云原生数据湖分析(Data Lake Analytics,DLA)是无服务器(Serverless)化的云上交互式查询分析服务,支持通过标准SQL分析多种数据源中的数据,快速入门将以DLA读取OSS数据为例,帮助您掌握DLA的基本使用流程。
数据源 | DLA SQL读写 | DLA Spark读写 |
支持 | 支持 | |
支持 | 待支持 | |
支持 | 待支持 | |
支持 | 待支持 | |
支持 | 支持 | |
支持 | 待支持 | |
支持 | 待支持 | |
支持 | 待支持 | |
支持 | 支持 | |
支持 | 待支持 | |
支持 | 待支持 |
步骤一:开通OSS数据源
如果您在DLA中没有开通OSS数据源,需参照以下步骤开通OSS数据源。
登录数据湖分析管理控制台。
在页面左上角,选择集群所在地域。
单击左侧导航栏的数据湖构建 > 元数据管理。
在创建Schema页面的常用页签下,选择对象存储服务中的使用向导创建。若您的账号还未开通OSS数据源,根据系统提示开通OSS数据源。
步骤二:创建Schema
DLA提供两种创建OSS Schema的方法:通过向导模式创建OSS Schema和操作步骤。本示例介绍如何通过向导模式创建OSS Schema。
登录数据湖分析管理控制台。
在页面左上角,选择集群所在地域。
