您在使用CLB的过程中如果遇到健康检查相关的问题,您可参考本文进行定位及处理。
健康检查的原理是什么?
负载均衡采用集群部署。四层集群或七层集群内的相关节点服务器同时承载了数据转发和健康检查职责。
四层集群内不同服务器分别独立、并行地根据负载均衡策略进行数据转发和健康检查操作。如果某一台四层集群中的服务器对某一台后端服务器健康检查失败,则该四层集群中的服务器将不会再将新的客户端请求分发给相应的异常的后端服务器。四层集群内所有服务器同步进行该操作。
如下图所示,传统型负载均衡CLB健康检查使用的地址段是100.64.0.0/10,后端服务器务必不能屏蔽该地址段。您无需在ECS安全组中额外针对该地址段配置放行策略,但如有配置iptables等安全策略,请务必放行(100.64.0.0/10 是阿里云保留地址,其他用户无法分配到该网段内,不会存在安全风险)。

更多信息,请参见CLB健康检查工作原理。
推荐的健康检查配置是什么?
为了避免由于健康检查频繁失败引起的切换对系统可用性造成的冲击,健康检查只有在健康检查时间窗内连续多次检查成功或失败后,才会进行状态切换。更多信息,请参见配置和管理CLB健康检查。
以下是TCP、HTTP和HTTPS监听建议使用的健康检查配置。
配置 | 推荐值 |
健康检查响应超时时间 | 5秒 |
健康检查间隔时间 | 2秒 |
健康检查健康阈值 | 3次 |
健康检查不健康阈值 | 3次 |
以下是UDP监听建议使用的健康检查配置。
配置 | 推荐值 |
健康检查响应超时时间 | 10秒 |
健康检查间隔时间 | 5秒 |
健康检查健康阈值 | 3次 |
健康检查不健康阈值 | 3次 |
此配置有利于您的服务和应用状态的尽快收敛。如果您有更高要求,可以适当地降低响应超时时间值,但必须优先保证服务在正常状态下的处理时间小于这个值。
是否可以关闭健康检查?
可以关闭。具体操作,请参见关闭健康检查。
如果关闭健康检查,当后端某个服务器健康检查出现异常时,负载均衡还是会把请求转发到该异常的ECS实例上,造成部分业务不可访问。
如果您的业务对负载敏感性高,高频率的健康检查探测可能会对正常业务访问造成影响。您可以结合业务情况,通过降低健康检查频率、增大健康检查间隔、七层检查修改为四层检查等方式,来降低对业务的影响。但为了保障业务的持续可用,不建议关闭健康检查。
TCP监听如何选择健康检查方式?
TCP监听支持HTTP和TCP两种健康检查方式:
TCP协议健康检查通过发送SYN握手报文,检测服务器端口是否存活。
HTTP协议健康检查通过发送HEAD或GET请求,模拟浏览器的访问行为来检查服务器应用是否健康。
TCP健康检查方式对服务器的性能资源消耗相对要少一些。如果您对后端服务器的负载高度敏感,则选择TCP健康检查;如果负载不是很高,则选择HTTP健康检查。
ECS实例权重设置为零对健康检查有什么影响?
该状态下,负载均衡不会再将流量转发给该ECS实例,监听的后端服务器健康检查不会显示异常。
将负载均衡后端ECS实例的权重置为零,相当于将该ECS实例移出负载均衡。一般是在ECS实例进行重启和配置调整等主动运维时将其权重设置为零。
HTTP监听向后端ECS实例执行健康检查默认使用的方法是什么?
HEAD方法。
如果后端ECS实例的服务关闭HEAD方法,会导致健康检查失败。建议在ECS实例上用HEAD方法访问自己IP地址进行测试:
curl -v -0 -I -H "Host:" -X HEAD http://IP:portHTTP监听向后端ECS实例执行健康检查的IP地址是什么?
CLB健康检查使用的地址段是100.64.0.0/10,后端服务器务必不能屏蔽该地址段。您无需在ECS安全组中额外针对该地址段配置放行策略,但如有配置iptables等安全策略,请务必放行(100.64.0.0/10 是阿里云保留地址,其他用户无法分配到该网段内,不会存在安全风险)。
为什么健康检查监控频率与Web日志记录不一致?
负载均衡健康检查服务也是集群方式的,这样可以避免单点故障。负载均衡的代理分布到很多节点上,因此看到的健康检查日志访问频率和控制台设置的频率不一致,这是正常现象。
负载均衡因后端数据库故障导致健康检查失败,如何处理?
