个帖子每个标签的权重,例如一个搞笑体育新闻的帖子可以得到搞笑的权重为0.5,体育的权重为0.5,新闻权重为0.1,则这个帖子的tag字段的值为[1 0.5 5 0.5 3 0.1]对会员用户,通过长时间的积累,我们能获知每个用户的兴趣标签。
例如用户nba_fans对体育和搞笑很感兴趣,他对应的体育和搞笑标签的权重分别为0.6和0.3。那么这个用户查询时,我们就可以通过kv_pairs子句把这个信息加到query里面。假如这个kv_pairs子句名字为user_tag, 那么nba_fans的user_tag的值5=0.6:1=0.3。这样,我们只要在精排表达式中配置了tag_match(user_tag, tag, mul, sum), 我们就能够实现对用户感兴趣的帖子加权,把用户更感兴趣的帖子排到前面。
例如nba_fans搜索到上面那个帖子时,搞笑和体育这两个标签能够匹配到。通过指定kv_op参数为mul,我们会把query和doc中的值相乘,他们各自的计算分数分别为(体育:0.5 * 0.6 = 0.3, 搞笑:0.5 * 0.3 = 0.15)。通过指定merge_op参数为sum,我们会把体育和搞笑的分数加和(0.3+0.15 = 0.45),这个加和的分数会加到最终的排序分数上。这样,我们就能够实现了对这个用户感兴趣帖子的排序加权。
场景2:
商品可以具有多个属性标签,如1表示年轻人(年龄)、2表示中年人(年龄)、3表示小清新(风格)、4表示时尚(风格)、5表示女性(性别)、6表示男性(性别)等。
