分析函数CUME_DIST
函数定义
CUME_DIST函数在SQL Server 2012中用于计算给定一组值中某个特定值的累积分布。它根据升序或降序排列的方式来确定特定值在数据集中的相对位置。
如果数据集按升序排列,则CUME_DIST函数计算小于等于当前值的行数与总行数的比例;如果数据集按降序排列,则CUME_DIST函数计算大于等于当前值的行数与总行数的比例。
使用示例
执行如下代码,构造一组数据。
-- 声明一个表变量,用于存储数据
DECLARE @analytic TABLE(
name varchar(35) , -- 姓名
dept varchar(35), -- 部门
salary money -- 工资
)
-- 向表变量插入数据
INSERT INTO @analytic
VALUES
--bd部门
('andy01','bd',15000),
('andy02','bd',12000),
('andy03','bd',12000),
('andy04','bd',10000),
('andy05','bd',8000),
--ca部门
('andy06','ca',20000),
('andy07','ca',18000),
('andy08','ca',18000),
('andy09','ca',15000),
('andy10','ca',12000),
('andy11','ca',12000),
('andy12','ca',10000),
('andy13','ca',8000),
('andy14','ca',8000),
('andy15','ca',8000)
-- 使用CUME_DIST函数计算累积分布
SELECT
dept, name, salary,
CUME_DIST() OVER(PARTITION BY dept ORDER BY salary) AS cume_dist_
FROM @analytic
ORDER BY dept, salary DESC返回结果如下:
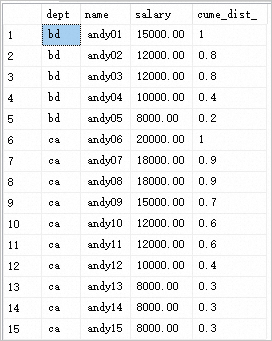
示例分析
在上述示例中,使用了窗口函数CUME_DIST()来计算每个员工的工资在所属部门中的累计分布百分比。例如,如果bd部门的andy02的工资是12000,那么等于或小于12000的记录有4条,总共有5条记录,因此CUME_DIST()的值为4/5=0.8。其他员工也会按照同样的逻辑进行计算。
分析函数LAST_VALUE
函数定义
LAST_VALUE函数在SQL Server 2012中用于获取有序集合中的最后一个值。
使用示例
执行如下代码,构造一组数据。
DECLARE
@analytic TABLE(
name varchar(35) , -- 姓名
dept varchar(35), -- 部门
salary money , -- 薪水
hiredate date -- 入职日期
)
INSERT INTO @analytic
VALUES
--bd部门
('andy01','bd',15000,'2002-01-09'),
('andy02','bd',12000,'2003-01-09'),
('andy03','bd',12000,'2003-02-09'),
('andy04','bd',10000,'2005-05-09'),
('andy05','bd',8000,'2003-06-09'),
--ca部门
('andy06','ca',20000,'2003-01-09'),
('andy07','ca',18000,'2005-02-09'),
('andy08','ca',18000,'2005-03-09'),
('andy09','ca',15000,'2004-01-09'),
('andy10','ca',12000,'2003-06-09'),
('andy11','ca',12000,'2002-09-09'),
('andy12','ca',10000,'2003-07-09'),
('andy13','ca',8000,'2003-08-09'),
('andy14','ca',8000,'2003-11-09'),
('andy15','ca',8000,'2003-01-09')
SELECT
dept,name ,salary,hiredate,
LAST_VALUE(hiredate) OVER(PARTITION BY dept ORDER BY salary) AS last_value_
FROM @analytic返回结果如下:
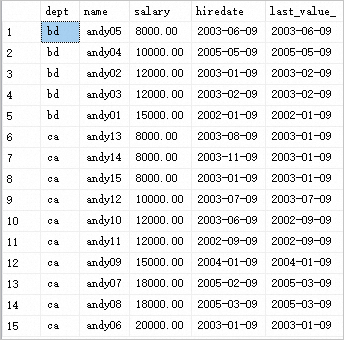
示例分析
在上述示例中,查询结果会返回每个记录的部门(dept)、名字(name)、薪水(salary)、入职日期(hiredate),以及每个部门中薪水最高的记录的入职日期作为最后的LAST VALUE。
在使用LAST_VALUE函数时,通过在OVER子句的ORDER BY中根据salary字段进行排序。然后从排序结果中选择salary最后一行的hiredate值作为最后的LAST VALUE。需注意,如果有多个记录具有相同的salary值,需要选择根据salary排序后的最后一条记录作为其他LAST VALUE的依据。
分析函数FIRST_VALUE
函数定义
FIRST_VALUE函数在SQL Server 2012中用于获取有序值集合中的第一个值。
从函数名称字面来看,FIRST_VALUE似乎跟LAST_VALUE是相反的含义,但实际并非如此。
使用示例
执行如下代码,构造一组数据。
DECLARE
@analytic TABLE(