单击左侧导航栏的数据湖管理 > 元数据管理。
在创建Schema页面的常用页签下,选择对象存储服务中的使用向导创建。
在创建Schema页面,按照页面提示进行参数配置。
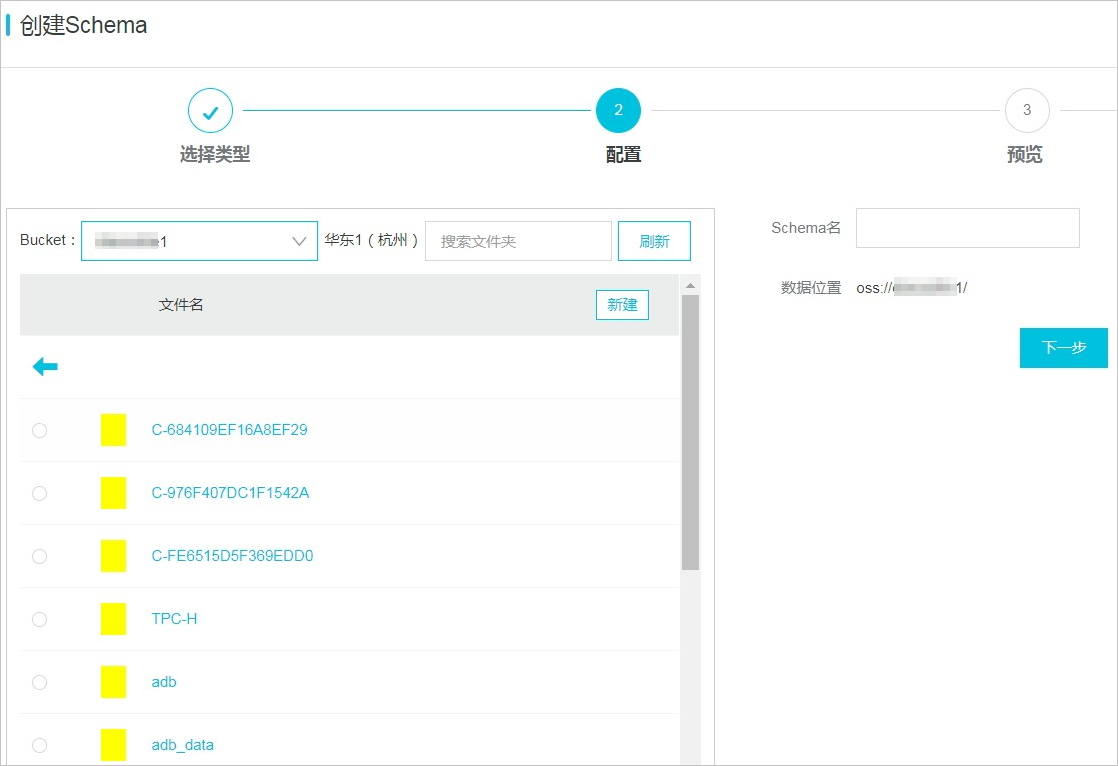
Bucket:系统自动拉取与DLA同地域的OSS Bucket,根据业务需求从下拉列表中选择Bucket。
选择Bucket后,系统自动列出该Bucket下所有的Object和文件,支持模糊搜索Object,单击目标Object将其添加到右侧的数据位置处。
数据位置:文件在OSS中的存储地址,以
/结尾。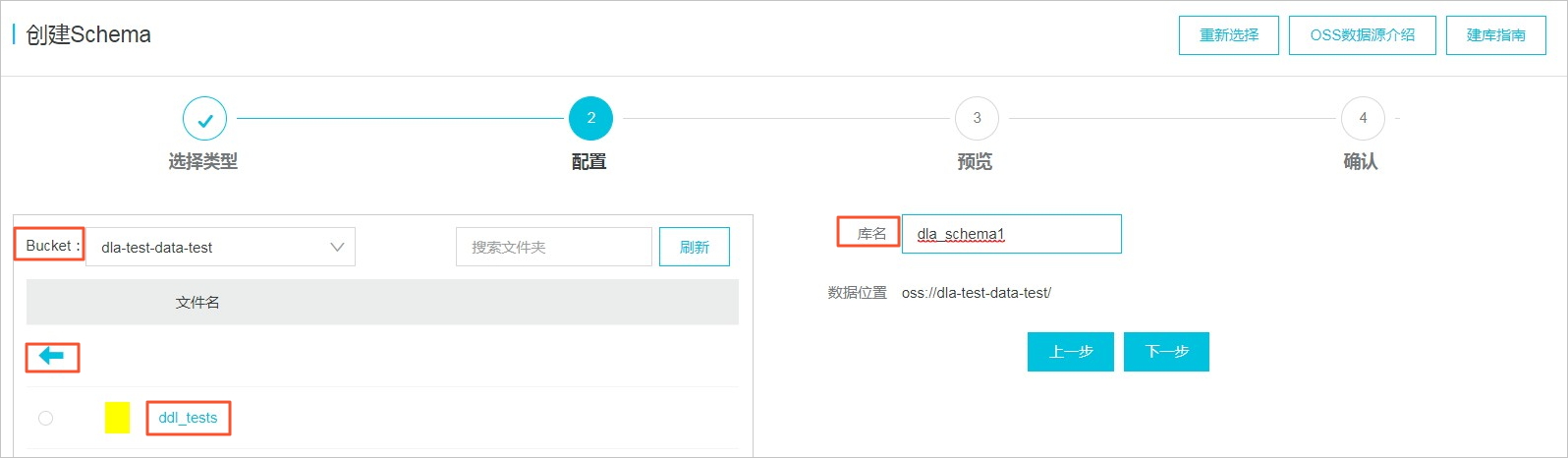
完成上述参数配置后,单击下一步。
在创建Schema页面预览生成的Schema创建语句,可以根据需要修改SQL。
确认SQL无误后,单击执行,在弹出的执行确认窗口,单击确认创建Schema。
步骤三:创建表
DLA提供两种创建OSS表的方法:通过向导模式创建OSS表和操作步骤。本示例介绍如何通过向导模式创建OSS表。
登录数据湖分析管理控制台。
在页面左上角,选择集群所在地域。
单击左侧导航栏的数据湖管理 > 元数据管理。
在元数据管理列表,单击目标Schema右侧的创建新表。