假设我们只想表示商品有没有某个标签,不想区分哪个标签更重要。这个标签通过options字段来保存。那么年轻时尚女性的衣服的options字段可以表示为[1 4 5], 注意这里只有标签key,没有value。用户也都有自己的属性标签,和商品标签对应。例如年轻女性用户,历史成交中多购买小清新风格衣服。这该用户的查询可以写为user_options=1:3:5。注意这里kv_pair中也是只有标签key,没有value的。
要实现对符合用户标签喜好的商品加权,我们可以在formula中使用tag_match(user_options, options, 10, sum, false, false)。这里我们通过user_options和options指定了query和doc的标签信息。kv_op设为常数10,表示只要有标签匹配到,那么匹配的计算结果就是10。has_default为false,表示我们不需要初始值。doc_kv为false,表示我们doc中只存储了key信息,没有value。
这样,上面的年轻女用户查询到上面的衣服时,女性和年轻两个标签能够匹配上,这两个标签的计算结果都是10。通过sum这个merge_op,能够得到这件商品的最终加权分数为20。通过这种方式,即使我们没有标签的权重信息,也能够实现对匹配到的文档做排序加权。
注意事项
函数参数依赖字段需创建为属性
如果是用在filter或者sort子句中,则query_key、kv_op、merge_op、has_default、doc_kv必须使用双引号括起来,如:sort=-tag_match(“user_options”, options, “mul”, “sum”, “false”, “true”, 100)。