name varchar(35) ,
dept varchar(35),
salary money ,
hiredate date
)
INSERT INTO @analytic
VALUES
--bd
('andy01','bd',15000,'2002-01-09'),
('andy02','bd',12000,'2003-01-09'),
('andy03','bd',12000,'2003-02-09'),
('andy04','bd',10000,'2005-05-09'),
('andy05','bd',8000,'2003-06-09'),
--ca
('andy06','ca',20000,'2003-01-09'),
('andy07','ca',18000,'2005-02-09'),
('andy08','ca',18000,'2005-03-09'),
('andy09','ca',15000,'2004-01-09'),
('andy10','ca',12000,'2003-06-09'),
('andy11','ca',12000,'2002-09-09'),
('andy12','ca',10000,'2003-07-09'),
('andy13','ca',8000,'2003-08-09'),
('andy14','ca',8000,'2003-11-09'),
('andy15','ca',8000,'2003-01-09')
SELECT
dept,name ,salary,hiredate,
FIRST_VALUE(name) OVER(PARTITION BY dept ORDER BY salary) AS first_value_
FROM @analytic返回结果如下:
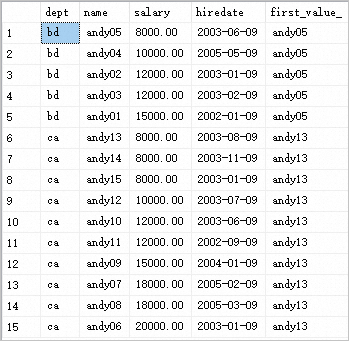
示例分析
在上述示例中,使用了OVER子句,通过PARTITION BY将数据按照部门(dept)进行分组。然后,使用ORDER BY对每个分组内的记录进行排序。而FIRST_VALUE函数会在每个分组内获取排序后的第一个记录的值,而不是根据salary的值来确定的。为了更加明确地表达该含义,将FIRST_VALUE(name)修改为FIRST_VALUE(hiredate)后,可以更清楚地看到每个部门中的第一个记录的入职日期。
因此,显然FIRST_VALUE与LAST_VALUE并不是相反的含义。它们根据不同的排序规则和分组方式来确定值,而不是简单地相反。
分析函数LEAD
函数定义
LEAD(col,n,default)函数用于访问结果集中后续行的数据,而无需使用SQL Server 2012中的自联接。LEAD函数通过指定一个物理偏移量来提供对后续行的访问。在SELECT语句中,我们可以使用LEAD函数来比较当前行中的值与后续行中的值。函数参数取值如下:
col:列名,指定要查找的列。n:查找的行数,指定要返回的值所在的行数(默认为1,表示下一行)。default:默认值,当下一行的值为NULL时,则返回默认值。
使用示例
执行如下代码,构造一组数据。
DECLARE
@analytic TABLE(
name varchar(35) ,
dept varchar(35),
salary money ,
hiredate date
)
INSERT INTO @analytic
VALUES
--bd部门
('andy01','bd',15000,'2002-01-09'),
('andy02','bd',12000,'2003-01-09'),
('andy03','bd',12000,'2003-02-09'),
('andy04','bd',10000,'2005-05-09'),
('andy05','bd',8000,'2003-06-09'),
--ca部门
('andy06','ca',20000,'2003-01-09'),
('andy07','ca',18000,'2005-02-09'),
('andy08','ca',18000,'2005-03-09'),
('andy09','ca',15000,'2004-01-09'),
('andy10','ca',12000,'2003-06-09'),
('andy11','ca',12000,'2002-09-09'),
('andy12','ca',10000,'2003-07-09'),
('andy13','ca',8000,'2003-08-09'),
('andy14','ca',8000,'2003-11-09'),
('andy15','ca',8000,'2003-01-09')
SELECT
dept,name,hiredate,salary,
LEAD(salary,1,0) OVER(PARTITION BY dept ORDER BY salary) AS lead_, -- 使用LEAD函数获取每个部门内按薪水排序后的下一个薪水值,如果没有下一个值,则返回0
(LEAD(salary,1,0) OVER(PARTITION BY dept ORDER BY salary)-salary) AS diff_salary -- 计算当前薪水值与下一个薪水值之间的差异
FROM @analytic返回结果如下:
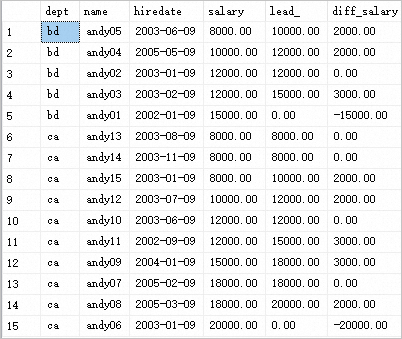
示例分析
在上述示例中,通过使用LEAD函数,将结果集按照dept分区,并根据salary排序,比较当前记录和后一条记录(偏移量为1)的salary值的差值,可以了解每个部门内部员工的薪资变化情况,提供了一种有效的分析方法。