问题现象
ECS实例内配置了两个网站:
www.example.com是静态网站,aliyundoc.com是动态网站,都配置了负载均衡。后端数据库服务异常,导致访问www.example.com静态网站出现502错误。问题原因
负载均衡健康检查配置的检查域名是
aliyundoc.com,RDS或者自建数据库故障导致aliyundoc.com访问异常,所以健康检查失败。解决方案
将负载均衡健康检查域名配置为
www.example.com即可。
负载均衡服务TCP端口健康检查成功,为什么在后端业务日志中出现网络连接异常信息?
问题现象
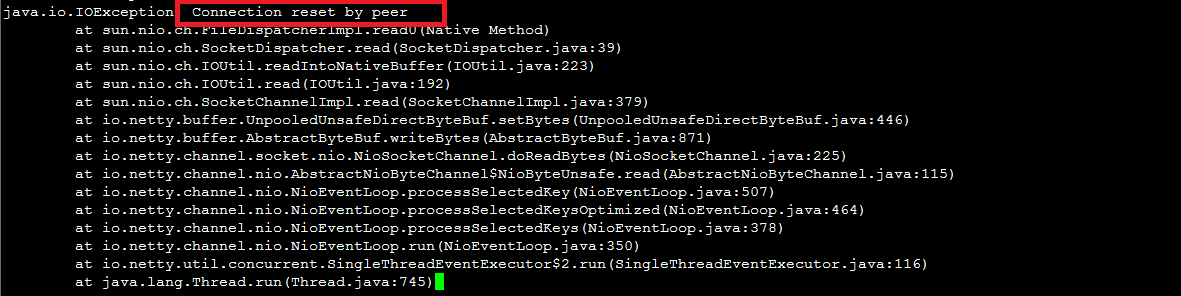
负载均衡后端配置TCP服务端口后,后端业务日志中频繁出现类似如下网络连接异常错误信息。经过抓包分析,发现相关请求来自负载均衡服务器,同时负载均衡主动向服务器发送了RST数据包。
问题原因
该问题和负载均衡的健康检查机制有关。
由于TCP对上层业务状态无感知,同时,为了降低负载均衡健康检查成本和对后端业务的冲击,当前负载均衡针对TCP协议服务端口的健康检查只会做简单的TCP三次握手,而后直接发送RST包断开TCP连接。数据交互流程如下:
负载均衡服务器向后端负载均衡服务端口发送SYN请求包。
后端服务器收到请求后,如果端口状态正常,则按照正常的TCP机制返回相应的SYN+ACK应答包。
负载均衡服务器成功收到后端服务端口应答后,则认为端口监听是正常的,判定健康检查成功。
负载均衡服务器向相应TCP服务端口直接发送RST包主动关闭连接,结束本次健康检查操作,且没有继续发送业务数据。
如上所述,由于健康检查成功后,负载均衡服务器直接发送TCP RST包中断了连接,并没有做进一步的业务数据交互,导致上层业务(例如Java连接池等)认为相应的连接是异常的,所以会出现
Connection reset by peer等错误信息。解决方案
更换TCP协议为HTTP协议。
在业务层面,对来自SLB服务器IP地址段的相关请求做日志过滤,忽略相关错误信息。
为什么业务本身没有异常但是健康检查显示异常?
问题现象
负载均衡HTTP方式的健康检查始终失败,但测试
curl得到的状态码是正常的。问题原因
如果返回的状态码与控制台配置的正常状态码不一致,则判定健康检查异常。如果您配置的正常状态码为http_2xx,则所有返回的非HTTP 2xx状态码均被认为是健康检查失败。
Tengine/Nginx配置执行
curl命令会发现没有问题,但是执行echo命令会匹配到默认站点,导致测试文件test.html返回404错误,如下图所示。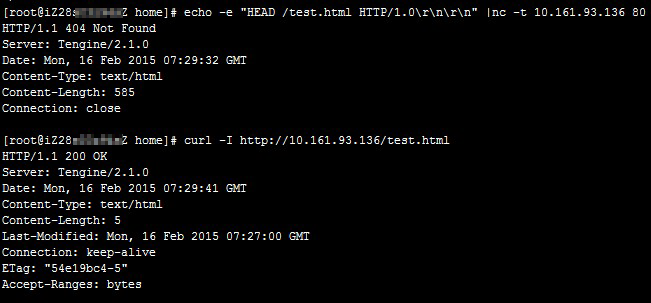
解决方案
修改主配置文件,注释默认站点。
在健康检查配置中添加检查域名。