tag_match的key匹配都是通过整数比较来完成的。因此query和doc中的key都应该转换为整数形式,如果是浮点类型,tag_match在比较时,会强制转换为整数类型。
案例演示
假设文档内容共有如下10类型的标签:
1-财经
2-科技
3-体育
4-娱乐
5-时尚
6-教育
7-旅游
8-游戏
9-科普
10-医疗案例1:关键词相同,但是标签不同的title:
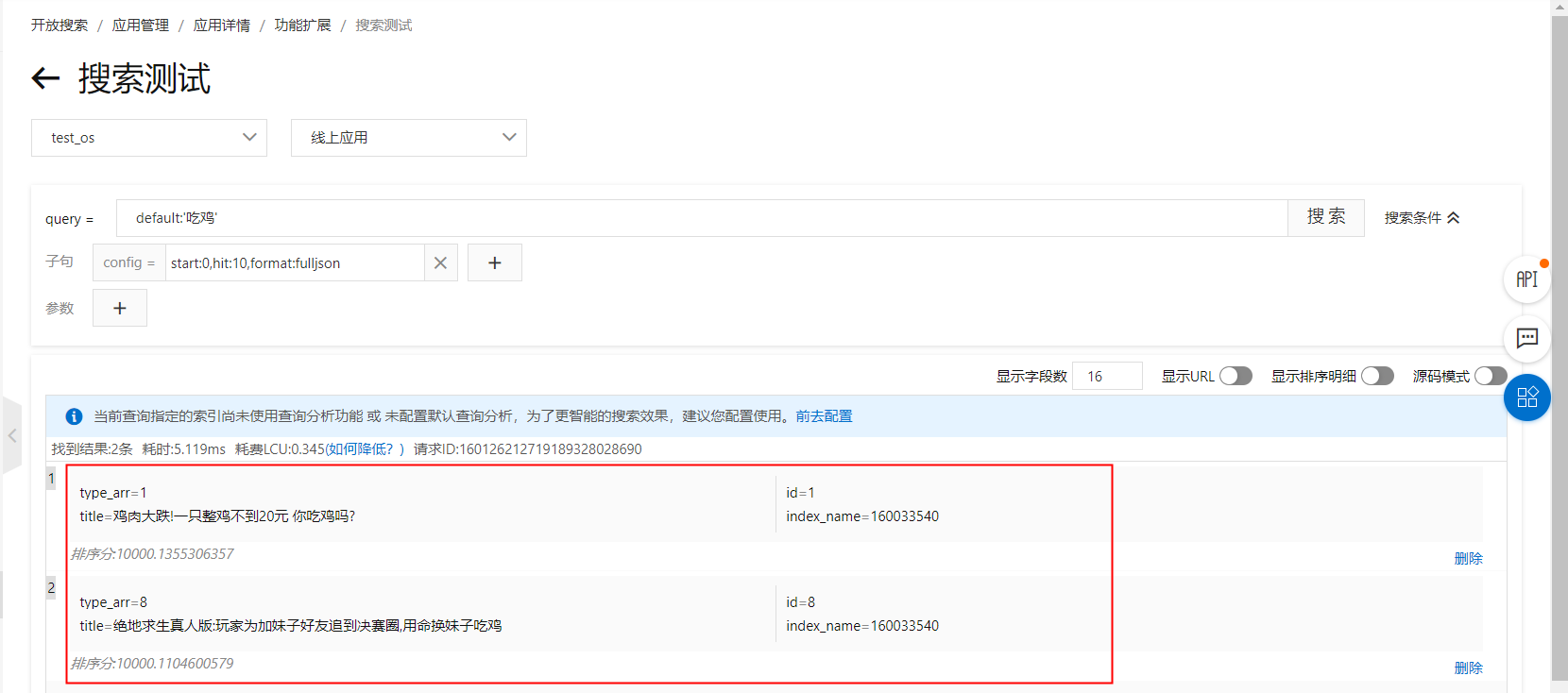 如上图所示,搜索“吃鸡”出现两篇doc,但是二者的类型不同,分别是1-财经、8-游戏,如果想将“游戏”标签的文档在前面展示,可设置tag_match函数,以下分别演示配置在排序表达式和sort子句中的方法:
如上图所示,搜索“吃鸡”出现两篇doc,但是二者的类型不同,分别是1-财经、8-游戏,如果想将“游戏”标签的文档在前面展示,可设置tag_match函数,以下分别演示配置在排序表达式和sort子句中的方法:
kvpairs:type:8
排序表达式:tag_match(type, type_arr, 10, max,false,false)
sort子句:tag_match("type", type_arr, 10, "max","false","false")排序表达式展示的结果: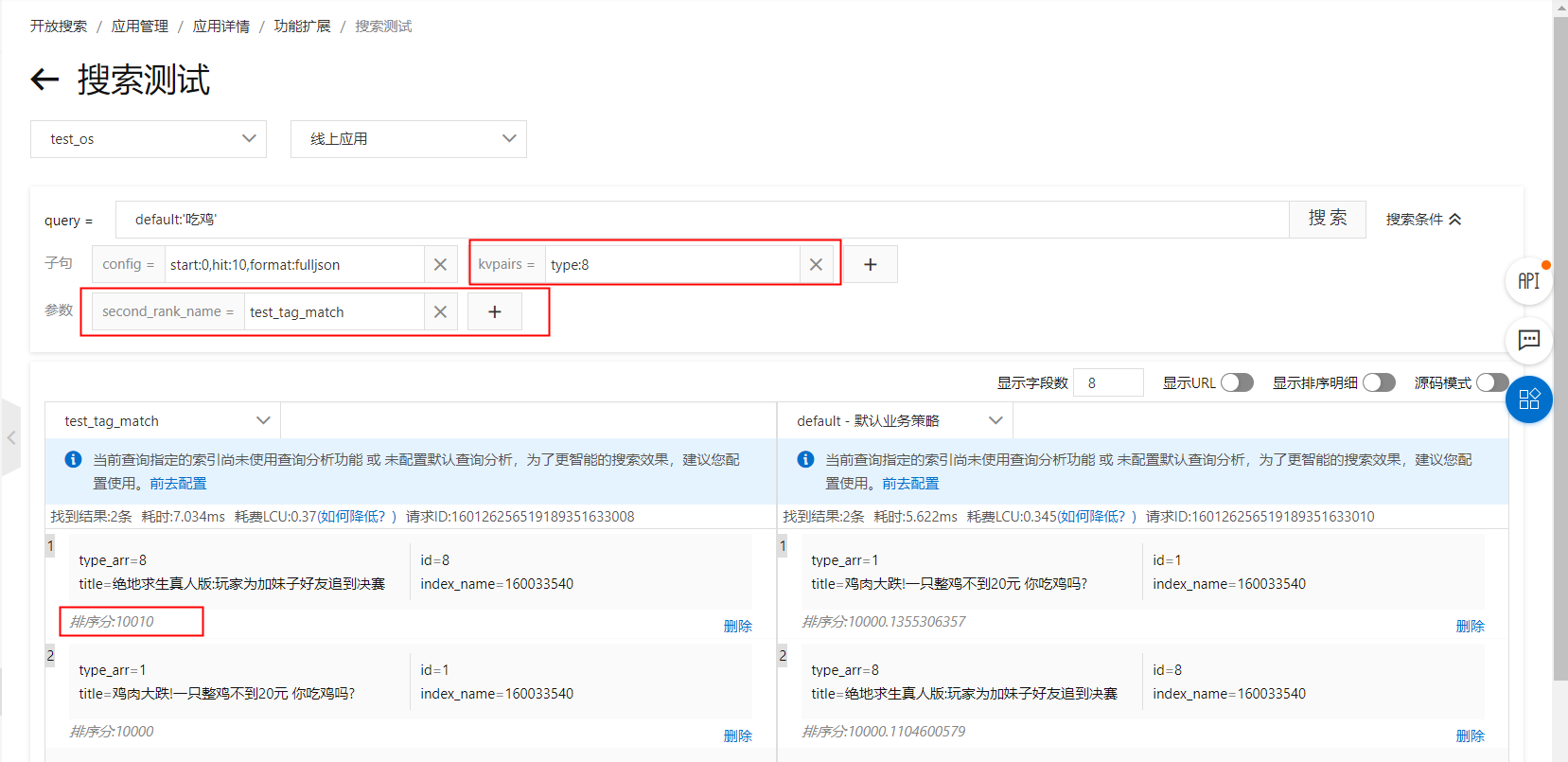 sort子句展示的结果:
sort子句展示的结果: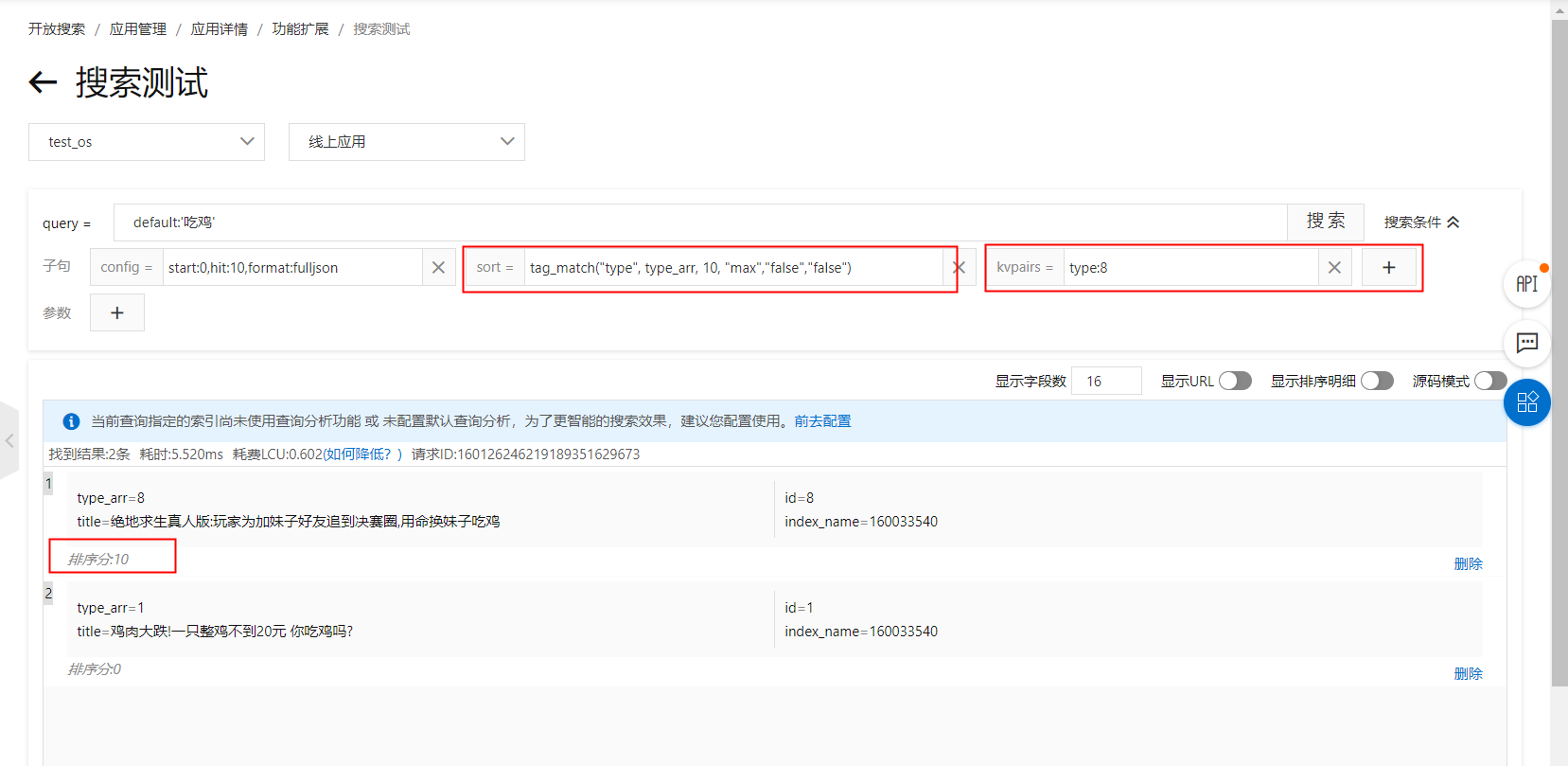
案例2:多标签综合得分展示(可针对用户的个性化推荐)