在快速建表页面,选择目标Schema,然后单击下一步。
根据系统提示进行参数配置。
若文件夹下有子文件夹,单击文件夹将显示子文件夹,左边的数据位置也会随着改变。单击箭头图标返回上层文件夹。
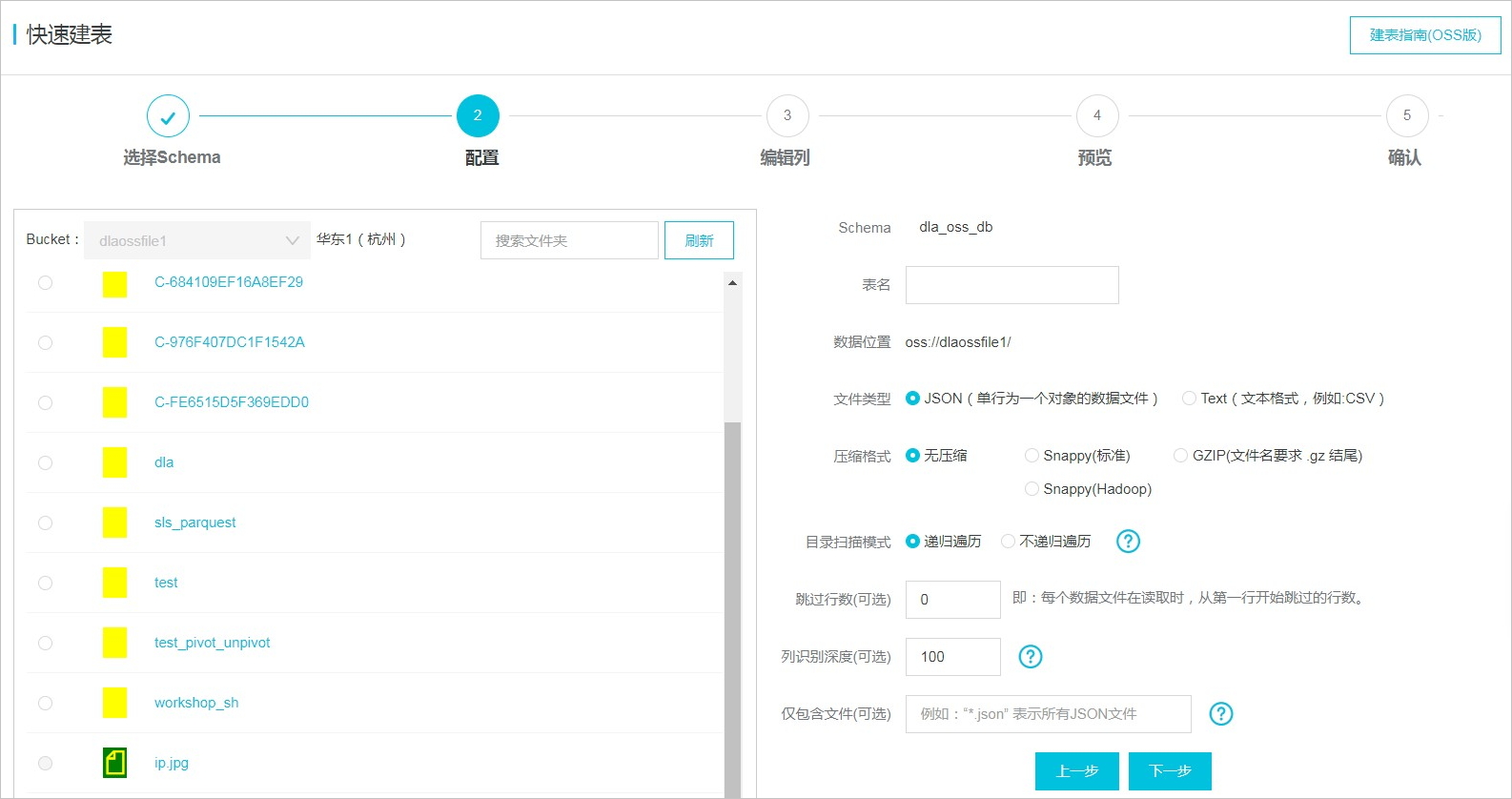
参数
说明
表名
设置OSS的表名。
数据位置
系统根据文件夹的路径,自动设置数据位置。
文件类型
支持JSON和Text两种类型。
压缩格式
选择默认无压缩。
目录扫描模式
配置表所在目录下的资源扫描方式。递归遍历:扫描所有文件及子目录。不递归遍历:扫描所有文件,不包含任何目录。
行分隔符
文件类型为Text时,设置数据的行分隔符。行分隔符支持回车符和换行符。
跳过行数
读取文件数据时,从第一行开始跳过的行数。
列分隔符
文件类型为Text时,设置数据的列分隔符。列隔符支持英文逗号(,)和竖线(|),支持自定义列分隔符。
列识别深度
-
仅包含文件
设置要扫描哪些文件。特定文件:输入扫描文件的文件名,只扫描某个特定文件某类文件:使用通配符,设置扫描某类文件,例如.json表示扫描所有JSON文件。
完成上述参数配置,单击下一步。
在编辑列页面,单击下一步。
在预览页面,确认
Create Table无误,单击执行。在弹出的执行确认窗口,单击确认,系统开始执行Create TableSQL。