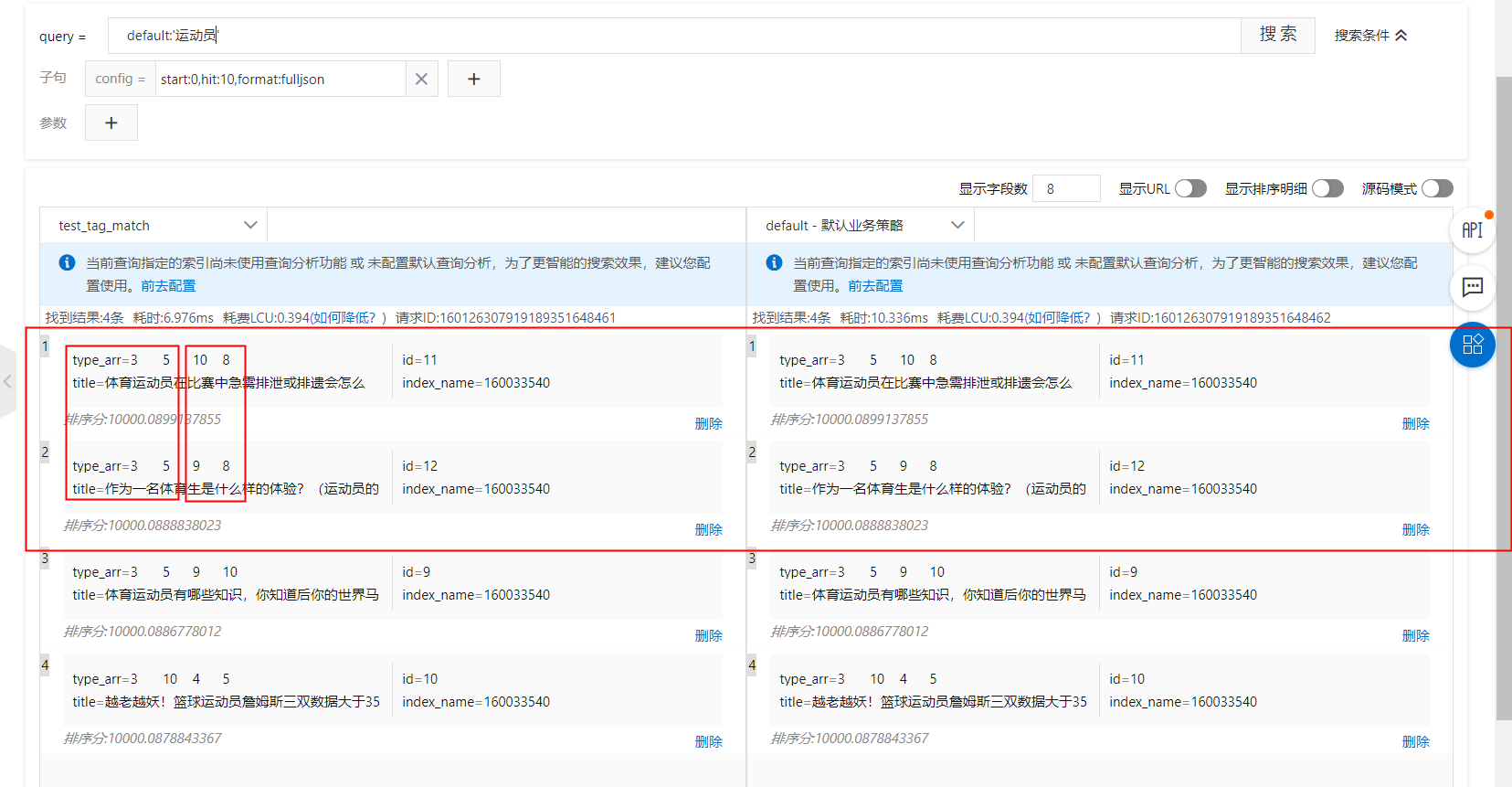 如图,在一级标签相同的情况下,需要匹配二级标签的得分,以下分别演示配置在排序表达式和sort子句中的方法:
如图,在一级标签相同的情况下,需要匹配二级标签的得分,以下分别演示配置在排序表达式和sort子句中的方法:
kvpairs:type:3=2:10=1
排序表达式:tag_match(type, type_arr, 10, sum,false,true)
sort子句:tag_match("type", type_arr, 10, "sum","false","true")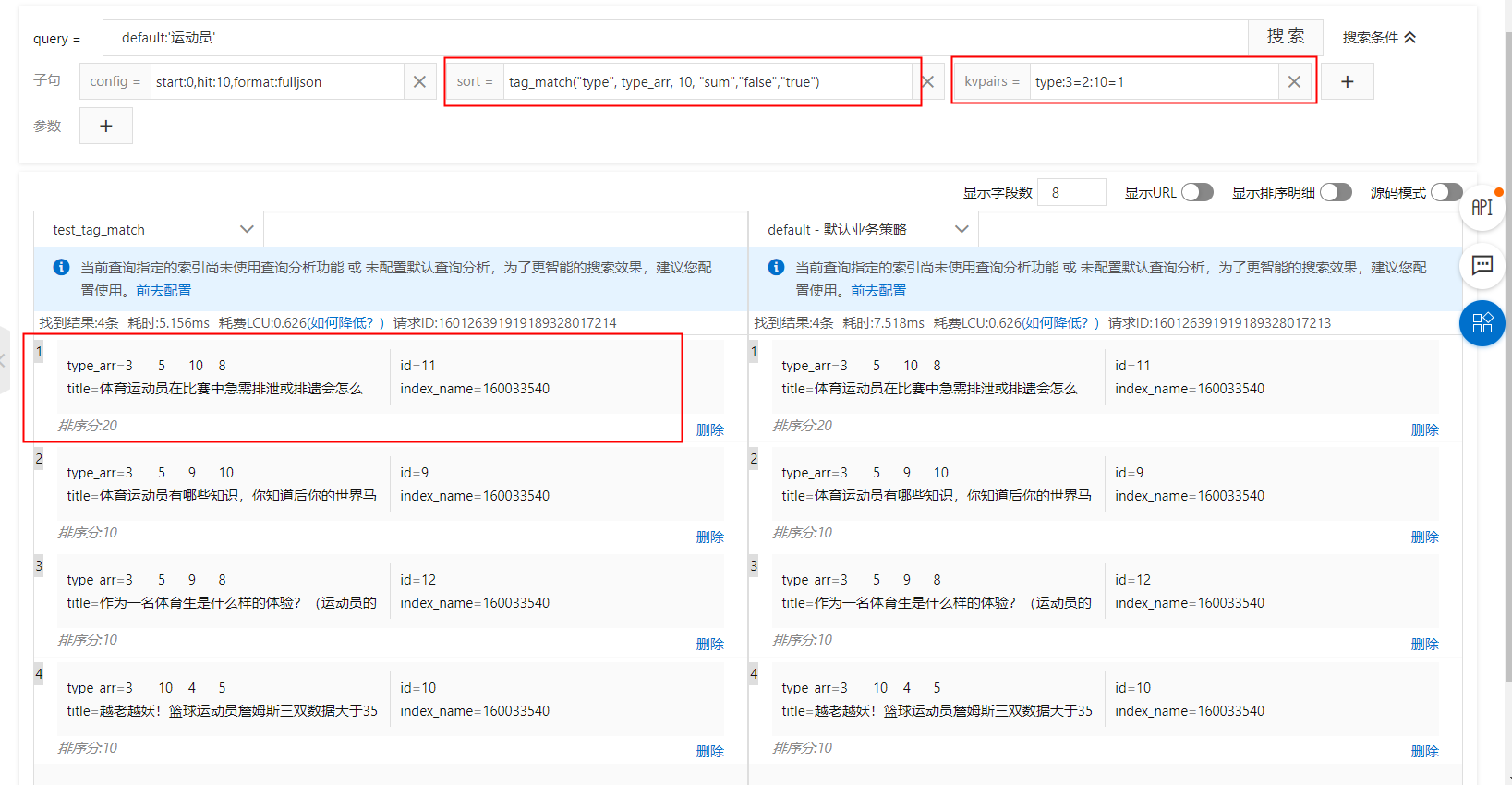
案例3:多标签同类型,不同得分
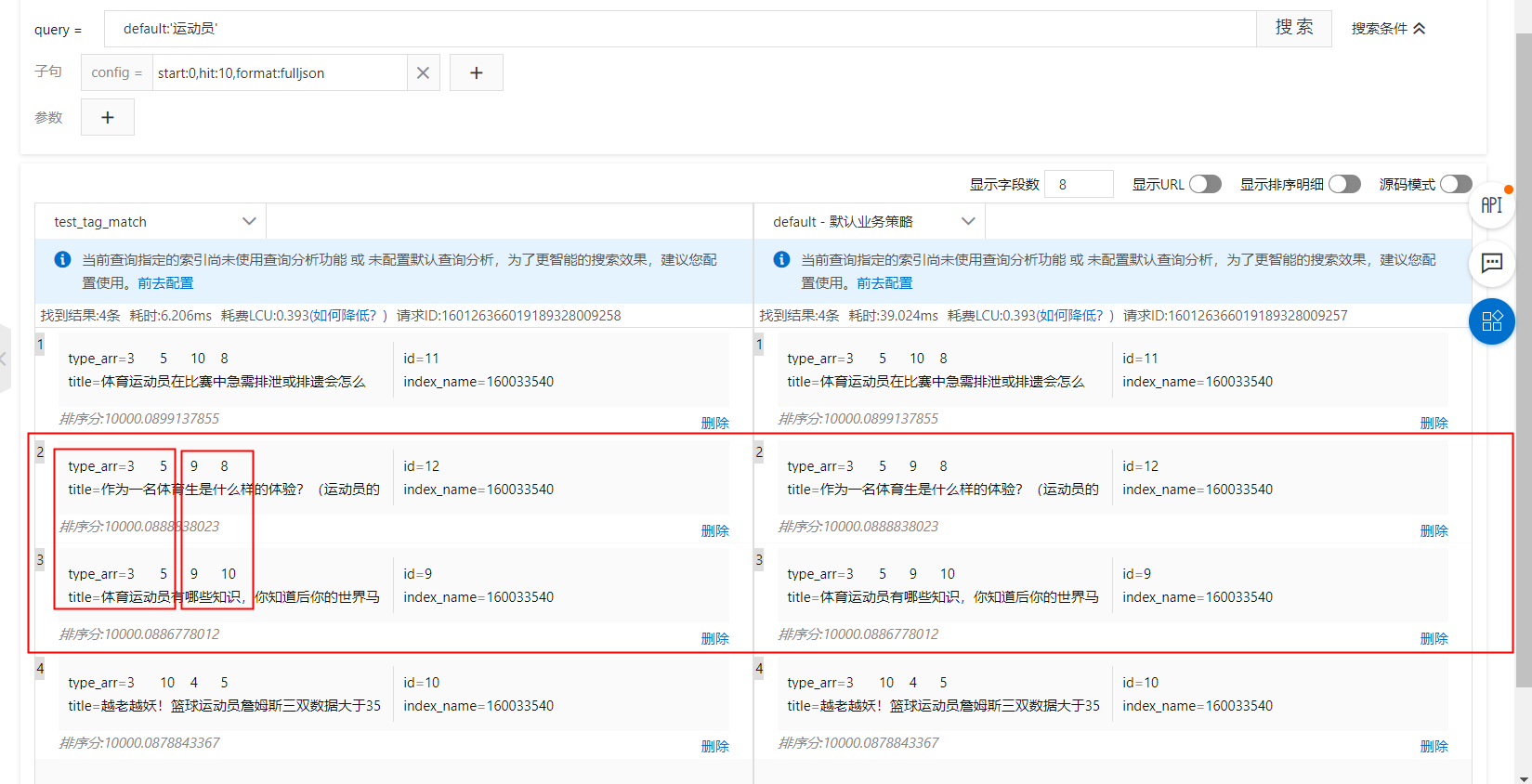 如图,红框展示的内容,都同属于同样的标签,但是每个标签的打分不同,以下分别演示配置在排序表达式和sort子句中的方法:
如图,红框展示的内容,都同属于同样的标签,但是每个标签的打分不同,以下分别演示配置在排序表达式和sort子句中的方法:
kvpairs:type:3=2:9=2
排序表达式:tag_match(type, type_arr, sum, sum,false,true)
sort子句:tag_match("type", type_arr, "sum", "sum","false","true")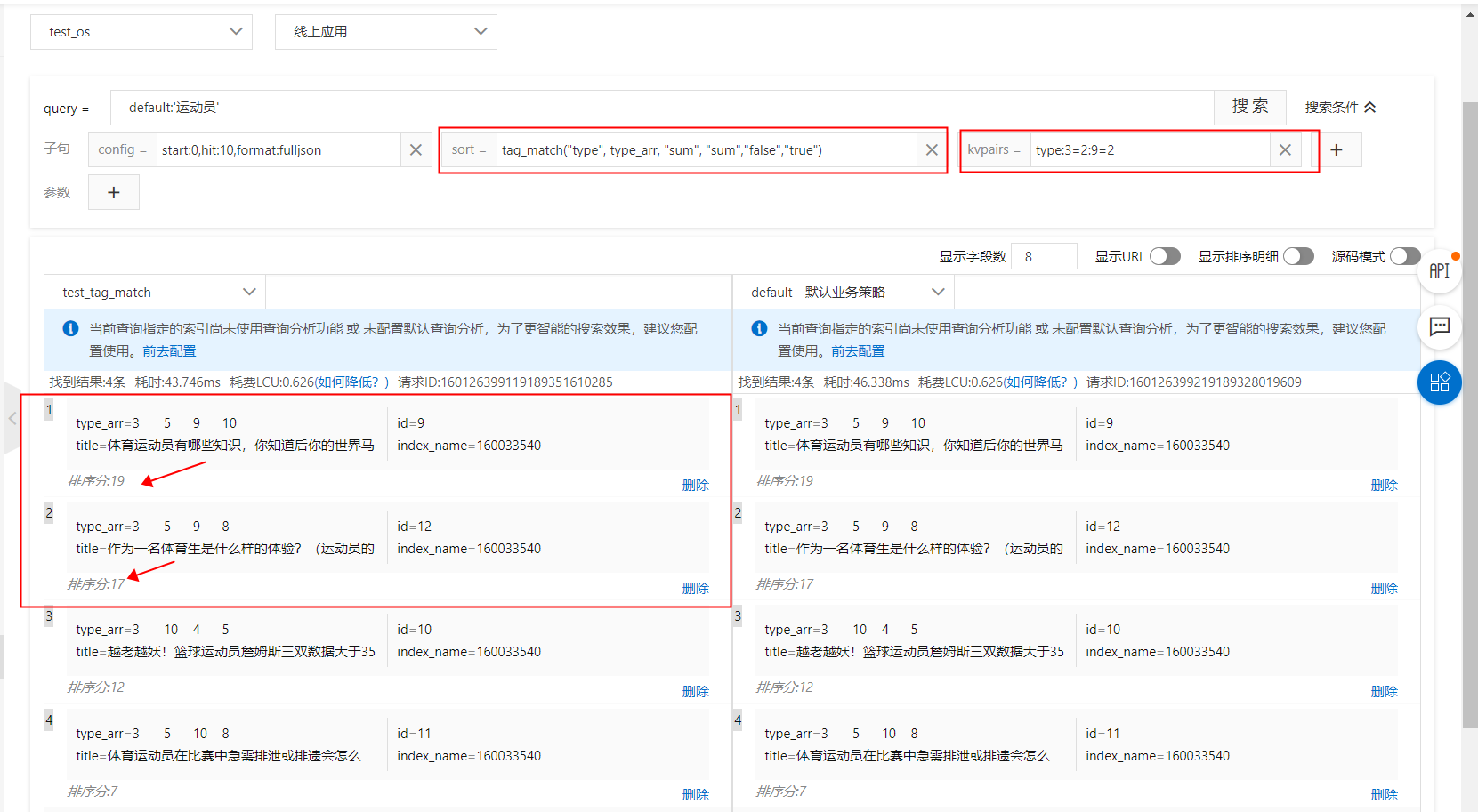
Java sdk 示例参考:Java sdk 搜索Demo